
在游戏中,火焰是一种常见的特效。通常来讲火焰特效通过粒子系统的方式实现的相对较多,本文将通过Shader Graph的方式来实现一种不同的火焰效果。
那么怎么实现呢
首先创建一个名为Fire的Shader Graph文件,然后创建一个名为M_Fire的材质球。

基础的贴图显示
老规矩,还是参考UV滚动动画的基础资源显示部分的节点,建立最基本的Texture 2D类型的参数命名为MainTex。这里需要用到一个制作好的图片资源用来做遮挡,节点如下。

火焰的制作
遮罩的实现
制作火焰时,我们需要对中心处进行遮罩的实现,首先可以对我们预先准备的图片资源进行一个One Minus的操作,来获取中心部位是遮罩的效果,然后通过一个Power节点用一个名为Radius的变量来控制中心部分遮罩的范围,再用Saturate节点进行一个0-1的Clamp取值。

火焰的实现
火焰我们需要用到两种噪声节点,一个是Voronoi噪声(细胞状的),另一个是Gradient Noise(模拟随机性)。
Voronoi噪声部分
首先使用Voronoi噪声节点对其进行One Minus的操作获取像细胞球一样的效果,节点如下。

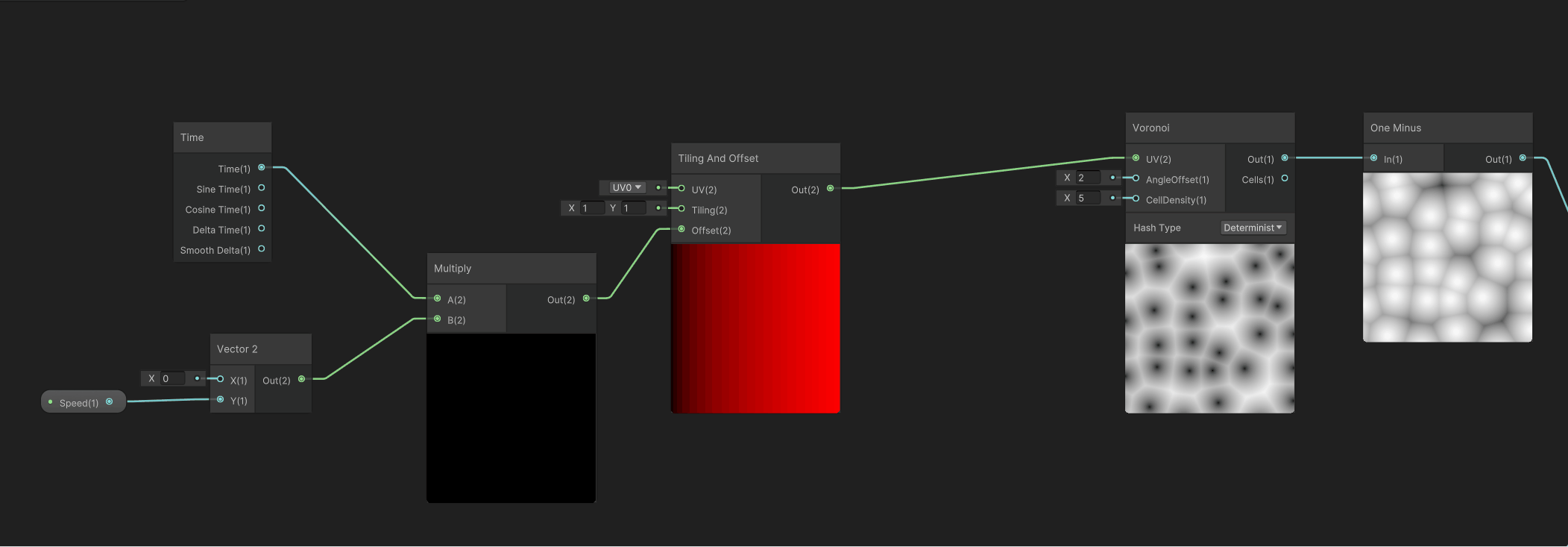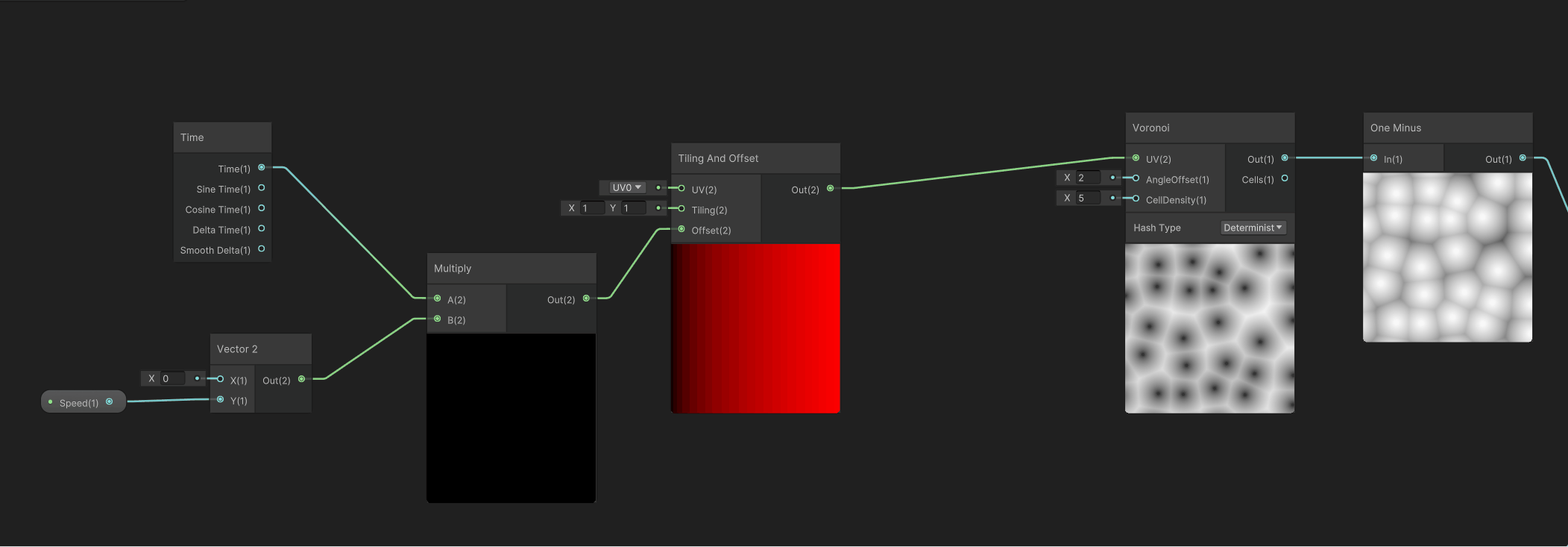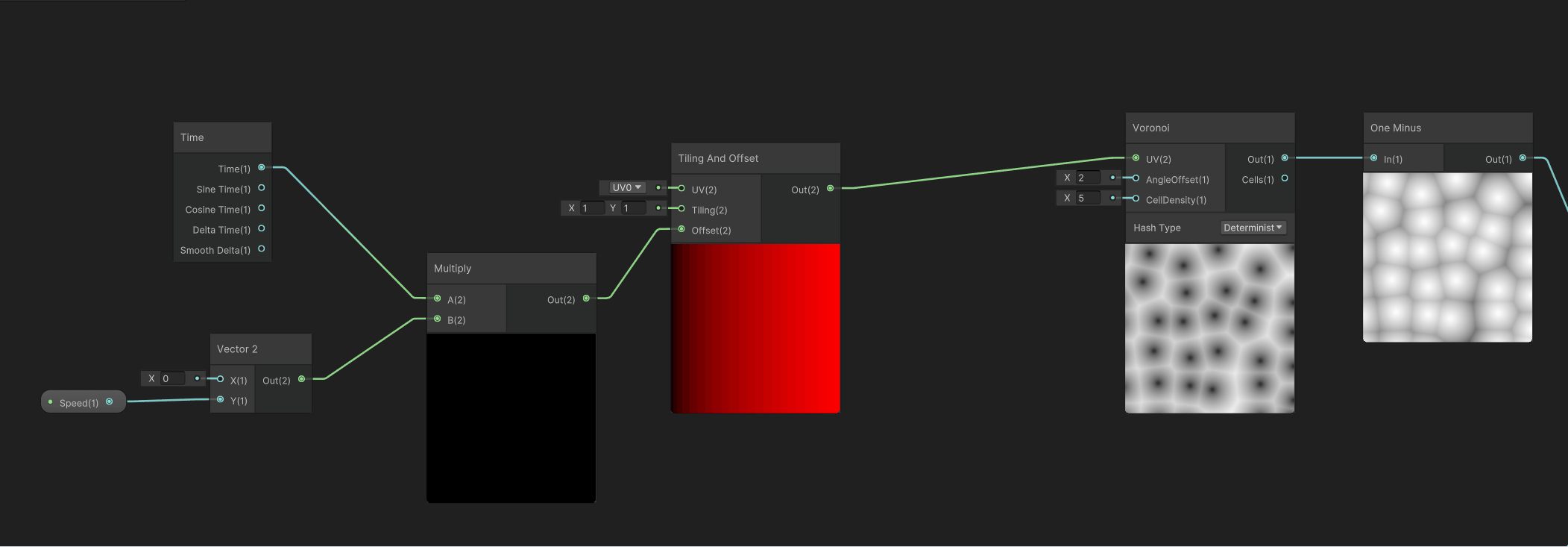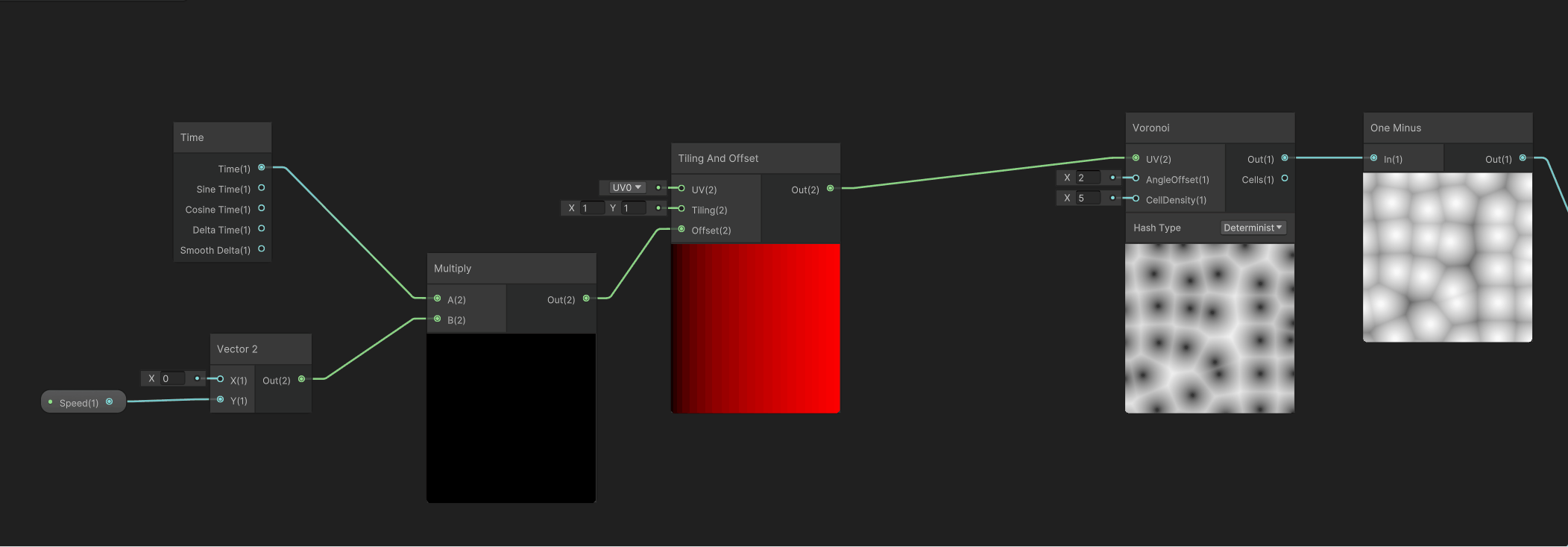
然后需要给这个Voronoi噪声增加一个Y轴向上的移动,需要用到Time时间节点、控制Y轴移动速度的Speed变量、以及控制UV移动的Tilling And Offset节点,组合之后如下。

