将机器模型部署到生产环境的方法有很多。 常见的方法之一是将其实现为 Web 服务。 最流行的类型是 REST API。 它的作用是全天候(24/7)部署和运行,等待接收来自客户端的 JSON 请求,提取输入,并将其发送到 ML 模型以预测结果。 然后将结果包装到响应中并返回给用户

推荐:用 NSDT编辑器 快速搭建可编程3D场景
1、朴素的实现模式
你开始在 Google 上使用“将机器学习部署为 REST API”来搜索此问题。 你将收到一百万个结果。 如果你付出努力并阅读此内容。 在许多排在前面的结果中,你将看到解决此问题的常见模式,如下图所示。
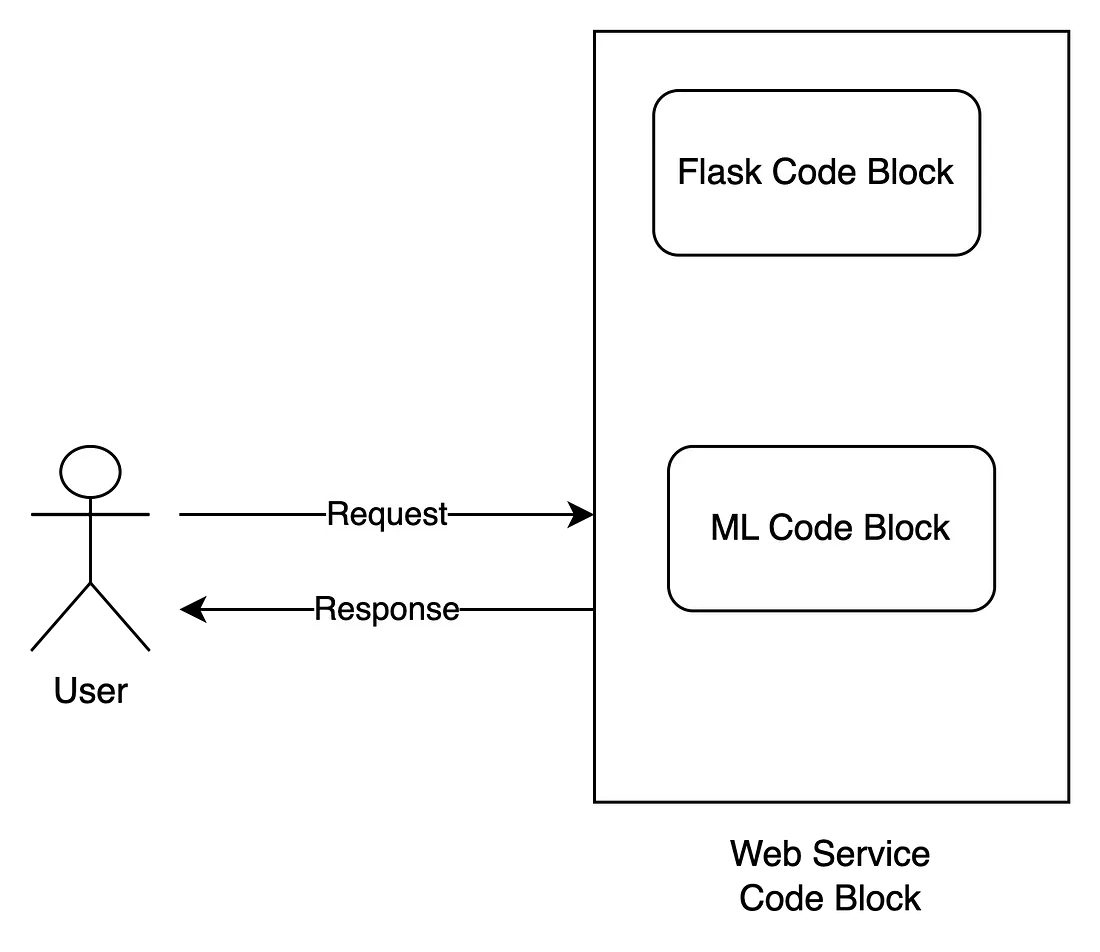
流行的方式是我们需要一个用于构建 API 的 Web 框架(Flask、Diango 或 FastAPI)。 接下来,我们将需要机器学习来获取输入并返回预测。 为了帮助系统在生产环境中运行,我们需要将额外的 WSGI(如果我们使用 Flask)或 ASGI(如果我们使用 FastAPI)封装在 Web 模块之外。
这里值得注意的是,这种方法中的机器学习模型通常与 Web 框架(Flask / FastAPI / …)在同一代码块中实现。 这意味着机器学习模型与 Web 模块在同一进程中运行。 这会导致很多问题:
- 对于一个 Flask/FastAPI 进程,只能从一个 ML 模型进程开始。
- 在一个运行时间点,ML模型只能处理一个请求
- 如果我们想要扩展应用程序,我们可以使用 WSGI(例如 guvicorn)或 ASGI(例如 uvicorn)来创建许多子进程,这会增加 Web 模块和机器学习模型的数量,因为它们是在同一进程中实现的。
- 对于一些繁重的任务,ML 模型可能需要很长时间(甚至几秒钟)来运行推理。 因为它们是在 Web 模块的同一代码块中创建的,所以当我们需要等待所有任务完成才能处理下一个任务时,它会阻塞其他请求。
那么有没有更好的方法呢? 对于繁重且长时间运行的任务,有什么方法可以在不阻塞客户端请求的情况下处理它们? 今天,我将介绍一种可能并不新鲜但似乎尚未应用于将机器学习 ML 部署到生产环境的方法:使用任务队列分布式系统。
2、什么是任务队列?
任务队列用作跨线程或机器分配工作的机制。
任务队列的输入是一个工作单元,称为任务,专用工作进程然后不断监视队列以执行新工作。 – Celery Github
任务队列是一种工具,允许你在单独的机器/进程/线程中运行不同的软件程序。 在应用程序中,有一些部分(任务)经常运行很长时间或者我们不知道它们何时完成。 对于这些任务,最好将它们放在单独的进程或分布式机器中运行,当它们运行完成时,会通知我们检查结果。 这不会阻塞其他部分。 这适用于长时间运行的任务,例如发送电子邮件、抓取网页内容,或者在本例中运行 ML 模型。 让我们考虑下面的描述。
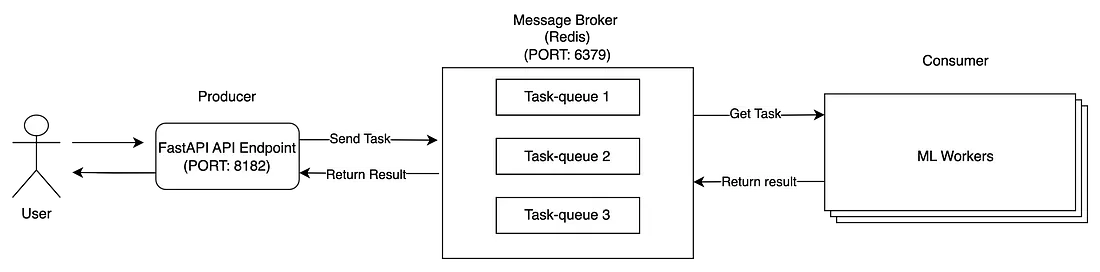
分布式任务队列的架构包含三个主要模块:生产者、消费者和消息代理。
- 客户端向我们的 Flask 应用程序(Producer)发送请求。
- 生产者将任务消息发送给 Message Broker。
- ML Workers(消费者)使用来自消息代理的消息。 任务完成后,将结果保存到 Message Broker 并更新任务状态。
- 将任务发送到消息代理后,FastAPI 应用程序还可以从消息代理监控任务的状态。 当状态完成时,它检索结果并将其返回给客户端
三个模块在不同的进程或分布式机器中启动,以便它们能够独立生存。 用于开发任务队列的工具有很多,分布在多种编程语言中,在本博客中,我将重点关注 Python 并使用 Celery,这是 Python 项目中最流行的任务队列工具。 要了解更多关于 Celery 和分布式任务队列系统的优点,可以查看精彩的解释。 现在,让我们跳到下面的问题。
3、行程时间预测模型
为了说明这一点,我将尝试构建一个简单的机器学习模型,该模型可以帮助预测给定上车地点、下车地点和行程长度的平均行程时间。 这将是一个回归模型。 请注意,我在本博客中并不专注于构建准确性模型,而只是利用它来设置 Web 服务 API。 模型权重以及我们如何构建模型可以在此链接中找到。
