目标:使用 github 唐诗宋词数据库的 json 数据,训练一共唐诗生成器
数据源:https://github.com/chinese-poetry/chinese-poetry
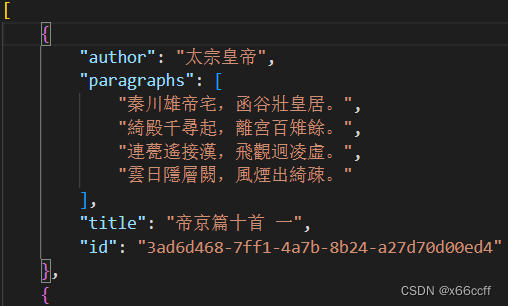
查看原始数据格式
原始数据包含 作者、正文、标题、id四个部分,这里仅仅使用诗词正文进行训练
制作唐诗数据集
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import json
path_tang = './tang/poet.tang.' # 读取 json 文件
def get_json(path):with open(path, 'r', encoding='utf-8') as f:data = json.load(f)return data# 对 ./tang/ 文件夹下的所有 json 文件进行遍历
import os# 获取文件夹下的所有文件名
def get_file_name(path):file_name = []for root, dirs, files in os.walk(path):for file in files:file_name.append(file)return file_name
file_name_ls = get_file_name('./tang/')
ret_ls = []for file_name in file_name_ls:ls = get_json('./tang/' + file_name)n_ls = len(ls)for i in range(n_ls):para = ls[i]['paragraphs']para = ''.join(para)ret_ls.append(para)
len(ret_ls) # 一共 57607 首诗歌
n_poet = len(ret_ls)
n_poet
查看前10首诗
for i in range(10):print(ret_ls[i])
秦川雄帝宅,函谷壯皇居。綺殿千尋起,離宮百雉餘。連甍遙接漢,飛觀迥凌虛。雲日隱層闕,風煙出綺疎。
巖廊罷機務,崇文聊駐輦。玉匣啓龍圖,金繩披鳳篆。韋編斷仍續,縹帙舒還卷。對此乃淹留,欹案觀墳典。
…
以茲遊觀極,悠然獨長想。披卷覽前蹤,撫躬尋既往。望古茅茨約,瞻今蘭殿廣。人道惡高危,虛心戒盈蕩。奉天竭誠敬,臨民思惠養。納善察忠諫,明科慎刑賞。六五誠難繼,四三非易仰。廣待淳化敷,方嗣云亭響。
进行 tokenizer 统计
# 全部合并成一个 string
str_all = ''.join(ret_ls)
str_all[:1000]
‘秦川雄帝宅,函谷壯皇居。綺殿千尋起,離宮百雉餘。連甍遙接漢,飛觀迥凌虛。雲日隱層闕,風煙出綺疎。巖廊罷機務,崇文聊駐輦。玉匣啓龍圖,金繩披鳳篆。韋編斷仍續,縹帙舒還卷。對此乃淹留,欹案觀墳典。移步出
…
百蠻奉遐賮,萬國朝未央。雖無舜禹迹,幸欣天地康。車軌同八表,書文混四方。赫奕儼冠蓋,紛綸盛服章。羽旄飛馳道,鐘鼓震巖廊。組練輝霞色,霜戟耀朝光。晨宵懷至理,終媿撫遐荒。壽丘惟舊跡,酆邑乃前基。粵予承累’
# 用 keras 的 Tokenizer 进行统计
from keras.preprocessing.text import Tokenizer# 设置最大词汇量为 10000 个词
tokenizer = Tokenizer(num_words=10000,char_level=True) # 注意:这里是 char_level=True,因为是字符级别的统计
# 在 str_all 上进行训练
tokenizer.fit_on_texts([str_all])
## 使用word_index属性查看每个词对应的编码
## 使用word_counts属性查看每个词对应的频数
for ii,iterm in enumerate(tokenizer.word_index.items()):if ii < 10:print(iterm)else:break
print("===================")
for ii,iterm in enumerate(tokenizer.word_counts.items()):if ii < 10:print(iterm)else:break
(‘,’, 1)
(‘。’, 2)
(‘不’, 3)
(‘人’, 4)
(‘一’, 5)
(‘無’, 6)
(‘山’, 7)
(‘風’, 8)
(‘日’, 9)
(‘有’, 10)
===================
(‘秦’, 1983)
(‘川’, 2503)
(‘雄’, 1060)
(‘帝’, 2099)
(‘宅’, 771)
(‘,’, 268814)
(‘函’, 268)
(‘谷’, 1301)
(‘壯’, 748)
(‘皇’, 1900)
制作数据集
# 制作数据集的方法:从 ret_ls 中,采样一首诗,然后从这首诗随机采样一个长度为 20 的子串,作为输入,然后预测下一个字符
# 数据集大小为 1w 样本对,采样方法是随机采样
import random
from tqdm import tqdm
x_seq_ls = []
