文章目录
- 五、基本数据类型
- 5.1 整数和浮点数
- 5.1.1 整数和浮点数的类型
- 5.1.2 进制和进制转换
- 5.1.3 round函数
- 5.2 运算符
- 5.2.1 常用运算符、运算符函数和逻辑运算符
- 5.2.2 位运算符
- 5.2.3 运算符的优先级及其进阶使用
- 5.2.4 海象运算符`:=`
- 5.3 布尔类型
- 5.4 字符串
- 5.4.1 字符串的基本操作
- 5.4.2 字符串函数
- 5.4.3 strip、split和 join 函数详解
- 5.4.4 字符串的比较
- 5.5 格式化字符串
- 5.5.1 使用`%`进行格式化
- 5.5.2 使用format进行格式化
- 5.5.3 f-string 格式化(Python 3.6+)
- 六、组合数据类型
- 6.1 集合
- 6.2 序列
- 6.2.1 元组
- 6.2.2 列表
- 6.2.2.1 列表常用函数
- 6.2.2.2 列表推导式
- 6.3 字典
- 6.3.1 字典基本操作
- 6.3.2 字典推导式
- 6.3.3 统计三国出场人物,生成词云
Python官网、Python 3.11.5 中文文档、慕课:Python语言程序设计
五、基本数据类型
在 Python 中,数据类型用于表示不同类型的数据,例如整数、浮点数、字符串等Python 支持多种内置数据类型,包括但不限于:
- 整数(int):表示整数值,例如:
10,-5,1000。 - 浮点数(float):表示带有小数部分的数值,例如:
3.14,0.5,-2.0。 - 字符串(str):表示文本数据,用单引号或双引号括起,例如:
'Hello',"Python"。 - 布尔值(bool):表示真(True)或假(False)的逻辑值。
- 列表(list):表示有序的数据集合,可以包含不同类型的元素。
- 元组(tuple):类似于列表,但是不可变,元素用小括号括起。
- 字典(dict):表示键-值对的集合,用花括号括起。
- 集合(set):表示无序且不重复的元素集合。
5.1 整数和浮点数
5.1.1 整数和浮点数的类型
整数(int)和浮点数(float) 是python中的基础数据类型,其中整数存储格式和范围为:
| 格式 | 字节数 | 最小值 | 最大值 |
|---|---|---|---|
| int8 | 1 | -128 | 127 |
| int16 | 2 | -32,768 | 32,767 |
| int32 | 4 | -2,147,483,648 | 2,147,483,647 |
| int64 | 8 | -9,223,372,036,854,775,808 | 9,223,372,036,854,775,807 |
浮点数存储格式和范围为:
| 格式 | 字节数 | 非负最小值 | 非负最大值 | 小数位数 |
|---|---|---|---|---|
| float16(半精度) | 2 | 5.96 × 1 0 − 8 5.96 \times 10^{-8} 5.96×10−8 | 6.55 × 1 0 4 6.55 \times 10^{4} 6.55×104 | 3-4 |
| float32(单精度) | 4 | 1.40 × 1 0 − 45 1.40 \times 10^{-45} 1.40×10−45 | 3.40 × 1 0 38 3.40 \times 10^{38} 3.40×1038 | 7-8 |
| float64 (双精度) | 8 | 5.00 × 1 0 − 324 5.00 \times 10^{-324} 5.00×10−324 | 1.80 × 1 0 308 1.80 \times 10^{308} 1.80×10308 | 15-17 |
在 Python 2 中,存在两种整数类型:
int和long。然而,在 Python 3 中,这两种类型已经合并为统一的整数类型int,因此不存在long类型。
在Python中,通常情况下,你不需要显式指定整数或浮点数的类型,因为Python解释器会自动根据数值的大小和值来确定数据类型。这种动态类型的特性使得Python非常灵活,适用于各种编程任务。
如果你想查看一个数字的具体类型,可以使用内置函数 type() 来检查。如果想了解整数或浮点数的位数,可以使用NumPy中的dtype属性来获取。
import numpy as np
a,b = 42,3.14# 获取整数和浮点数的数据类型
int_type,float_type = type(a) , type(b)
int_dtype,float_dtype = np.array(a).dtype , np.array(b).dtype# 打印数据类型和位数
print(f'整数 a 的数据类型是 {int_type},位数是 {int_dtype} ')
print(f'浮点数 b 的数据类型是 {float_type},位数是 {float_dtype} 位')
整数 a 的数据类型是 <class 'int'>,位数是 int32
浮点数 b 的数据类型是 <class 'float'>,位数是 float64 位
如果你希望显式指定整数或浮点数的类型,可以使用以下方法:
- 使用numpy.intXX或numpy.floatXX构造指定类型的数字
x = np.int16(42) # 创建一个16位整数
y = np.float32(3.14) # 创建一个32位浮点数
- 使用dtype属性来指定
x = np.array([1, 2, 3], dtype=np.int16)
y = np.array([1.0, 2.0, 3.0], dtype=np.float32)
5.1.2 进制和进制转换
| 进制 | 描述 | 示例 |
|---|---|---|
| 二进制(Binary) | 由0和1组成,以0b或0B开头。 | 0b1010 |
| 八进制(Octal) | 由0到7组成,以0o或0O开头。 | 0o17 |
| 十六进制(Hexadecimal) | 由0到9和A到F(大小写均可)组成,以0x或0X开头。 | 0x1A |
| 进制转换 | 描述 | 示例 |
|---|---|---|
| 转换为二进制 | 使用 bin() 函数。 | bin(10) 返回 '0b1010' |
| 转换为八进制 | 使用 oct() 函数。 | oct(17) 返回 '0o21' |
| 转换为十六进制 | 使用 hex() 函数。 | hex(26) 返回 '0x1a' |
5.1.3 round函数
round() 是Python内置的一个函数,用于将浮点数四舍五入到指定的小数位数,语法如下:
round(number, ndigits)
number是要四舍五入的浮点数。ndigits是要保留的小数位数(可选参数)。如果不提供ndigits,则默认为0,表示将浮点数四舍五入到最接近的整数。
round(3.14) # 返回 3
round(3.65) # 返回 4
round(3.14159265, 2) # 返回 3.14
round(3.14159265, 4) # 返回 3.1416
ndigits 参数也可以是负数,此时,round() 会将浮点数的小数点左边的指定位数变为零,然后再四舍五入。这种功能在处理大数时很有用。例如芬兰的面积为 338,424 平方公里,格陵兰岛的面积为 2,166,086 平方公里。我们在介绍时不需要这么精确,就可以使用round函数:
finland_area = 338424 # 芬兰的面积
greenland_area = 2166086 # 格陵兰岛的面积
print(f'芬兰的面积为{round(finland_area, -3)}平方公里,格陵兰岛的面积为{round(greenland_area, -3)}平方公里')