3.1 API 概述
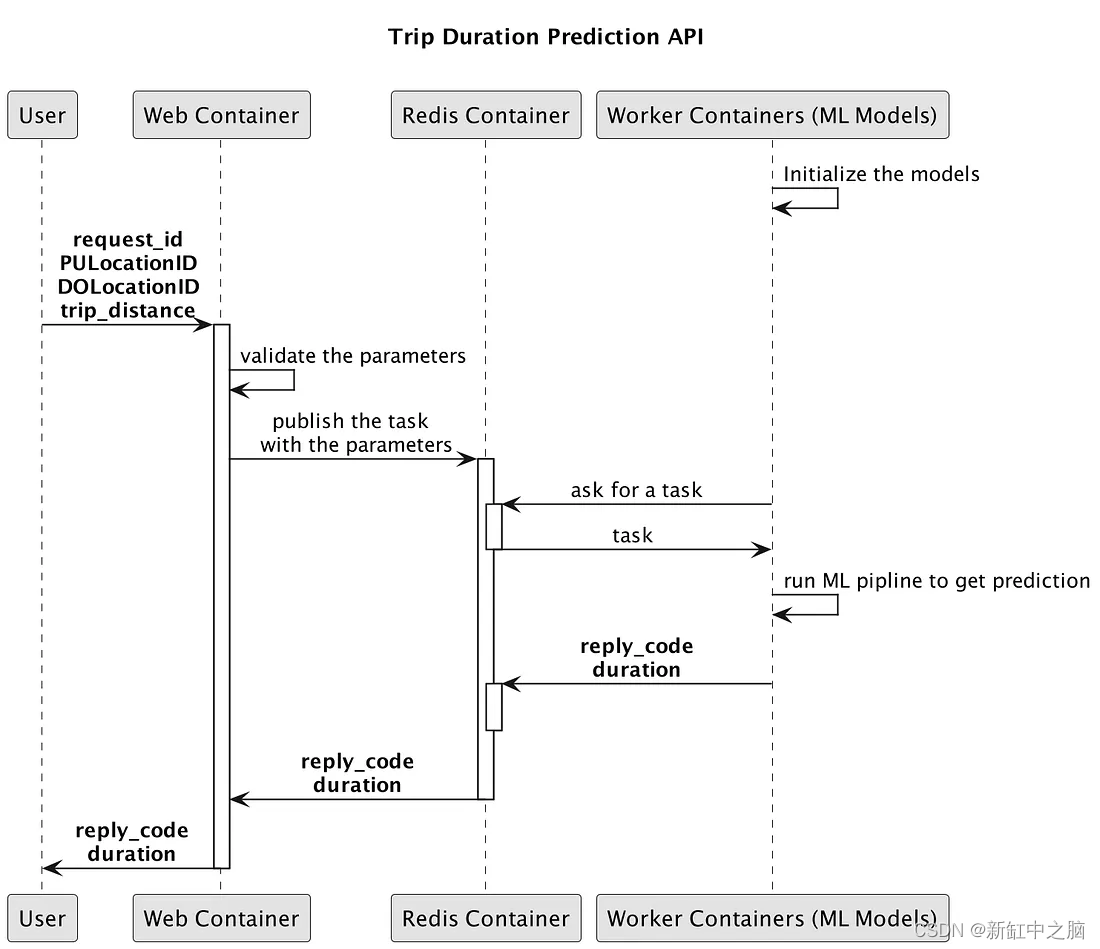
我们将开发一个用于服务机器学习模型的 Web API,其中包含 3 个模块:Web、Redis 和 ML 模型。 这些模块被 Docker 化并部署到容器中。
├── apps
│ └── api
│ ├── api_routers.py
│ └── main.py
├── boot
│ ├── docker
│ │ ├── celery
│ │ │ ├── cuda90.yml
│ │ │ └── trip
│ │ │ ├── Dockerfile
│ │ │ └── entrypoint.sh
│ │ ├── compose
│ │ │ └── trip_duration_prediction
│ │ │ ├── docker-compose.cpu.yml
│ │ │ ├── docker-compose.dev.yml
│ │ │ ├── docker-compose.yml
│ │ │ ├── docker-services.sh
│ │ │ ├── my_build.sh
│ │ └── uvicorn
│ │ ├── Dockerfile
│ │ ├── entrypoint.sh
│ │ └── requirements.txt
│ └── uvicorn
│ └── config.py
├── config.py
├── core
│ ├── managers
│ ├── schemas
│ │ ├── api_base.py
│ │ ├── health.py
│ │ └── trip.py
│ ├── services
│ │ ├── trip_duration_api.py
│ │ └── trip_duration_prediction_task.py
│ └── utilities
├── repo
│ ├── logs
│ └── models
│ └── lin_reg.bin
├── tasks
│ └── trip
│ └── tasks.py
└── tests├── http_test│ └── test_api.py└── model_test└── test_trip_prediction_task.py
以下是存储库文件夹结构的详细信息:
- apps:使用FastAPI定义Web模块的主应用程序和API路由器
- boot:为 Web 模块、ML 模块和 docker-compose 文件定义 Dockerfile 映像以链接 3 个模块。 它还包含每个 docker 映像的配置以及包库的相应 yml 文件。
- config.py:配置文件定义了有关 CELERY_BROKER_URL、CELERY_RESULT_BACKEND、TRIP_DURATION_MODEL、TRIP_DURATION_THRESHOLD 等的各种配置…
- core:定义Web、Redis、Worker模块中使用的所有实现脚本
- repo:API启动时存储应用程序和任务日志。 它还存储了模型权重
- tasks:定义 Celery 任务脚本
- tests:定义 API 的单元测试
3.2 Web模块
在Web模块中,我使用FastAPI作为Web框架。 FastAPI 提供了许多利基功能,例如:超快、与 Uvicorn 集成、使用 Pydantic 自动检查类型验证、自动文档生成等等……
让我们看看如何启动 FastAPI 应用程: boot/docker/uvicorn/entrypoint.sh,这是我启动 FastAPI 应用程序的地方
#!/usr/bin/env shUSERNAME="$(id -u -n)"
MODULE="apps.api"
SOCKET="0.0.0.0:8182"
MODULE_APP="${MODULE}.main:app"
CONFIG_PATH="boot/uvicorn/config.py"
REPO_ROOT="repo"
LOGS_ROOT="${REPO_ROOT}/logs/apps/api"
