文本文件如下:
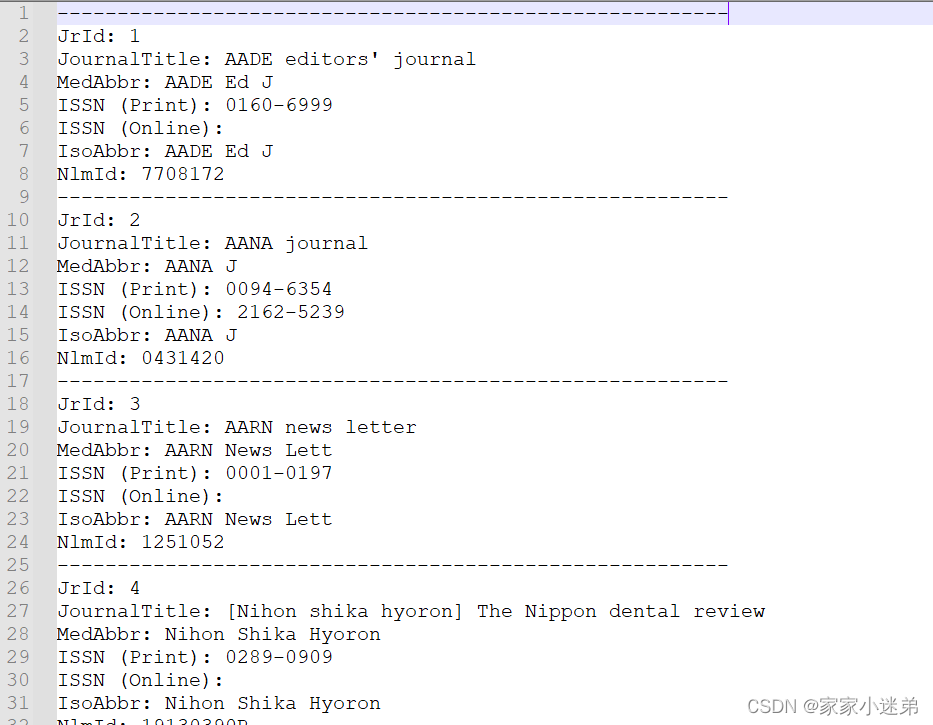
现在不好处理,打算将其转换为excel,其中通过冒号分割:line.split(":")
main方法如下:
public static void main(String[] args) {String textFilePath = "D:\\zoom\\期刊\\J_Medline\\J_Medline"; // 替换为你的文本文件路径String excelFilePath = "D:\\zoom\\期刊\\J_Medline\\output1.xlsx"; // 生成的 Excel 文件路径List<String[]> data = new ArrayList<>();try (BufferedReader br = new BufferedReader(new FileReader(textFilePath))) {String line;while ((line = br.readLine()) != null) {String[] fields = line.split(":");String strip = StringUtils.strip(Arrays.toString(fields), "[]");if(!strip.equals("--------------------------------------------------------")){data.add(fields);}}} catch (IOException e) {e.printStackTrace();}try (Workbook workbook = new XSSFWorkbook()) {Sheet sheet = workbook.createSheet("Sheet1");int rowNum = 0;for (String[] rowData : data) {Row row = sheet.createRow(rowNum++);int colNum = 0;for (String field : rowData) {Cell cell = row.createCell(colNum++);cell.setCellValue(field);}}try (FileOutputStream outputStream = new FileOutputStream(excelFilePath)) {workbook.write(outputStream);System.out.println("Excel file created successfully: " + excelFilePath);}} catch (IOException e) {e.printStackTrace();}}
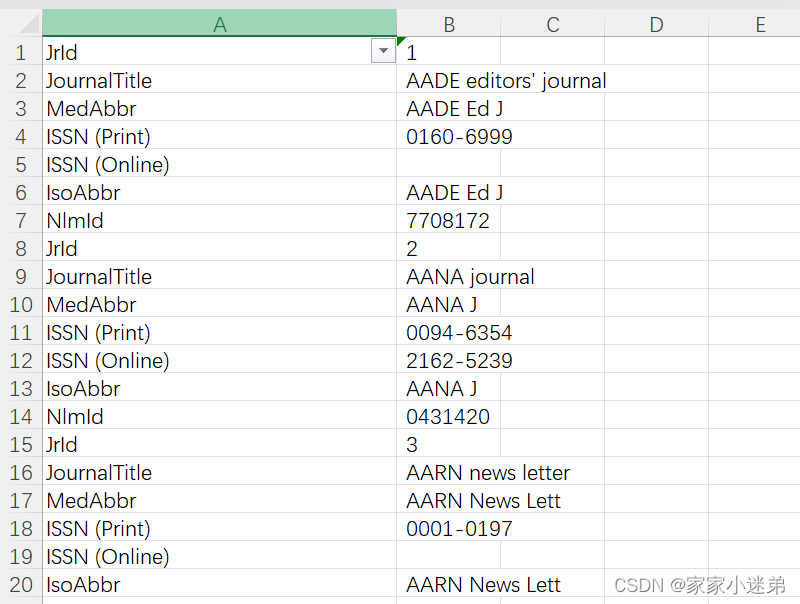
其中去掉了横线----------------------------------------,结果如下:
相关依赖如下:
import org.apache.commons.lang3.StringUtils;
import org.apache.poi.ss.usermodel.Cell;
import org.apache.poi.ss.usermodel.Row;
import org.apache.poi.ss.usermodel.Sheet;
import org.apache.poi.ss.usermodel.Workbook;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;import java.io.BufferedReader;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
<dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>4.1.2</version></dependency><dependency><groupId>org.apache.commons</groupId><artifactId>commons-lang3</artifactId><version>3.12.0</version></dependency>