芬兰的面积为338000平方公里,格陵兰岛的面积为2166000平方公里
如果要进行更精确的四舍五入或舍弃,请使用 decimal 模块中的 Decimal 类。
在某些情况下,由于浮点数的表示方式,round() 可能不会像你期望的那样工作。因此,在涉及精确计算的应用程序中,请小心处理浮点数。
5.2 运算符
5.2.1 常用运算符、运算符函数和逻辑运算符
以下是 Python 中常用的运算符,以 Markdown 表格形式表示:
| 运算符 | 描述 | 示例 |
|---|---|---|
| + | 加法 | x + y |
| - | 减法 | x - y |
| * | 乘法 | x * y |
| / | 除法 | x / y |
| % | 取模(取余数) | x % y |
| // | 取整除 | x // y |
| ** | 幂运算 | x ** y |
| == | 等于 | x == y |
| != | 不等于 | x != y |
| < | 小于 | x < y |
| > | 大于 | x > y |
| <= | 小于等于 | x <= y |
| >= | 大于等于 | x >= y |
| @ | 装饰器 | @decorator |
| 快捷运算符 | 说明 |
|---|---|
| += | 加法赋值运算符,等同于 x = x + y |
| -= | 减法赋值运算符,等同于 x = x - y |
| *= | 乘法赋值运算符,等同于 x = x * y |
| /= | 除法赋值运算符,等同于 x = x / y |
| //= | 取整除赋值运算符,等同于 x = x // y |
| %= | 取模赋值运算符,等同于 x = x % y |
| @= | at 赋值运算符,等同于 x = x @ y |
| &= | 位与赋值运算符,等同于 x = x & y |
| |= | 位或赋值运算符,等同于 x = x |
| ^= | 位异或赋值运算符,等同于 x = x ^ y |
| >>= | 右移赋值运算符,等同于 x = x >> y |
| <<= | 左移赋值运算符,等同于 x = x << y |
| **= | 幂赋值运算符,等同于 x = x ** y |
| 运算符函数 | 描述 |
|---|---|
abs(x) | 返回 x 的绝对值 |
pow(x, y) | 返回 x 的 y 次幂 |
sqrt(x) | 返回 x 的平方根 |
round(x, n) | 返回 x 的四舍五入值,可指定小数位数 n |
max(iterable) | 返回可迭代对象中的最大值 |
min(iterable) | 返回可迭代对象中的最小值 |
sum(iterable) | 返回可迭代对象中所有元素的和 |
divmod(x, y) | 返回 (x // y, x % y) 的元组 |
int(x) | 将 x 转换为整数 |
float(x) | 将 x 转换为浮点数 |
complex(real, imag) | 创建一个复数 |
| 逻辑运算符 | 描述 | 示例 |
|---|---|---|
| not | 逻辑非(取反) | not x |
| and | 逻辑与(与) | x and y |
| or | 逻辑或(或) | x or y |
| is、is not | 判断是否为同一对象,即检查它们是否指向内存中的相同对象 | x is y |
| in、not in | 判断一个元素是否存在于一个容器(如列表、元组、字符串、集合等)中 | x in y |
注意:在使用
is和is not运算符时要谨慎,因为它们检查对象的身份而不是值,有时可能会导致意外的结果。通常情况下,我们更倾向于使用==和!=运算符来比较对象的值是否相等。
5.2.2 位运算符
位运算是计算机中对二进制位进行操作的一种运算方式。它们用于直接操作二进制表示的数据,通常用于底层编程、位级操作和优化算法中。位运算包括以下常见的操作:
| 位运算符 | 描述 | 示例 |
|---|---|---|
& | 按位与运算符:对每个位进行与运算,相同位均为 1 时结果位为 1,否则为 0。 | x & y |
| | 按位或运算符:对每个位进行或运算,至少一个位为 1 时结果位为 1。 | x | y |
^ | 按位异或运算符:对每个位进行异或运算,相同位为 0,不同位为 1。 | x ^ y |
~ | 按位取反运算符:对每个位进行取反运算,0 变 1,1 变 0。 | ~x |
<< | 左移运算符:将二进制数左移指定位数。 | x << y |
>> | 右移运算符:将二进制数右移指定位数。 | x >> y |
下面举一个例子来更详细的说明位运算:
# 函数示例:演示位运算符的用法
def bitwise_operators_example(a, b):# 1. 按位与(&):对应位都为1时结果为1,否则为0result_and = a & b# 2. 按位或(|):对应位有一个为1时结果为1,否则为0result_or = a | b# 3. 按位异或(^):对应位不相同为1,相同为0result_xor = a ^ b# 4. 按位取反(~):每个位上的0变成1,1变成0result_not_a = ~aresult_not_b = ~b# 5. 左移位(<<):将二进制数左移指定位数,低位用0填充result_left_shift = a << 2# 6. 右移位(>>):将二进制数右移指定位数,高位用0填充(对于正数)或用1填充(对于负数)result_right_shift = a >> 2# 输出结果print(f"a & b: {result_and}")print(f"a | b: {result_or}")print(f"a ^ b: {result_xor}")print(f"~a: {result_not_a}")print(f"~b: {result_not_b}")print(f"a << 2: {result_left_shift}")print(f"a >> 2: {result_right_shift}")# 示例使用
bitwise_operators_example(5, 3)
a & b: 1
a | b: 7
a ^ b: 6
~a: -6
~b: -4
a << 2: 20
a >> 2: 1
让我们逐个解释这些结果,以更好地理解为什么会得到这些值。 a 的二进制表示是 101, b 的二进制表示是 011。
a & b: 1(按位与): 对应位都为1的情况下,结果为1,所以101 & 011的结果是001,即十进制的1。a | b: 7(按位或):对应位只要有一个为1,结果就为1,所以101 | 011的结果是111,即十进制的7。a ^ b: 6(按位异或): 对应位不同为1,相同为0,所以101 ^ 011的结果是110,即十进制的6。~a: -6(按位取反,注意负数表示):~a对a的每个位取反,得到010。 由于二进制的最高位是1,表示负数,所以010在补码表示中表示的是-6。~b: -4(按位取反,注意负数表示):~b对b的每个位取反,得到100。 由于二进制的最高位是1,表示负数,所以100在补码表示中表示的是-4。a << 2: 20(左移位): 左移2位相当于将二进制数向左移动2位并在低位补充0,所以101 << 2的结果是10100,即十进制的20。a >> 2: 1(右移位): 右移2位相当于将二进制数向右移动2位,所以101 >> 2的结果是1,即十进制的1。
位运算的补码是一种用于表示负整数的二进制数表示方法,它在计算机中广泛使用。补码的定义和用法如下:
- 原码:原码表示法是最简单的二进制表示法。对于正整数,它的原码和二进制表示一样。例如,十进制的+5表示成原码是