y_seq_ls = []for i in tqdm(range(n_poet)):if len(ret_ls[i])-21<=0: # 如果这首诗歌的长度小于等于 21,就跳过continue# 随机选一个子串start = random.randint(0, len(ret_ls[i])-21)end = start + 20# 保存到 x_seq_ls 和 y_seq_ls 中x_seq_ls.append(ret_ls[i][start:end])y_seq_ls.append(ret_ls[i][end])100%|██████████| 57607/57607 [00:00<00:00, 654635.20it/s]
len(x_seq_ls),len(y_seq_ls)
(56294, 56294)
# 查看一下 x_seq_ls 和 y_seq_ls
for i in range(20):print(x_seq_ls[i],y_seq_ls[i])
綺殿千尋起,離宮百雉餘。連甍遙接漢,飛觀 迥
匣啓龍圖,金繩披鳳篆。韋編斷仍續,縹帙舒 還
電。驚雁落虛弦,啼猿悲急箭。閱賞誠多美, 於
…
輦駐新豐。紐落藤披架,花殘菊破叢。葉鋪荒 草
濟世豈邀名。星旂紛電舉,日羽肅天行。徧野 屯
參差影,寒猿斷續聲。冠蓋往來合,風塵朝夕 驚
# 把 x_seq_ls 和 y_seq_ls 用 tokenizer 进行编码x_token = tokenizer.texts_to_sequences(x_seq_ls)
y_token = tokenizer.texts_to_sequences(y_seq_ls)
# 查看一下 x_seq_ls 和 y_seq_ls
for i in range(20):print(x_token[i],y_token[i])
[854, 486, 68, 268, 183, 1, 187, 203, 182, 1953, 252, 2, 238, 3516, 283, 610, 210, 1, 87, 578] [1219]
[1599, 1378, 152, 629, 1, 56, 1814, 833, 326, 2625, 2, 2001, 1248, 258, 692, 1131, 1, 2359, 2958, 1306] [103]
[1585, 2, 265, 606, 74, 299, 613, 1, 513, 1062, 304, 636, 1289, 2, 2161, 723, 855, 58, 603, 1] [362]
…
[1479, 1061, 96, 1270, 2, 4298, 74, 1361, 833, 1862, 1, 18, 278, 891, 582, 739, 2, 181, 1527, 485] [95]
[1021, 189, 260, 1533, 134, 2, 286, 3148, 624, 1585, 663, 1, 9, 483, 1127, 12, 38, 2, 1396, 214] [1978]
[695, 872, 243, 1, 71, 1062, 258, 1131, 69, 2, 707, 789, 402, 13, 309, 1, 8, 153, 79, 325] [265]
# 转化为 numpy
x_mat = np.array(x_token)
y_mat = np.array(y_token)
# 查看一下 x_seq_ls 和 y_seq_ls
for i in range(20):print(x_mat[i],y_mat[i])
[ 854 486 68 268 183 1 187 203 182 1953 252 2 238 3516
283 610 210 1 87 578] [1219]
[1599 1378 152 629 1 56 1814 833 326 2625 2 2001 1248 258
692 1131 1 2359 2958 1306] [103]
…
[1021 189 260 1533 134 2 286 3148 624 1585 663 1 9 483
1127 12 38 2 1396 214] [1978]
[ 695 872 243 1 71 1062 258 1131 69 2 707 789 402 13
309 1 8 153 79 325] [265]
查看数据集形状
x_mat,x_mat.shape
(array([[ 854, 486, 68, …, 1, 87, 578],
[1599, 1378, 152, …, 2359, 2958, 1306],
[1585, 2, 265, …, 58, 603, 1],
…,
[ 781, 1, 644, …, 1, 103, 155],
[ 108, 552, 819, …, 472, 231, 231],
[ 19, 165, 2, …, 12, 14, 794]]),
(56294, 20))
y_mat,y_mat.shape
(array([[1219],
[ 103],
[ 362],
…,
[ 4],
[ 145],
[ 1]]),
(56294, 1))
划分训练集、测试集
# 用 sklearn 对数据集进行划分
from sklearn.model_selection import train_test_split
# 划分为训练集和测试集(7:3)
x_train, x_test, y_train, y_test = train_test_split(x_mat, y_mat, test_size=0.3, random_state=42, shuffle=True)
