现在的模型越来越大,动辄几B甚至几百B。但是显卡显存大小根本无法支撑训练推理。例如,一块RTX2090的10G显存,光把模型加载上去,就会OOM,更别提后面的训练优化。
作为传统pytorch Dataparallel的一种替代,DeepSpeed的目标,就是为了能够让亿万参数量的模型,能够在自己个人的工作服务器上进行训练推理。DeepSpeed是微软推出的大规模模型分布式训练的工具,主要实现了ZeRO并行训练算法。
本文旨在简要地介绍Deepspeed进行大规模模型训练的核心理念,以及最基本的使用方法。更多内容,笔者强烈建议阅读HuggingFace Transformer官网对于DeepSpeed的教程:
Transformer DeepSpeed Integration
原始文档链接:DeepSpeed Integration (huggingface.co)
一、DeepSpeed核心思想
DeepSpeed的核心就在于,GPU显存不够,CPU内存来凑。
比方说,我们只有一张10GB的GPU,那么我们很可能需要借助80GB的CPU,才能够训练一个大模型。
看一下官网对于这个理念的描述:
Why would you want to use DeepSpeed with just one GPU?
- It has a ZeRO-offload feature which can delegate some computations and memory to the host’s CPU and RAM, and thus leave more GPU resources for model’s needs - e.g. larger batch size, or enabling a fitting of a very big model which normally won’t fit.
- It provides a smart GPU memory management system, that minimizes memory fragmentation, which again allows you to fit bigger models and data batches.
具体点说,DeepSpeed将当前时刻,训练模型用不到的参数,缓存到CPU中,等到要用到了,再从CPU挪到GPU。这里的“参数”,不仅指的是模型参数,还指optimizer、梯度等。
越多的参数挪到CPU上,GPU的负担就越小;但随之的代价就是,更为频繁的CPU,GPU交互,极大增加了训练推理的时间开销。因此,DeepSpeed使用的一个核心要义是,时间开销和显存占用的权衡。
- Optimizer state partitioning (ZeRO stage 1)
- Gradient partitioning (ZeRO stage 2)
- Parameter partitioning (ZeRO stage 3)
- Custom mixed precision training handling
- A range of fast CUDA-extension-based optimizers
- ZeRO-Offload to CPU and NVMe
DeepSpeed的ZeRO config文件就可以分为如下几类:
ZeRO Stage 1: 划分optimizer states。优化器参数被划分到多个memory上,每个momoey上的进程只负责更新它自己那部分参数。ZeRO Stage 2: 划分gradient。每个memory,只保留它分配到的optimizer state所对应的梯度。这很合理,因为梯度和optimizer是紧密联系在一起的。只知道梯度,不知道optimizer state,是没有办法优化模型参数的。ZeRO Stage 3: 划分模型参数,或者说,不同的layer. ZeRO-3会在forward和backward的时候,自动将模型参数分配到多个memory。
由于ZeRO-1只分配optimizer states(参数量很小),实际使用时,一般只会考虑ZeRO-2和ZeRO-3。
二、DeepSpeed的使用
运行方法
使用DeepSpeed之后,你的命令行看起来就会像下面这样:
deepspeed --master_port 9900 --num_gpus=2 run_s2s.py \
--deepspeed ds_config.json
--master_port:端口号。最好显示指定,默认为9900,可能会被占用(i.e., 跑了多个DeepSpeed进程)。--num_gpus: GPU数目,默认会使用当前所见的所有GPU。--deepspeed: 提供的config文件,用来指定许多DeepSpeed的重要参数。
使用DeepSpeed的一个核心要点,就在于写一个config文件(可以是.json,也可以是类json格式的配置文件),在这个配置文件中,你可以指定你想要的参数,例如,权衡时间和显存 (前文所提到的,这是一个很重要的权衡)。因此,上面几个参数里,最重要的便是--deepspeed,即你提供的config文件,即ZeRO。这也是本文接下来要重点介绍的。
# 1.单卡的使用方法
deepspeed --num_gpus=1 examples/pytorch/translation/run_translation.py ...# 单卡,并指定对应的GPU
deepspeed --include localhost:1 examples/pytorch/translation/run_translation.py ...
