文章目录
- 前言
- 一、redis使用场景
- 1. 知识分布
- 2. 缓存穿透
- ① 问题引入
- ② 举例说明
- ③ 解决方案
- ④ 实战面试
- 3. 缓存击穿
- ① 问题引入
- ② 举例说明
- ③ 解决方案
- ④ 实战面试
- 4. 缓存雪崩
- ① 问题引入
- ② 举例说明
- ③ 解决方案
- ④ 实战面试
- 5. 缓存-双写一致性
- ① 问题引入
- ② 举例说明
- ③ 解决方案
- ④ 实战面试
- 6. 缓存-持久化
- ① 问题引入
- ② Redis持久化-RDB(数据备份文件)
- ③ Redis持久化-AOF(追加文件)
- ④ RDB与AOF对比
- ⑤ 实战面试
- 7. 缓存-数据过期策略
- ① 问题引入
- ② Redis数据删除策略-惰性删除
- ③ Redis数据删除策略-定期删除
- ④ Redis的数据过期策略总结
- ⑤ 实战面试
- 8. 缓存-数据淘汰策略
- ① 问题引入
- ② 选择删除的Key-8种策略
- ③ 其他面试问题
- ④ 数据淘汰策略总结
- ⑤ 实战面试
- 二、Redis分布式锁
- 1. 使用场景
- ① 问题引入
- ② 举例说明-抢卷场景
- 2. 实现原理(setnx、redisson)
- ① setnx实现分布式锁
- ② redisson实现分布式锁
- 3. 分布式锁总结
- ① 问题总结
- ② 实战面试
- 三、Redis的其他面试问题
- 1. 主从复制(高并发)
- ① 问题引入
- ② 主从数据同步原理
- ③ 问题总结
- ④ 实战面试
- 2. 哨兵模式(髙可用)
- ① 哨兵的作用
- ② 服务状态监控
- ③ Redis集群(哨兵模式)脑裂
- ④ 问题总结
- ⑤ 实战面试
- 3. 分片集群(海量数据存储)
- ① 问题引入
- ② 分片集群结构
- ③ 分片集群的数据读写
- ④ 问题总结
- ⑤ 实战面试
- 4. Redis单线程
- ① 问题引入
- ② 用户空间与内核空间
- ③ 阻塞IO与非阻塞IO
- ④ IO多路复用
- ⑤ Redis网络模型
- ⑥ 问题总结
- ⑦ 实战面试
- 引用声明
前言
本文主要记录redis的缓存穿透、缓存击穿、缓存雪崩、双写一致性、持久化、数据过期策略、数据淘汰策略、分布式锁等问题的分析与面试回答示例。
提示:以下是本篇文章正文内容,下面案例可供参考
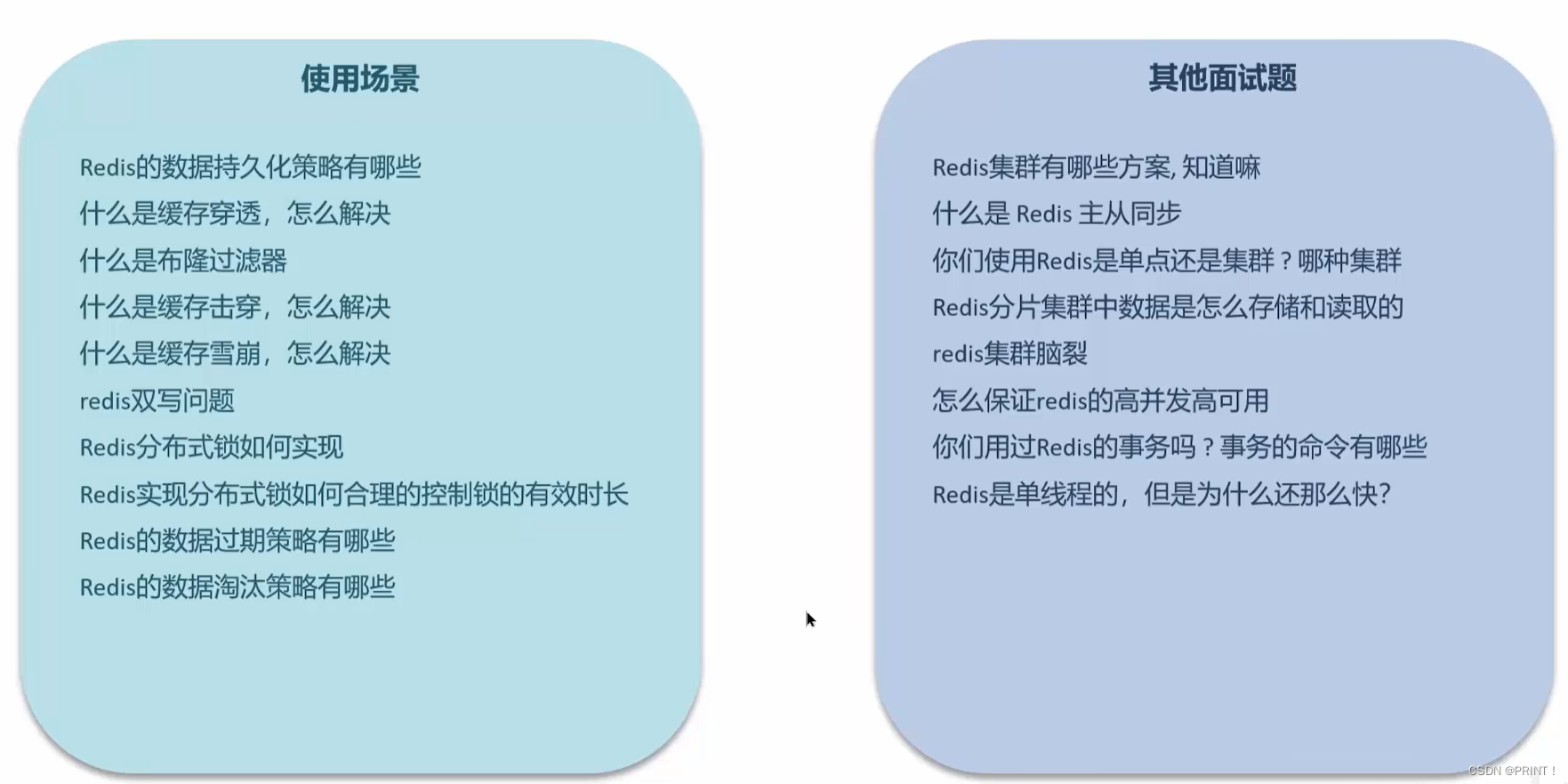
一、redis使用场景
1. 知识分布


2. 缓存穿透
① 问题引入

② 举例说明
一个get请求路径:api/news/getById/1
从数据库中查询到了数据并加载到redis缓存,直接查询redis中的数据,查询到了就返回结果,否则查数据库,具体流程如下:
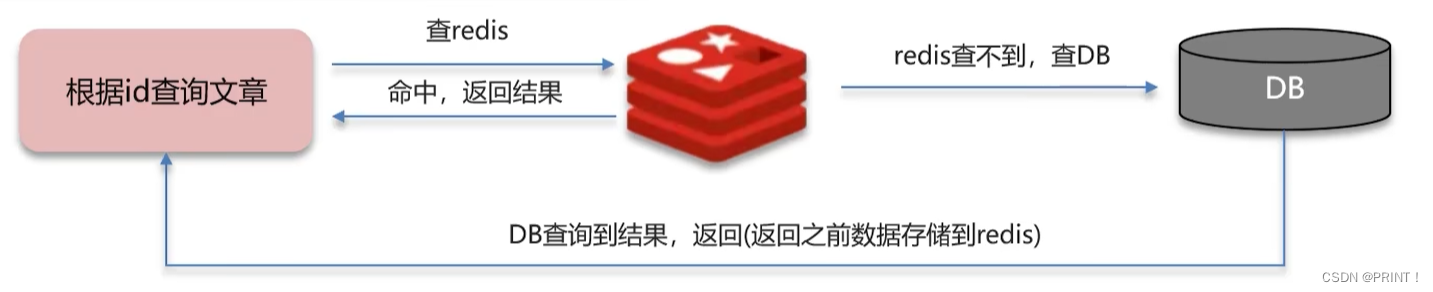
缓存穿透:查询一个不存在的数据,mysql查询不到数据也不会直接写入缓存,就会导致每次请求都查数据库,给数据库增加压力。
③ 解决方案
方案一:缓存空数据,查询返回的数据为空,仍把这个空结果进行缓存
优点:简单
缺点:消耗内存,可能数据库数据已经修改,但是redis中还是之前的空数据
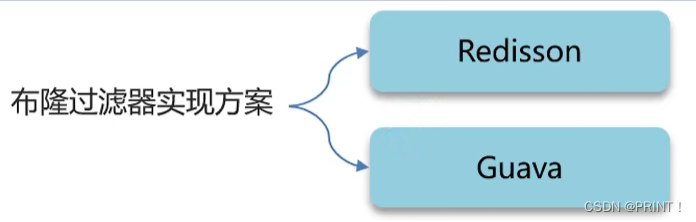
方案二:布隆过滤器,拦截不存在的数据
优点:内存占用较少,没有多余的key
缺点:实现复杂,存在误判

补充:
在添加数据到数据库时,也需要添加到redis、布隆过滤器中
布隆过滤器依赖bitmap(位图):一个以(bit)位为单位的数组,只能存储二进制(0、1)

布隆过滤器的作用:用于检索一个元素是否在一个集合中。
比如添加一个id=1的数据,经过哈希函数计算,将0改为1,表示存在数据。

当id=1和id=2都存在,但是id=3不存在,经过hash函数计算得到的结果是存在,这就是误判。
误判率:数组越小误判率就越大,数组越大误判率就越小,但是同时带了了更多的内存消耗。

布隆过滤器的实现中我们可以控制误判率(5%之内)
④ 实战面试

3. 缓存击穿
① 问题引入

② 举例说明
缓存击穿: 当某一个热门的key设置了过期时间,当key过期的时候,恰好这个时间点对这个key有大量的并发请求过来,redis缓存重建的过程比较慢,这些并发请求可能会瞬间把数据库压垮。

③ 解决方案
**方案一:**互斥锁
优点:数据强一致
缺点:性能查
补充:当线程1在缓存的过程中,其他线程只能等待;当线程1把数据缓存成功,其他的线程就可以获取到数据

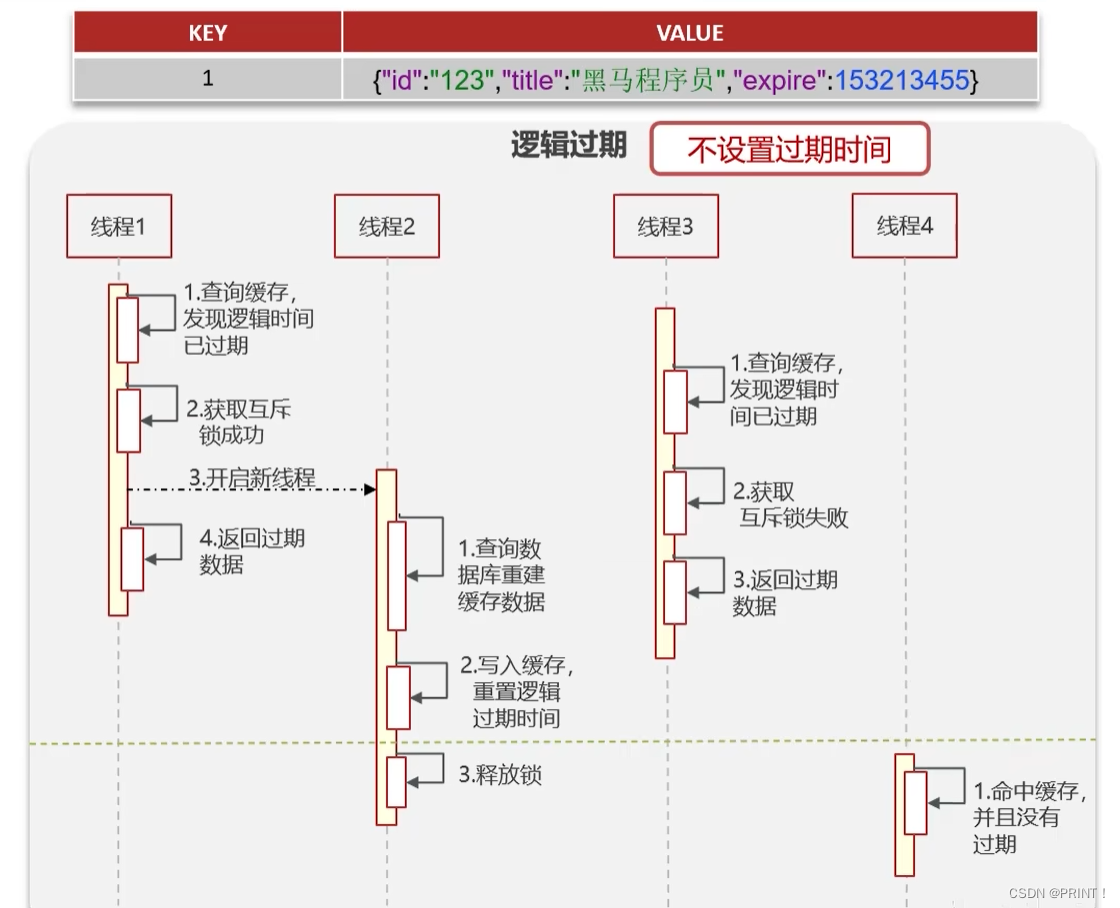
方案二: 逻辑过期
优点:高可用,保证查询效率
缺点:不能保证数据绝对一致
补充:当线程2没有将最新数据加入到缓存之前,所有的线程获取的都是过期数据,当线程2将数据更新完成后,所有的线程获取到最新数据。
④ 实战面试