LOGS_PATH="${LOGS_ROOT}/daemon.log"sudo mkdir -p ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${REPO_ROOT} && \gunicorn \--name "${MODULE}" \--config "${CONFIG_PATH}" \--bind "${SOCKET}" \--log-file "${LOGS_PATH}" \"${MODULE_APP}"
然后,我定义 API 路由器和消息模式 - apps/api/api_routers.py:
import os
import json
from typing import Dictfrom loguru import logger
from fastapi import Request, APIRouterimport config
from core.schemas.trip import TripAPIRequestMessage, TripAPIResponseMessage
from core.schemas.health import Health
from core.services.trip_duration_api import TripDurationApiAPI_VERSION = config.API_VERSION
MODEL_VERSION = config.MODEL_VERSIONapi_router = APIRouter()@api_router.get("/health", response_model=Health, status_code=200)
def health() -> Dict:return Health(name=config.PROJECT_NAME, api_version=API_VERSION, model_version=MODEL_VERSION).dict()@api_router.post(f"/{config.API_VERSION}/trip/predict",tags=["Trips"],response_model=TripAPIResponseMessage,status_code=200,
)
def trip_predict(request: Request, trip_request: TripAPIRequestMessage):api_service = TripDurationApi()results = api_service.process_raw_request(request, trip_request)return results
core/schemas/trip.py:from core.schemas.api_base import APIRequestBase, APIResponseBaseclass TripAPIRequestMessage(APIRequestBase):PULocationID: intDOLocationID: inttrip_distance: floatclass Config:schema_extra = {"example": {"request_id": "99999","PULocationID": 130,"DOLocationID": 250,"trip_distance": 3.0,}}class TripAPIResponseMessage(APIResponseBase):duration: floatclass Config:schema_extra = {"example": {"reply_code": 0, "duration": 12.785509620119132}}
core/services/trip_duration_api.py:import collectionsimport celery
from loguru import logger
from fastapi import Request
from fastapi.encoders import jsonable_encoderimport config
