MonoDETR论文解读
abstract
单目目标检测在自动驾驶领域,一直是一个具有挑战的任务。现在大部分的方式都是沿用基于卷积的2D 检测器,首先检测物体中心,后通过中心附近的特征去预测3D属性。
但是仅仅通过局部的特征去预测3D特征是不高效的,且并没有考虑一些长距离的物体之间的深度关系,丢失了很多的有意义的信息。
在本作中,作者介绍了一种基于DETR框架的用于单目检测的网络。作者通过对原始的transformer网络进行改造,加入了以深度为引导的transformer结构。作者将此网络结构命名为MonoDETR。
具体来说,作者在使用视觉encoder去提取图像的特征外,还引入了一种depth encoder去预测前景深度地图,后续将其转化为depth embeddings。之后就和传统的DETR或者BevFormer一致,使用3D object query去与前述生成的vision embeding 和 depth embending分别做self 和 cross attention,通过decoder得到最终的2D以及3D结果。通过此种方法,每一个3D物体都是通过depth-guided regions(embedding)去获取的3D信息,而非限制在局部的视觉特征。

介绍
相对于基于lidar和multi-view 的3D检测任务,单目3D检测是相对较困难的。因为没有可依赖的3D深度信息以及多视角几何学关系。所以相应的检测结果也不会那么的好。