# 2.多GPU的使用方法1
torch.distributed.run --nproc_per_node=2 your_program.py <normal cl args> --deepspeed ds_config.json# 多GPU的使用方法2
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
# 3.多节点多卡方法1,需要在多个节点上手动启动
python -m torch.distributed.run --nproc_per_node=8 --nnode=2 --node_rank=0 --master_addr=hostname1 --master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json# 多节点多卡方法2,需要创建一个 hostfile 文件,只需在一个节点上启动
hostname1 slots=8
hostname2 slots=8
# 然后运行
deepspeed --num_gpus 8 --num_nodes 2 --hostfile hostfile --master_addr hostname1 --master_port=9901 your_program.py <normal cl args> --deepspeed ds_config.json
# 在SLURM上运行,略,参见原始文档
# 在jupyter中运行,略,参见原始文档为什么单卡的情况,也可以使用deepspeed?
- 使用ZeRO-offload,将部分数据offload到CPU,降低对显存的需求
- 提供了对显存的管理,减少显存中的碎片
传递deepspeed参数
TrainingArguments(..., deepspeed="/path/to/ds_config.json")
# or
ds_config_dict = dict(scheduler=scheduler_params, optimizer=optimizer_params)
TrainingArguments(..., deepspeed=ds_config_dict)2.1 ZeRO Stage 2
结合官网的介绍,笔者提供一个常用的ZeRO-stage-2的config文件:
{"bfloat16": {"enabled": "auto"},"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto"}},"zero_optimization": {"stage": 2,"offload_optimizer": {"device": "cpu","pin_memory": true},"allgather_partitions": true,"allgather_bucket_size": 2e8,"overlap_comm": true,"reduce_scatter": true,"reduce_bucket_size": 2e8,"contiguous_gradients": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","steps_per_print": 1e5
}overlap_comm:控制是否使用通信与计算的重叠。当设置为True时,DeepSpeed将在梯度计算时尝试并行执行梯度通信。可以有效地减少通信时间,从而加速整个训练过程。简单地理解,它控制着多个memory上进程之间通信的buffer的大小。这个值越大,进程之间通信越快,模型训练速度也会提升,但相应的显存占用也会变大;反之亦然。因此,overlap_comm也是一个需要进行一定权衡的参数。allgather_bucket_size:用于控制Allgather操作的分桶大小。Allgather操作是指在分布式训练中,每个进程收集其他所有进程的张量,并将这些张量按顺序拼接起来。通过将张量划分为较小的桶(buckets),可以在通信过程中更高效地传输数据。allgather_bucket_size值越大,每个桶的大小越大,通信操作可能会变得更快,但也需要更多的内存来存储中间结果。合适的桶大小要根据实际情况调整。reduce_bucket_size:类似于allgather_bucket_size,用于控制Allreduce操作的分桶大小。Allreduce操作是将所有进程的某个张量进行规约(例如求和),并将结果广播回所有进程。通过将张量划分为较小的桶,可以更高效地传输数据。reduce_bucket_size值越大,每个桶的大小越大,通信操作可能会变得更快,但同时也需要更多的内存来存储中间结果。合适的桶大小需要根据实际情况进行调整。offload_optimizer:如上述所示,我们将其”device“设置成了cpu,DeepSpeed就会按照之前提到过的ZeRO操作,在训练过程中,将优化器状态分配到cpu上。从而降低单张GPU的memory占用。
overlap_comm使用的是allgather_bucket_size和reduce_bucket_size值的4.5倍。如果它们被设置为5e8,需要9GB显存(5e8 x 2Bytes x 2 x 4.5)。如果内存大小是8GB或更小,需要将这些参数减少到约2e8,从而避免OOM,这需要3.6GB显存。如果在大容量GPU上也出现OOM,也需要做同样的调整。
在deepspeed==0.4.4中新增了 round_robin_gradients 选项,可以并行化CPU的offload。当梯度累积的步数增加,或者GPU数量增加时,会有更好的性能优势。
关于auto
我们可以发现,上述大量参数被设置为auto。由于DeepSpeed目前已经被集成到了HuggingFace Transformer框架。而DeepSpeed的很多参数,和Transformer的Trainer参数设置是一模一样的,例如,"optimizer","scheduler"。因此,官方推荐将很多常用的模型训练参数,设置为auto,在使用Trainer进行训练的时候,这些值都会自动更新为Trainer中的设置,或者帮你自动计算。
当然,你也可以自己设置,但一定要确保和Trainer中的设置一样。因为,如果设置错误,DeepSpeed还是会正常运行,不会立即报错。
大多数情况下,你只需要注意DeepSpedd-specific参数(如,offload),其他和Trainner重复的参数项,强烈建议设置成auto。而具体这些每一项参数的含义,和值的设置,请参见官网的详细介绍。