x_train.shape, x_test.shape, y_train.shape, y_test.shape
((39405, 20), (16889, 20), (39405, 1), (16889, 1))
训练模型
搭建网络
# 开始搭建网络
from keras.models import Sequential
from keras.layers import Dense, Embedding, LSTM, Dropout
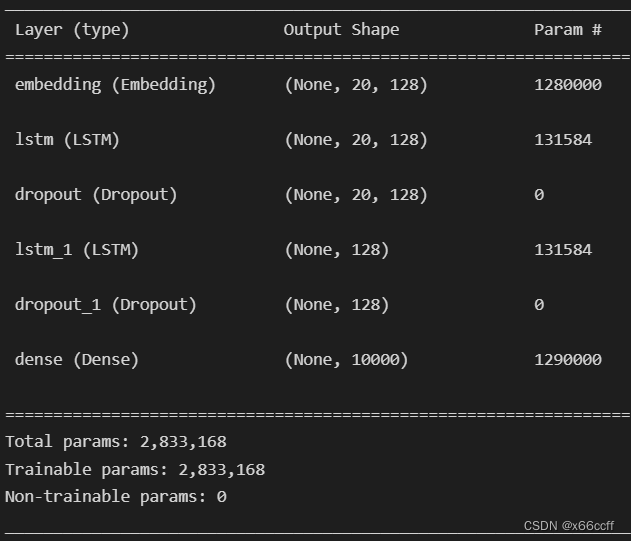
from keras.optimizers import Adammodel = Sequential()
model.add(Embedding(10000, 128, input_length=20))
model.add(LSTM(128, return_sequences=True))
model.add(Dropout(0.2))
model.add(LSTM(128))
model.add(Dropout(0.2))
model.add(Dense(10000, activation='softmax'))# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=Adam(learning_rate=0.001), metrics=['accuracy'])
model.summary()
# 测试样本能否正常输入网络
pred = model.predict(x_train[:1])
pred.shape
(1, 10000)
# y 标签转化为 one-hot 编码 (因为使用的损失函数是 categorical_crossentropy,而不是 sparse_categorical_crossentropy)
# 如果使用 sparse_categorical_crossentropy,就不需要转化为 one-hot 编码
# 【重要】from keras.utils import to_categorical
y_train_onehot = to_categorical(y_train, num_classes=10000)
y_test_onehot = to_categorical(y_test, num_classes=10000)
# 开始训练
history = model.fit(x_train, y_train_onehot, batch_size=32, epochs=40, validation_data=(x_test, y_test_onehot))
保存模型 和 tokenizer
# 保存模型
model.save('tang_poet_LSTM_v1.h5')
# 保存 tokenizer
import pickle
# saving
with open('tokenizer_tang_poet_LSTM_v1.pkl', 'wb') as f: pickle.dump(tokenizer, f) 测试模型
test_string = '白日依山盡,黃河入海流,欲窮千里目,更上一'for i in range(300):# 循环100步,每步生成一个字符test_string_token = tokenizer.texts_to_sequences([test_string[-20:]])test_string_mat = np.array(test_string_token)pred = model.predict(test_string_mat)pred_argmax = np.argmax(pred, axis=1)[0]# 把 pred_argmax 对应的词语找出来tokenizer.index_word[pred_argmax]test_string = test_string + tokenizer.index_word[pred_argmax]
test_string
繁体输出
‘白日依山盡,黃河入海流,欲窮千里目,更上一拙羣。胡杯越泛起。自恐承雙苔,未由不相聽。況思無里息,無里白雲疎。早石侵飯客,天風亦相然。更知何處在,病路得成情。羽縫當貴者,不知無子娛,何年何處在?晨棄信音名。但見千年在,病酒洞花香。況思不未盡,歸處亦無然。韜知如揀咽郡,霜區隔柴陽。況月未相至,風寡獨相然。何日明雲久,歸郭得杉空。彈穴螢浦色,秋月入樓花。獨道分霖水,歸郭亦離春。臥寢分傳日,美人見此塵。獨思千情客,不知不相過。況思無限客,不知亦不然。更知如此在,目我是公情。獨憶分霖色,搖連隔鏡稀。歛暖沙野續,風雲不不經。何日空空急,風山一北花。況思分氣散,花聲蜀翠翎。風水白山月,歸郭雪頭風。獨照塵峰外,秋痕入抽湯。短苒崦亭裏,韶悵滿羅氳。自得’
简体输出
‘白日依山尽,黄河入海流,欲穷千里目,更上一拙羣。胡杯越泛起。自恐承双苔,未由不相听。况思无里息,无里白云疎。早石侵饭客,天风亦相然。更知何处在,病路得成情。羽缝当贵者,不知无子娱,何年何处在?晨弃信音名。但见千年在,病酒洞花香。况思不未尽,归处亦无然。韬知如拣咽郡,霜区隔柴阳。况月未相至,风寡独相然。何日明云久,归郭得杉空。弹穴萤浦色,秋月入楼花。独道分霖水,归郭亦离春。卧寝分传日,美人见此尘。独思千情客,不知不相过。况思无限客,不知亦不然。更知如此在,目我是公情。独忆分霖色,摇连隔镜稀。歛暖沙野续,风云不不经。何日空空急,风山一北花。况思分气散,花声蜀翠翎。风水白山月,归郭雪头风。独照尘峰外,秋痕入抽汤。短苒崦亭里,韶怅满罗氲。自得’