4. 缓存雪崩
① 问题引入
② 举例说明
缓存雪崩: 是指在同一时段大量的缓存key同时失效或者Redis服务宕机导致大量请求到达数据库,带来巨大压力。

③ 解决方案
方案一:
情况:大量的缓存key同时失效
方法:给不同的key设置不同的过期时间,在原有的时间基础上再加一个随机时间值;
方案二:
情况:大量的缓存key同时失效
方法:给业务添加多级缓存;
方案三:
情况:Redis服务宕机
方法:利用Redis集群提高服务的可用性,比如哨兵模式、集群模式。
方案四:
情况:降级作为系统保底策略,适用于穿透、击穿、雪崩
方法:给缓存业务添加降级限流策略,比如nginx或者springcloud gateway
④ 实战面试

5. 缓存-双写一致性
① 问题引入

② 举例说明
双写一致性: 当修改了数据库的数据也要同时更新缓存的数据,缓存和数据库的数据要保持一致。
读操作:缓存命中,直接返回;缓存未命中查询数据库,写入缓存,设定超时时间。

写操作:延迟双删

- 先删除缓存还是先删除数据库?
情况一:先删除缓存,再操作数据库,可能会出现脏数据
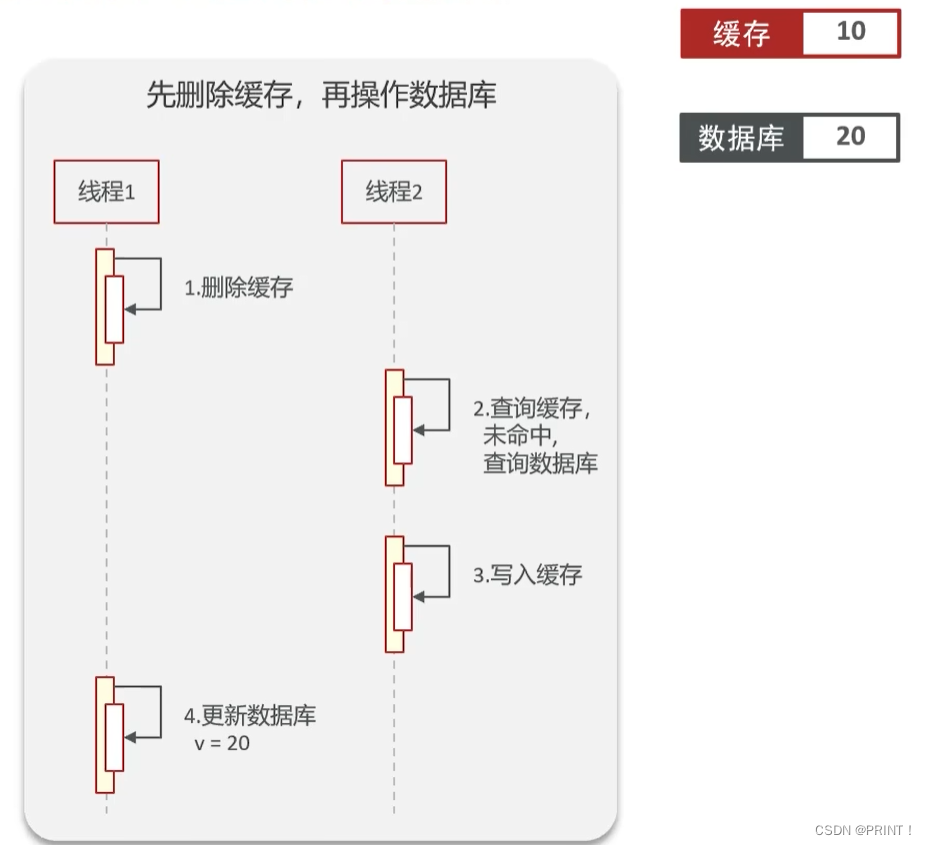
情况二:先操作数据库,再删除缓存,也可能会出现脏数据

- 为什么要删除两次缓存?
降低脏数据的出现 - 为什么要延时删除?
数据库是主从分离的,延时把同步数据,也可能出现脏数据
③ 解决方案
方案一: 分布式锁
优点:保证强一致性
缺点:性能低
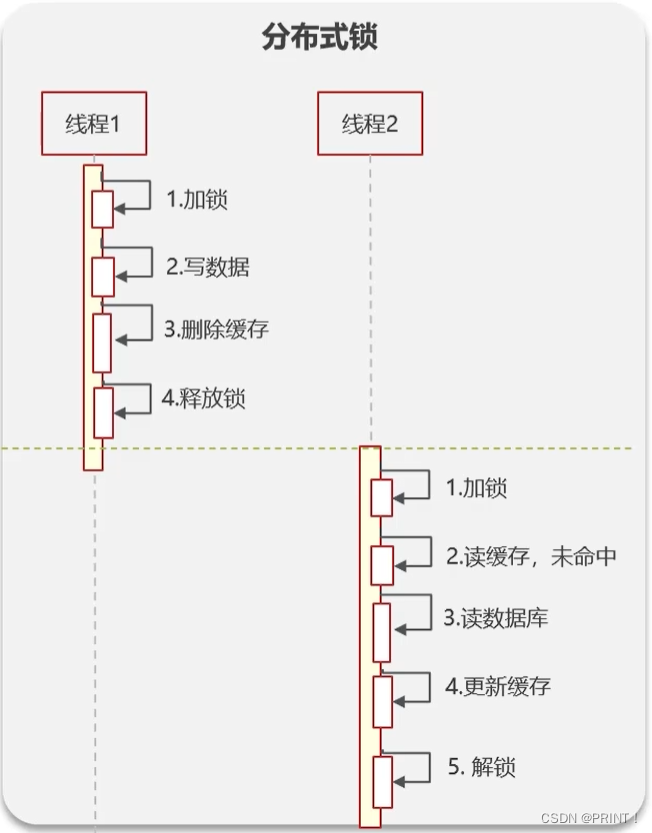
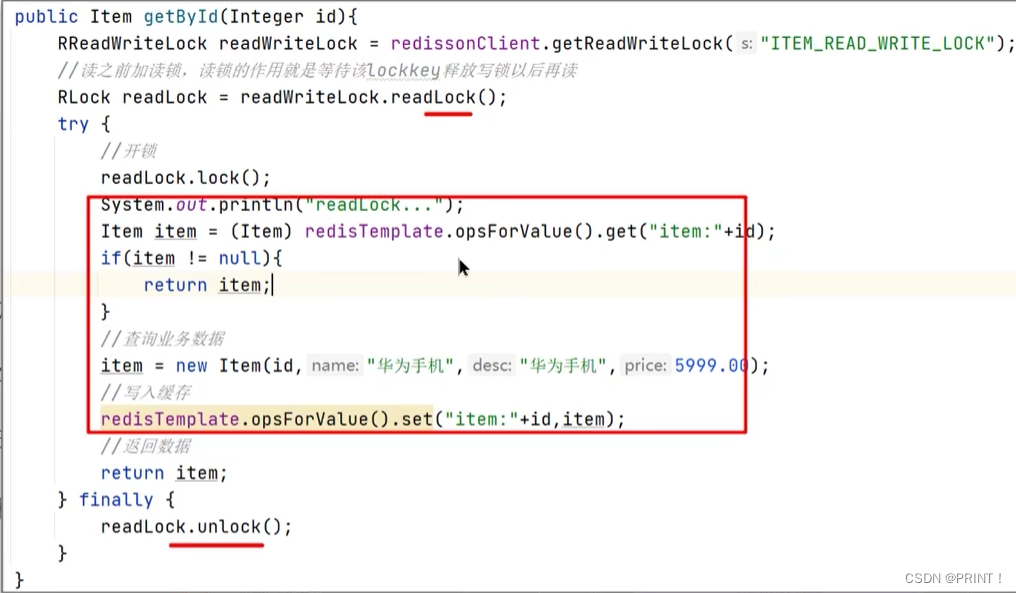
方案二: 共享锁与排他锁(优化版)
优点:保证数据强一致性
共享锁:读锁readLock,加锁之后,其他线程可以共享读操作
排他锁:独占锁writeLock也叫,加锁之后,阻塞其他线程读写操作
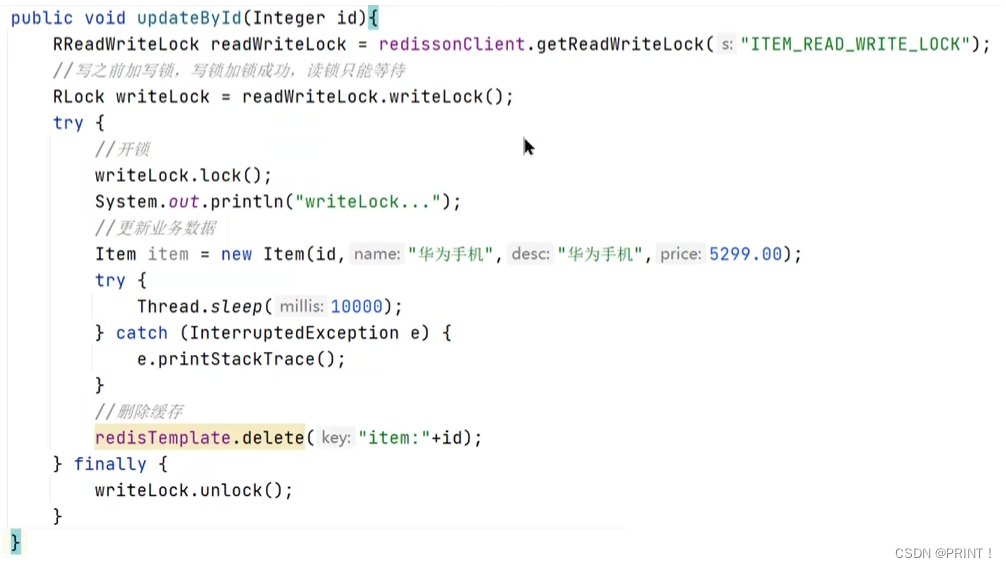
方案三: MQ异步通知
优点:保证数据的一致性
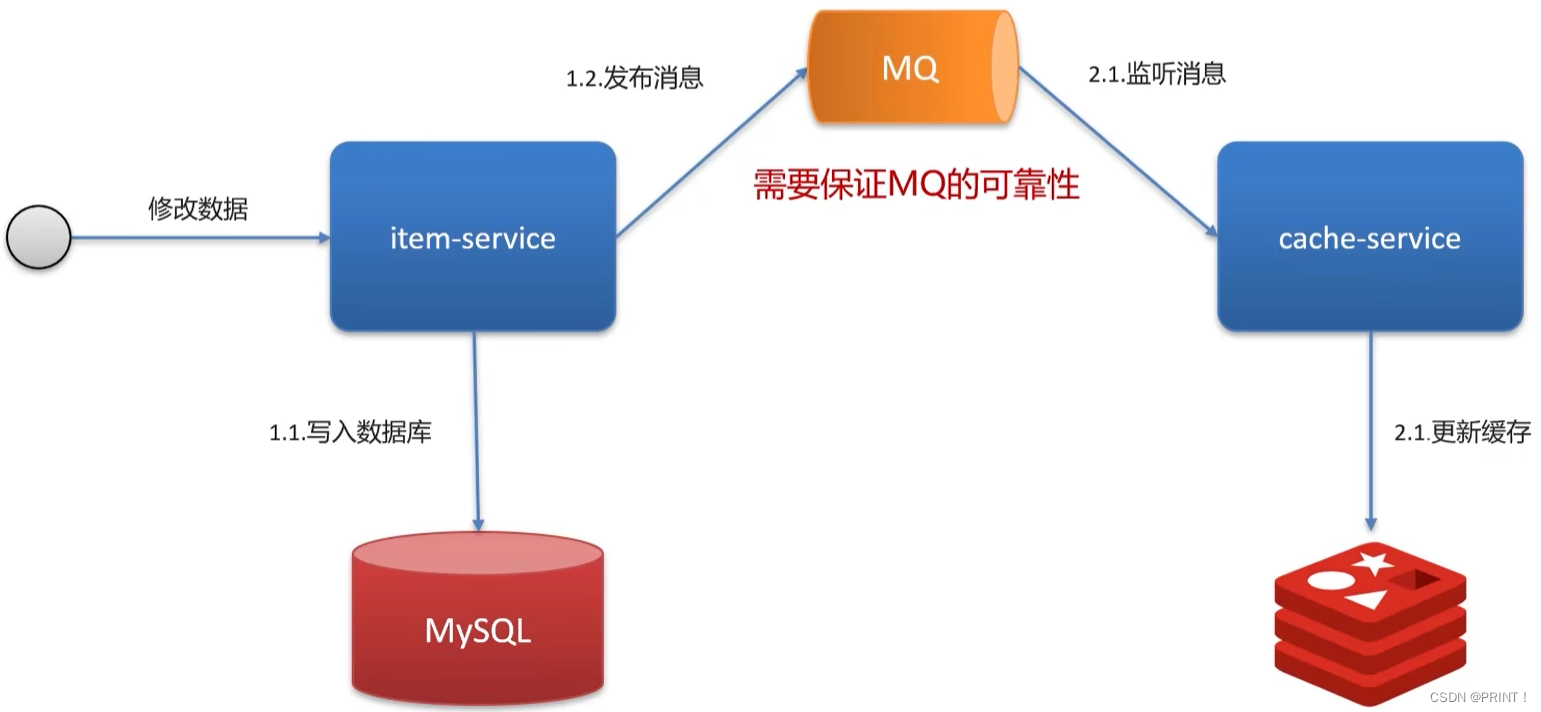
方案四: Canal异步通知
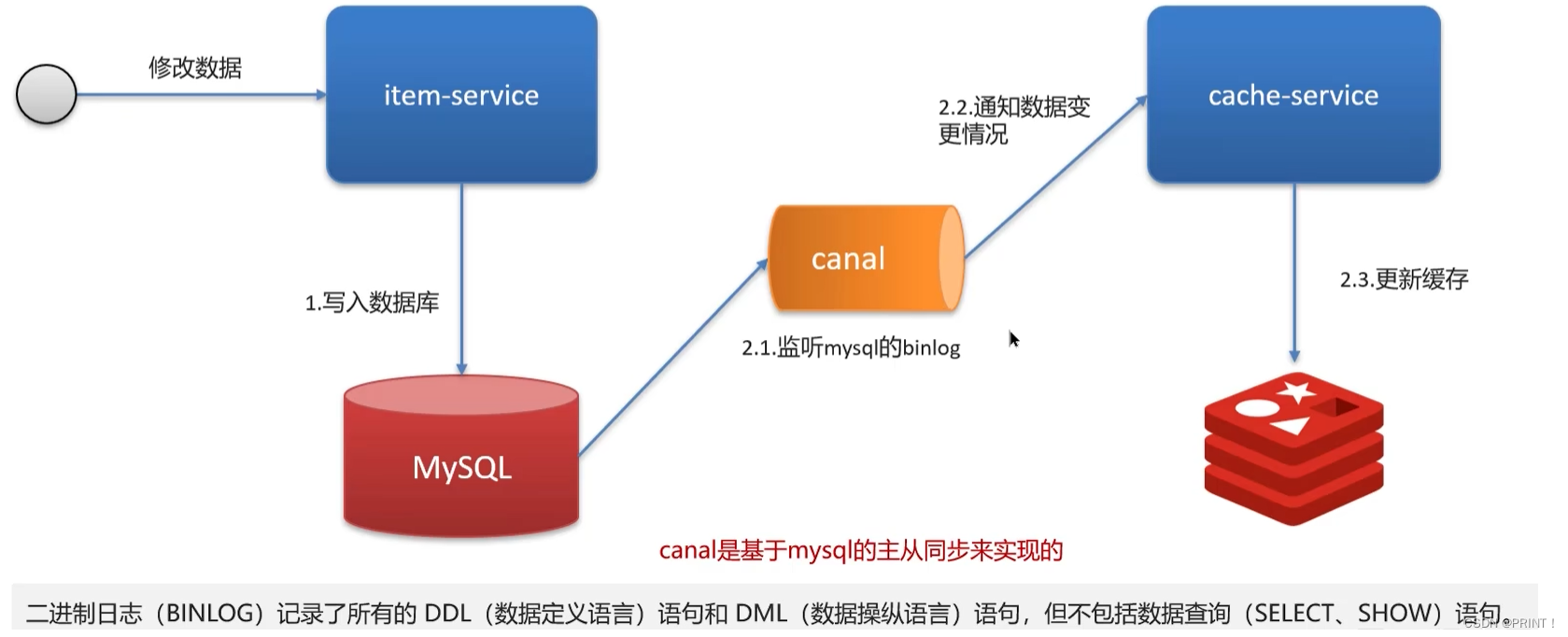
④ 实战面试
分为两种情况进行回答,主要是业务需要是属于一致性要求高、延迟一致性