00000101。- 反码:反码表示法是在原码的基础上,对负整数的符号位(最高位)取反。对于正整数,它的反码和原码一样。例如,十进制的+5的反码也是
00000101。- 补码:补码表示法是在反码的基础上,将所有位取反后加1。对于正整数,它的补码和原码一样。例如,十进制的+5的补码也是
00000101。
但是,补码的真正优势在于表示负整数。例如,要表示十进制的-5,首先找到+5的补码
00000101,然后将所有位取反得到11111010,最后加1得到-5的补码。这意味着在计算机中,加法和减法可以使用相同的硬件逻辑来执行,因为减法可以转换为加法。
5.2.3 运算符的优先级及其进阶使用
在Python中,运算符具有不同的优先级,这决定了它们在表达式中的计算顺序。如果表达式中包含多个运算符,Python会按照一定的规则确定它们的计算顺序。以下是一些常见运算符的优先级,按照从高到低的顺序:
- 幂运算符:
** - 正号和负号:
+和-(一元运算符) - 算术运算符:
*(乘法)、/(除法)、//(整除)、%(取余数) - 加法和减法运算符:
+和-(二元运算符) - 位左移和位右移运算符:
<<和>> - 位与运算符:
& - 位异或运算符:
^ - 位或运算符:
| - 比较运算符:
<、<=、>、>=、==、!= - 逻辑非运算符:
not - 逻辑与运算符:
and - 逻辑或运算符:
or
如果需要改变运算顺序,可以使用小括号 () 来明确指定表达式的计算顺序。括号中的表达式会首先被计算。下面是一些进阶知识:
-
比较操作支持链式操作:可以在一条表达式中进行多次比较,并且这些比较操作会按照从左到右的顺序依次执行。例如,
a < b == c将首先比较a是否小于b,然后再检查b是否等于c。这个表达式会返回布尔值True或False,表示整个比较表达式的结果。a = 3 b = 4 c = 4 result = a < b == c # 结果为 True,因为 a 小于等于 b,且 b 等于 c -
and、or和not组合操作:可以使用and和or运算符来组合多个比较操作或布尔表达式,并根据其真假情况得到最终的布尔结果。最后可以用not运算符来取反。因此,A and not B or C等价于(A and (not B)) or C。 -
布尔运算符是短路运算符:这意味着在进行布尔运算时,Python会从左到右逐个检查操作数,并且一旦确定整个表达式的结果,就会停止继续检查,这可以提高性能并防止不必要的计算。
a = True b = False c = True result = a and b and c # 结果为 False,因为一旦发现 b 为假,就停止继续检查 c
5.2.4 海象运算符:=
海象运算符 := 是Python 3.8版本引入的一项特性,也被称为"表达式内部赋值"或"walrus operator"。它的主要用途是在表达式中执行赋值操作,并且返回被赋的值。这个特性在循环判断中很有用。
在海象运算符之前,您可能会在循环中重复计算一个表达式,并将其值赋给变量,然后再使用该值进行条件判断。使用海象运算符,您可以在表达式中同时进行计算和赋值,从而更加简洁和清晰地表达您的意图。
with open('novel.txt', 'r', encoding='utf-8') as file:while chunk := file.read(200):print(chunk)
上述代码用于读取文件中的数据块(chunk)。使用海象运算符,可以在表达式中将读到的200个字节内容赋值给变量chunk ,同时,这个表达式会将 chunk 的值用于条件判断。如果成功读取了数据(数据块不为空),则 条件表达式为真,循环体继续执行。
如果不使用海象运算符,可以写成:
with open('novel.txt', 'r', encoding='utf-8') as file:while True:chunk = file.read(200) # 读取200个字符if not chunk:break # 如果数据块为空,表示已经到达文件末尾,退出循环print(chunk)
5.3 布尔类型
Python中的布尔类型非常简单,它只有两个值:True和False,分别表示1和0,可以直接参与计算。这两个值也通常用于表示逻辑真和逻辑假。布尔类型通常与条件语句一起使用,广泛用于控制循环、判断条件、过滤数据等等。
True + False # 结果为1
Python还提供了一些用于处理布尔类型的内置函数,如 bool() 函数用于将其他数据类型转换为布尔类型,any() 和 all() 用于对迭代对象中的布尔值进行判断。
# bool() 函数
x = bool(5) # True
y = bool(0) # False# any() 和 all() 函数
numbers = [True, False, True]
any_true = any(numbers) # True,至少有一个True
all_true = all(numbers) # False,不是所有的都是True
在Python中,布尔类型 False 只是布尔对象的一种,而其他对象也可以在适当的情况下被视为 False。Python中定义了一个规则,根据这些规则,以下对象被视为 False:
- 布尔值:
False是显而易见的,它是布尔值的字面值。 - 数字:一些数字也被视为
False。这包括整数0、浮点数0.0,以及其他数值类型中的零值。 - 空序列和集合:空的序列(如空列表
[]、空元组()、空字符串"")和空集合(如空集合set())也被视为False。(空格符被视作True) - 特殊对象
None:None表示空值,也被视为False。 - 自定义类的实例:如果自定义的类中定义了
__bool__()或__len__()方法,并且这些方法返回False或者0,那么该类的实例也被视为False。
你可以使用以下方式测试一个对象是否为 False:
value = 0if not value:print("value 是 False 或者空")
else:print("value 是 True 或者非空")
5.4 字符串
在Python中,字符串是一种用来存储文本数据的数据类型,你可以使用单引号 '、双引号 " 或三重引号 ''' 或 """ 来创建字符串。
single_quoted = '这是一个单引号字符串'
double_quoted = "这是一个双引号字符串"
triple_quoted = '''这是一个
多行字符串'''
5.4.1 字符串的基本操作
-
拼接和复制
你可以使用 + 运算符将两个字符串连接起来,使用 * 运算符将一个字符串复制多次 -
合并
- 相邻的两个或多个 字符串 (引号标注的字符)会自动合并,拼接分隔开的长字符串时,这个功能特别实用。
- 这项功能只能用于两个字面值,不能用于变量或表达式。合并多个变量,或合并变量与字面值,要用
+
'Py' 'thon'
Python
text = ('Put several strings within parentheses ''to have them joined together.')
text'Put several strings within parentheses to have them joined together.'
prefix = 'Py'
prefix + 'thon''Python'
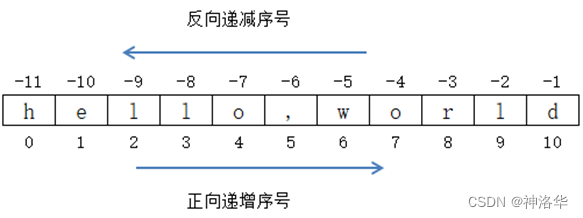
- 索引:字符串中的字符可以通过索引来访问,索引从0开始,负索引表示从末尾开始计数
- 切片: 你可以使用切片来获取字符串的一部分。
- 如果省略起始索引,将从字符串的开头开始切片。省略结束索引,将切片到字符串的末尾
- 你可以使用步长来指定切片的间隔。
- 使用
str[::-1]可以反转字符串
text = "Hello, World!"
