目录
- 一、消费者组案例
- 1.1、案例需求
- 1.2、案例代码
- 1.2.1、消费者1代码
- 1.2.2、消费者2代码
- 1.2.3、消费者3代码
- 1.2.4、生产者代码
- 1.3、测试
一、消费者组案例
1.1、案例需求
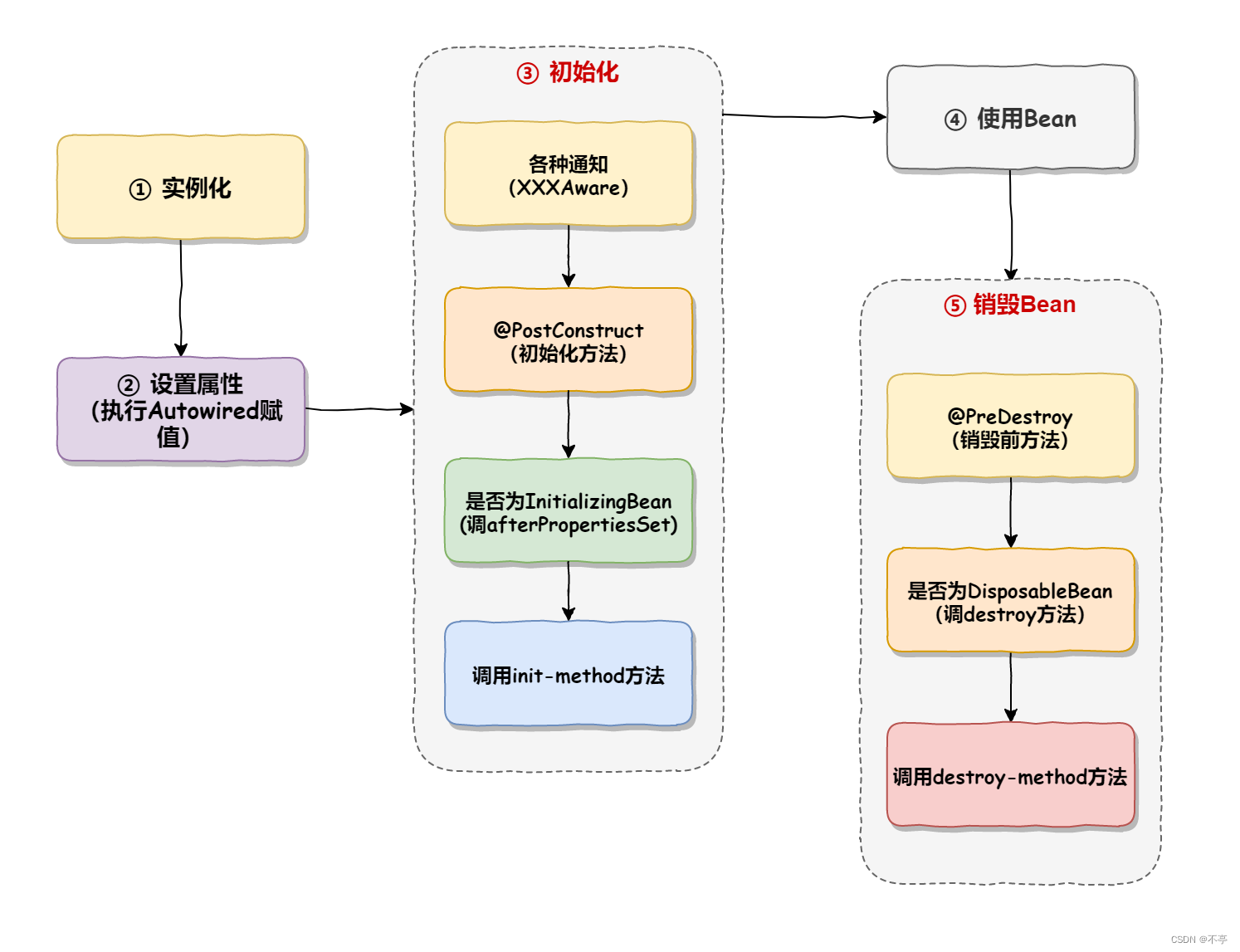
- 测试同一个主题的分区数据,只能由一个消费者组中的一个消费。如下图所示:

1.2、案例代码
复制一份基础消费者的代码,在 IDEA 中同时启动,即可启动同一个消费者组中的两个消费者。
1.2.1、消费者1代码
-
代码
package com.xz.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration; import java.util.ArrayList; import java.util.Properties;public class CustomConsumer1 {public static void main(String[] args) {// 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.27:9092,192.168.136.28:9092,192.168.136.29:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test5");// 设置分区分配策略properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("firstTopic");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){//每一秒拉取一次数据ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));//输出数据for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}kafkaConsumer.commitAsync();}} }
1.2.2、消费者2代码
-
代码