情况一:强一致性

情况二:延迟一致

6. 缓存-持久化
① 问题引入

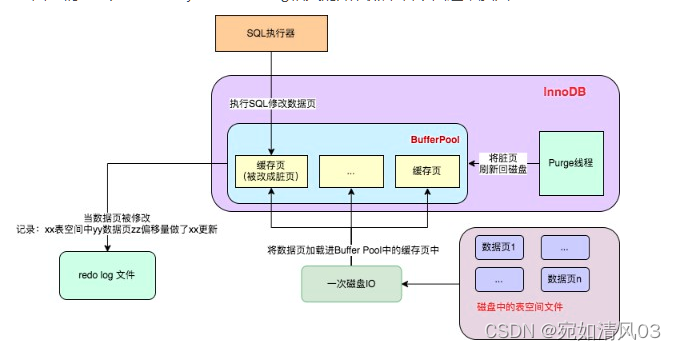
在Redis中提供了两种数据持久化的方式:1、RDB 2、AOF
② Redis持久化-RDB(数据备份文件)
RDB全称Redis Database Backup file (Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。
主动备份 (进入redis客户端)

自动备份(触发条件)
Redis内部有触发RDB的机制,可以在redis.conf文件中找到,格式如下:

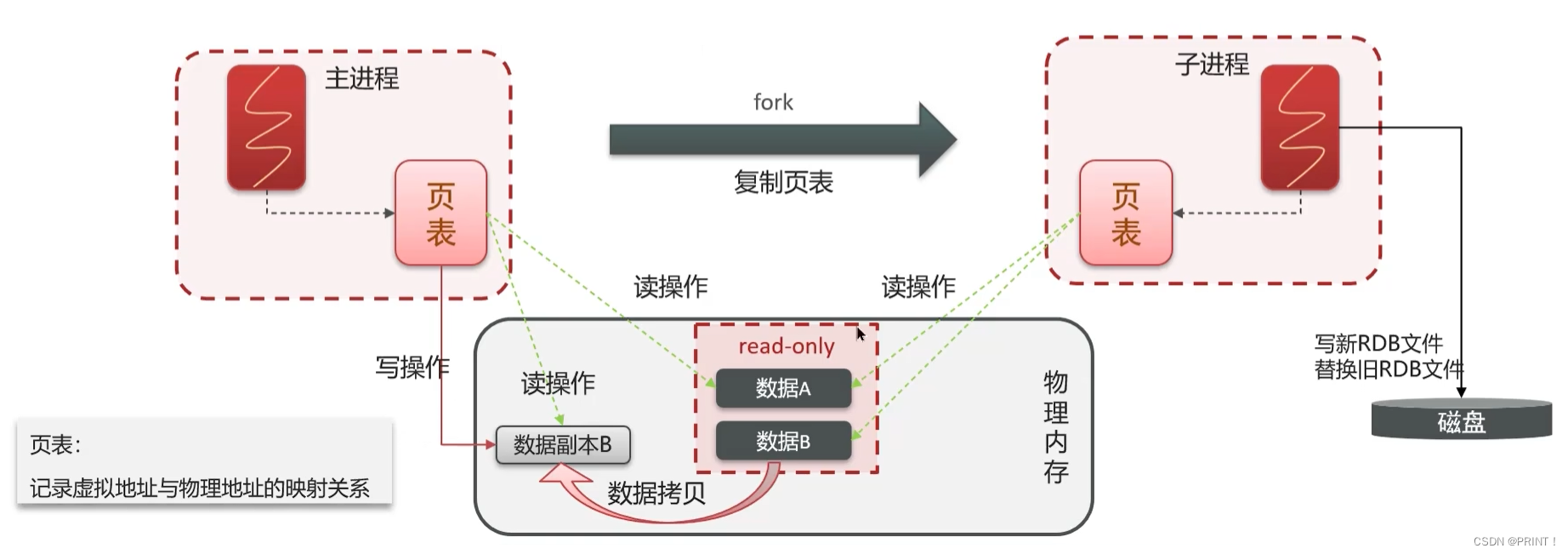
RDB的执行原理: bgsave开始时会fork主进程得到子进程,子进程共享主进程的内存数据。完成fork后读取内存数据并写入RDB 文件。
fork采用的是copy-on-write技术:
· 当主进程执行读操作时,访问共享内存;
· 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
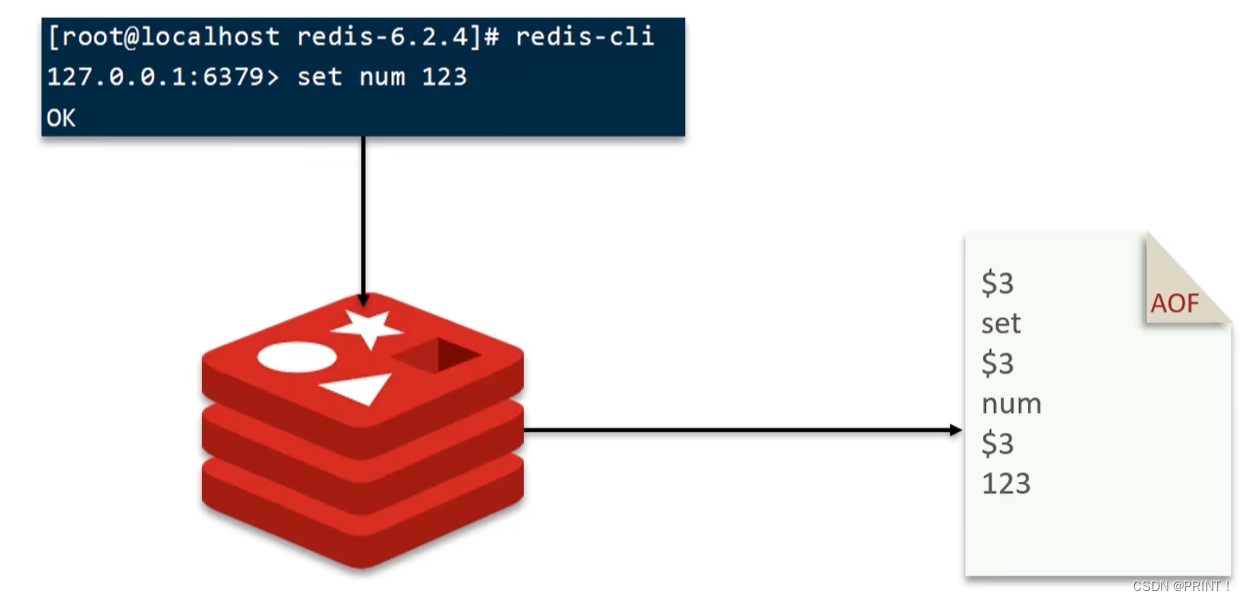
③ Redis持久化-AOF(追加文件)
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件。
AOF默认是关闭的,需要修改redis.conf配置文件来开启AOF,格式如下:
 AOF的命令记录的频率也可以通过redis.conf文件来配:
AOF的命令记录的频率也可以通过redis.conf文件来配:
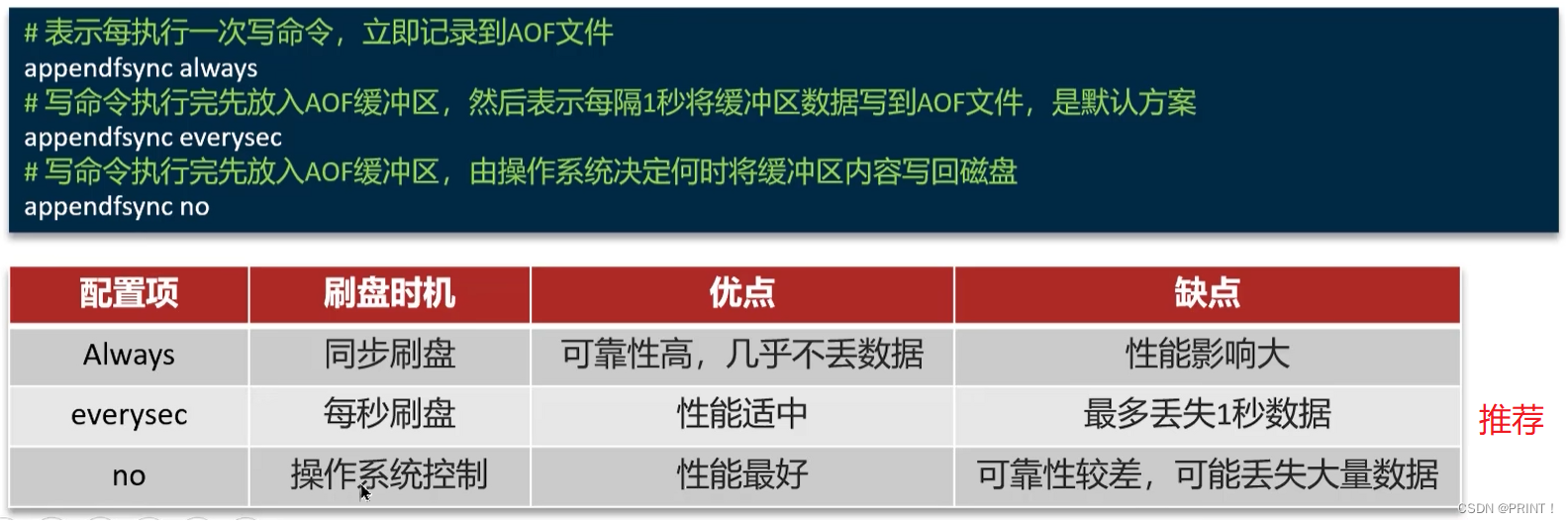
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次与操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。
例如:同时对num进行两次操作,重写文件