总而言之,由于设置了auto,上述config,能够适配大多数的Transformer框架stage-2的use-cases。
2.2 ZeRO Stage 3
{"bfloat16": {"enabled": false},"fp16": {"enabled": "auto","loss_scale": 0,"loss_scale_window": 1000,"initial_scale_power": 16,"hysteresis": 2,"min_loss_scale": 1},"optimizer": {"type": "AdamW","params": {"lr": "auto","betas": "auto","eps": "auto","weight_decay": "auto"}},"scheduler": {"type": "WarmupLR","params": {"warmup_min_lr": "auto","warmup_max_lr": "auto","warmup_num_steps": "auto"}},"zero_optimization": {"stage": 3,"offload_optimizer": {"device": "cpu","pin_memory": true},"offload_param": {"device": "cpu","pin_memory": true},"overlap_comm": true,"contiguous_gradients": true,"sub_group_size": 1e9,"reduce_bucket_size": "auto","stage3_prefetch_bucket_size": "auto","stage3_param_persistence_threshold": "auto","stage3_max_live_parameters": 1e9,"stage3_max_reuse_distance": 1e9,"stage3_gather_fp16_weights_on_model_save": true},"gradient_accumulation_steps": "auto","gradient_clipping": "auto","steps_per_print": 1e5,"train_batch_size": "auto","train_micro_batch_size_per_gpu": "auto","wall_clock_breakdown": false
}可以看到,除了和stage2一样,有offload_optimizer参数之外,stage3还有一个offload_param参数。即,将模型参数进行划分。
stage3_max_live_parameters是保留在 GPU 上的完整参数数量的上限。stage3_max_reuse_distance是指将来何时再次使用参数的指标,从而决定是丢弃参数还是保留参数。 如果一个参数在不久的将来要再次使用(小于 stage3_max_reuse_distance),可以保留以减少通信开销。 使用activation checkpointing时,这一点非常有用。- 如果遇到 OOM,可以减少
stage3_max_live_parameters和stage3_max_reuse_distance。 除非正在使用activation checkpointing,否则它们对性能的影响应该很小。 1e9 会消耗 ~2GB。 内存由stage3_max_live_parameters和stage3_max_reuse_distance共享,所以不是相加的,一共 2GB。 stage3_gather_16bit_weights_on_model_save在保存模型时启用模型 fp16 权重合并。 对大型模型和多GPU,在内存和速度方面都是一项昂贵的操作。 如果打算恢复训练,目前需要使用它。 未来的更新将消除此限制。sub_group_size控制在optimizer steps中更新参数的粒度。 参数被分组到sub_group_size的桶中,每个桶一次更新一个。 当与 ZeRO-Infinity 中的 NVMe offload一起使用时,sub_group_size控制模型状态在optimizer steps期间从 NVMe 移入和移出 CPU 内存的粒度。 防止超大模型耗尽 CPU 内存。不使用NVMe offload时,使其保持默认值。出现OOM时,减小sub_group_size。当优化器迭代很慢时,可以增大sub_group_size。- ZeRO-3 中未使用
allgather_partitions、allgather_bucket_size和reduce_scatter配置参数
一样的道理,这些值很多都可以用来控制stage-3的显存占用和训练效率(e.g.,sub_group_size);同时,有一些参数也可以设置为auto,让Trainer去决定值(e.g., reduce_bucket_size,stage3_prefetch_bucket_size,stage3_param_persistence_threshold).
对于这些参数的具体描述,和值的trade-off,详见官网 ZeRO-3 Config
一样的道理,上述config文件,也能够适配绝大多是use-cases。一些stage-3-specific的参数可能需要额外注意一下。具体而言,推荐阅读官方文档。
2.3 ZeRO Infinity
除了stage2和3之外,这里简单介绍一下ZeRO-Infinity。
ZeRO-Infinity可以看成是stage-3的进阶版本,需要依赖于NVMe的支持。他可以offload所有模型参数状态到CPU以及NVMe上。得益于NMVe协议,除了使用CPU内存之外,ZeRO可以额外利用SSD(固态),从而极大地节约了memory开销,加速了通信速度。
官网对于ZeRO-Infinity的详细介绍:
DeepSpeed官方教程 :
ZeRO-Infinity has all of the savings of ZeRO-Offload, plus is able to offload more the model weights and has more effective bandwidth utilization and overlapping of computation and communication.