package com.xz.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration; import java.util.ArrayList; import java.util.Properties;public class CustomConsumer2 {public static void main(String[] args) {// 0 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.27:9092,192.168.136.28:9092,192.168.136.29:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test5");// 设置分区分配策略properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("firstTopic");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}}} }
1.2.3、消费者3代码
-
代码
package com.xz.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration; import java.util.ArrayList; import java.util.Properties;public class CustomConsumer3 {public static void main(String[] args) {// 配置Properties properties = new Properties();// 连接 bootstrap.serversproperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.27:9092,192.168.136.28:9092,192.168.136.29:9092");// 反序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 配置消费者组idproperties.put(ConsumerConfig.GROUP_ID_CONFIG,"test5");// 设置分区分配策略properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"org.apache.kafka.clients.consumer.StickyAssignor");// 1 创建一个消费者 "", "hello"KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);// 2 订阅主题 firstArrayList<String> topics = new ArrayList<>();topics.add("firstTopic");kafkaConsumer.subscribe(topics);// 3 消费数据while (true){//每一秒拉取一次数据ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));//输出数据for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {System.out.println(consumerRecord);}kafkaConsumer.commitAsync();}} }
1.2.4、生产者代码
-
代码
package com.xz.kafka.producer;import org.apache.kafka.clients.producer.*; import org.apache.kafka.common.serialization.StringSerializer; import java.util.Properties;public class CustomProducerCallback {public static void main(String[] args) throws InterruptedException {//1、创建 kafka 生产者的配置对象Properties properties = new Properties();//2、给 kafka 配置对象添加配置信息:bootstrap.serversproperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.136.27:9092,192.168.136.28:9092,192.168.136.29:9092");//3、指定对应的key和value的序列化类型 