(来源:Blog | the scapegoat dev)
前言
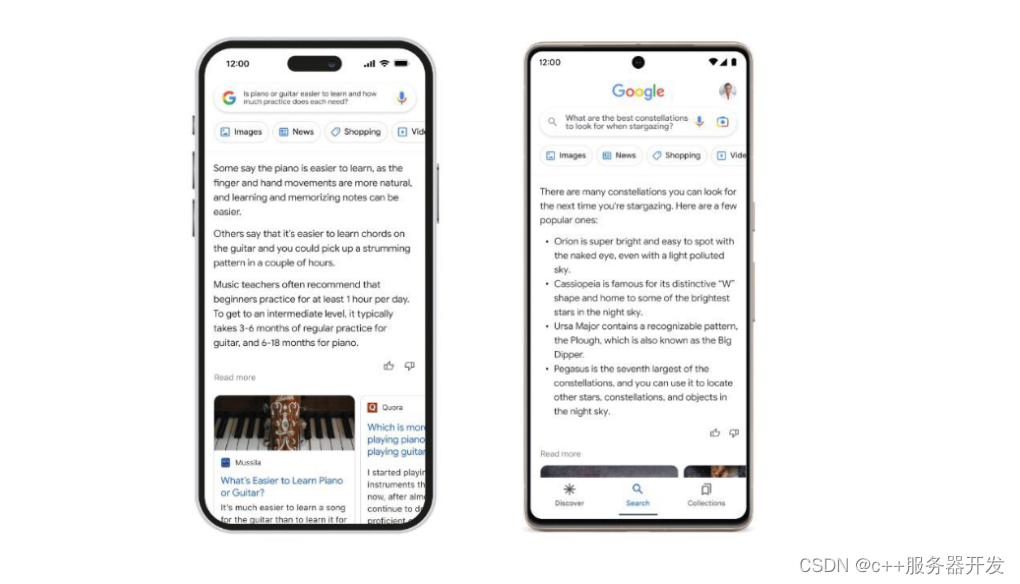
人工智能的发展已经深刻地改变了我们的生活和工作方式,使得我们能够在各种领域中实现更加复杂和高效的任务。其中包括自然语言处理(NLP)和机器翻译等领域,这些领域最近出现了一种新的技术——基于大型语言模型的自适应技术,也称为LLM(large language models)。LLM是一种利用深度学习训练的巨大神经网络,它可以通过分析大量语言数据来预测和生成自然语言之间的关系。LLM的成果之一是各种预先训练的模型,如BERT、GPT-3等,这些模型几乎可以与人类一样理解和生成自然语言。但是,这种技术的出现是否将从根本上改变传统的软件工程方式呢?这篇文章将探讨这个问题。
什么是LLM?
LLM(Large Language Models)是一种新兴的人工智能技术,它利用深度学习算法训练数以亿计的参数,以便在处理自然语言时具有更强的能力。这些模型可以从文本中获取知识,并预测新文本的结构和含义。近年来,LLM已经在自然语言处理(NLP)领域迅速发展,并被广泛应用于翻译、自动问答、语音识别等任务中。
LLM如何工作?
LLM的核心思想是预训练一个巨大的神经网络,在实际任务中进行微调。在预训练阶段,模型被大量文本数据喂养。这些数据可能是来自互联网上的海量文本数据,或者是特定领域的数据。在经过预训练后,模型可以对新的输入进行推断和生成输出。当将模型