自动触发重写:Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:

④ RDB与AOF对比
RDB和AOF各有自己的优缺点,如果对数据安全性要求较高,在实际开发中往往会结合两者来使用。

⑤ 实战面试

7. 缓存-数据过期策略
① 问题引入

Redis对数据设置数据的有效时间,数据过期以后,就需要将数据从内存中删除掉。可以按照不同的规则进行删除,这种删除规则就被称之为数据的删除策略(数据过期策略)。
有两种删除方式:惰性删除、定期删除
Redis的过期删除策略:惰性删除+定期删除两种策略进行配合使用
② Redis数据删除策略-惰性删除
惰性删除:设置该key过期时间后,我们不去管它,当需要该key时, 我们在检查其是否过期,如果过期,我们就删掉它,反之返回该key
优点:对CPU友好,只会在使用该key时才会进行过期检查,对于很多用不到的key不用浪费时间进行过期检查
缺点:对内存不友好,如果一个key已经过期, 但是一直没有使用, 那么该key就会一直存在内存中, 内存永远不会释放

③ Redis数据删除策略-定期删除
定期删除:每隔一段时间,,我们就对一些key进行检查 ,删除里面过期的key(从一定数量的数据库中取出一定数量的随机key进行检查,并删除其中的过期key)。
定期清理有两种模式:
● SLOW模式是定时任务,执行频率默认为10hz,每次不超过25ms,以通过修改配置文件redis.conf的hz选项来调
整这个次数
● FAST模式执行频率不固定,但两次间隔不低于2ms,每次耗时不超过1ms
优点:可以通过限制删除操作执行的时长和频率来减少删除操作对CPU的影响。另外定期删除,也能有效释放过期键占用的内存。
缺点:难以确定删除操作执行的时长和频率。
④ Redis的数据过期策略总结
惰性删除:访问key的时候判断是否过期,如果过期,则删除
定期删除:定期检查一定量的key是否过期( SLOW模式+ FAST模式)
Redis的过期删除策略:惰性删除+定期删除两种策略进行配合使用
⑤ 实战面试

8. 缓存-数据淘汰策略
① 问题引入

这个问题主要是想知道redis的-数据淘汰策略
数据的淘汰策略:当Redis中的内存不够用时, 此时在向Redis中添加新的key,那么Redis就会按照某一种规则将内存中的数据删除掉,这种数据的删除规则被称之为内存的淘汰策略。
② 选择删除的Key-8种策略
- noeviction:不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl:对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰(TTL过期时间)
- allkeys-random:对全体key,随机进行淘汰。
- volatile-random:对设置了TTL的key,随机进行淘汰。
- alkeys-lru:对全体key,基于LRU算法进行淘汰
- volatile-Iru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu:对全体key,基于LFU算法进行淘汰
- volatile-lfu:对设置了TTL的key,基于LFU算法进行淘汰
补充LRU和LFU:
LRU (Least Recently Used)最近最少使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。(例如:key1是在3s之前访问的, key2是在9s之前访问的,删除的就是key2)
LFU (Least Frequently Used))最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。(例如:key1最近5s访问了4次, key2最近5s访问了9次,删除的就是key1)
推荐使用:
1 . 优先使用 allkeys-lru策略。充分利用LRU算法的优势,把最近最常访问的数据留在缓存中。如果业务有明显的冷热数据区分,建议使用。
2.如果业务中数据访问频率差别不大,没有明显冷热数据区分,建议使用allkeys-random,随机选择淘汰。
3.如果业务中有置顶的需求,可以使用volatile-lru 策略,同时置顶数据不设置过期时间,这些数据就一直不被删除,会淘汰其他设置过期时间的数据。
4.如果业务中有短时高频访问的数据,可以使用allkeys-lfu或volatile-lfu策略。
③ 其他面试问题
1.数据库有1000万数据,Redis只能缓存20万数据,如何保证Redis中的数据都是热点数据?
回答:使用allkeys-Iru(挑选最近最少使用的数据淘汰)淘汰策略,留下来的都是经常访问的热点数据
2 . Redis的内存用完了会发生什么?
提示:主要看数据淘汰策略是什么?如果是默认的配置( noeviction ),会直接报错
④ 数据淘汰策略总结
- Redis提供了8种不同的数据淘汰策略,默认是noeviction不删除任何数据,内存不足直接报错
- LRU:最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰
优先级越高。 - LFU:最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高
注意:平时开发过程中用的比较多的就是allkeys-Iru(结合自己的业务场景)
⑤ 实战面试

二、Redis分布式锁
1. 使用场景
① 问题引入

分布式锁使用的场景:集群情况下的定时任务、抢单、幂等性场景(需要结合项目中的业务进行回答)
② 举例说明-抢卷场景
系统获取优惠劵数量,然后判断是否还有优惠劵,还有剩余就自减,没有就返回异常。

两个线程同时去查询并且剩余优惠卷只有1张就会出现问题,如:线程1和线程2查询到的剩余量都是剩余1张优惠劵,然后线程1先进行自减,此时优惠劵的剩余量是0张,但是线程2是在这之前就查询到的剩余1张的信息,线程2就会继续执行自减,此时就会出现异常。
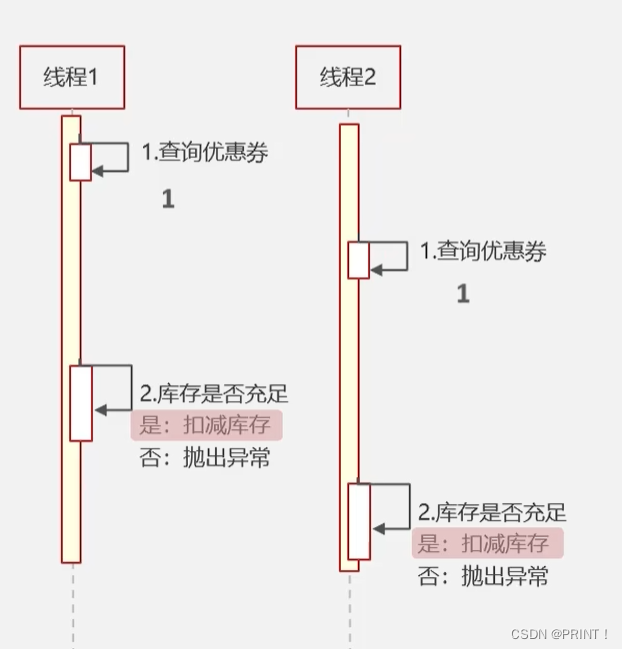
解决方法一:加互斥锁(单台服务器)
这种方式虽然可以解决上面这个问题,但是没办法支撑更多的并发请求,只适用于单台服务器。

