https://github.com/OpenTalker/SadTalker
开源项目
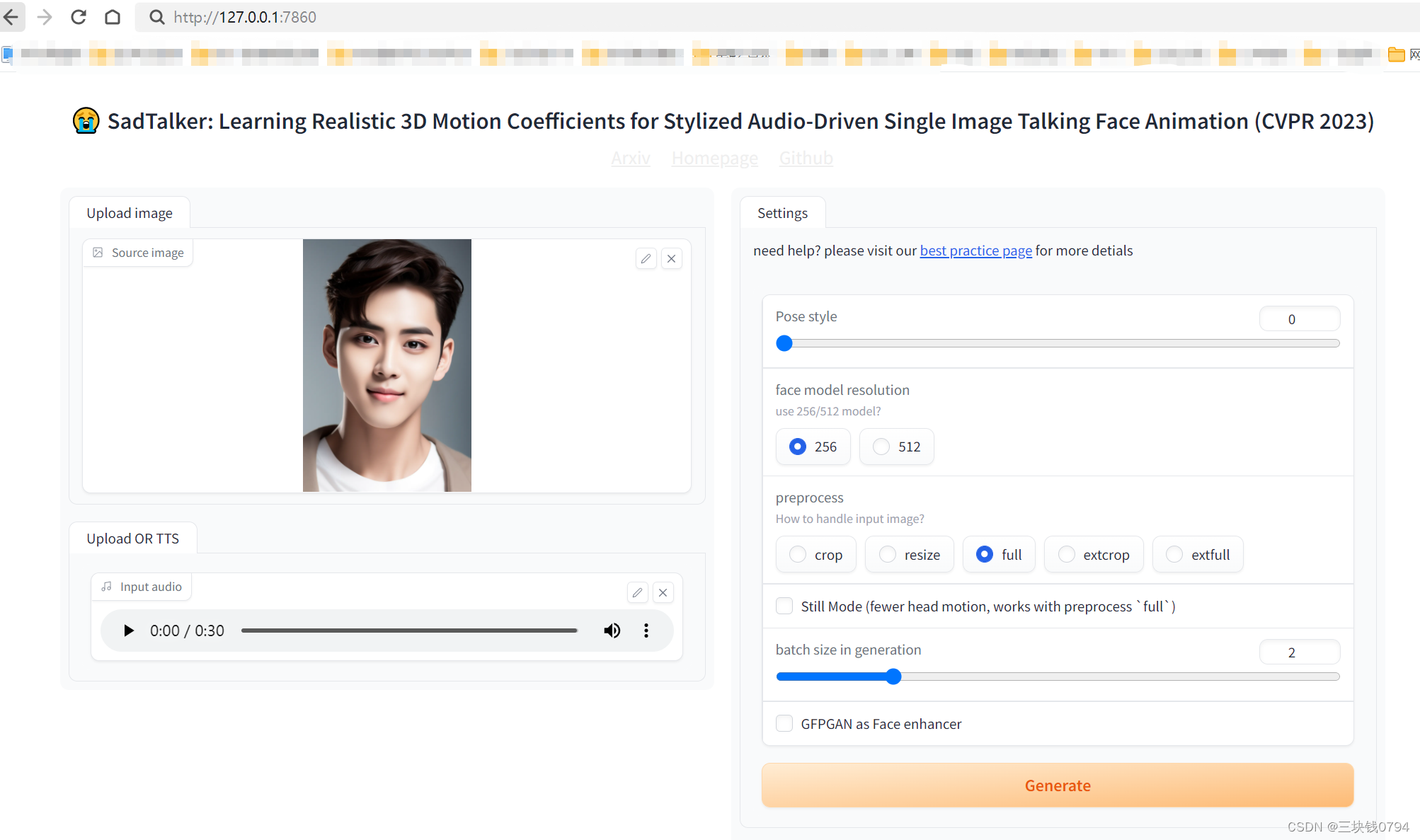
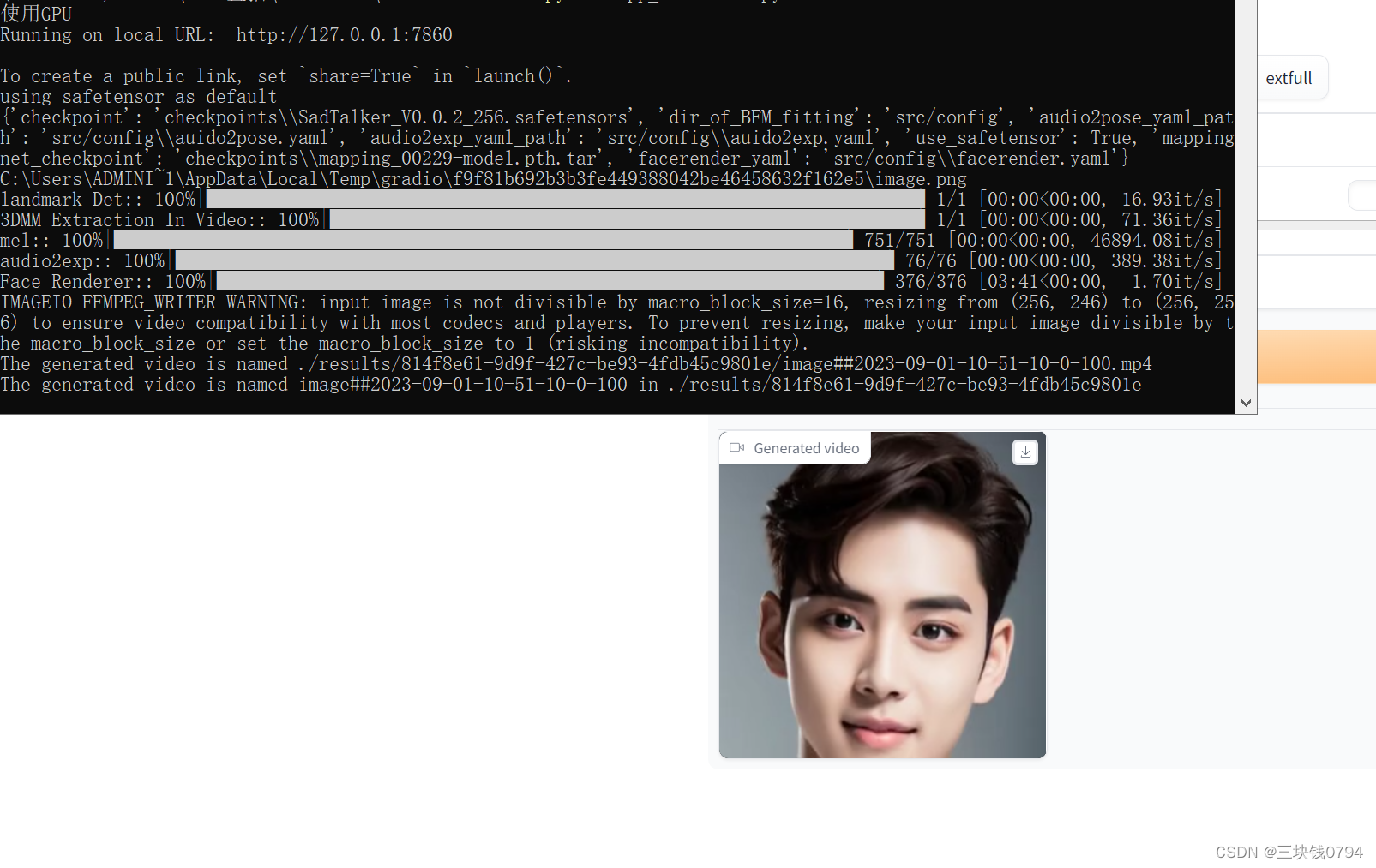
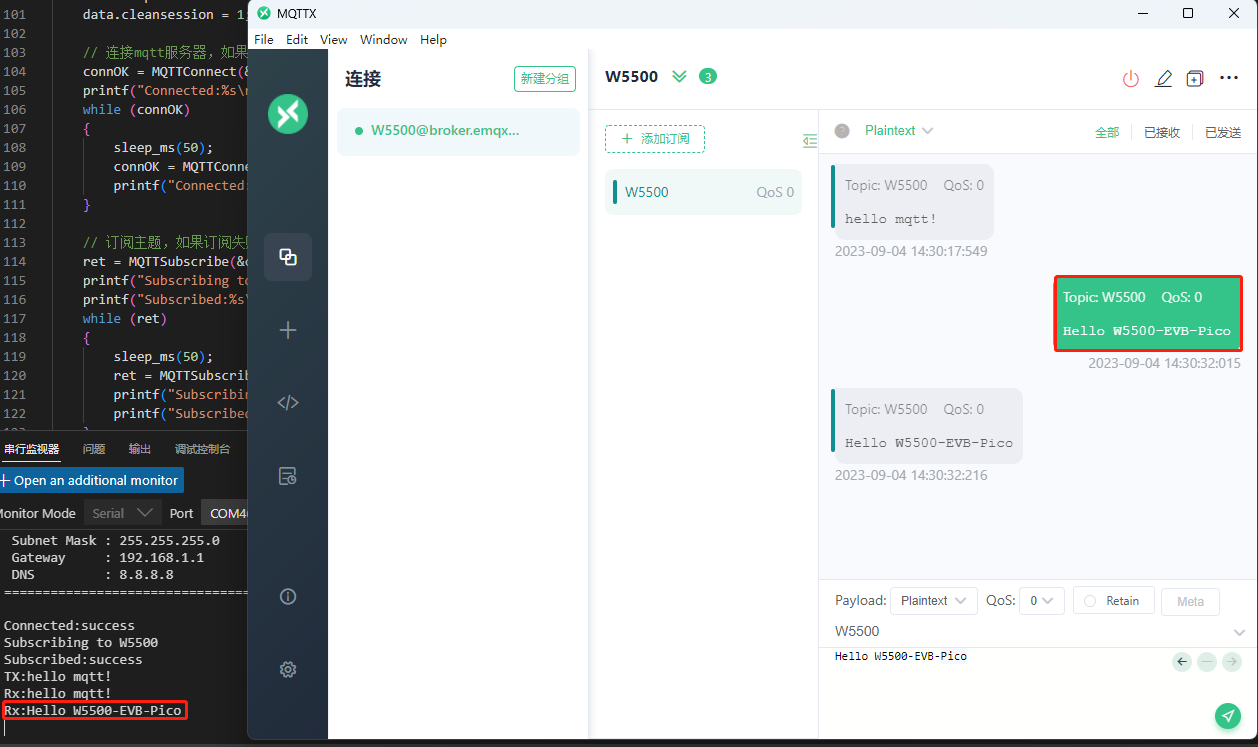
SadTalker模型是一个使用图片与音频文件自动合成人物说话动画的开源模型,我们自己给模型一张图片以及一段音频文件,模型会根据音频文件把传递的图片进行人脸的相应动作,比如张嘴,眨眼,移动头部等动作。
SadTalker,它从音频中生成 3DMM 的 3D 运动系数(头部姿势、表情),并隐式调制一种新颖的 3D 感知面部渲染,用于生成说话的头部运动视频。
检查cuda版本,我这里是11.7
通过终端或者命令行窗口,我们可以使用以下命令来查看CUDA的版本号:
nvcc --version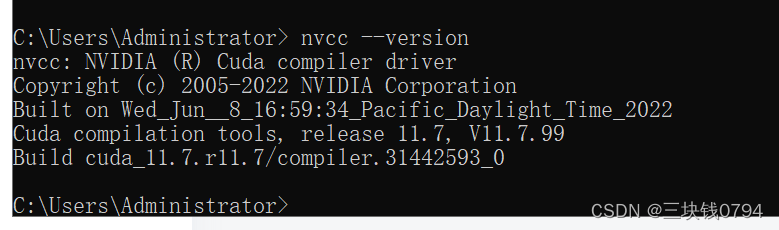
git clone https://github.com/Winfredy/SadTalker.gitcd SadTalker conda create -n sadtalker python=3.8conda activate sadtalker###这里和github 不一样
pip install torch torchvision torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu117conda install ffmpegpip install -r requirements.txt
模型下载
Google Driver: download our pre-trained model from this link (main checkpoints) and gfpgan (offline patch)
Github Release Page: download all the files from the lastest github release page, and then, put it in ./checkpoints.