from core.schemas.trip import TripAPIRequestMessage, TripAPIResponseMessage
from core.utilities.cls_time import Timertask_celery = config.CeleryTasksGeneralConfig
celery_app = celery.Celery()
celery_app.config_from_object(task_celery)class TripDurationApi:# pylint: disable=too-many-instance-attributesdef call_celery_matching(self,pu_location_id: int,do_location_id: int,trip_distance: float,):""":type celery_result: celery.result.AsyncResult"""celery_result = celery_app.send_task(task_celery.task_process_trip,args=[pu_location_id,do_location_id,trip_distance,],queue=task_celery.task_trip_queue,)return celery_resultdef process_api_request(self):celery_result = self.call_celery_matching(self.trip_request.PULocationID,self.trip_request.DOLocationID,self.trip_request.trip_distance,)results: dict = {}try:results = celery_result.get(timeout=60)celery_result.forget()results = results or {}except celery.exceptions.TimeoutError:results = {}reply_code: int = results.pop("reply_code", 1)duration: float = float(results.pop("duration", 0.0))self.response = TripAPIResponseMessage(reply_code=reply_code, duration=duration)self.status_code = 200self.timings = results.pop("timings", {})self.results = results
接下来,我定义一个名为 trip_duration_api.py 的类,在其中处理请求逻辑。
- 在函数process_request_api中,它会收集请求信息
- call_celery_matching 函数将作为任务添加到部署在另一个容器中的消息代理 Redis 队列中。 部署在其他容器中的 ML 模块将从 Redis 中弹出任务并开始处理此任务。 结果是一个承诺,当工作人员完成任务或在到期时间后,它将通知 Web 模块的后台。 请注意第 29 行和第 35 行,其中需要输入 task_celery.task_process_trip 作为 Celery 任务名称,并输入 task_celery.task_trip_queue 作为 Celery 队列
- 第12到14行帮助Web模块通过Celery与ML模块连接
所有内容都被组合并构建到一个 docker 镜像中。
Web Dockerfile:
ARG VM_BASE
FROM $VM_BASEARG VM_USER
ARG VM_HOME
ARG VM_CODE
ARG VM_PIPCOPY . $VM_CODE
WORKDIR $VM_CODE/
RUN rm -rf libs