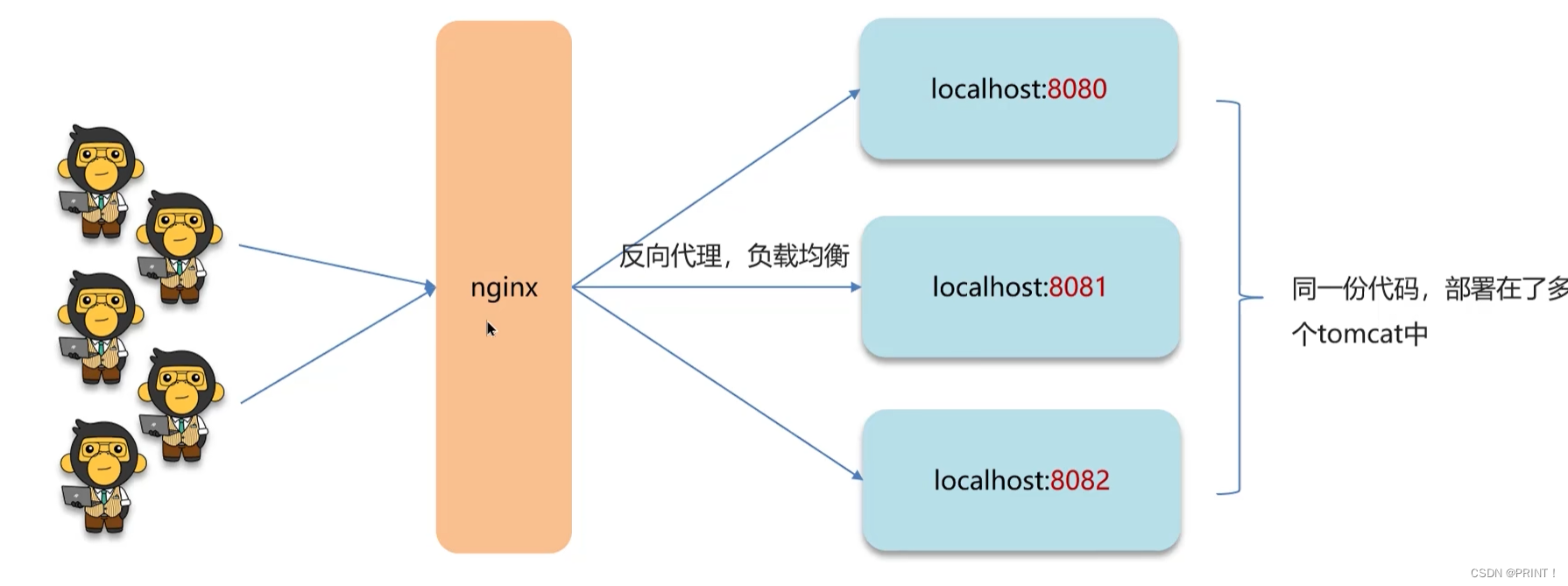
解决方法二:分布式锁(集群)
服务集群部署:
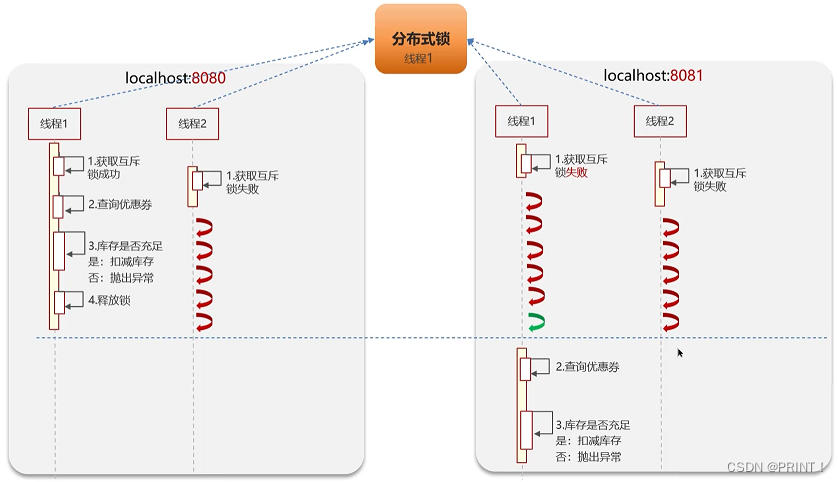
在线程1有锁的情况下,所有的线程都需要等待,如下图所示:
2. 实现原理(setnx、redisson)
① setnx实现分布式锁
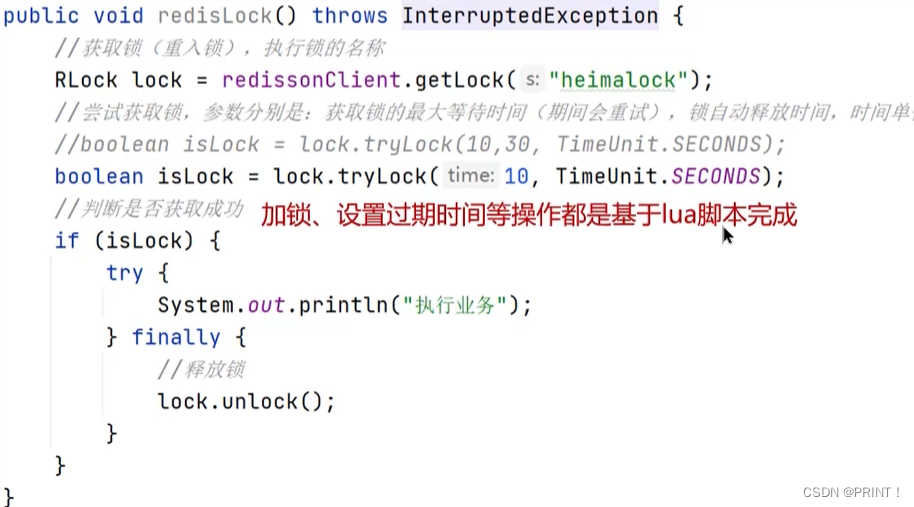
Redis实现分布式锁主要利用Redis的setnx命令。setnx是SET if not exists(如果不存在,则SET)的简写。

补充:如果不设置过期时间可能会导致死锁问题(服务器宕机无法正常释放锁,那么设置过期时间可以解决这个问题)

有两种方案:根据业务执行时间预估、给锁续期
② redisson实现分布式锁
线程1持有锁,线程2不断循环尝试加锁,如果线程1一直没有释放锁,线程2循环到一定的次数就会直接结束,线程2获取锁失败。
等待机制在高并发的情况下可以增加分布式锁的使用性能。
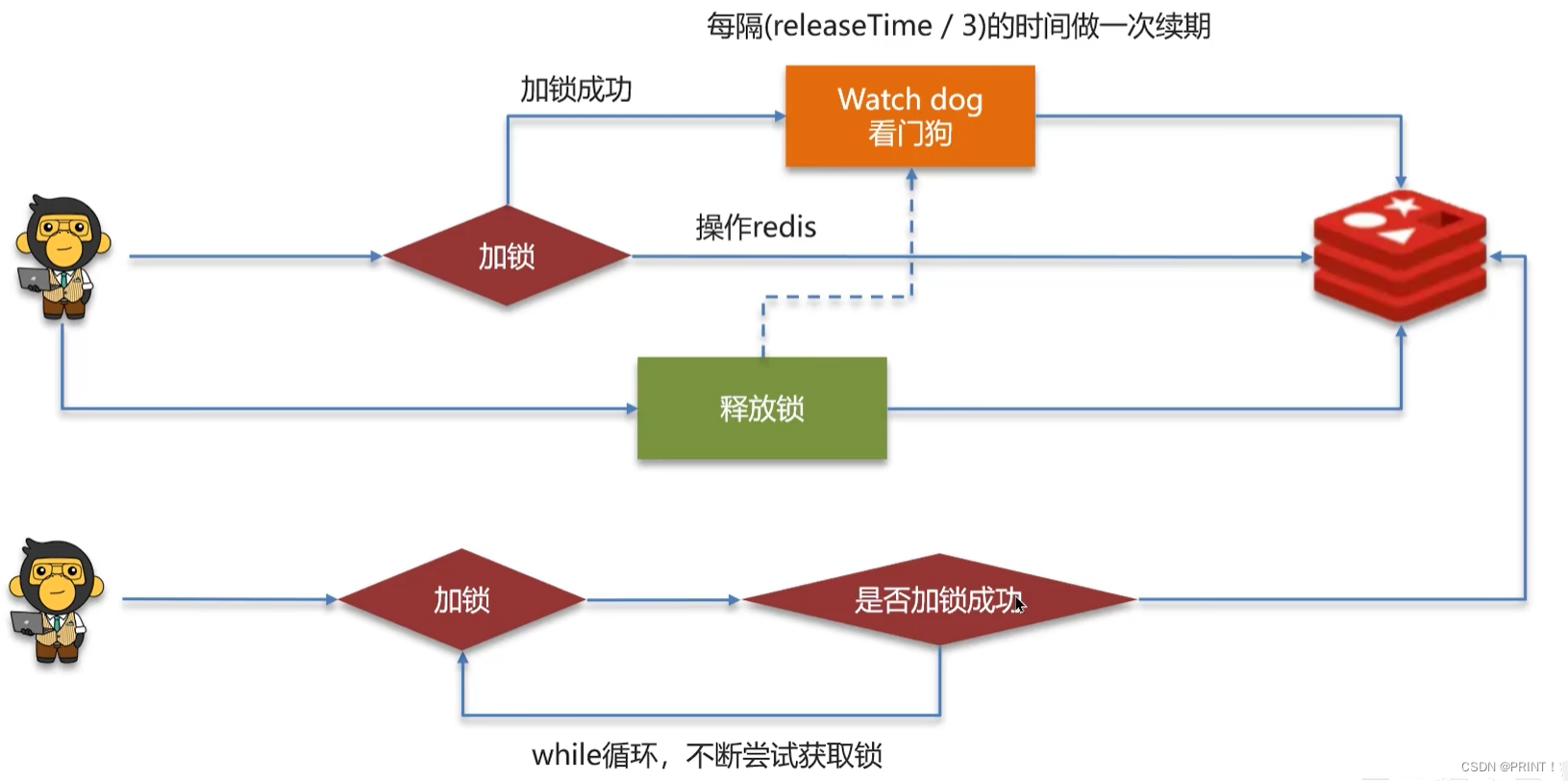
lua保证命令执行的原子性:可以调用redis命令,保证多条命令执行的原子性。
三个重点:
- watch dog可以给锁续期
- 抢不到锁的线程会进行尝试等待
- 所有的redis命令是基于lua脚本完成的,保证执行的原子性
redisson实现的分布式锁-可重入:
同一个线程可以重入,比如在add1方法中调用了add2方法

redisson实现的分布式锁-主从一致性:
主节点:负责写入数据(增删改)
从节点:负责读取数据(查)
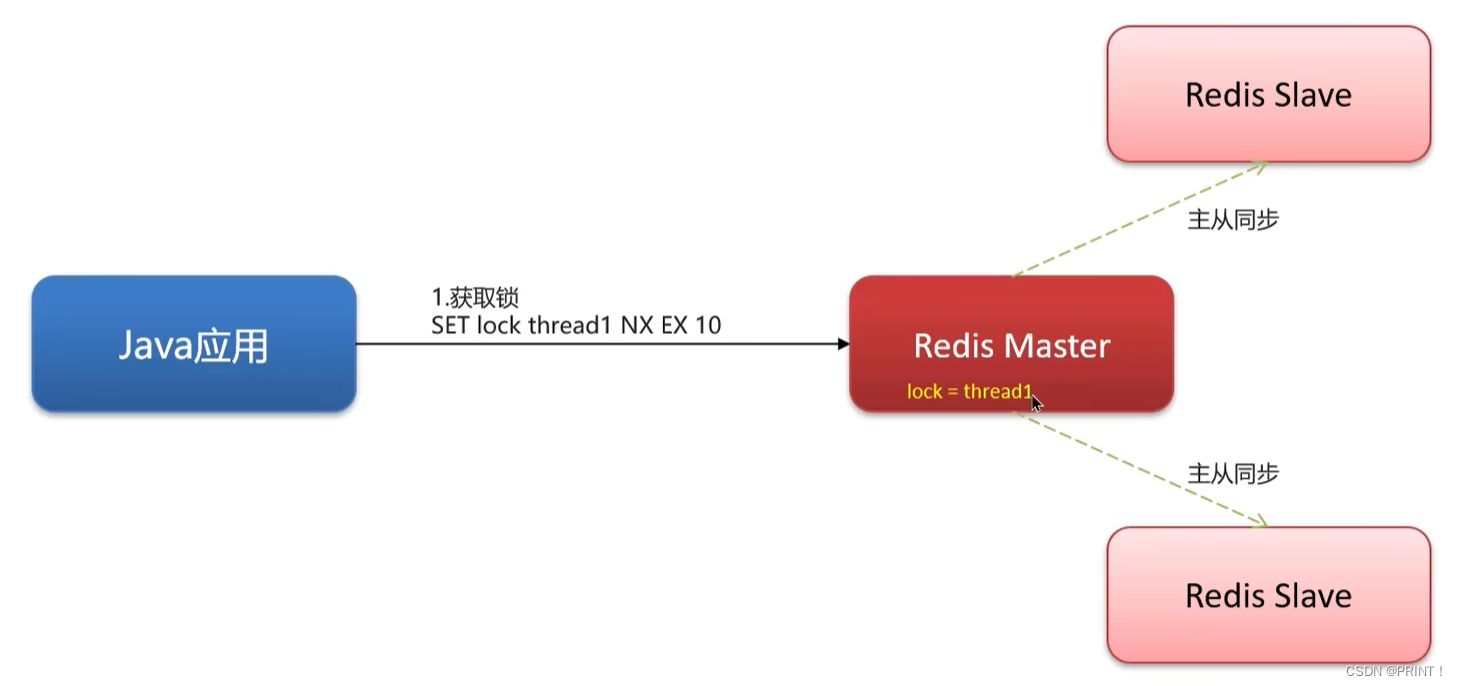
如果主节点宕机,通过redis的哨兵模式在剩下的子节点中选出主节点,但这样也出现了新的问题,两个线程同时持有一把锁。用红锁可以解决。