substring = text[7:] # 获取从索引7到11的子字符串,值为 'World'
substring = text[0::2] # 从第一个字符开始,每隔2个取一个,值为'Hlo ol!'- 修改字符串:Python 字符串不能修改,为字符串中某个索引位置直接赋值会报错。
word = 'Python'
word[2:] = 'py'
Traceback (most recent call last):File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment
要生成不同的字符串,应新建一个字符串:
'J' + word[1:]
'Jython'
5.4.2 字符串函数
可参考官方文档《String Methods》
| 字符串格式函数 | 描述 | 示例 | 结果 |
|---|---|---|---|
str.upper() | 转换为大写 | 'hello'.upper() | 'HELLO' |
str.lower() | 转换为小写 | 'HeLLo'.lower() | 'hello' |
str.title() | 每个单词首字母大写 | 'hello world'.title() | 'Hello World' |
str.capitalize() | 只将字符串的首字母大写 | 'hello world'.capitalize() | 'Hello world' |
str.swapcase() | 将字符串中的大写/小写字母转换为小写/大写字母 | 'Hello World'.swapcase() | 'hELLO wORLD' |
str.strip() | 去除两侧空格或指定字符 | ' hello '.strip() | 'hello' |
str.split(sep) | 分割字符串 | 'apple,banana,orange'.split(',') | ['apple', 'banana', 'orange'] |
str.join(iterable) | 连接可迭代对象元素 | ', '.join(['apple', 'banana', 'orange']) | 'apple, banana, orange' |
| 字符串查找函数 | 描述 | 示例 | 结果 |
|---|---|---|---|
str.replace(old, new) | 替换子串 | 'Hello, world'.replace('world', 'Python') | 'Hello, Python' |
str.find(sub) | 查找子串第一次出现的索引,不存在则返回-1 | 'Hello, world'.find('world') | 7 |
str.rfind(sub) | 查找子串最后一次出现的索引,不存在则返回-1 | 'Hello, world'.find('world') | 7 |
str.index(sub) | 查找子串第一次出现的索引,不存在报错ValueError | 'Hello, world'.index('world') | 7 |
str.rindex(sub) | 查找子串最后一次出现的索引,不存在报错ValueError | 'Hello, world'.index('world') | 7 |
| 字符串转换函数 | 描述 | 示例 | 结果 |
|---|---|---|---|
str.replace(old, new) | 替换子串 | 'Hello, world'.replace('world', 'Python') | 'Hello, Python' |
str(obj) | 将对象转换为字符串 | str(42) | '42' |
hex(number) | 将整数转换为十六进制字符串 | hex(255) | '0xff' |
chr(i) | 将 Unicode 整数转换为字符 | chr(65) | 'A' |
ord(char) | 返回字符的 Unicode 整数值 | ord('A') | 65 |
| 字符串统计检查函数 | 描述 | 示例 | 结果 |
|---|---|---|---|
len(str) | 返回字符串长度 | len('Hello') | 5 |
str.count(sub) | 统计子串出现次数 | 'Hello, world, world'.count('world') | 2 |
str.startswith(prefix) | 检查前缀 | 'Hello, world'.startswith('Hello') | True |
str.endswith(suffix) | 检查后缀 | 'Hello, world'.endswith('world') | False |
str.isalpha() | 检查是否只包含字母 | 'Hello'.isalpha() | True |
str.isdigit() | 检查字符串是否只包含数字字符(只包括阿拉伯数字)。 | '12345'.isdigit() | True |
str.isalnum() | 检查是否只包含字母和数字 | 'hello123'.isalnum() | True |
str.isnumeric() | 检查字符串是否由数字组成(包括罗马数字)。 | '3.14'.isnumeric() | False |
str.isdecimal() | 检查字符串是否只包含十进制数字字符。 | '12345'.isdecimal() | True |
str.isspace() | 检查字符串是否只包含空白字符(空格、制表符、换行符等)。 | ' \t\n'.isspace() | True |
str.isprintable() | 检查字符串是否只包含可打印字符(不包括控制字符)。 | '\n'.isprintable() | False |
str.isidentifier() | 检查字符串是否是有效的 Python 标识符。 | '123var'.isidentifier() | False |
5.4.3 strip、split和 join 函数详解
strip()函数用于去除字符串两侧的指定字符,它的语法如下:
str.strip([chars])
chars(可选):指定要去除的字符集合,默认为去除空白字符,如空格、制表符、换行符等。
# 示例 1: 去除空白字符
text = " Hello, world "
result = text.strip()
print(result) # 输出:"Hello, world"
# 示例 2: 去除指定字符
text = "**Hello, world**"
result = text.strip('*')
print(result) # 输出:"Hello, world"
split()函数
split() 函数用于将字符串分割成子串,并返回一个包含子串的列表。它的语法如下:
str.split([sep[, maxsplit]])
sep(可选):指定分隔符,默认为空白字符。maxsplit(可选):指定最大分割次数,如果提供,则最多分割maxsplit次。
# 示例 1: 使用默认分隔符(空白字符)
text = "apple banana orange"
result = text.split()
print(result) # 输出:['apple', 'banana', 'orange']
# 示例 2: 使用自定义分隔符
text = "apple,banana,orange"
result = text.split(',')
print(result) # 输出:['apple', 'banana', 'orange']
# 示例 3: 限制分割次数
text = "apple,banana,orange,grape"
result = text.split(',', 2)
print(result) # 输出:['apple', 'banana', 'orange,grape']
join()函数
join() 函数用于连接字符串列表中的元素,并返回一个新的字符串。它的语法如下:
str.join(iterable)
iterable:要连接的可迭代对象,通常是一个包含字符串的列表或元组。
# 示例 1: 连接元组中的字符串
fruits = ('apple', 'banana', 'orange')
result = ' and '.join(fruits)
print(result) # 输出:"apple and banana and orange"
# 示例 2: 连接字符串列表
words = ['apple', 'banana', 'orange']
result = ','.join(words) # 结果是"apple,banana,orange"
