auto_increment的优点:
-
字段长度较uuid小很多,可以是bigint甚至是int类型,这对检索的性能会有所影响。
-
在写的方面,因为是自增的,所以主键是趋势自增的,也就是说新增的数据永远在后面,这点对于性能有很大的提升。
-
数据库自动编号,速度快,而且是增量增长,按顺序存放,对于检索非常有利。
-
数字型,占用空间小,易排序,在程序中传递也方便。
auto_increment的缺点:
-
由于是自增,很容易通过网络爬虫知晓当前系统的业务量。
-
高并发的情况下,竞争自增锁会降低数据库的吞吐能力。
-
数据迁移或分库分表场景下,自增方式不再适用。
UUID的优点:
-
不会冲突。进行数据拆分、合并存储的时候,能保证主键全局的唯一性
-
可以在应用层生成,提高数据库吞吐能力
UUID的缺点:
-
影响插入速度, 并且造成硬盘使用率低。与自增相比,最大的缺陷就是随机io,下面我们会去具体解释
-
字符串类型相比整数类型肯定更消耗空间,而且会比整数类型操作慢。
uuid 和自增 id 的索引结构对比
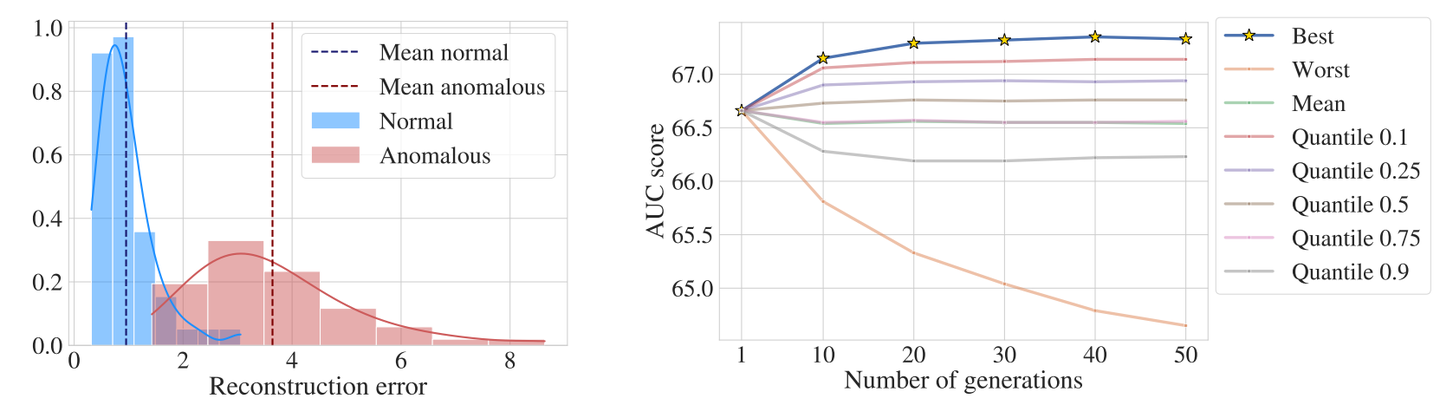
1、使用自增 id 的内部结构
自增的主键的值是顺序的,所以 InnoDB 把每一条记录都存储在一条记录的后面。
-
当达到页面的最大填充因子时候(InnoDB 默认的最大填充因子是页大小的 15/16,会留出 1/16 的空间留作以后的修改)。
-
下一条记录就会写入新的页中,一旦数据按照这种顺序的方式加载,主键页就会近乎于顺序的记录填满,提升了页面的最大填充率,不会有页的浪费。
-
新插入的行一定会在原有的最大数据行下一行,MySQL 定位和寻址很快,不会为计算新行的位置而做出额外的消耗。减少了页分裂和碎片的产生。
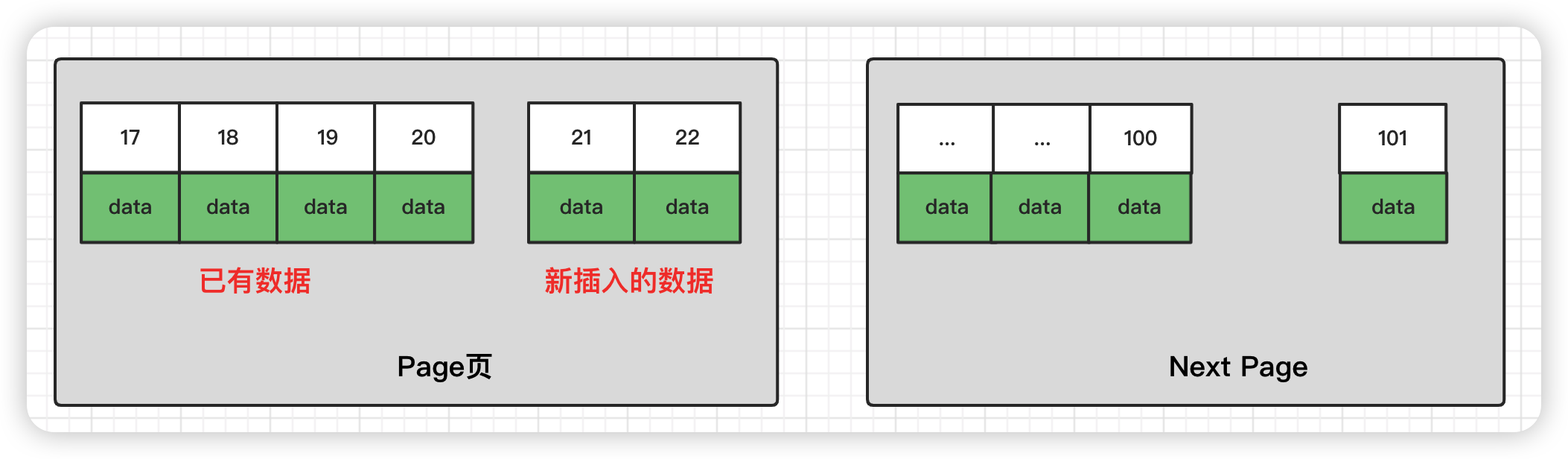
2、使用 uuid 的索引内部结构
插入UUID: 新的记录可能会插入之前记录的中间,因此需要移动之前的记录
被写满已经刷新到磁盘上的页可能会被重新读取

因为 uuid 相对顺序的自增 id 来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以 innodb 无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
-
写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb 在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机 IO。
-
因为写入是乱序的,innodb 不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,一次插入最少需要修改三个页以上。
-
由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片。
-
在把随机值(uuid 和雪花 id)载入到聚簇索引(InnoDB 默认的索引类型)以后,有时候会需要做一次 OPTIMEIZE TABLE 来重建表并优化页的填充,这将又需要一定的时间消耗。
结论:使用 InnoDB 应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行。如果是分库分表场景下,分布式主键ID的生成方案 优先选择雪花算法生成全局唯一主键(雪花算法生成的主键在一定程度上是有序的)。
知识来源:马士兵教育









![java八股文面试[数据库]——explain](https://img-blog.csdn.net/20131108110428796?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvemh1eGluZWxp/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70/gravity/SouthEast)