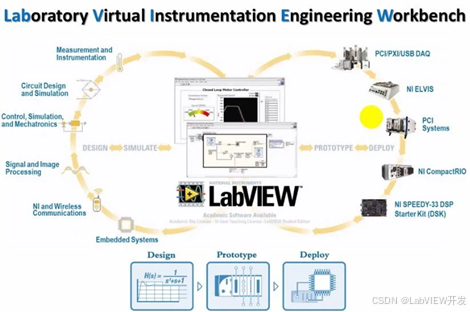
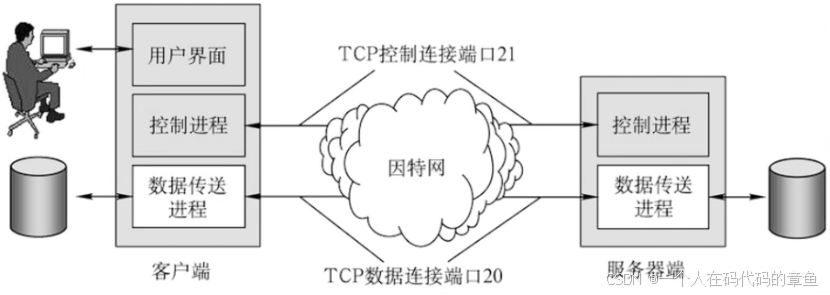
本案例较为简单,用到的知识有 v-model、v-if、v-else、指令修饰符.prevent .number .trim等、computed计算属性、toFixed方法、reduce数组方法。
涉及的功能需求有:渲染、添加、删除、修改、统计总分,求平均分等。
需求效果如下:




代码实现:
<!DOCTYPE html>
<html lang="en"><head><meta charset="UTF-8" /><meta http-equiv="X-UA-Compatible" content="IE=edge" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><link rel="stylesheet" href="./styles/index.css" /><title>成绩案例实现</title></head><body><div id="app" class="score-case"><div class="table"><table><thead><tr><th>编号</th><th>科目</th><th>成绩</th><th>操作</th></tr></thead><tbody v-if="list.length > 0"><tr v-for="(item, index) in list" :key="item.id"><td>{{ index + 1 }}</td><td>{{ item.subject }}</td><!-- 需求:不及格的标红, < 60 分, 加上 red 类 --><td :class="{ red: item.score < 60 }"><span v-if="editingId !== item.id">{{ item.score }}</span><input v-else type="text" v-model.number="item.score" @blur="finishEdit(item.id)"></td><td><!-- 阻止默认行为 --><a @click.prevent="del(item.id)" href="http://www.baidu.com">删除</a><a @click="edit(item.id)" href="#" style="color: red">编辑</a></td></tr></tbody><tbody v-else><tr><td colspan="5"><span class="none">暂无数据</span></td></tr></tbody><tfoot><tr><td colspan="5"><span>总分:{{ totalScore }}</span><span style="margin-left: 50px">平均分:{{ averageScore }}</span></td></tr></tfoot></table></div><div class="form"><div class="form-item"><div class="label">科目:</div><div class="input"><inputtype="text"placeholder="请输入科目"v-model.trim="subject"/></div></div><div class="form-item"><div class="label">分数:</div><div class="input"><inputtype="text"placeholder="请输入分数"v-model.number="score"/></div></div><div class="form-item"><div class="label"></div><div class="input"><button @click="add" class="submit" >添加</button></div></div></div></div><script src="https://cdn.jsdelivr.net/npm/vue@2/dist/vue.js"></script><script>const app = new Vue({el: '#app',data: {list: [{ id: 1, subject: '语文', score: 92 },{ id: 7, subject: '数学', score: 89 },{ id: 12, subject: '英语', score: 50 },],subject: '',score: '',editingId: null },computed: {totalScore() {return this.list.reduce((sum, item) => sum + item.score, 0)},averageScore () {if (this.list.length === 0) {return 0}return (this.totalScore / this.list.length).toFixed(2)}},methods: {del (id) {this.list = this.list.filter(item => item.id !== id)},edit(id) {this.editingId = id; // 设置正在编辑的项的ID},finishEdit(id) {this.editingId = null;},add () {if (!this.subject) {alert('请输入科目')return}if (typeof this.score !== 'number') {alert('请输入正确的成绩')return}this.list.unshift({id: +new Date(),subject: this.subject,score: this.score})this.subject = ''this.score = ''}}})</script></body>
</html>







![python算法和数据结构刷题[5]:动态规划](https://i-blog.csdnimg.cn/direct/a18bf42fd18c4f35937d3793bd67de08.png)