RedLock(红锁):不能只在一个redis实例上创建锁,应该是在多个redis实例上创建锁(n/ 2+1),避免在一个redis实例上加锁。
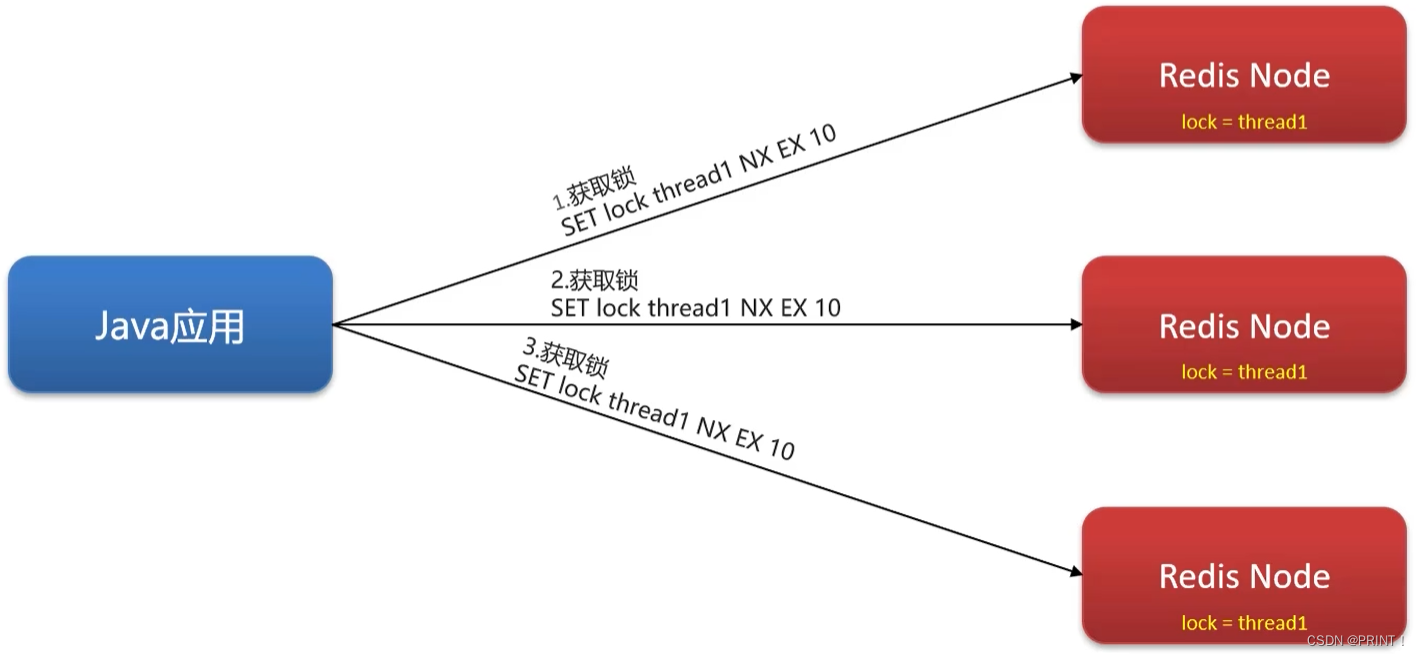
补充:在项目中不推荐采用红锁,因为实现复杂、性能差、运维繁琐,需要提供多个独立的redis节点。
解决主从可以使用zookeeper
3. 分布式锁总结
① 问题总结

回答:
先按照自己简历上的业务进行描述分布式锁使用的场景(比如抢劵系统)
我们当使用的redisson实现的分布式锁,底层是setnx和lua脚本(保证原子性)

回答:在redisson的分布式锁中,提供了一个WatchDog(看门狗),一个线程获取锁成功以后,WatchDog会给持有锁的线程续期(默认是每隔10秒续期一次)

回答:可以重入,多个锁重入需要判断是否是当前线程,在redis中进行存储的时候使用的hash结构,来存储线程信息和重入的次数。

回答:不能解决,但是可以使用redisson提供的红锁来解决,但是这样的话,性能就大低了,如果业务中非要保证数据的强一致性,建议采用zookeeper实现的分布式锁。
② 实战面试

三、Redis的其他面试问题

在Redis中提供的集群方案总共有三种:
1.主从复制
2.哨兵模式
3.分片集群
1.redis主从数据同步的流程是什么?
2.怎么保证redis的高并发高可用?
3.你们使用redis是单点还是集群,哪种集群?
4.Redis分片集群中数据是怎么存储和读取的?
5.Redis集群脑裂,该怎么解决呢?
1. 主从复制(高并发)
① 问题引入
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读写分离,增强并发能力。
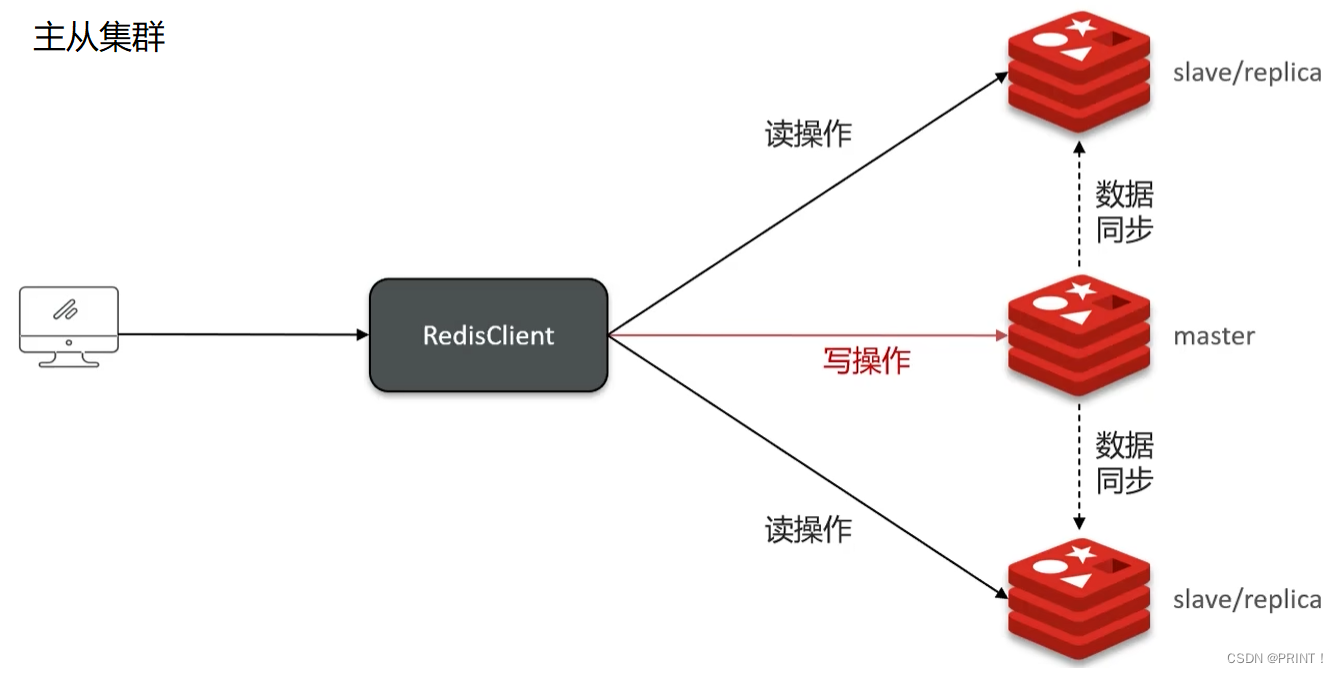
② 主从数据同步原理
主从全量同步:
Replication ld:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid;
offset:偏移量,随着记录在repl baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset,如果slave的offset小于master的offset,说明slave数据落后于master,需要更新。

思考问题:
- 主节点master如何判断从节点slave是第一次同步?
回答:主节点与拿取从节点的replid,对比是否一致,不一致则是第一次同步; - 主节点与从节点同步数据时,如何做到不多不少正好是从节点需要的那部分数据呢?
第一次同步数据则会生成RDB文件,不是第一次同步数据就会根据偏移量来获取缺少的部分
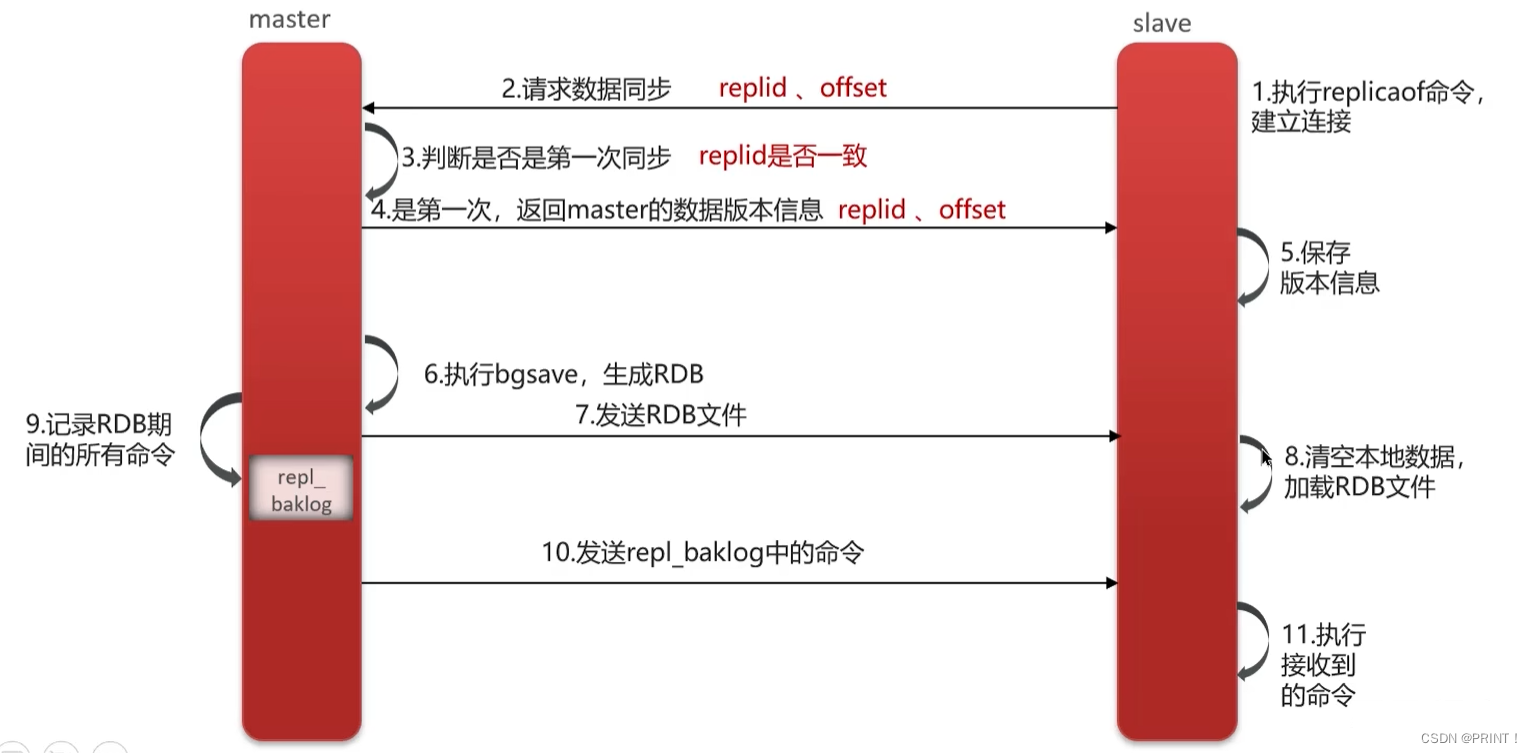
主从增量同步:slave重启或后期数据变化
从节点发送replid和offset给主节点

