没有明确写明数据库时,默认基于oracle
约束的分类
用于确保数据的完整性和一致性。约束可以分为 表级约束 和 列级约束,区别在于定义的位置和作用范围




复合主键约束: 主键约束中有2个或以上的字段
复合主键的列顺序会影响索引的使用,需谨慎设计



添加约束
oracle会自动为主键约束, 唯一约束, 外键约束创建索引, 以提高查询性能
在已存在的表上添加约束

添加约束注意:
主键约束: 如果表中已经存在重复数据或 NULL 值,无法添加主键约束, 在对已经存在的表添加主键之前先检查数据, 处理重复值和NULL值
非空约束:如果表中已经存在NULL值,无法添加,添加前先检查是否存在NULL值

删除约束

查看约束
使用数据字典视图:
-
USER_CONSTRAINTS:查看当前用户拥有的约束。 -
ALL_CONSTRAINTS:查看当前用户可以访问的所有约束。 -
DBA_CONSTRAINTS:查看数据库中所有约束(需要DBA权限)。



启用/禁用约束
启用约束

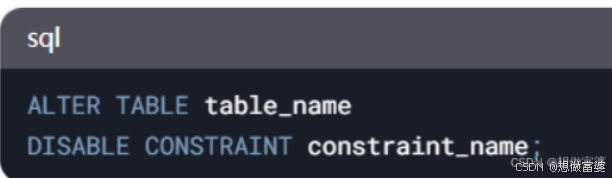
禁用约束
 ]
]
在使用列级约束时并没有定义约束的名称, 但是Oracle 会自动为约束生成一个默认名称。这些默认名称通常以 SYS_C 开头,后面跟随一串数字。要查看这些自动生成的约束名称,你可以查询数据字典视图 USER_CONSTRAINTS 或 ALL_CONSTRAINTS。
外键约束
外键约束(Foreign Key Constraint)用于确保表之间的引用完整性。外键约束定义了一个表中的列(或一组列)必须与另一个表中的主键或唯一键列的值相匹配。外键约束可以防止在子表中插入无效的数据,并可以定义在删除或更新父表中的数据时的行为。

[ON DELETE CASCADE | ON DELETE SET NULL] 是用于定义外键约束时,指定当父表中的记录被删除时,子表中相关记录应如何处理的可选子句。

oracle的主键自增: 序列和触发器

在 Oracle 数据库中, 通过以下两种方式实现主键自增





2种方法在高并发环境下的表现

在高并发环境下,Oracle如何确保自增值的唯一性
序列:

触发器:
在插入数据时自动从序列中获取下一个值并赋值给主键列。触发器确保在插入操作时自动生成唯一的主键值
其他数据库的主键自增
mysql

GaussDB高斯数据库

在多个表中使用同一个序列时,会导致表中的序列号不连续。为了避免这种情况,建议为每个表创建独立的序列,以确保每个表的自增值连续且不受其他表的影响。

PostgreSQL
方法一: SERIAL

方法二: IDENTITY

GENERATED BY DEFAULT AS IDENTITY >>默认情况下作为标识生成

序列 sequence




-- 插入数据时使用序列
INSERT INTO Users (UserID, UserName)
VALUES (序列名.NEXTVAL, 'John Doe');-- 获取当前序列值
SELECT 序列名.CURRVAL FROM dual;

查看序列
方法一:

如果你有权限访问其他用户的序列,可以使用 ALL_SEQUENCES 视图; (语法如上)
如果你有DBA权限,可以使用 DBA_SEQUENCES 视图查看数据库中所有序列的信息;(语法如上)
方法二:











![python算法和数据结构刷题[5]:动态规划](https://i-blog.csdnimg.cn/direct/a18bf42fd18c4f35937d3793bd67de08.png)