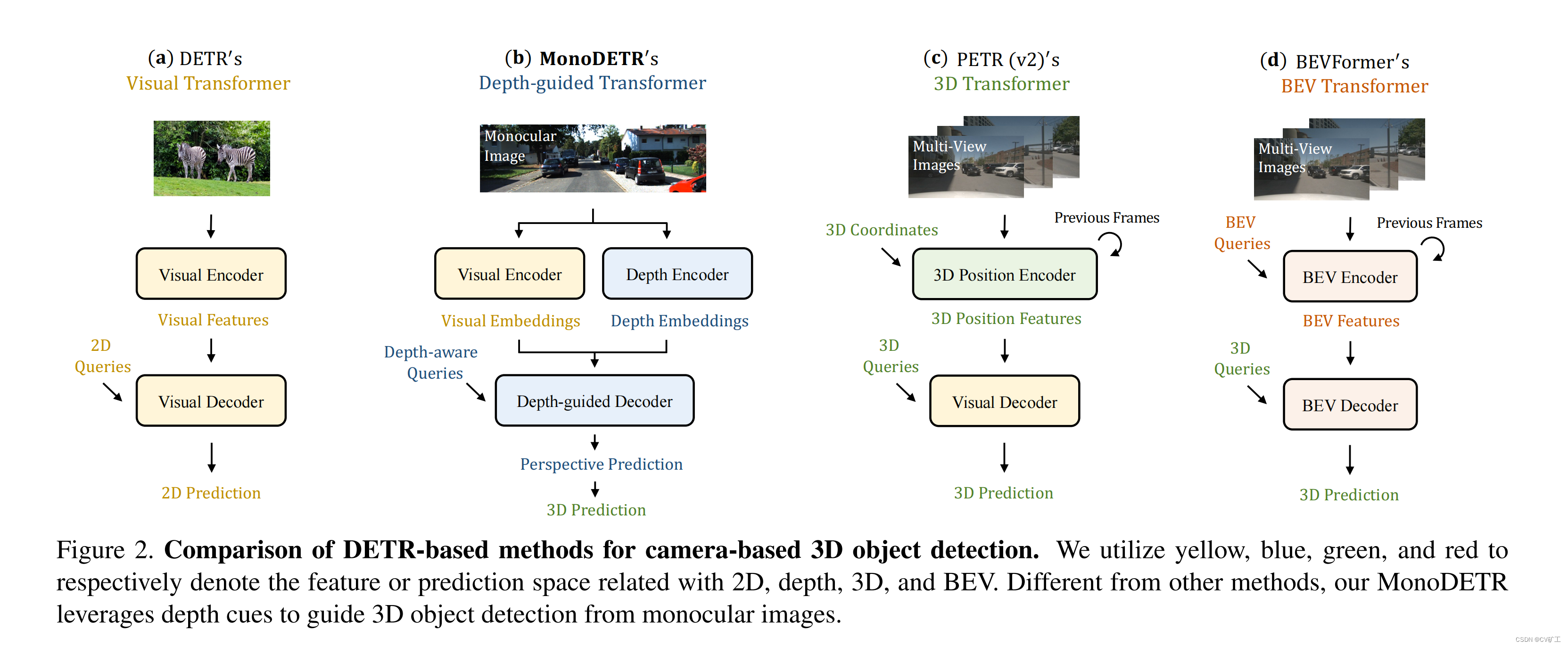
为了解决这些问题,我们根据DETR的2
D检测框架提出了本文的网络结构。如上图所示b所示:此结构包括两个平行部分,分别为vision encoder 和 depth encoder。
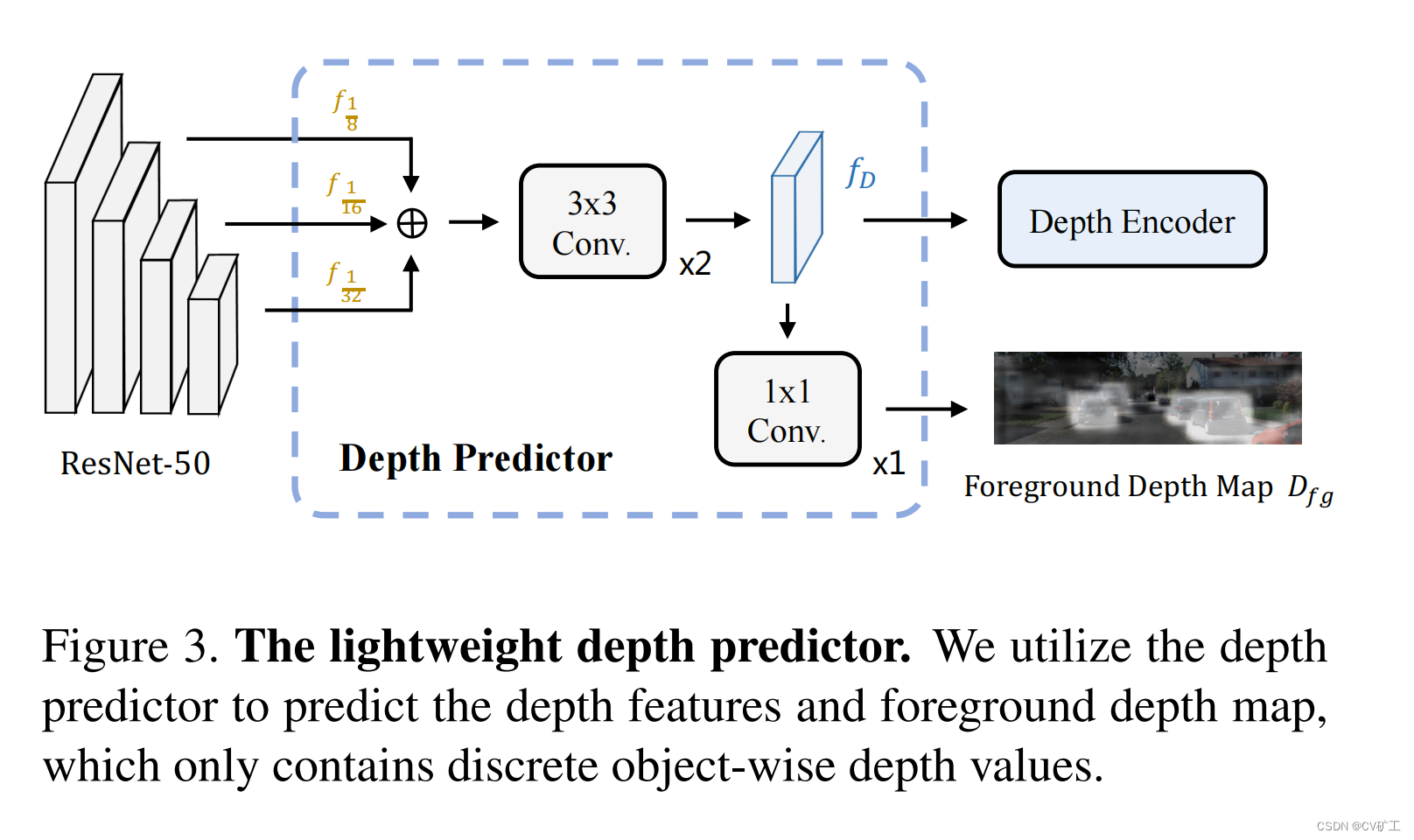
划重点:如何去学习深度信息呢?这里论文使用了了一个“轻”的监督去获取输入图像的深度信息。具体是在在image backbone后接了一个depth predictor,用于输出前景深度地图。同时在过程中产生的depth feature会输入到紧接着的depth encoder,用来提取深度信息。同时我们对输出的前景地图进行监督。此监督仅仅是由我们的labeled object构成即可,也就是一个discrete depth of objects。这样就不需要稠密的深度地图label。减轻了对数据的压力。又能获取使用的深度信息。
在这两个encoder后,继续接一个transformer结构,使用object query从视觉embeding和depth embeding中聚合信息,从而对物体进行检测。