key.serializer value.serializerproperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,StringSerializer.class.getName());//4、创建 kafka 生产者对象KafkaProducer<String, String> kafkaProducer = new KafkaProducer<>(properties);//5、调用 send 方法,发送消息for (int i = 0; i < 200; i++) {kafkaProducer.send(new ProducerRecord<>("firstTopic", "hello kafka" + i), new Callback() {@Overridepublic void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null){System.out.println("主题: "+metadata.topic() + " 分区: "+ metadata.partition());}}});Thread.sleep(2);}// 3 关闭资源kafkaProducer.close();} }
1.3、测试
-
在 Kafka 集群控制台,创建firstTopic主题
bin/kafka-topics.sh --bootstrap-server 192.168.136.27:9092 --create --partitions 3 --replication-factor 1 --topic firstTopic
-
首先,在 IDEA中分别启动消费者1、消费者2和消费者3代码
-
然后,在 IDEA中分别启动生产者代码
-
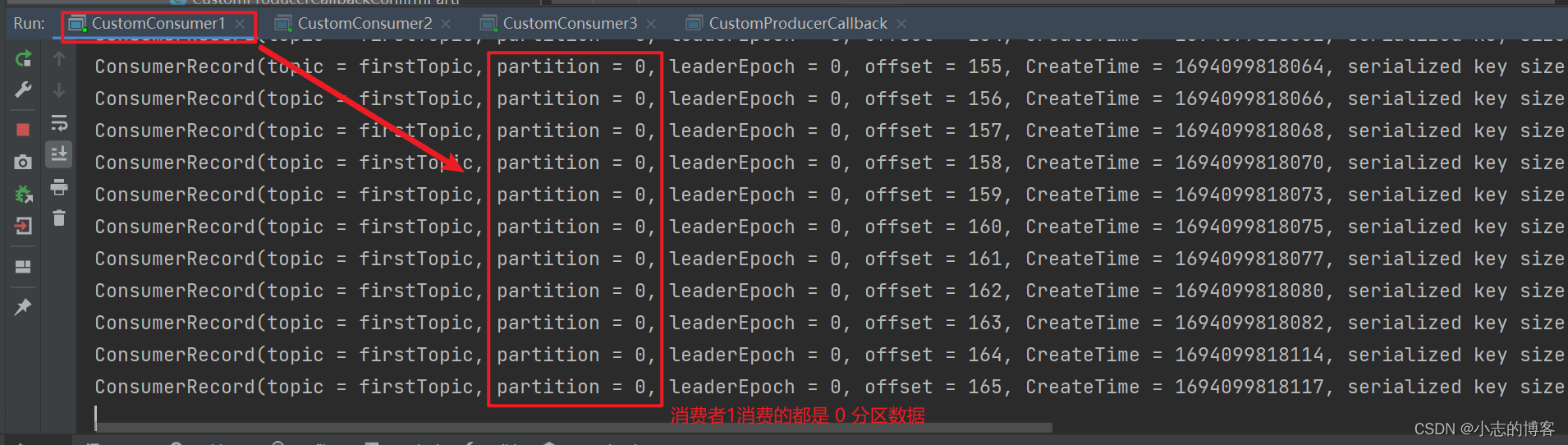
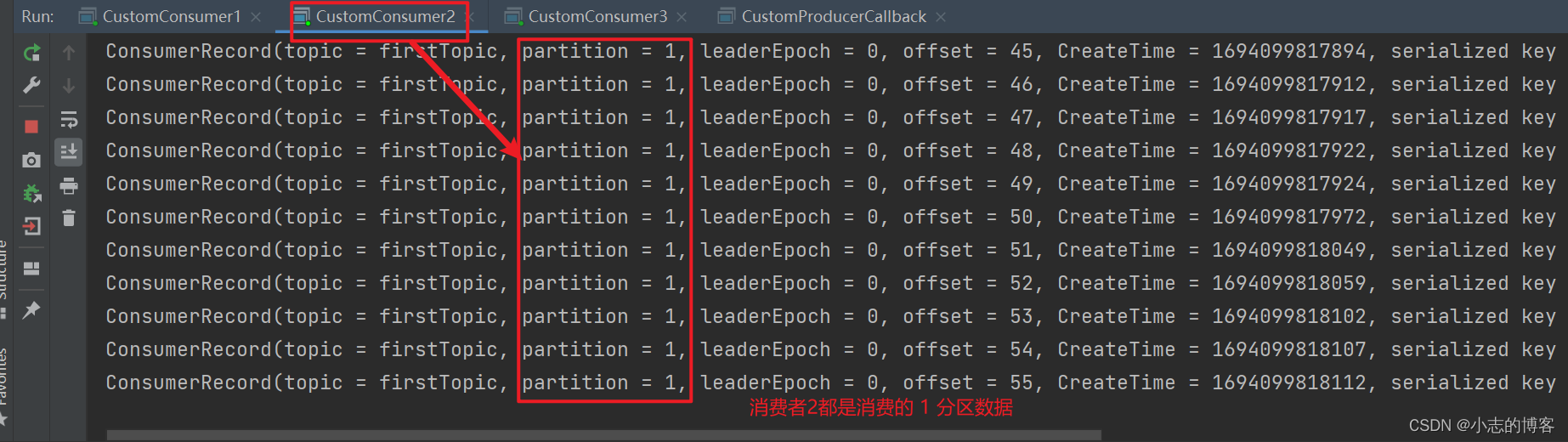
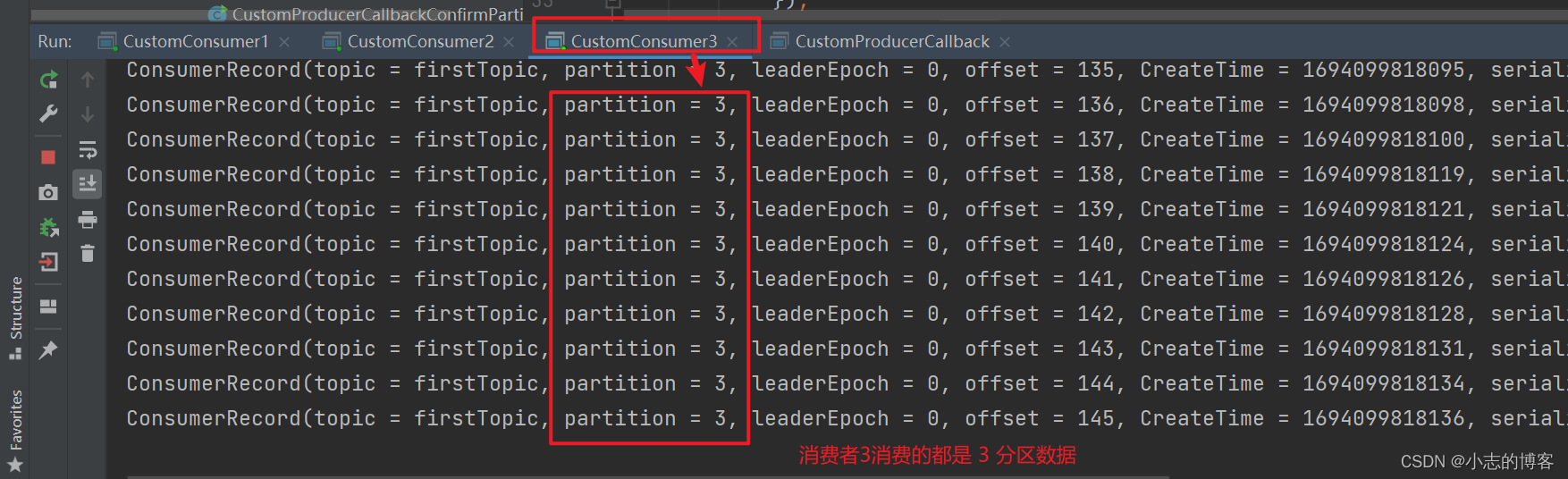
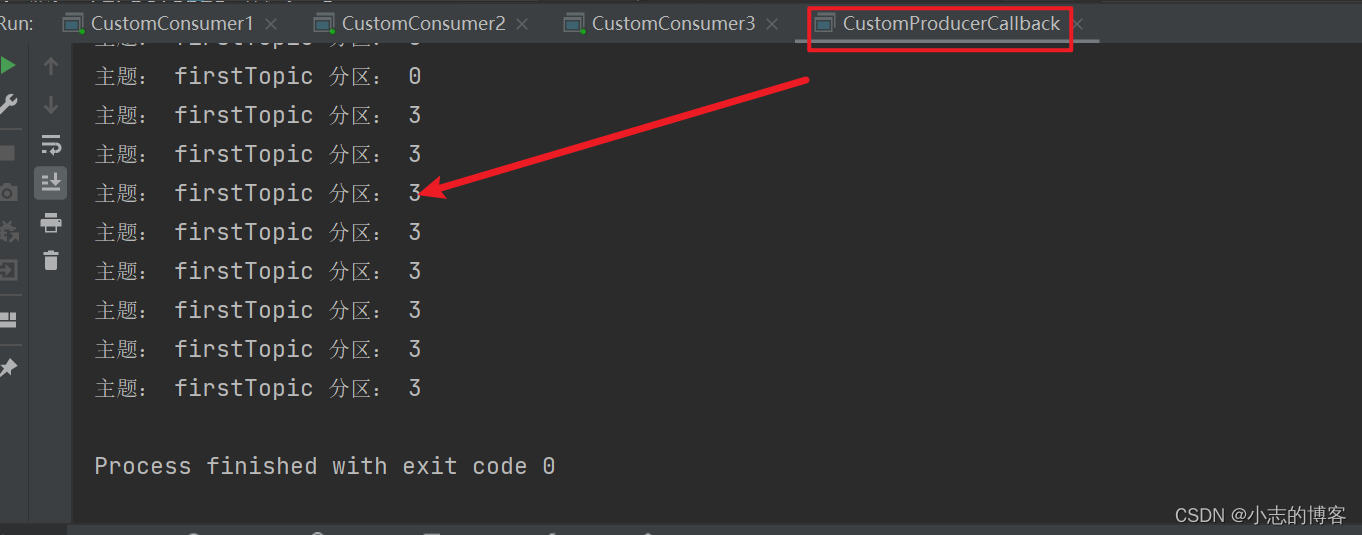
在 IDEA 控制台观察消费者1、消费者2和消费者3控制台接收到的数据,如下图所示:
由下图可知:3个消费者在消费不同分区的数据