本文介绍的是使用redis的HyperLoglog实现uv的统计功能。
背景
首先我们先明确一下uv这个名词代表的实际意义。uv代表的是通过网页访问浏览的人数,和文章的阅读量差不多,但是需要注意的是,一个人即使是多次访问,也只算一次。
所以,这种统计uv的方式放在后端的代码来做的话就会有一些大才小用了。建议使用redis的HpyerLoglog来实现统计。相信又有伙伴来疑问了,为什么不用redis的set来做呢?先来看看HperLoglog的使用场景吧,这是一个被忽略但是很好用的redis数据类型。
HyperLoglog
Redis HyperLogLog(HLL)是一种基数估计算法,用于近似计算大数据集中的不同元素数量。它可以提供接近精确计数的结果,但只使用很小的存储空间。
HyperLogLog 使用一种概率性算法来估计基数。它通过将元素的哈希值映射到一个固定长度的位数组中,并利用一些特定的位操作来计算基数的近似值。在 Redis 中,HyperLogLog 数据结构可以存储多个不同集合的基数。
以下是使用 Redis HyperLogLog 的一些常见操作:
-
PFADD key element [element ...]:向HyperLogLog数据结构中添加一个或多个元素。
示例:PFADD hllset "element1" "element2" "element3" -
PFCOUNT key [key ...]:返回 HyperLogLog 数据结构中估计的基数。
示例:PFCOUNT hllset -
PFMERGE destkey sourcekey [sourcekey ...]:将多个 HyperLogLog 数据结构合并为一个新的 HyperLogLog 数据结构。
示例:PFMERGE mergedset hllset1 hllset2
Redis 的 HyperLogLog 功能非常适合在需要对海量数据进行去重或计数时使用。它的特点是存储空间小,执行速度快,并且近似计数的误差范围可配置。但要注意,由于是基于概率性算法,它在计数结果上可能会存在一定的误差,因此不能用于精确计数场景。
所以,根据以上的表述,统计uv的场景就非常适合用HyperLoglog来做。
命令行测试
说了这么多,先来命令行测试一下效果吧。
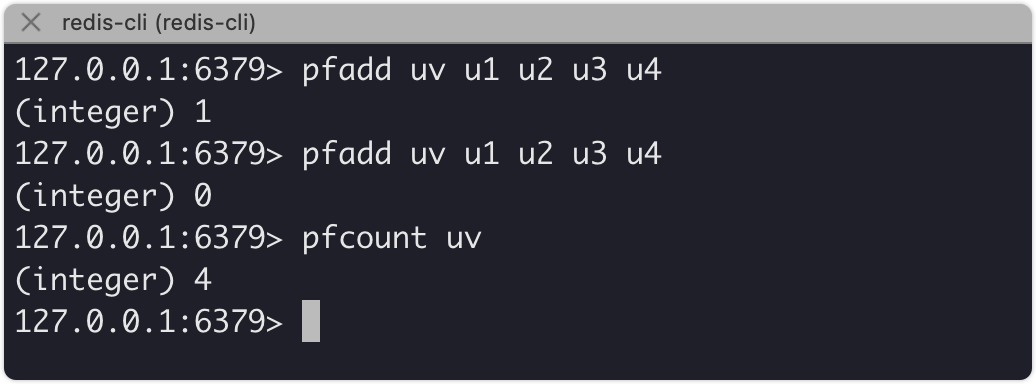
明显的看到了确实去重复了,下边我们用代码演示一下。
代码测试
我直接展示我的测试代码吧。

这里的逻辑就是批量的插入100w个用户的访问,最后获得nv的值。我这边的多次测试结果都在1001048左右,也就是说多了1000左右的数据是不正确的,但是这不影响nv的评估和统计。
好了,以上就是今天的分享了,感谢伙伴们的阅读。
与shigen一起,每天不一样!



![[Linux]动静态库](https://img-blog.csdnimg.cn/img_convert/e275ac4cd796029cfb49e93ce8c23945.png)