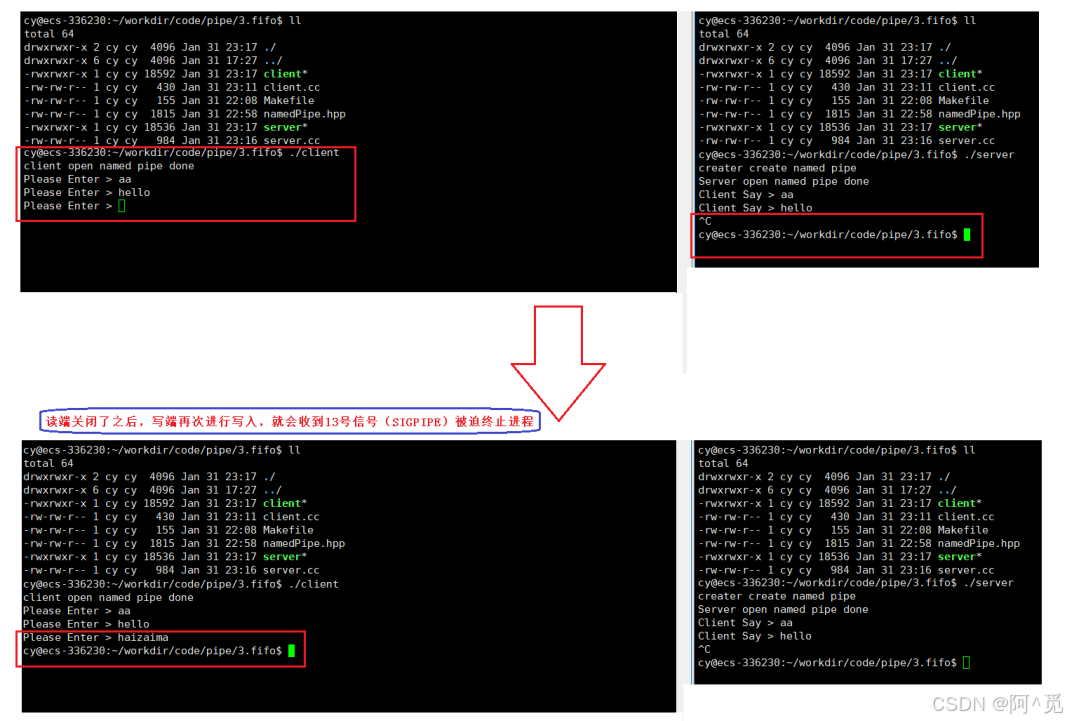
这东西具有隔离效果,对于一些插件需要append一些div倒是不错的选择
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="utf-8">
<title>演示例子</title>
</head>
<body>
<style>
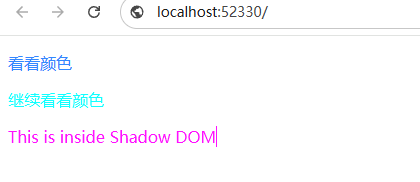
p{color:#38f !important;}
.box{color:#1ff !important;}
</style><p>看看颜色</p>
<div class="box">继续看看颜色</div>
<div id="shadow">影子节点</div>
<script>
// 获取宿主元素
const hostElement = document.querySelector('#shadow');// 创建一个 Shadow Root
const shadowRoot = hostElement.attachShadow({ mode: 'closed' });
// 添加一些样式和内容到 Shadow Root
shadowRoot.innerHTML = `<style>p {color: #f1f;}</style><p>This is inside Shadow DOM</p>
`;
</script>
</body>
</html>