HuggingFace官网:
It allows for training incredibly large models by extending GPU and CPU memory with NVMe memory. Thanks to smart partitioning and tiling algorithms each GPU needs to send and receive very small amounts of data during offloading so modern NVMe proved to be fit to allow for an even larger total memory pool available to your training process. ZeRO-Infinity requires ZeRO-3 enabled.
NVMe Support
- ZeRO-Infinity 需要使用 ZeRO-3
- ZeRO-3 会比 ZeRO-2 慢很多。使用以下策略,可以使得ZeRO-3 的速度更接近ZeRO-2
- 将
stage3_param_persistence_threshold参数设置的很大,比如6 * hidden_size * hidden_size - 将
offload_params参数关闭(可以极大改善性能)
- 将
2.4 如何选择不同的Zero stage和offload
- 从左到右,越来越慢
Stage 0 (DDP) > Stage 1 > Stage 2 > Stage 2 + offload > Stage 3 > Stage 3 + offloads - 从左到右,所需GPU显存越来越少
Stage 0 (DDP) < Stage 1 < Stage 2 < Stage 2 + offload < Stage 3 < Stage 3 + offloads
三、调参步骤
- 将
batch_size设置为1,通过梯度累积实现任意的有效batch_size - 如果OOM则,设置
--gradient_checkpointing 1(HF Trainer),或者model.gradient_checkpointing_enable() - 如果OOM则,尝试ZeRO stage 2
- 如果OOM则,尝试ZeRO stage 2 +
offload_optimizer - 如果OOM则,尝试ZeRO stage 3
- 如果OOM则,尝试offload_param到CPU
- 如果OOM则,尝试offload_optimizer到CPU
- 如果OOM则,尝试降低一些默认参数。比如使用generate时,减小beam search的搜索范围
- 如果OOM则,使用混合精度训练,在Ampere的GPU上使用bf16,在旧版本GPU上使用fp16
- 如果仍然OOM,则使用ZeRO-Infinity ,使用offload_param和offload_optimizer到NVME
- 一旦使用batch_size=1时,没有导致OOM,测量此时的有效吞吐量,然后尽可能增大batch_size
- 开始优化参数,可以关闭offload参数,或者降低ZeRO stage,然后调整batch_size,然后继续测量吞吐量,直到性能比较满意(调参可以增加66%的性能)
一些其他建议
- 如果训模型from scratch,hidden size最好可以被16整除
- batch size最好可以被2整除
四、优化器和调度器
- 当不使用
offload_optimizer时,可以按照下表,混合使用HF和DS的优化器和迭代器,除了HF Scheduler和DS Optimizer这一种情况。
| Combos | HF Scheduler | DS Scheduler |
|---|---|---|
| HF Optimizer | Yes | Yes |
| DS Optimizer | No | Yes |
4.1 优化器
- 启用 offload_optimizer 时可以使用非 DeepSpeed 的优化器,只要它同时具有 CPU 和 GPU 的实现(LAMB 除外)。
- DeepSpeed 的主要优化器是 Adam、AdamW、OneBitAdam 和 Lamb。 这些已通过 ZeRO 进行了彻底测试,建议使用。
- 如果没有在配置文件中配置优化器参数,Trainer 将自动将其设置为 AdamW,并将使用命令行参数的默认值:--learning_rate、--adam_beta1、--adam_beta2、 --adam_epsilon 和 --weight_decay。