百度云盘: we provided the downloaded model in checkpoints, 提取码: sadt. And gfpgan, 提取码: sadt.
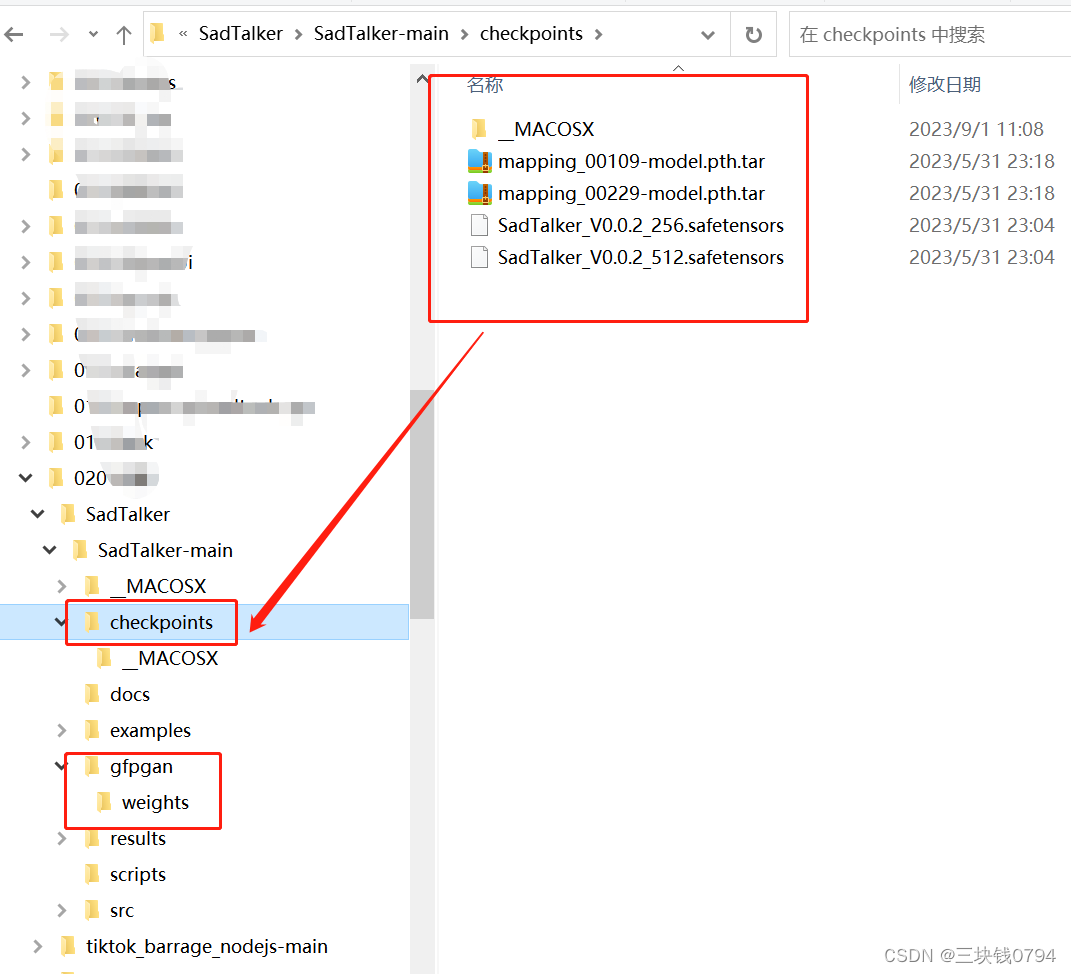
检查是否安装成功
import torch
torch.cuda.is_available() # cuda是否可用print(torch.version.cuda) # 查看pytorch 对应的cuda版本print(torch.