result.split(',') # 结果是['apple', 'banana', 'orange']
5.4.4 字符串的比较
| 字符串操作符 | 描述 | 示例 | 结果 |
|---|---|---|---|
+ | 字符串连接 | 'Hello' + ' ' + 'World' | 'Hello World' |
* | 重复字符串 | 'Python' * 3 | 'PythonPythonPython' |
==、!= | 相等比较 | 'Hello' == 'World' | False |
<、<=、> 、 >= | 字典序比较 | "apple" < "banana" | True |
- 如果两个字符串的内容完全相同,
==比较符才返回True,否则返回False。 - 字典序比较:您可以使用
<、<=、>和>=操作符来比较两个字符串的字典序,确定它们在字典中的顺序。这些比较基于字符的 Unicode 编码值。 - 自定义比较规则:如果需要按照特定规则进行比较,可以编写自定义的比较函数,并使用
sorted()函数或自定义排序算法来比较字符串。例如:
# 按照字符串长度排序
names = ["Alice", "Bob", "Charlie", "David"]
names.sort(key=len)
print(names) # 输出:['Bob', 'Alice', 'David', 'Charlie']
# 按照字符串的最后一个字符排序
words = ["apple", "banana", "cherry", "date"]
sorted_words = sorted(words, key=lambda x: x[-1])
print(sorted_words) # 输出:['banana', 'cherry', 'apple', 'date']
5.5 格式化字符串
详情可参考《格式字符串语法 》、
在Python中,格式化字符串是一种用来创建可变的、动态的文本输出的方法。格式化字符串允许将变量的值插入到字符串中,从而生成带有数据的文本。这使得输出更加有意义、有用,并且具有更好的可读性。Python提供了几种方式来格式化字符串,下面一一介绍。
5.5.1 使用%进行格式化
更多有关%格式化的内容,请参考《printf 风格的字符串格式化》
通过在字符串中使用百分号(%),然后在字符串后面跟上格式化元组,可以将变量值插入字符串中。变量值可以是单个值,也可以是元组(或字典)包含的多个值。示例:
name = "Alice"
age = 30
height = 5.8formatted_str = "Name: %s, Age: %d, Height: %.2f" % (name, age, height)
在这个示例中,%s 插入了字符串 name,%d 插入了整数 age,%.2f 插入了浮点数 height,并且使用 % 运算符连接了这些占位符和变量值。下面是字符串格式化占位符的说明:
%s:用于插入字符串。%d:用于插入整数。%f:用于插入浮点数。%x:用于插入十六进制整数。
% 格式化不支持格式指定符的高级功能,如对齐、填充字符等,它相对不够灵活。另外还可能导致许多常见错误,例如无法正确显示元组和字典等,通常更推荐使用 f-strings 或 str.format() 方法。
5.5.2 使用format进行格式化
有关此部分的详细内容,可参考官方文档《格式字符串语法》
Python 3.0以后引入了更现代的字符串格式化方式,使用花括号{}来表示要插入的变量,并使用format()方法进行格式化。示例:
name = "Bob"
age = 30
formatted_string = "My name is {} and I am {} years old.".format(name, age)
print(formatted_string)
上面代码中,花括号 {} 用作占位符,表示将在字符串中的这些位置插入变量的值。format() 方法用于将实际的值插入这些占位符的位置。以下是更详细的说明:
-
参数: 花括号中可以使用位置参数或者关键字参数,也可以混用。例如:
"Hello, {} and {second}.".format(name1, second=name2)。 -
索引:
可以在花括号{}中使用索引,表示要插入的变量的位置。例如:"{1} comes before {0}.".format("apple", "banana")。 -
格式指定符:
可以在花括号{}中使用冒号:来添加格式指定符,控制插入值的格式。例如:"Value: {:.2f}".format(3.14159)将保留两位小数。 -
空花括号
{}:
如果要插入的值与花括号{}中的索引不一致,可以在花括号内部留空。例如:"Hello, {}!".format(name)。 -
转义花括号:
使用两个花括号{{}}来表示字面的花括号。例如:"The format is {{}}.".format()。
有关格式指定符的详细说明如下:
-
整数格式: 例如
"Integer: {:d}, Hex: {:x}, Octal: {:o}".format(42, 42, 42),其中:d:整数。x:十六进制(小写)。#x指定十六进制格式带有前缀 0xX:十六进制(大写)。o:八进制。
-
浮点数格式: 例如
"Value: {:.2f}".format(3.14159),其中f:浮点数。.nf:浮点数并指定小数位数。
-
字符串格式: 例如
"Hello, {}!".format("Alice") -
对齐和宽度: 例如
"{:<10}".format("Hello"),其中<:左对齐(默认)。>:右对齐。^:居中对齐。width:设置字段宽度。
-
符号和补零: 例如
"{:+}".format(42),其中+:显示正负号。-:仅显示负号(默认)。0:用零填充字段宽度。
-
千位分隔符::用逗号分隔数字的千位,例如:
"{:,}".format(1000000)。 -
指数记法:
e和E分别表示小写和大写的科学计数法,例如"{:.2e}".format(12345.6789)。 -
百分号: 将浮点数转换为百分比形式,例如
"{:.2%}".format(0.75)。

最后,在处理长字符串格式化时,最好使用关键字参数而不是位置参数,因为:
- 可读性更高:通过使用变量名称而不是位置,代码更容易理解和维护,因为您不需要记住每个占位符的位置。
- 避免错误:如果您在长格式字符串中有多个占位符,依赖位置可能容易出错,特别是当占位符很多时。按名称引用变量可以降低出错的可能性。
- 更灵活:使用变量名称可以让您更轻松地更改变量的顺序或添加/删除变量,而无需重新排列所有占位符。
所以推荐的做法是,将变量放入一个字典中,然后在格式化字符串中使用这些变量名称作为键来引用它们,这在处理复杂的格式化字符串时尤其有用,例如:
table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 8637678}
print('Jack: {0[Jack]:d}; Sjoerd: {0[Sjoerd]:d}; Dcab: {0[Dcab]:d}'.format(table))
Jack: 4098; Sjoerd: 4127; Dcab: 8637678
你也可以写成以下两种形式:
print('Jack: {Jack:d}; Sjoerd: {Sjoerd:d}; Dcab: {Dcab:d}'.format(**table))
print('Jack: {}; Sjoerd: {}; Dcab: {}'.format(table['Jack'],table['Sjoerd'],table['Dcab']))
再举一个生成平方和立方的表例子:
for x in range(1, 11):print('{0:2d} {1:3d} {2:4d}'.format(x, x*x, x*x*x))
1 1 1
2 4 8
3 9 27
4 16 64
5 25 125
6 36 216
7 49 343
8 64 512
9 81 729
10 100 1000
你也可以手动设置格式,结果是一样的:
for x in range(1, 11):print(str(x).rjust(2), str(x*x).rjust(3), end=' ')# Note use of 'end' on previous lineprint(str(x*x*x).rjust(4))
5.5.3 f-string 格式化(Python 3.6+)
Python 3.6引入了一种更简洁、直观的字符串格式化方式,即f-string。使用f-string,您可以在字符串中直接插入变量,而无需使用.format()。
name = "Eve"
age = 22
formatted_string = f"My name is {name} and I am {age} years old."