此处的优势就比较明显,相对于目前自动驾驶领域的各种繁重的数据pipeline,此方法仅仅需要常规的物体标注结果即可完成全部的检测流程。而无需额外的dense depth maps或者Lidar信息。且在kitti中取得了SOTA的成绩。
同时这里边提到的depth encoder也可以作为一个plug and play的插件直接用来增强多视觉3D检测效果,比如BEVFormer。(当然我看来这几个点,似乎没啥用~)
related work
咱自己看论文哈~和本文关系不太大
突然看到有个有点意思的介绍,这里简单说下:
DETR base methods
- MonoDTR: 仅仅引入transformer去增强数据提取而已。还是提取的局部特征,基于object center这种,严格上不是基于DETR的方法,具体可以参考:MonoDTR解读
- DETR3D 和PETR v2 : multi view 3D检测,使用了detr结构,但是没用到transform base的encoder。相应的也就只用了视觉信息,无深度信息。具体参考PETR v2解读 DETR 3D
- BEVFormer:加了个从image feature到bev feature的encoder进行信息提取。后续在bev空间进行3D检测。GOOD!BEVFormer 解读
Method
又到了喜闻乐见的看图说论文环节,上图
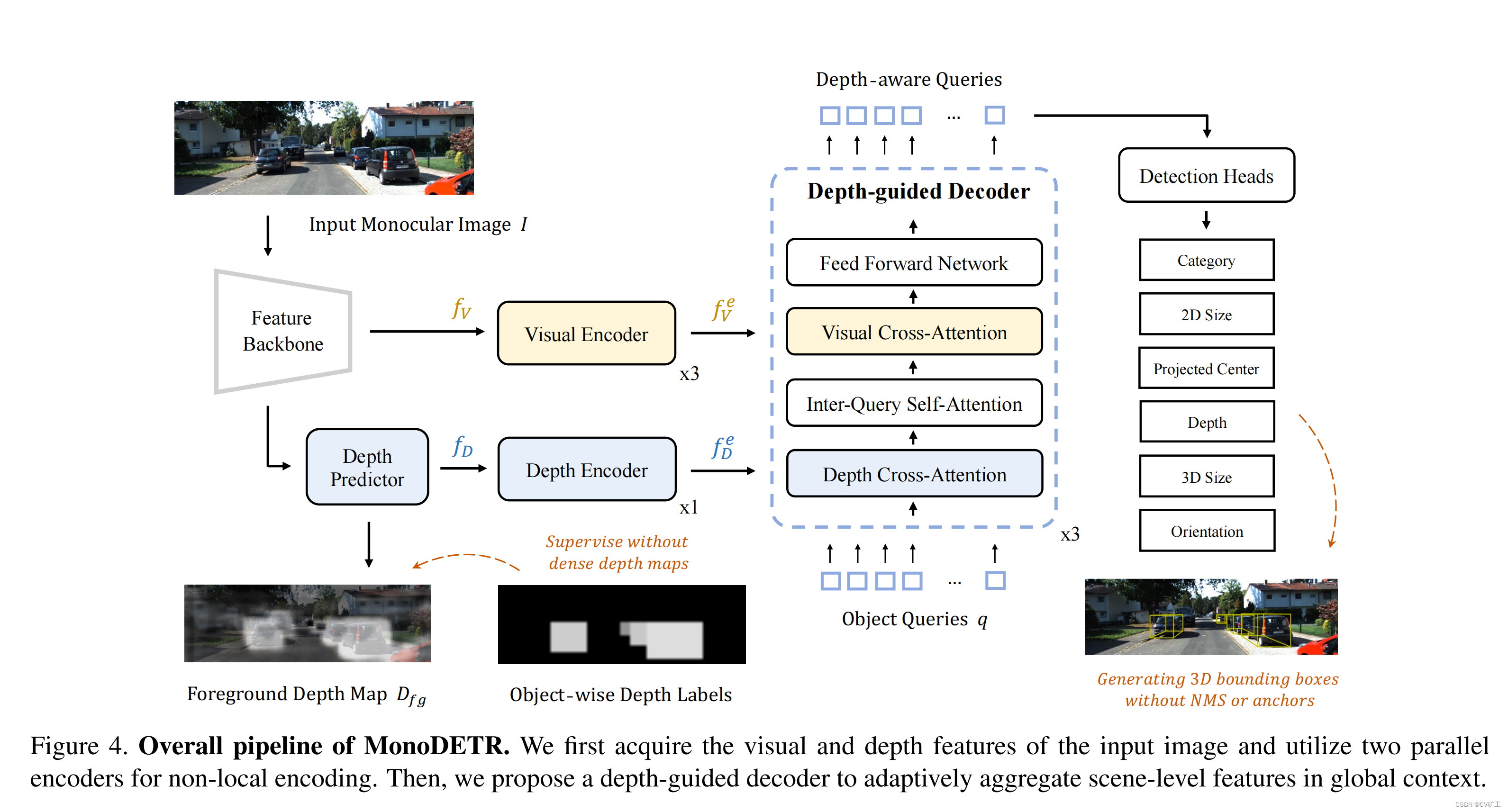
Feature Extraction
未完待续