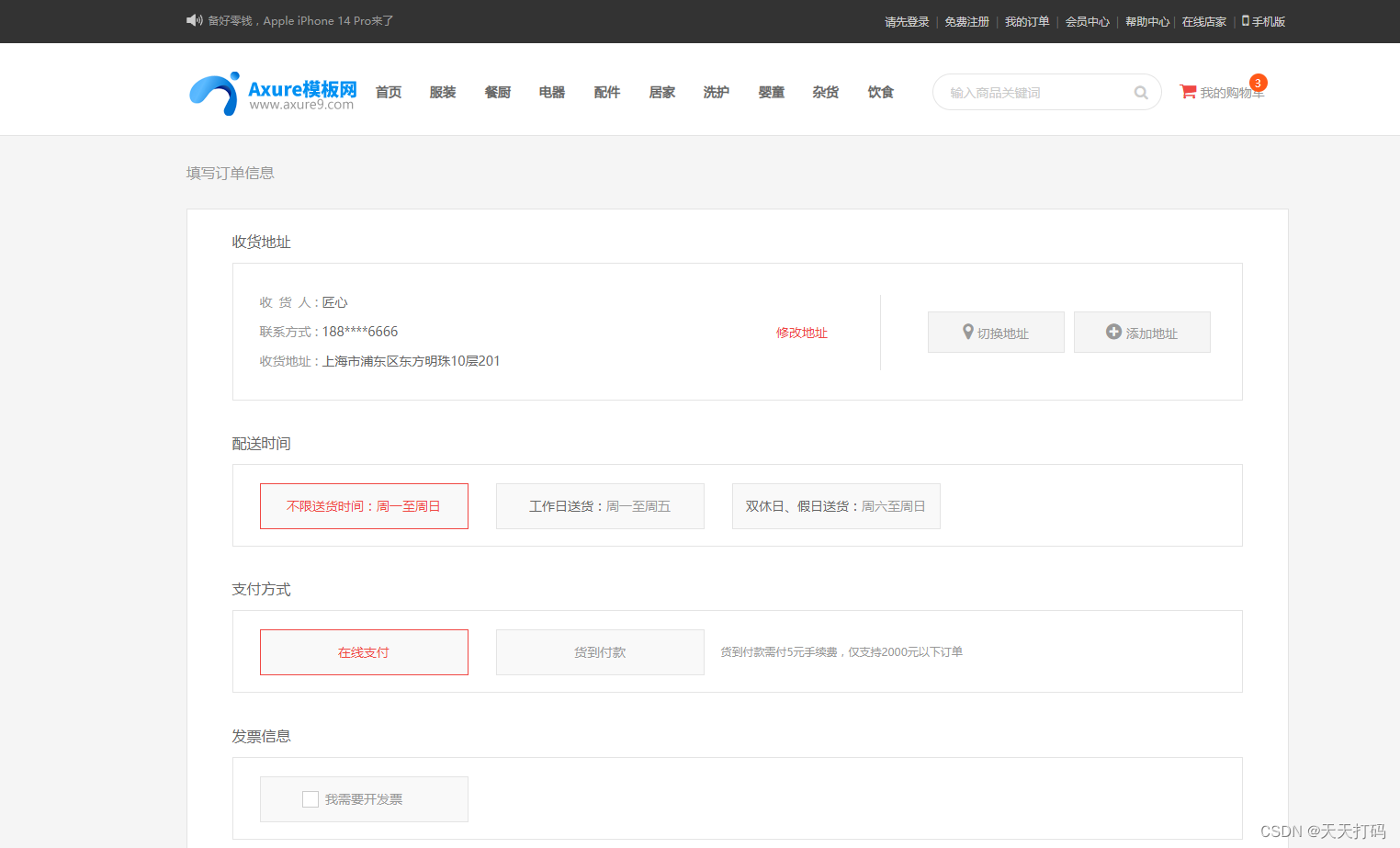
LinkedHashMap实现LRU缓存cache机制,Kotlin
LinkedHashMap的accessOrder=true后,访问LinkedHashMap里面存储的元素,LinkedHashMap就会把该元素移动到最尾部。利用这一点,可以设置一个缓存的上限值,当存入的缓存数理超过上限值后,删掉LinkedHashMap头部元素即可(因为最头部意味着没有被多少使用)。
至于删除最头部的元素,我们自己可以写代码,把最头部(第一个)元素找出来,然后删掉。但是,刚好,LinkedHashMap内部源代码实现有一个函数:
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {return false;}它默认返回false,如果该函数返回true,那么LinkedHashMap就会去删除头部最老的值。在代码中动态判断当前存储的元素数理是否超过缓存上限,超过就返回true,让LinkedHashMap删除最头部(最老的)值。
import java.util.LinkedHashMapclass Lru(initialCapacity: Int,loadFactor: Float,accessOrder: Boolean
) : LinkedHashMap<Int, String>(initialCapacity, loadFactor, accessOrder) {private val CACHE_LIMIT: Int = 3//accessOrder=true改变LinkedHashMap的存储策略constructor() : this(10, 0.75F, true)//如果当前的map尺寸大于缓存上限//删除最老的元素。override fun removeEldestEntry(eldest: MutableMap.MutableEntry<Int, String>?): Boolean {return size > CACHE_LIMIT}
}fun main(args: Array<String>) {val map = Lru()map[1] = "A"map[2] = "B"map[3] = "C"println(map)println("-")//插入D后,最头的A被删除。println("插入D")map[4] = "D"println(map)println("-")//插入E后,最头的B被删除。println("插入E")map[5] = "E"println(map)println("-")println("访问C")println(map[3])println(map)
}特意设置最多缓存3个元素,看代码运行结果:
{1=A, 2=B, 3=C}
-
插入D
{2=B, 3=C, 4=D}
-
插入E
{3=C, 4=D, 5=E}
-
访问C
C
{4=D, 5=E, 3=C}
Java的HashMap与LinkedHashMap异同_zhangphil的博客-CSDN博客一句话概括的说:两者最大的不同就是,HashMap不保证put进去的数据的顺序;而LinkedHashMap则保证put进去的数据的顺序。换句话也就是说,HashMap添加进去的数据顺序和遍历时的数据顺序不一定;而LinkedHashMap则保证添加时数据顺序是什么,遍历时数据顺序是什么。例如,假如在HashMap中依次、顺序添加元素:1,2,3,4,5,在遍历HashMap时输出的顺https://blog.csdn.net/zhangphil/article/details/44115629
基于Java LinkedList,实现Android大数据缓存策略_zhangphil的博客-CSDN博客import java.util.HashMap;import java.util.LinkedList;/* * 基于Java LinkedList,实现Android大数据缓存策略 * 作者:Zhang Phil * 原文出处:http://blog.csdn.net/zhangphil * * 实现原理:原理的模型认为:在LinkedList的头部元素是最旧的缓存数据,在L_android大数据缓存https://blog.csdn.net/zhangphil/article/details/44116885