③ 问题总结

回答:单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,就需要搭建主从集群,实现读与分离。一般都是一主多从,主节点负责写数据,从节点负责读数据

回答:
全量同步:
1.从节点请求主节点同步数据(replication id、 offset )
2.主节点判断是否是第一次请求,是第一次就与从节点同步版本信息(replication id和offset)
3.主节点执行bgsave,生成rdb文件后,发送给从节点去执行
4.在rdb生成执行期间,主节点会以命令的方式记录到缓冲区(一个日志文件)
5.把生成之后的命令日志文件发送给从节点进行同步
增量同步:
1.从节点请求主节点同步数据,主节点判断不是第一次请求,不是第一次就获取从节点的offset值
2.主节点从命令日志中获取offset值之后的数据,发送给从节点进行数据同步
④ 实战面试

2. 哨兵模式(髙可用)
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复(保证redis主从的高可用)。
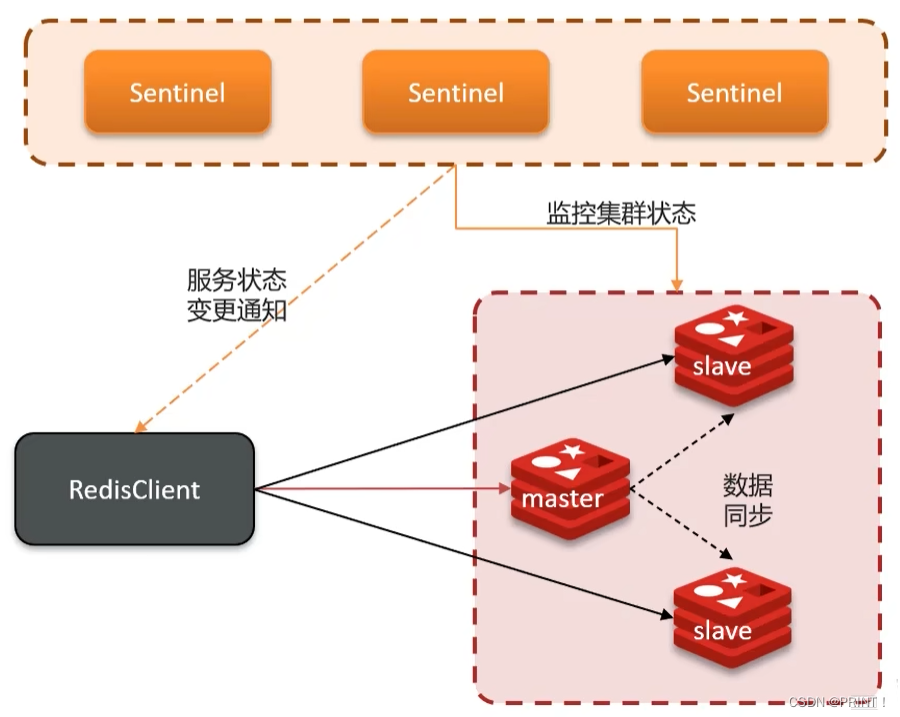
① 哨兵的作用
哨兵的结构和作用如下:
监控:Sentinel会不断检查您的master和slave
是否按预期工作
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
通知: Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
② 服务状态监控
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线。
客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半。
哨兵选主规则
● 首先判断主与从节点断开时间长短,如超过指定值就排该从节点
● 然后判断从节点的slave-priority值,越小优先级越高
● 如果slave-prority-样,则判断slave节点的offset值,越大优先级越高
● 最后是判断slave节点的运行id大小,越小优先级越高。
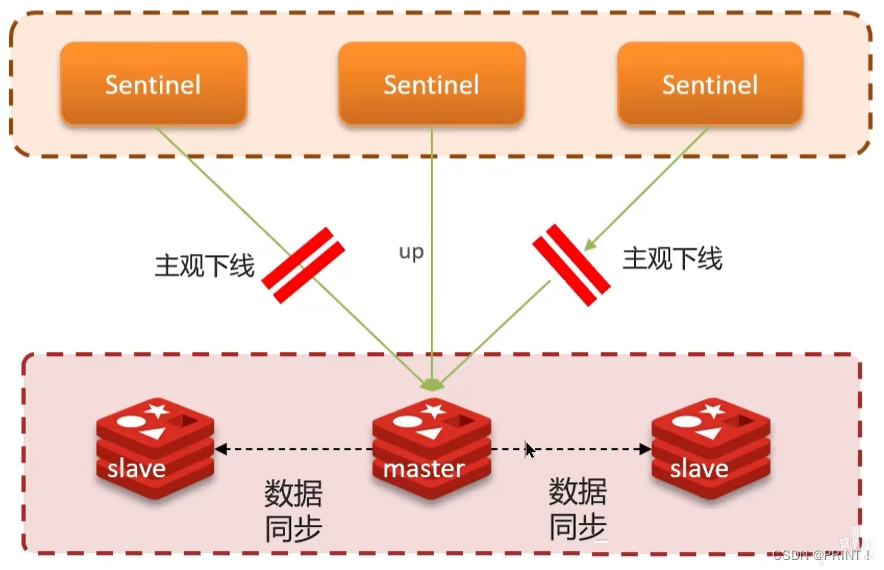
③ Redis集群(哨兵模式)脑裂
脑裂:主节点和从节点处于不同的网络分区,就会出现两个master

此时客户端是连接的之前的主节点,当网络恢复了就会把之前的主节点降级为子节点,那么后面新增加的数据就会被清空掉。
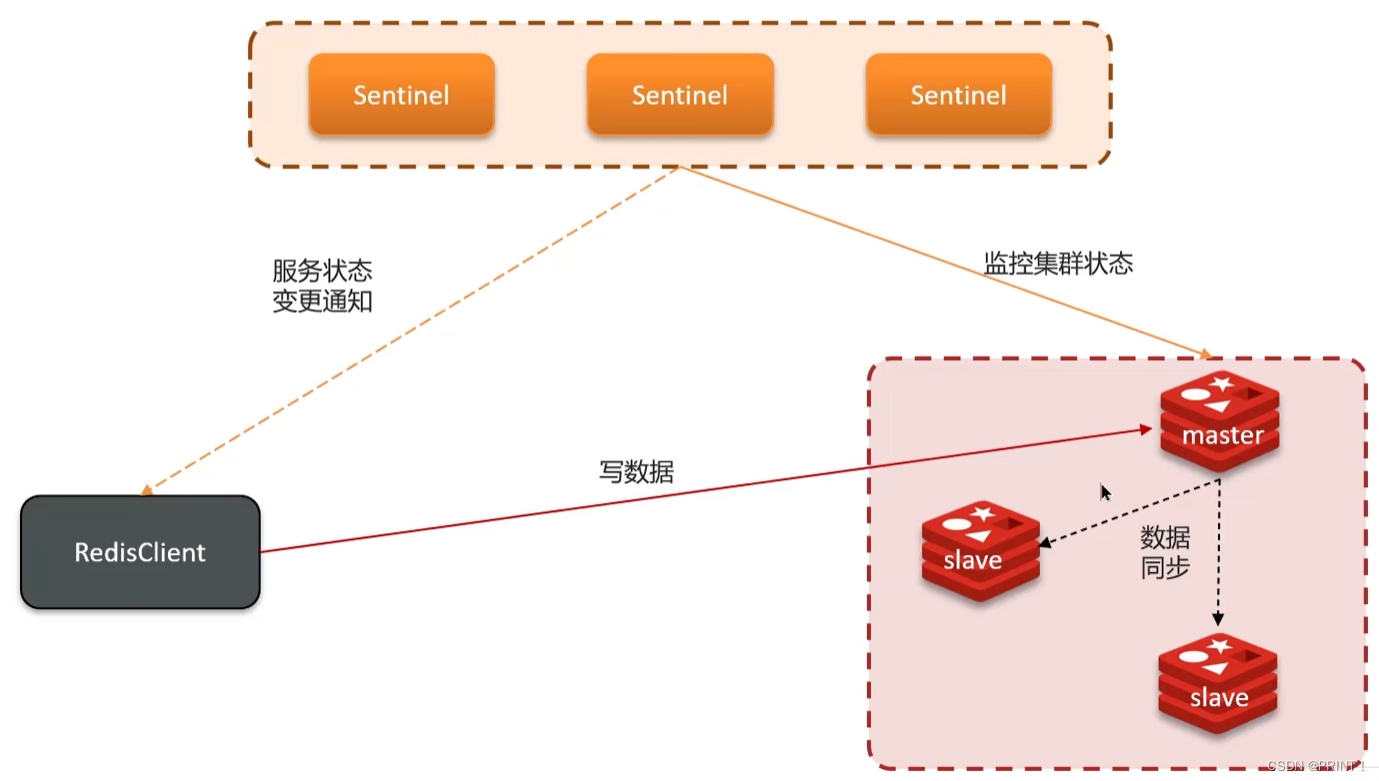
解决脑裂问题,通过redis中有两个配置参数:
1.min-replicas-to-write 1表示最少的salve节点为1个
2.min-replicas-max-lag 5表示数据复制和同步的延迟不能超过5秒
④ 问题总结
redis是作为缓存使用的,不适用存储海量数据,适合存储热点数据,redis单节点的写操作并发8万,读操作并发10万。

解决:我们可以修改redis的配置,可以设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求就可以避免大量的数据丢失。
⑤ 实战面试

3. 分片集群(海量数据存储)
① 问题引入
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
● 海量数据存储问题
● 高并发写的问题
② 分片集群结构
使用分片集群可以解决上述问题,分片集群特征:
● 集群中有多个master,每个master保存不同数据
● 每个master都可以有多个slave节点
● master之间通过ping监测彼此健康状态
● 客户端请求可以访问集群任意节点,最终都会被转发到正确节点

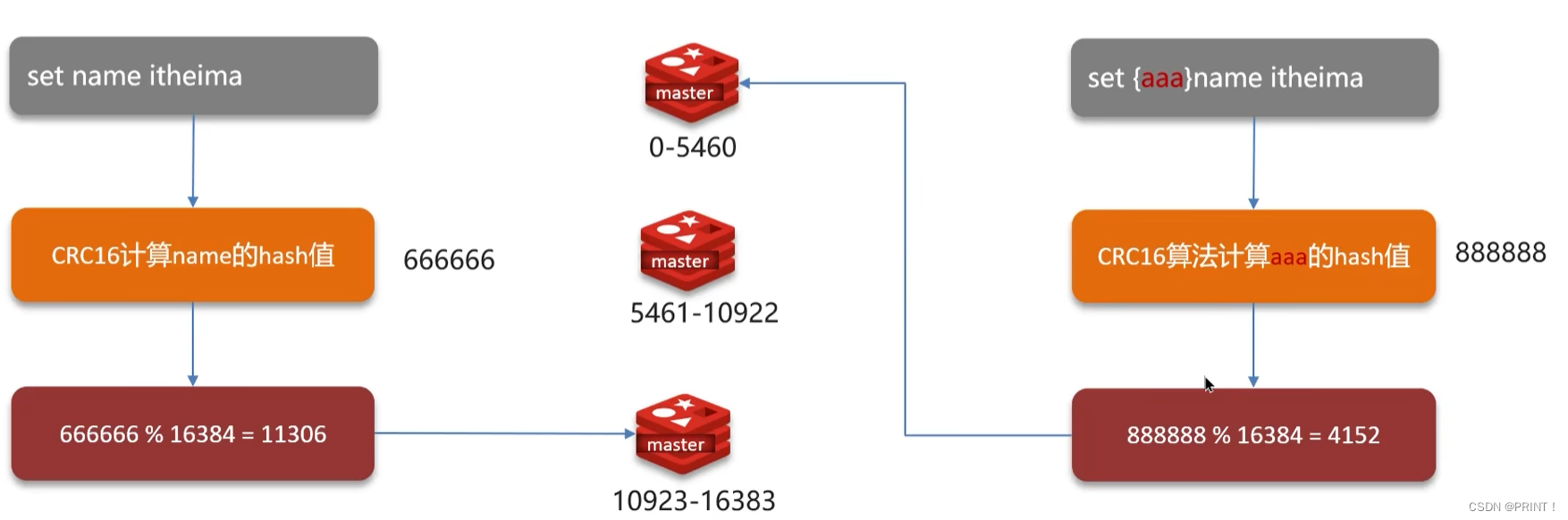
③ 分片集群的数据读写
Redis分片集群引入了哈希槽的概念,Redis 集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来
决定放置哪个槽,集群的每个节点负责一部分hash槽。
④ 问题总结

