爬虫是批量模拟网络请求的程序,想百度谷歌这种搜索类网站本质上就是爬虫
使用爬虫的时候不应该对别人的网站有严重的影响,比如你爬的频率太高了,让人家的网站崩溃了。不应该爬取网页上显示不到的内容,比如有一个直播的网站,人家显示的是热度值而不是具体人数,热度值是根据具体人数计算出来的,但是具体人数人家没展示在网页上,这个时候你不应该爬具体人数
目录
1 爬虫的分类
2 反爬机制与反反爬策略
3 robots.txt
4 加密方式
1 爬虫的分类
爬虫分为下面三类
- 通用爬虫:搜索引擎(百度谷歌这种)抓取系统的主要组成部分,通用爬虫抓取一整张页面的数据
- 聚焦爬虫:基于通用爬虫抓取整张页面数据后提取页面中特定的局部内容
- 增量式爬虫:检测网站中数据更新的情况,只抓取增量内容(新更新的数据)
2 反爬机制与反反爬策略
反爬机制:被爬的网站设置不让你爬的一些规则。比如被爬的网站就可以设置同一个mac码一秒中的访问数量不能超过两次
反反爬策略:想爬取网站的人规避反爬机制的策略。比如被爬的网站设置了同一个mac码访问频率,你就可以多搞几个mac码去访问,从而得到数据
爬虫是一门对抗类的技术,你想爬但没爬到你就输了,你想不让别人爬但是别人爬到了那你就输了。这种对抗类的技术如果你想成功率高的话需要投入很多,所以面对某一些反爬机制强的网站,及时的放弃不一定是坏事
3 robots.txt
网站被爬不全是坏事,网站被爬可以带来流量。但我们又不希望网站无限制被爬,这个时候就产生了robots.txt协议,robots.txt协议由被爬的网站注明,其中会写明网站哪些东西可以被爬,哪些东西不可以被爬。robots.txt中的内容对于代码没有任何约束,只是给人看的,你如果爬了robots.txt中的禁止爬取的内容人家可能会去法院告你
我们可以在网站的域名后加上 /robots.txt 来查看当前网站的robots.txt协议。比如百度,这里面就告诉你哪个路由你不能动

再比如淘宝,他的robots.txt就是百度不准爬跟路径,剩下的都能爬。如果你不是百度,那你根路径也能爬

4 加密方式
对称密钥加密:客户端或服务端把密钥与信息一起发到对方(客户端发给服务端,服务端发给客户端),然后由服务端解密。如果发送的过程中信息被捕获了,那么加密信息与密钥都会暴露,相当于信息泄露了
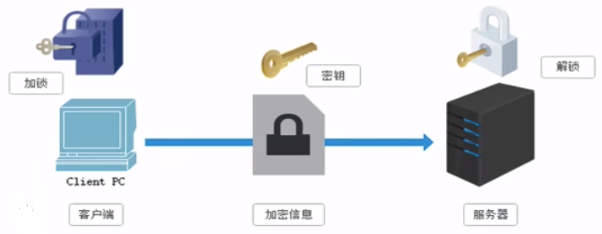
非对称密钥加密:A是客户端,B是服务端,总的来讲就是就是客户端与服务端都加密。如果发送的过程中信息被捕获了,信息不会泄露。客户端的的加密方式叫私钥,服务端的加密方式叫公钥
非对称密钥中没有私钥的传递
非对称密钥加密的缺点是,如果在 步骤2 被捕获了,也就是公钥暴露了,第三方就可以篡改公钥,导致客户端收到的响应不对。而且非对称加密的效率很低

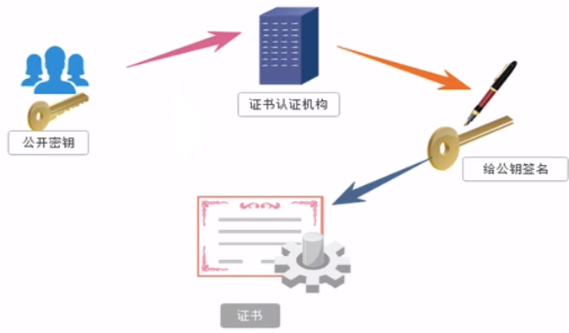
证书密钥加密:在对称加密的基础上对 步骤2 进行了改进,客户端先把密码发送给 证书认证机构,然后证书认证机构给公钥签名做防伪(签名后的公钥叫做证书),之后把证书发给服务端
证书密钥加密是https的加密方式