__version__) # 查看pytorch版本torch.cuda.device_count() # 返回gpu数量torch.cuda.get_device_name(0) # 返回gpu名字,设备索引默认从0开始;torch.cuda.current_device() # 返回当前设备索引修改一下代码
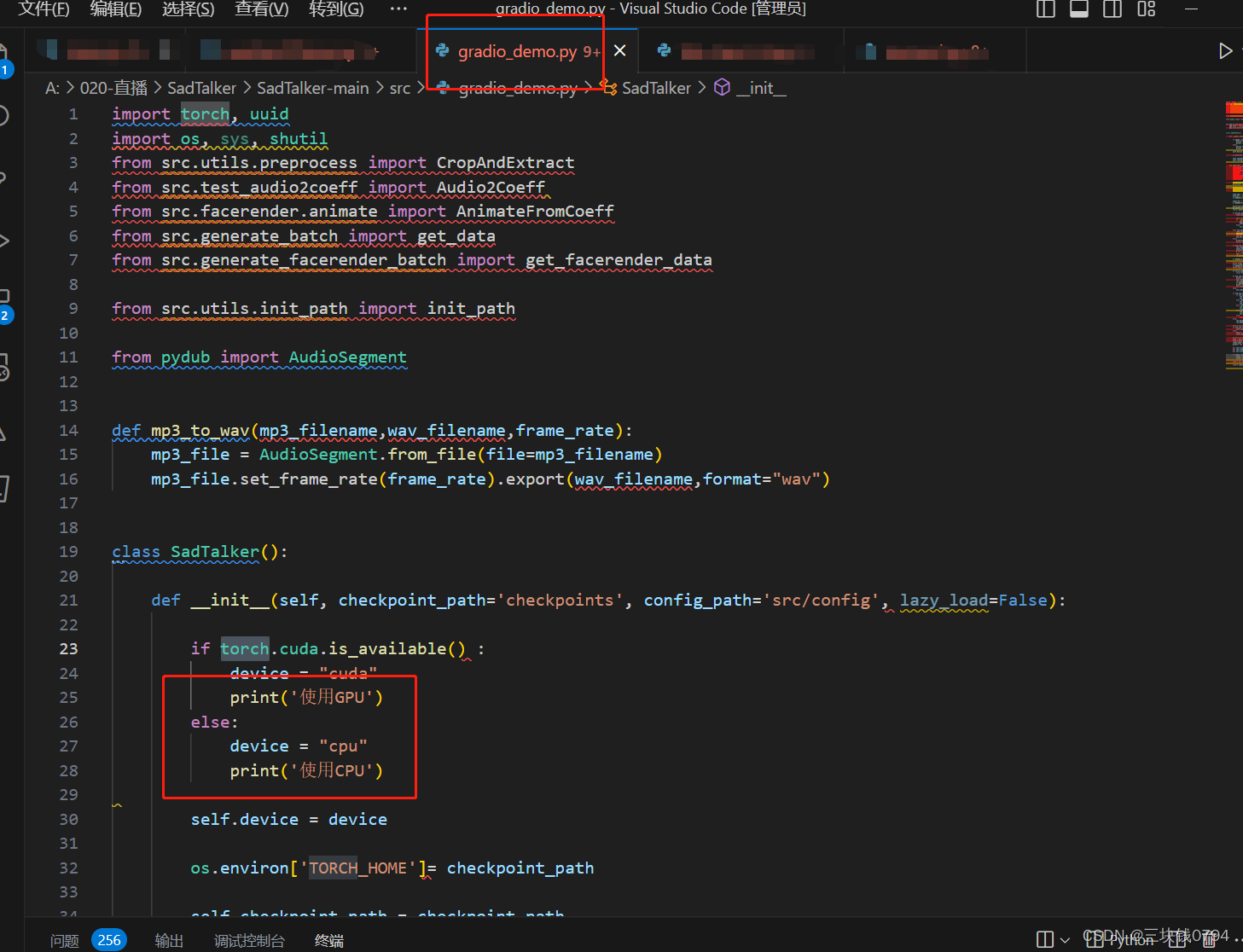

运行