print(formatted_string)
f-string还有一些其它的用法:
-
使用表达式: 您可以在 f-string 中使用表达式,这使得在字符串内部进行计算变得更加方便。
num1,num2 = 10,20 result = f"The sum of {num1} and {num2} is {num1 + num2}." print(result) -
调用函数: 你还可以在 f-string 中调用函数,并将结果插入到字符串中。
def double(x):return x * 2num = 5 formatted_string = f"Double of {num} is {double(num)}." print(formatted_string) -
转义花括号: 同format一样,使用两个花括号
{{}}来插入字面的花括号。name = "Bob" formatted_string = f"His name is {name}, and he likes {{Python}} programming." print(formatted_string) -
格式指定符:
-
可以直接使用变量名作为格式化指定符,它将自动选择适当的格式,例如
age = 25 formatted_age = f"I am {age} years old, which is {age:d} in integer format." print(formatted_age) -
f-string也支持格式指定符来控制插入值的格式,并且与format方法中的格式指定符是完全一样的。# 浮点数格式化 pi = 3.141592653589793 formatted_pi = f"圆周率: {pi:.2f}" # 使用 :.2f 指定浮点数格式,保留两位小数 print(formatted_pi) # 输出: 圆周率: 3.14# 百分比格式化 percentage = 0.75 formatted_percentage = f"百分比: {percentage:.1%}" # 使用 :.1% 指定百分比格式,保留一位小数 print(formatted_percentage) # 输出: 百分比: 75.0%# 嵌套格式化 width = 10 precision = 4 value = "12.34567" f"result: {value:{width}.{precision}}" # 输出:'result: 12.3 '# 左对齐格式化 text = "左对齐" formatted_text = f"文本: {text:<10}" # 使用 :<10 指定宽度为 10,左对齐 print(formatted_text) # 输出: 文本: 左对齐# 自定义填充符 table = {'Sjoerd': 4127, 'Jack': 4098, 'Dcab': 7678}for name, phone in table.items():print(f'{name:10} ==> {phone:10d}') # 只写{phone:10}也没问题Sjoerd ==> 4127 Jack ==> 4098 Dcab ==> 7678
-
-
格式说明符
=(Python3.8新特性):可将一个表达式扩展为表达式文本,将变量的源码和值同时进行输出,快速查看变量,在调试追踪中很有用。例如:bugs = 'roaches' count = 16,075 area = 'living room' print(f'Debugging {bugs=} {count=:,d} {area=}')Debugging bugs='roaches' count=16,075 area='living room'from datetime import datetime today = datetime(year=2017, month=1, day=27) f"{today=:%B %d, %Y}"'today=January 27, 2017'
六、组合数据类型
6.1 集合
集合是Python中的一种数据结构,它类似于列表(List),但有一些重要的区别:
- 集合中的元素是无序的,不重复的,即集合中不允许重复的元素;
- 集合用花括号
{}表示,或者可以使用set()函数来创建。要注意的是,创建空集合只能用set(),不能用{},因为{}创建的是空字典; - 集合支持集合运算,如并集、交集、差集等。
- 与 列表推导式 类似,集合也支持推导式:
a = {x for x in 'abracadabra' if x not in 'abc'}
下面是常用的集合操作符和函数:
| 集合操作符 | 说明 |
|---|---|
| S & T 或S.intersection(T) | 交,返回一个新集合,包括同时在集合 S 和 T 中的元素 |
| S | T或S.union(T) | 并,返回一个新集合,包括在集合S和T中的所有元素 |
| S - T或 S.difference(T) | 差,返回一个新集合,包括在集合 S 但不在 T 中的元素 |
| S ^ T或S.symmetric_difference(T) | 补,返回一个新集合,包括集合 S 和 T 中的非相同元素 |
| S <= T 或 S < T | 返回 True/False,判断 S 和 T 的子集关系 |
| S >= T 或 S > T | 返回 True/False,判断 S 和 T 的包含关系 |
| S.issubset(T) | 判断 S 是否是 T 的子集 |
| S.issuperset(T) | 判断 S 是否是 T 的超集 |
| S.isdisjoint(T) | 判断和 T 是否有交集 |
| S == T、S != T | 判断 S 和 T 是否相等 |
| S -= T | 差,更新集合 S,包括在集合 S 但不在 T 中的元素 |
| S &= T | 交,更新集合 S,包括同时在集合 S 和 T 中的元素 |
| S ^= T | 补,更新集合 S,包括集合 S 和 T 中的非相同元素 |
| S -= T、S &= T 、S ^= T、S | =T | 快捷运算符,等同于S = S op T |
以下是常用的集合函数:
| 集合函数 | 说明 |
|---|---|
| set(x) | 将其他类型变量 x 转变为集合类型 |
| S.add(x) | 如果 x 不在集合 S 中,将 x 增加到 S |
| S.update(x) | 将 x 中的各个元素分别添加到集合中,x 可以是元组、列表、集合 |
| S.discard(x) | 移除 S 中元素 x,如果 x 不在集合 S 中,不报错 |
| S.remove(x) | 移除 S 中元素 x,如果 x 不在集合 S 中,产生 KeyError 异常 |
| S.clear() | 移除 S 中所有元素 |
| S.pop() | 随机删除 S 的一个元素,S 为空集则产生 KeyError 异常 |
| S.copy() | 返回集合 S 的一个副本 |
| len(S) | 返回集合 S 的元素个数 |
| x in S , x not in S | 判断 S 中是否含有元素 x, |
集合是Python中的基础数据结构,它们在许多应用场景中都很有用,例如:
- 去重数据: 集合中的元素是唯一的,因此它们经常用于从重复数据中获取唯一值。你可以将一个列表或其他可迭代对象转换为集合,以轻松去除重复元素。
- 成员检查: 你可以使用集合来快速检查某个元素是否存在于集合中。这比在列表或其他数据结构中进行线性搜索更加高效。
- 集合运算: 集合支持并集、交集、差集等数学操作,因此它们在处理数学问题时非常有用。例如,查找两个集合的交集以找到共同的元素、排列组合、子集问题等。