RUN apk add --no-cache sudo \&& apk add --no-cache --virtual .build-deps gcc musl-dev g++\&& pip install --no-cache-dir -r $VM_PIP \&& apk del .build-depsRUN apk add --no-cache bashRUN adduser --disabled-password --gecos '' $VM_USER \&& addgroup sudo \&& adduser $VM_USER sudo \&& echo '%sudo ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoers \&& chown -R $VM_USER $VM_HOMEUSER $VM_USERWORKDIR $VM_CODE/
EXPOSE 8182
ENTRYPOINT ["boot/docker/uvicorn/entrypoint.sh"]
3.3 Worker模块
在 celery 中,可以在单独的进程或机器中完成的每项工作称为任务。 任务可能多种多样,从抓取网页内容到发送电子邮件,甚至是复杂的运行机器模型。 任务可以在运行时触发,也可以定期触发。 部署后,每个工作线程都可以在一个进程、一个绿色线程中运行……具体取决于我们使用的 Celery 类型。 为了更好地了解 Celery 执行池,可以阅读此博客的更多内容。 在此 API 中,我选择 Celery 池类型 gevent。 Celery的起点可以在boot/docker/celery/trip/entrypoint.sh中找到
#!/usr/bin/env bashUSERNAME="$(id -u -n)"
MODULE="tasks.trip"
REPO_ROOT="repo"
LOGS_ROOT="${REPO_ROOT}/logs/tasks/trip"
LOGS_PATH="${LOGS_ROOT}/daemon.log"sudo mkdir -p ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${LOGS_ROOT} && \
sudo chown -R ${USERNAME} ${REPO_ROOT} && \
source activate venv && \
python -m celery worker \-A ${MODULE} \-Q ${MODULE} \-P gevent \--prefetch-multiplier=1 \--concurrency=4 \--loglevel=INFO \--logfile="${LOGS_PATH}"
请注意,在第 18 行,我选择的 Celery 类型是 gevent。 预取乘数是一次预取的消息数量,这意味着它一次只会为每个工作进程保留一个任务。 并发数是每个 Celery 实例创建的绿色线程的数量。
Celery配置
Celery 配置在 config.py 中定义:
class CeleryTasksGeneralConfig:task_trip_queue = "tasks.trip"task_trip_prefix = "tasks.trip.tasks"task_process_trip = f"{task_trip_prefix}.predict_ride"broker_url = os.environ.get("CELERY_BROKER_URL", None)result_backend = os.environ.get("CELERY_RESULT_BACKEND", None)worker_prefetch_multiplier = int(os.environ.get("CELERY_WORKER_PREFETCH_MULTIPLIER", 1))
上面的文件包含了 Celery 运行所需的所有配置。 第 6 行和第 7 行设置代理 URL 和结果后端(在本例中为 Redis)。 这些配置将从 docker 映像的 env 文件中获取,稍后我将在定义 docker-compose 时进行解释。