⑤ 实战面试

4. Redis单线程
① 问题引入

● Redis是纯内存操作, 执行速度非常快
● 采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题
● 使用I/O多路复用模型, 非阻塞IO

Redis是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟而不是执行速度,I/O多路复 用模型主要就是实现了高效的网络请求
● 用户空间和内核空间
● 常见的IO模型
➢ 阻塞IO (Blocking I0)
➢ 非阻塞IO (Nonblocking I0)
➢ I0多路复用(IO Multiplexing)
●Redis网络模型
② 用户空间与内核空间
● Linux系统中一 -个进程使用的内存情况划分两部分:内核空间、用户空间
● 用户空间只能执行受限的命令(Ring3) ,而且不能直接调用系统资源
必须通过内核提供的接口来访问
● 内核空间可以执行特权命令(Ring0) ,调用一-切系统资源
Linux系统为了提高IO效率,会在用户空间和内核空间都加入缓冲区:
● 写数据时,要把用户缓冲数据拷贝到内核缓冲区,然后写入设备
● 读数据时, 要从设备读取数据到内核缓冲区,然后拷贝到用户缓冲区
③ 阻塞IO与非阻塞IO
阻塞IO就是两个阶段都必须阻塞等待:
阶段一:
1.用户进程尝试读取数据 (比如网卡数据)
2.此时数据尚未到达,内核需要等待数据
3.此时用户进程也处于阻塞状态
阶段二:
1.数据到达并拷贝到内核缓冲区,代表已就绪
2.将内核数据拷贝到用户缓冲区
3.拷贝过程中,用户进程依然阻塞等待
4.拷贝完成,用户进程解除阻塞,处理数据
阻塞IO模型中,用户进程在两个阶段都是阻塞状态。

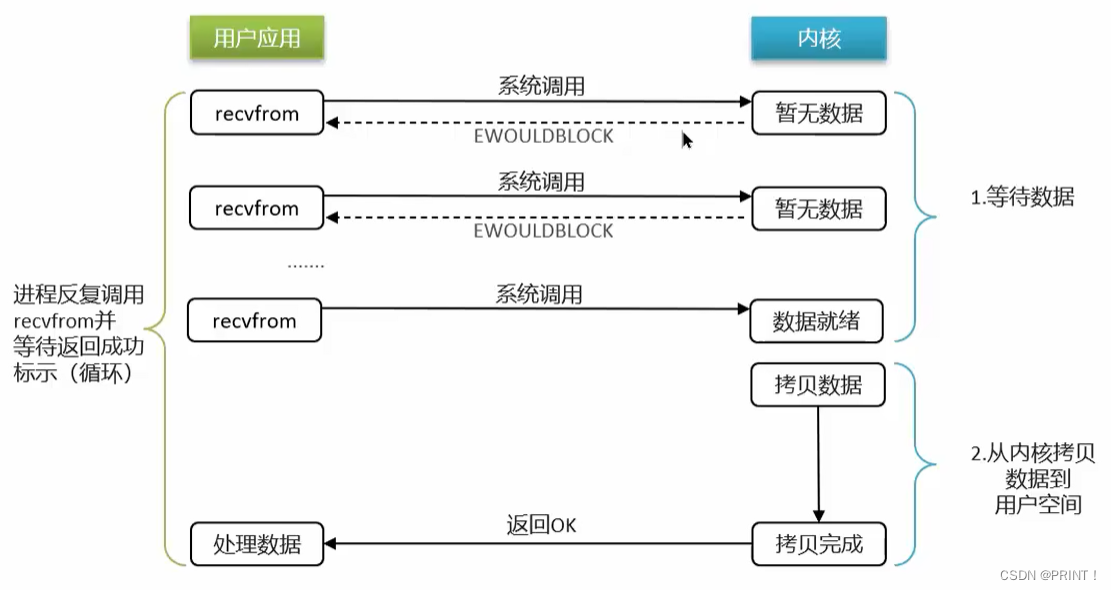
非阻塞IO的recvfrom操作会立即返回结果而不是阻塞用户进程。
阶段一:
1.用户进程尝试读取数据(比如网卡数据)
2.此时数据尚未到达,内核需要等待数据
3.返回异常给用户进程
4.用户进程拿到error后,再次尝试读取
5.循环往复,直到数据就绪
阶段二:
将内核数据拷贝到用户缓冲区
拷贝过程中,用户进程依然阻塞等待
拷贝完成,用户进程解除阻塞,处理数据
可以看到,非阻塞IO模型中,用户进程在第一个阶段是非阻塞,第二个阶段是阻塞状态。虽然是非阻塞,但性能并没有得到提高。而且忙等机制会导致CPU空转,CPU使用率暴增。
④ IO多路复用
IO多路复用:是利用单个线程来同时监听多个Socket(客户端的连接),并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
阶段一:
1.用户进程调用select,指定要监听的Socket集合
2.内核监听对应的多个socket
3.任意一个或多个socket数据就绪则返回readable
4.此过程中用户进程阻塞
阶段二:
1.用户进程找到就绪的socket
2.依次调用recvfrom读取数据
3.内核将数据拷贝到用户空间
4.用户进程处理数据
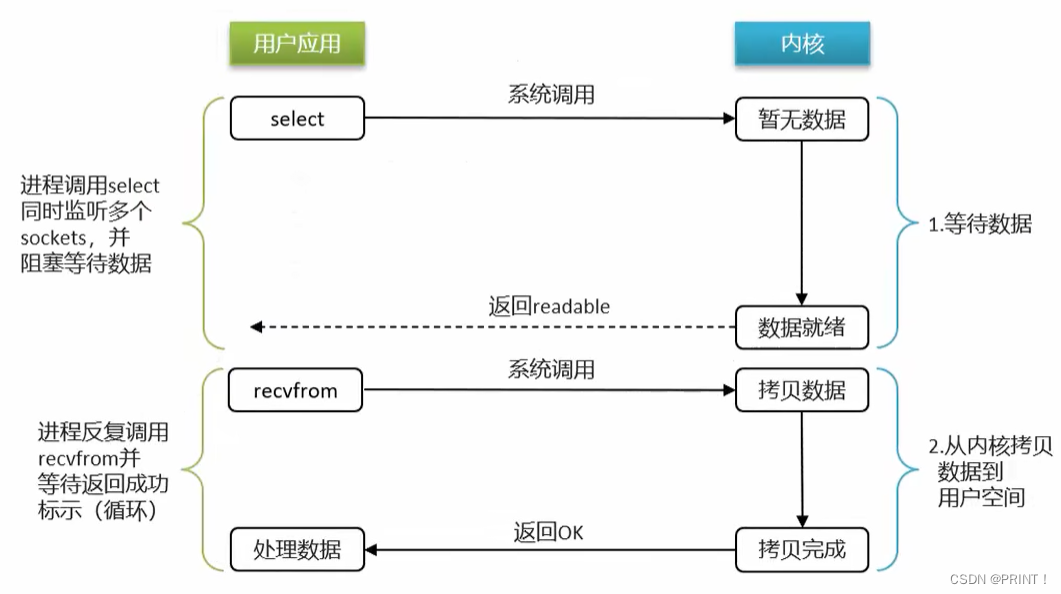
IO多路复用(Linux系统)是利用单个线程来同时监听多个Socket,并在某个Socket可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。不过监听Socket的方式、通知的方式又有多种实现,常见的有:
select、poll、epoll
差异:
1.select和poll只会通知用户进程有Socket就绪,但不确定具体是哪个Socket,需要用户进程逐个遍历Socket来确认
2.epoll则会在通知用户进程Socket就绪的同时,把已就绪的Socket写入用户空间
点餐案例(select、poll ):每个顾客可以通过自己的开关进行点灯,灯亮的时候服务员就去一个一个去询问,确定是谁点灯
点餐案例(epoll ):每个顾客可以控制服务员的计算机,客户按下按钮,计算器中显示几号桌就绪

⑤ Redis网络模型
Redis通过IO多路复用来提高网络性能,并且支持各种不同的多路复用实现,并且将这些实现进行封装,提供了统一的高性能事件库
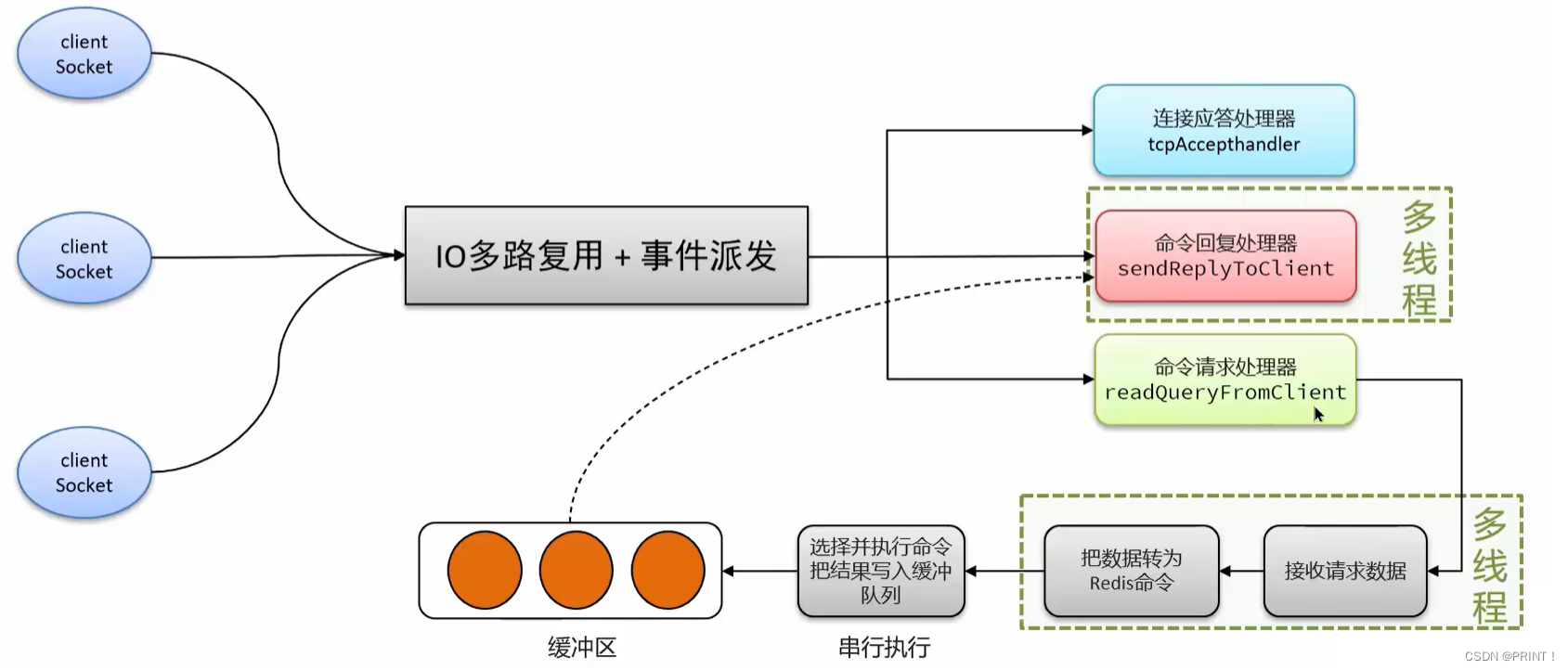
redis的网络模型=IO多路复用+事件派发,对应不同的事件给不同的处理器。
⑥ 问题总结

⑦ 实战面试

引用声明
文章内容来源:https://www.bilibili.com/video/BV1yT411H7YK?p=7&spm_id_from=pageDriver&vd_source=98092b0aee05ae7c890b09fe07f13df4
https://www.bilibili.com/video/BV1cr4y1671t/?spm_id_from=333.337.search-card.all.click