- 标记和过滤数据: 你可以使用集合来标记或过滤数据。例如,你可以创建一个包含兴趣爱好的集合,然后筛选出符合特定兴趣爱好的人。
- 网络和图算法: 集合通常用于图算法中,用于存储节点的邻居或其他特性。
6.2 序列
在Python中,序列类型是一种数据结构,用于存储一系列有序的元素。在python中,字符串、列表、元组都是序列类型,共享一些通用的特性和操作,包括:
-
有序性: 序列中的元素是按照一定的顺序排列的,每个元素都有一个唯一的位置(索引)。
-
可迭代性: 你可以使用循环来遍历序列中的每个元素,例如
for循环。 -
索引访问: 你可以使用索引来访问序列中的单个元素,索引从0开始,表示第一个元素。
-
切片操作: 你可以使用切片(slice)来获取序列中的子序列。切片允许你指定起始索引、结束索引和步长。
-
长度: 你可以使用内置函数
len()来获取序列的长度,即其中元素的数量。
以下是序列型通用的操作符和函数:
| 序列操作符 | 说明 |
|---|---|
x in s | 如果 x 是序列 s 的元素,返回 True,否则返回 False。 |
x not in s | 如果 x 是序列 s 的元素,返回 False,否则返回 True。 |
s + t | 连接两个序列 s 和 t。 |
s * n 或 n * s | 将序列 s 复制 n 次。 |
s[i] | 索引,返回序列 s 中的第 i 个元素,i 是序列的序号。 |
s[i:j] 或 s[i:j:k] | 切片,返回序列 s 中第 i 到 j 以 k 为步长的元素子序列。 |
# 创建两个元组
tuple1 = (1, 2, 3, 4, 5)
tuple2 = (5, 6, 7, 8, 9)# 使用操作符/函数
result1 = 3 in tuple1 # 判断元素是否存在于元组中,返回True
concatenated_tuple = tuple1 + tuple2 # 连接两个元组
repeated_tuple = tuple1 * 3 # 将元组重复3次
slice_of_tuple = tuple2[1:4] # 获取元组中索引1到3的子序列# 输出结果
print("3 in tuple1:", result1)
print("Concatenated Tuple:", concatenated_tuple)
print("Repeated Tuple:", repeated_tuple)
print("Slice of Tuple2:", slice_of_tuple)
3 in tuple1: True
Concatenated Tuple: (1, 2, 3, 4, 5, 5, 6, 7, 8, 9)
Repeated Tuple: (1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 1, 2, 3, 4, 5)
Slice of Tuple2: (6, 7, 8)
| 序列函数 | 说明 |
|---|---|
len() | 返回序列的长度(元素个数) |
max() | 返回序列中的最大元素 |
min() | 返回序列中的最小元素 |
index() | 返回指定元素的索引(第一次出现的位置) |
count() | 返回指定元素在序列中出现的次数 |
sorted() | 返回一个排序后的序列副本 |
reversed() | 返回一个反向的序列副本 |
因为sort是对被操作对象进行原地修改,所以不适用于元组和字符串,但是sorted函数可以。
6.2.1 元组
元组是一种有序的不可变序列,与列表相似,但不可以修改。元组使用圆括号 () 表示,内部的各个值用逗号隔开。元组可以包含不同类型的元素,只有一个元素的元组可以通过在这个元素后添加逗号来构建。
singleton = 'hello',
singleton('hello',)
元组也可以进行索引和解包操作:
t = 1, 2, 3, 4, 5
u = t, (1, "Hello", 3.14) # 结果是((1, 2, 3, 4, 5), (1, 'Hello', 3.14))
x ,y ,z = u[1]
x ,y ,z(1, 'Hello', 3.14)
元组(Tuples)是Python中的一种有序、不可变的数据结构,它们在许多应用场景中都非常有用,例如:
- 多个返回值: 函数可以返回多个值,这些值可以用元组打包。在调用函数时,可以将元组解包为多个变量,从而轻松获取多个返回值。
- 不可变性: 元组的不可变性使它们适合用于表示不应更改的数据,如日期、时间戳或配置参数,这可以确保数据的完整性(通常配置文件用元组来保存参数)。
- 不可更改的键: 元组可以用作字典的键,因为它们是不可变的,而列表不行。这使得元组在创建自定义字典或映射数据时很有用。
- 函数参数: 在函数定义和调用中,元组可用于传递一组参数。这对于编写可接受不定数量参数的函数非常有用。
6.2.2 列表
6.2.2.1 列表常用函数
列表是Python中最常用的数据结构之一,它用于存储一组有序的元素。列表是可变的,这意味着你可以在列表创建后添加、删除或修改元素。你使用方括号[]或list()创建列表,列表元素之间用逗号分隔。以下是常用的列表函数和操作(序列函数也适用):
| 操作/函数 | 说明 |
|---|---|
ls[i]=x | 替换列表 ls 中的第 i 个元素为 x。 |
ls[i:j:k]=lt | 用新列表 lt 替换列表 ls 中切片后的相应元素子列表,如果只是新命名,相当于删除元素。 |
del ls[i] | 删除列表 ls 中的第 i 个元素。 |
del ls[i:j:k] | 删除列表 ls 中第 i 到第 j 以步长 k 的元素。 |
ls+=lt | 将列表 lt 的元素添加到列表 ls 中,更新 ls。 |
ls*=n | 重复列表 ls 中的元素 n 次,更新 ls。 |
ls.append(x) | 向列表 ls 的末尾添加元素 x,不创建新对象。 |
ls.extend(iterable) | 将可迭代对象 iterable 的所有元素添加到列表 ls 的末尾,无需创建新对象。 |
ls.clear() | 清空列表 ls 中的所有元素。 |
ls.copy() | 创建一个新的列表,复制列表 ls 中的所有元素。 |
ls.insert(i, x) | 在列表 ls 的第 i 个位置插入元素 x。 |
ls.pop(i) | 删除列表 ls 中第 i 个位置的元素,如果未指定 i,默认删除最后一个元素。不存在报错 ValueError |
ls.remove(x) | 删除列表 ls 中第一次出现的元素 x。如果没有找到,不报错。 |
6.2.2.2 列表推导式
列表推导式可以在一行代码中创建列表,而不需要显式编写循环,所以语法更加的简洁。列表推导式常见的用法,是对序列或可迭代对象中的每个元素应用某种操作,其一般形式如下:
new_list = [expression for item in iterable if condition]
new_list:将生成的新列表的名称。expression:定义如何转换和处理可迭代对象中的每个元素的表达式。item:代表可迭代对象中的每个元素的变量名。iterable:可迭代对象,可以是列表、元组、字符串、集合、字典的键等。condition(可选):用于筛选元素的条件,只有满足条件的元素才会包含在新列表中。
下面是一些列表推导式的示例,以帮助您更好地理解:
- 生成一个数字列表:
numbers = [x for x in range(1, 6)] # 生成1到5的数字列表[1, 2, 3, 4, 5]
- 从字符串中提取元音字母:
text = "Hello, World!"