- 与 AdamW 类似,可以配置其他官方支持的优化器。 请记住,它们可能具有不同的配置值。 例如 对于 Adam,需要将 weight_decay 设置为 0.01 左右。
- 此外,offload在与 Deepspeed 的 CPU Adam 优化器一起使用时效果最佳。 如果想对offload使用不同的优化器,deepspeed==0.8.3 以后的版本,还需要添加:
{"zero_force_ds_cpu_optimizer": false
}4.2 调度器
- DeepSpeed 支持 LRRangeTest、OneCycle、WarmupLR 和 WarmupDecayLR 学习率调度器。
- Transformers和DeepSpeed中调度器的overlap
WarmupLR 使用 --lr_scheduler_type constant_with_warmup
WarmupDecayLR 使用 --lr_scheduler_type linear五、训练精度
- 由于 fp16 混合精度大大减少了内存需求,并可以实现更快的速度,因此只有在在此训练模式下表现不佳时,才考虑不使用混合精度训练。 通常,当模型未在 fp16 混合精度中进行预训练时,会出现这种情况(例如,使用 bf16 预训练的模型)。 这样的模型可能会溢出,导致loss为NaN。 如果是这种情况,使用完整的 fp32 模式。
- 如果是基于 Ampere 架构的 GPU,pytorch 1.7 及更高版本将自动切换为使用更高效的 tf32 格式进行某些操作,但结果仍将采用 fp32。
- 使用 Trainer,可以使用 --tf32 启用它,或使用 --tf32 0 或 --no_tf32 禁用它。 PyTorch 默认值是使用tf32。
自动混合精度
- fp16
- 可以使用 pytorch-like AMP 方式或者 apex-like 方式
- 使用
--fp16--fp16_backend amp或--fp16_full_eval命令行参数时启用此模式
- bf16
- 使用
--bf16or--bf16_full_eval命令行参数时启用此模式
- 使用
NCCL
- 通讯会采用一种单独的数据类型
- 默认情况下,半精度训练使用 fp16 作为reduction操作的默认值
- 可以增加一个小的开销并确保reduction将使用 fp32 作为累积数据类型
{"communication_data_type": "fp32"
}apex
- Apex 是一个在 PyTorch 深度学习框架下用于加速训练和提高性能的库。Apex 提供了混合精度训练、分布式训练和内存优化等功能,帮助用户提高训练速度、扩展训练规模以及优化 GPU 资源利用率。
- 使用
--fp16、--fp16_backend apex、--fp16_opt_level 01命令行参数时启用此模式
"amp": {"enabled": "auto","opt_level": "auto"
}六、获取模型参数
- deepspeed会在优化器参数中存储模型的主参数,存储在
global_step*/*optim_states.pt文件中,数据类型为fp32。因此,想要从checkpoint中恢复训练,则保持默认即可 - 如果模型是在ZeRO-2模式下保存的,模型参数会以fp16的形式存储在
pytorch_model.bin中 - 如果模型是在ZeRO-3模式下保存的,需要如下所示设置参数,否则pytorch_model.bin将不会被创建
{"zero_optimization": {"stage3_gather_16bit_weights_on_model_save": true}
}- 在线fp32权重恢复(需要很多的RAM)略
- 离线获取fp32权重
python zero_to_fp32.py . pytorch_model.bin七、模型推理
除了模型训练,有时候模型太大,连预测推理都有可能炸显存。
ZeRO 推理使用与 ZeRO-3 训练相同的配置。您只需要不需要优化器和调度器部分。实际上,如果要与训练共享相同的配置文件,则可以将它们留在配置文件中。它们将被忽略。
具体参考:ZeRO-Inference
只有ZeRO-3是有意义的,因为可以将参数分片:
deepspeed --num_gpus=2 your_program.py <normal cl args> --do_eval --deepspeed ds_config.jsonDeepspeed-Inference已经可用,使用 DeepSpeed 和 Accelerate 进行超快 BLOOM 模型推理
