🍁 博主 "开着拖拉机回家"带您 Go to New World.✨🍁
🦄 个人主页——🎐开着拖拉机回家_Linux,Java基础学习,大数据运维-CSDN博客 🎐✨🍁
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
一、概述
二、优点
三、核心架构
3.1、HDFS
3.2、NameNode
3.2、DataNode
四、Hadoop发行版本
4.1、Apache Hadoop
4.2、CDP
4.3、DataSophon
一、概述

Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS(Hadoop Distributed File System)。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算 [百度百科]。
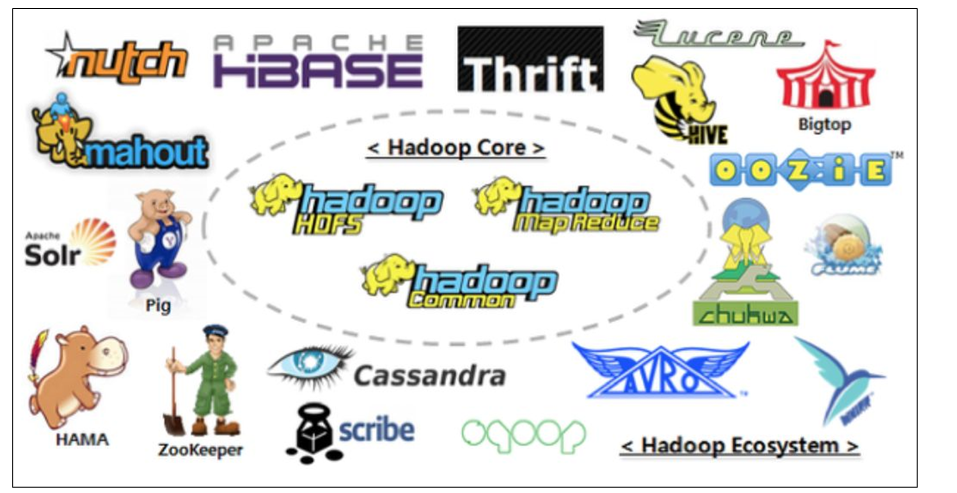
二、优点
Hadoop是一个能够对大量数据进行分布式处理的软件框架。 Hadoop 以一种可靠、高效、可伸缩的方式进行数据处理。
- 高可靠性。Hadoop底层维护多个数据副本,所以即使Hadoop某台服务器或者某个副本不可用,也不会导致数据的丢失。
- 高扩展性。Hadoop是在可用的集群分配数据并完成计算任务的,集群可以方便地扩展到数以千计的节点中 。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡(banlance)。在MapReduce的思想下,hadoop任务并行处理,因此处理速度非常快 。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配
- 低成本。hadoop是开源的,项目的软件成本因此会大大降低,又可部署在廉价的服务器上 。
三、核心架构
Hadoop设计了一个在分布式集群上实现资源管理与功能水平分层的架构,该分层解耦架构让大家可以在Hadoop上不断地叠加组件,并且每个组件可以独立升级,同类组件可以相互竞争,不断提升性能。作为Hadoop生态系统的核心,HDFS、YARN、MapReduce形成了一个灵活的基座,并以此为基础扩展出了非常多的Hadoop兼容开源项目和软件,常见的大数据组件包括。
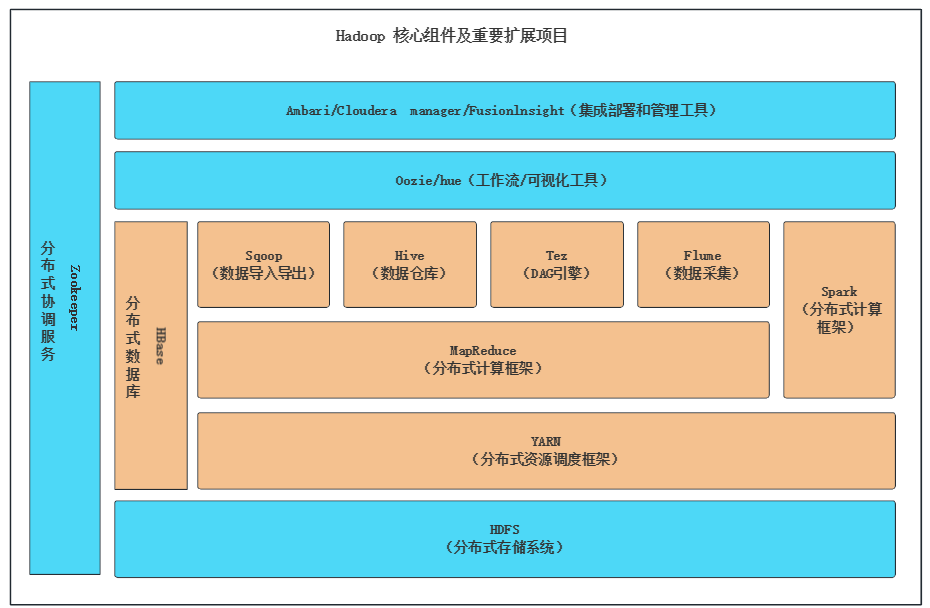
3.1、HDFS
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。 HDFS 的架构节点包括 NameNode,它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(2.x版本默认为128MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。