然后将这个Y轴向上的移动输出的UV给到Voronoi节点的UV输入节点,让细胞噪声有向上的移动,如下。
Gradient Noise部分
同样创建一个Float类型的Scale变量,用来控制Gradient Noise的噪声范围。然后用Voronois的同一个Time时间节点的输出来做一个Y轴向上的动画,创建一个单独的Float类型的GradientNoiseSpeed来控制移动的速度,同样需要用到Vector2节点和Tilling And Offset节点,组合连接如下。

最后将两部分的结果用乘法Multiply节点进行组合获得一个类似玻璃网格的效果,如下所示。

底部遮罩
将两部分融合后,需要做一个底部的遮罩来模拟火焰从下到上的一个渐变效果。既然是由下到上,那么就会用到Y轴的数据,因此需要一个UV节点加上一个Split节点来获取Y轴的数据,然后用一个Power节点来控制Y轴遮罩的基础范围(如果有需要也可以将这个参数开放出来进行可控),最后用一个乘法节点乘以一个Float型的Mask变量来控制遮罩的强弱,节点如下。

将遮罩的结果输出与之前两个噪声节点的输出进行相乘,来获得底部有遮罩的数据,节点如下。

最终的火焰效果
将之前准备的圆形遮罩范围与Y轴噪声节点的动画节点进行叠加,然后对其结果进行0-1的Clamp操作(Saturate,因为叠加会使结果大于1)。最后关键的一部就是对其进行One Minus的操作,这样中心的黑色部分会变成白色圆球,圆球周边的白色部分就会变黑色,节点如下。

给火焰加上颜色
然后用一个Lerp节点来给火焰加上颜色,从外焰到内焰,创建两个Color颜色变量,一个为外焰OutsideColor,一个为内焰InsideColor,颜色也可以设为HDR。最后将颜色的输出结果给到Base Color,Alpha则为One Minus黑白部分的输出。

那么最终的火焰效果预览如下所示,在Unity场景里赋予材质球和对应的贴图,调整参数可以做多个不同颜色的火焰,如文章开头所示,大家可以尽情尝试下。




