八、 内存估计
如之前多次强调的,DeepSpeed使用过程中的一个难点,就在于时间和空间的权衡。
分配更多参数到CPU上,虽然能够降低显存开销,但是也会极大地提升时间开销。
DeepSpeed提供了一段简单的memory估算代码:
from transformers import AutoModel
from deepspeed.runtime.zero.stage3 import estimate_zero3_model_states_mem_needs_all_live## specify the model you want to train on your device
model = AutoModel.from_pretrained("t5-large")
## estimate the memory cost (both CPU and GPU)
estimate_zero3_model_states_mem_needs_all_live(model, num_gpus_per_node=1, num_nodes=1)
以T5-large,只使用一块GPU为例,使用DeepSpeed的开销将会如下:
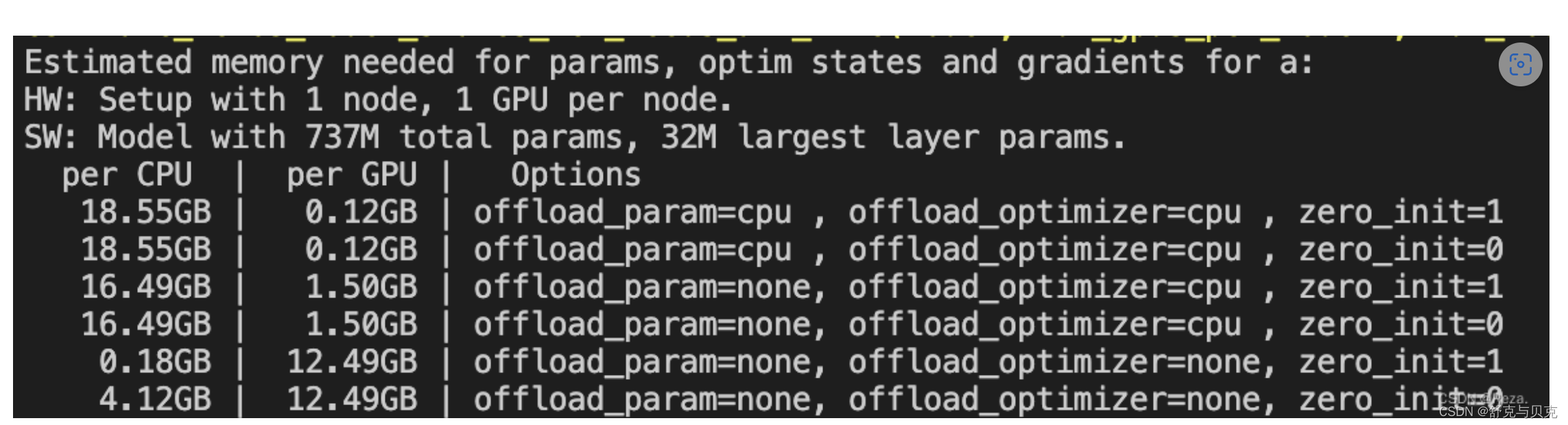
如上,如果不用stage2和stage3(最下面那两行),训练T5-large需要一张显存至少为12.49GB的显卡(考虑到很多其他的缓存变量,还有你的batch_size,实际上可能需要24GB大小的卡)。而在相继使用了stage2和3之后,显存开销被极大地降低,转而CPU内存消耗显著提升,模型训练时间开销也相应地增大。
建议:
在使用DeepSpeed之前,先使用上述代码,大概估计一下显存消耗,决定使用的GPU数目,以及ZeRO-stage。
原则是,能直接多卡训练,就不要用ZeRO;能用ZeRO-2就不要用ZeRO-3.
具体参见官网:Memory Requirements
九、其他补充
首先是stage 2,也就是只把optimizer放到cpu上。下面是使用前后的GPU显存占用和训练速度对比:
- GPU显存:
20513MB =>17349MiB - 训练速度 (由
tqdm估计):1.3iter/s =>0.77iter/s
可以明显看到,GPU的显存占用有了明显降低,但是训练速度也变慢了。以笔者当前的使用体感来说,deepspeed并没有带来什么收益。
笔者的机器配有24000MB的显卡,batch_size为2时,占用20513MB;而DeepSpeed仅仅帮助笔者空出了3000MB的显存,还是完全不够增加batch_size, 导致笔者总训练时长变长。
因此,DeepSpeed或许仅适用于显存极度短缺(i.e., 模型大到 batch_size == 1也跑不了)的情况;亦或是,使用DeepSpped节省下来的显存,刚好够支持更大的batch_size。否则,像笔者当前这种情况下,使用DeepSpeed只会增加时间开销,并没有其他益处。
此后,笔者还尝试使用stage 3,但是速度极其缓慢。一个原先需要6h的训练过程,用了DeepSpeed stage3之后,运行了2天2夜,也没有结束的迹象。无奈笔者只好终止测试。
此外,在使用DeepSpeed stage2时,由于分配了模型参数到多个设备上,console里面也看不到任何输出信息(但是GPU还是在呼呼响,utility也为100%),让人都不知道程序的运行进度,可以说对用户非常不友好了。
一些常见问题
由于DeepSpeed会通过占用CPU内存来减缓GPU的开销,当系统CPU不够的时候,DeepSpeed进程就会自动被系统停止,造成没有任何报错,DeepSpeed无法启动的现象。建议先用上文介绍的estimation估计一下CPU内存占用,然后用free -h查看一下机器的CPU内存空余量,来判断能否使用DeepSpeed。
另外,还有可能因为训练精度问题,出现loss为NAN的情况。详见:Troubleshooting.
- 启动时,进程被杀死,并且没有打印出traceback:CPU内存不够
- loss是NaN:训练时用的是bf16,使用时是fp16。常常发生于google在TPU上train的模型,如T5。此时需要使用fp32或者bf16。
在Transformers中集成DeepSpeed - 知乎 (zhihu.com)
DeepSpeed使用指南(简略版) (betheme.net)
deepspeed入门教程 - 知乎 (zhihu.com)