3.2、NameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上 。
实际的 I/O事务并没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode 。
NameNode 在一个称为 FsImage 的文件中存储所有关于文件系统名称空间的信息。这个文件和一个包含所有事务的记录文件(这里是 EditLog)将存储在 NameNode 的本地文件系统上。FsImage 和 EditLog 文件也需要复制副本,以防文件损坏或 NameNode 系统丢失 。
NameNode本身不可避免地具有SPOF(Single Point Of Failure)单点失效的风险,一般通过开启 HA 解决单点故障问题,如下为 NameNode HA 架构 。
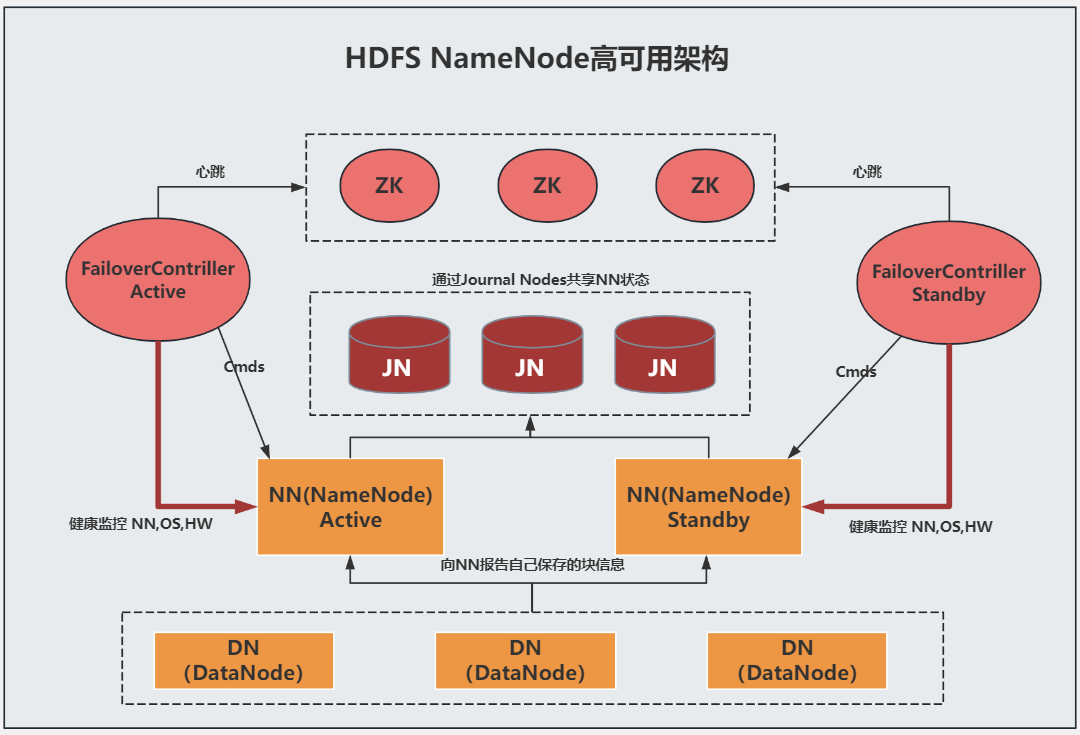
NameNode HA 架构
3.2、DataNode
DataNode 也是一个通常在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度 。
DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。NameNode 依赖来自每个 DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。

NameNode上并不永久保存哪个DataNode上有哪些数据块的信息,而是通过DataNode启动时的上报来更新NameNode上的映射表。
1.根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送所存储的块(block)的列表
2.数据块在DataNode进程所在的节点上以文件的形式存储在本地磁盘上
- 一个是数据本身
- 一个是元数据(数据块的长度,块数据的校验和,以及时间戳)
3.维护blockid与DataNode之间的映射信息(元信息)

四、Hadoop发行版本
Hadoop发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好;
- Cloudera内部集成了很多大数据框架,对应产品CDH;
- Hortonworks文档较好,对应产品HDP;
- Hortonworks现在已经被Cloudera公司收购,推出新的收费产品CDP;
4.1、Apache Hadoop
官网地址:http://hadoop.apache.org
下载地址:https://hadoop.apache.org/releases.html
Hadoop发行版本分为开源社区版。 社区版是指由Apache软件基金会维护的版本,是官方维护的版本体系,入门学习建议使用开源的Apache Hadoop 。
4.2、CDP
Hortonworks的主打产品是Hortonworks Data Platform(HDP),过去是开源的产品,2018年Hortonworks目前已经被Cloudera公司收购 ,现在已是CDP 且收费了。
- Cloudera Hadoop
- Hortonworks Hadoop
官网地址:Enterprise Data Management Platforms & Products | Cloudera
4.3、DataSophon
DataSophon是近日开源的一款国产自研大数据管理平台,致力于快速实现部署、管理、监控以及自动化运维大数据服务组件和节点的能力,帮助你快速构建起稳定、高效的大数据集群服务。还不够成熟,再等等吧。
开源地址:https://github.com/gaodayu168/datasophon
在线文档:https://gaodayu168.github.io/datasophon-website
国产收费的产品比较多阿里系, 星环等等 ,但是中小公司 可能不想过多投入,很多依然在使用之前开源的CDH和HDP
参考:国产自研开源大数据管理平台DataSophon Manager安装教程
Hadoop DataNode详解_hadoop3.0 datanode version 的内容是什么_雾幻的博客-CSDN博客
百度百科