vowels = [char for char in text if char.lower() in 'aeiou'] # 提取元音字母['e', 'o', 'o', 'o']
- 筛选元组:注意,下面代码中,for 和 if 的顺序相同
[(x, y) for x in [1,2,3] for y in [3,1,4] if x != y][(1, 3), (1, 4), (2, 3), (2, 1), (2, 4), (3, 1), (3, 4)]
这等价于:
combs = []
for x in [1,2,3]:for y in [3,1,4]:if x != y:combs.append((x, y))combs
- 使用嵌套函数
from math import pi
[str(round(pi, i)) for i in range(1, 6)]['3.1', '3.14', '3.142', '3.1416', '3.14159']
- 嵌套列表推导式: 列表推导式中的初始表达式可以是任何表达式,甚至可以是另一个列表推导式
matrix = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
flattened = [x for row in matrix for x in row] # 嵌套列表展开
matrix_T=[[row[i] for row in matrix] for i in range(4)] # 转置矩阵的行和列
打印出来结果如下:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[[1, 4, 7], [2, 5, 8], [3, 6, 9]]
实际应用中,最好用内置函数替代复杂的流程语句。此时,zip() 函数更好用:
list(zip(*matrix))
[(1, 4, 7), (2, 5, 8), (3, 6, 9)]
列表推导式不仅简化了代码,还提高了代码的可读性。但请注意,过度复杂的列表推导式可能会降低代码的可读性,因此在使用时要保持适度。如果列表推导式变得太复杂,可能更适合使用传统的循环结构。
习题:下面是由三重循环写出的矩阵乘法公式,请改写为列表推导式。
import numpy as np
M1 = np.random.rand(2,3)
M2 = np.random.rand(3,4)
res = np.empty((M1.shape[0],M2.shape[1]))
for i in range(M1.shape[0]):for j in range(M2.shape[1]):item = 0for k in range(M1.shape[1]):item += M1[i][k] * M2[k][j]res[i][j] = item((M1@M2 - res) < 1e-15).all() # 排除数值误差
#三层for循环就用三层列表,最外层for循环写在列表推导式的最外面
res=[[sum([M1[i][k]*M2[k][j] for k in range(M1.shape[1])]) for j in range(M2.shape[1])] for i in range(M1.shape[0])]
res=np.array(res)
res.shape, ((M1@M2 - res) < 1e-15).all()
6.3 字典
6.3.1 字典基本操作
字典是Python中非常重要且常用的数据结构之一,它允许您将数据存储为键-值对的集合。你可以使用花括号 {} 或者使用内置的 dict() 函数来创建字典。需要注意的是,字典中的键必须是不可变的,通常是字符串、整数或元组,而值可以是任何类型的数据。
要添加新的键值对,或者修改现有键的值,只需为字典指定新的键值对即可:
# 使用花括号创建字典
my_dict = {"name": "Alice", "age": 30, "city": "New York"}# 添加新的键值对
my_dict["email"] = "alice@example.com"# 修改现有键的值
my_dict["age"] = 31# 删除指定的键值对
del my_dict["city"]
以下是常见的字典操作:
| 操作/函数 | 说明 |
|---|---|
k in d | 判断键 k 是否在字典 d 中,如果存在返回 True,否则返回 False。 |
d.keys() | 返回字典 d 中所有的键信息,返回类型为 dict_keys,可以使用 list() 转换成列表。 |
d.values() | 返回字典 d 中所有的值信息,返回类型为 dict_values,可以使用 list() 转换成列表。 |
d.items() | 返回字典 d 中所有键值对信息,返回类型为 dict_items,可以使用 list() 转换成元组列表。 |
d.get(k, <default>) | 如果键 k 存在于字典中,则返回相应值,否则返回 <default> 值,默认返回 None。 |
d.pop(k, <default>) | 如果键 k 存在于字典中,则取出相应值,否则返回 <default> 值。 |
d.popitem() | 随机从字典 d 中取出一个键值对,以元组形式返回。 |
del d[k] | 删除字典 d 中 k 的键值对。如果键不存在,将引发 KeyError 错误。 |
d.clear() | 删除字典 d 中的所有键值对。 |
len(d) | 返回字典 d 中元素的个数。 |
sum(d) | 默认累加字典 d 的键值(前提是键是数字)。 |
6.3.2 字典推导式
字典推导式是一种用于创建字典的紧凑而强大的语法,类似于列表推导式。字典推导式的一般形式如下:
{key_expression: value_expression for item in iterable}
key_expression:用于计算字典键的表达式。value_expression:用于计算字典值的表达式。item:代表可迭代对象中的每个元素的变量名。iterable:可迭代对象,可以是列表、元组、字符串、集合等。
字典推导式会遍历可迭代对象中的每个元素,为每个元素计算键和值,然后构建一个新的字典。以下是一些字典推导式的示例:
- 从列表创建字典:
fruits = ["apple", "banana", "cherry"]
fruit_lengths = {fruit: len(fruit) for fruit in fruits}
# 结果:{'apple': 5, 'banana': 6, 'cherry': 6}
- 从两个列表创建字典:若两个列表元素数量不一致,以少的那个为基准生成字典
keys = ["a", "b", "c"]
values = [1, 2]
dictionary = {k: v for k, v in zip(keys, values)}
# 结果:{'a': 1, 'b': 2}
- 筛选出偶数并创建字典:
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9]
even_squared = {n: n**2 for n in numbers if n % 2 == 0}
# 结果:{2: 4, 4: 16, 6: 36, 8: 64}
- 从字符串创建字典:
text = "hello"
char_to_ord = {char: ord(char) for char in text}
# 结果:{'h': 104, 'e': 101, 'l': 108, 'o': 111}
6.3.3 统计三国出场人物,生成词云
- 这个是当初慕课上面Python语言程序设计里的一个示例,印象比较深,所以写一下。三国演义文本文件地址为:https://python123.io/resources/pye/threekingdoms.txt。
WordCloud生成中文词云会有乱码,可以在Google Fonts下载中文字体(ttf文件),然后在生成词云时指定字体路径。
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud# 1. 读取文本文件
with open('threekingdoms.txt', 'r', encoding='utf-8') as file:text = file.read()# 2. 使用jieba进行分词
words = jieba.cut(text)# 3. 创建一个字典来统计词频
word_counts = {}# 4. 统计词频
for word in words:if len(word)==1:continue elif word in ['诸葛亮','孔明曰']:rword='孔明'elif word in ['关公','云长']:rword='关羽'elif word in ['玄德','玄德曰']:rword='刘备'elif word in ['孟德','丞相']:rword='曹操'else:rword=word# get 方法接受一个键作为参数,如果键存在于字典中,则返回与该键关联的值,否则返回指定的默认值word_counts[rword] = word_counts.get(rword, 0) + 1# 5. 过滤非人名的高频词
exclude=['将军','却说','荆州','二人','不可','不能','如此','商议','主公','左右','如何','军士','军马','东吴','大喜','引兵', '次日', '天下', '于是', '今日', '不敢', '魏兵', '陛下', '一人', '都督', '人马', '不知', '汉中', '只见', '众将', '后主', '蜀兵', '上马', '大叫']
for word in exclude:del word_counts[word]# 6. 获取词频最高的前10个人物并打印
top_words = sorted(word_counts.items(), key=lambda x: x[1], reverse=True)[:10]
print("词频最高的前10个词:")
for word, count in top_words:print('{0:<10}{1:>5}'.format(word,count))# 7. 生成词云并显示
font_path ='MaShanZheng-Regular.ttf'
wordcloud = WordCloud(width=800, height=400, background_color='white',font_path=font_path).generate_from_frequencies(word_counts)plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()