当生产者向消息代理发送消息时,它需要定义要使用哪个任务以及在哪个队列中。 然后,根据队列名称和任务名称,Celery 可以将消息分配给处理该任务的正确消费者工作线程。 因此,在第 2 行中,我将队列名称定义为“tasks.trip”,将 task_name 定义为“tasks.trip.tasks.predict_ride”。 回想一下,当 Web 模块执行 Celery 任务时,这些参数在文件 core/services/trip_duration_api.py 中使用。
Celery任务
celery任务在tasks/trip/tasks.py中实现
import celeryimport config
from core.utilities.cls_loguru_config import loguru_setting
from core.services.trip_duration_prediction_task import TripDurationTaskloguru_setting.setup_app_logging()app = celery.Celery()
app.config_from_object(config.CeleryTasksGeneralConfig)
app.autodiscover_tasks(["tasks.trip"])@celery.shared_task(time_limit=60, soft_time_limit=60)
def predict_ride(pu_location_id: int, do_location_id: int, trip_distance: float):return TripDurationTask().process(pu_location_id, do_location_id, trip_distance)
第9行到第11行是我将任务分配给相应的任务名称的地方。 这样以后当客户端调用行程任务时,Celery就会触发执行脚本文件中的任务。 在第 14 行中,我将执行任务的最长时间设置为 60 秒,这意味着如果任务在 60 秒内没有完成,任务将失败并将错误通知给客户端。
行程时间预测任务
import pickle
import collections# import boto3
from loguru import loggerimport config
from core.utilities.cls_time import DictKeyTimer
from core.utilities.cls_constants import APIReply# s3 = boto3.resource("s3")# TRIP_DURATION_MODEL_KEY = config.ModelConfig.s3_trip_model_key()
# TRIP_DURATION_MODEL_BUCKET = config.ModelConfig.s3_bucket()TRIP_DURATION_MODEL_PATH = config.ModelConfig.trip_duration_model()
with open(TRIP_DURATION_MODEL_PATH, "rb") as f_in:dv, model = pickle.load(f_in)def preprare_feature(pu_location_id: int, do_location_id: int, trip_distance: float):features = {}features["PU_DO"] = f"{pu_location_id}_{do_location_id}"features["trip_distance"] = trip_distancereturn featuresclass TripDurationTask:@classmethoddef process(cls, pu_location_id: int, do_location_id: int, trip_distance: float):try:timings = collections.OrderedDict()step_name = "feature_prepare"with DictKeyTimer(timings, step_name):features = preprare_feature(pu_location_id, do_location_id, trip_distance)step_name = "model_predict"with DictKeyTimer(timings, step_name):pred = cls.predict(features)logger.info(f"Predict duration:{pred}")result = {"duration": pred,"reply_code": APIReply.SUCCESS,"timings": timings,}# pylint: disable=broad-exceptexcept Exception:result = {"duration": 0.0,"reply_code": APIReply.ERROR_SERVER,"timings": timings,}return result@classmethoddef predict(cls, features: dict):X = dv.transform(features)preds = model.predict(X)return float(preds[0])
上述文件是实现ML模型的主要位置。 从第 17 行到第 19 行,我加载存储在 repo/models 文件夹中的模型权重。 其他部分是不言自明的,其中回归模型采用包含上车位置、下车位置和行程距离的输入,然后预测行程时间。
4、使用 Docker Compose 连接一切
正如我在开头所解释的,我们需要 3 个模块:Web、Redis 和 ML 模块。 为了连接这三个部分并让它们能够相互通信,我使用 docker-compose 来定义三个 docker 镜像的定义。 当应用程序启动时,将创建三个相应的容器,并在 docker 网络中相互通信。 详细信息可以在 boot/docker/compose/trip_duration_prediction/docker-compose.yml 中找到。
version: "2.3"
services:web:build:context: "${DC_UNIVERSE}"dockerfile: "${WEB_VM_FILE}"args:VM_BASE: "${WEB_VM_BASE}"VM_USER: "${WEB_VM_USER}"VM_HOME: "${WEB_VM_HOME}"VM_CODE: "${WEB_VM_CODE}"VM_PIP: "${WEB_VM_PIP}"platform: linux/amd64image: ${DOCKER_IMAGE_PROJECT_ROOT_NAME}_web:${COMMIT_ID}ports:- "${HTTP_PORT}:8182"volumes:- "${HOST_REPO_DIR}:${WEB_VM_CODE}/repo"restart: alwaysenvironment:VERSION: "${WEB_VERSION}"PROJECT_APP: "${WEB_VM_PROJECT_APP}"REDIS_HOST: "redis"REDIS_PORT: "${REDIS_PORT}"CELERY_BROKER_URL: "redis://redis:${REDIS_PORT}"CELERY_RESULT_BACKEND: "redis://redis:${REDIS_PORT}"redis:image: redis:latestrestart: on-failureexpose:- "${REDIS_PORT}"command: redis-server --port "${REDIS_PORT}"worker:build:context: "${DC_UNIVERSE}"dockerfile: "${WORKER_VM_FILE}"args:VM_BASE: "${WORKER_VM_BASE}"VM_USER: "${WORKER_VM_USER}"VM_HOME: "${WORKER_VM_HOME}"VM_CODE: "${WORKER_VM_CODE}"VM_CONDA: "${WORKER_VM_CONDA}"platform: linux/amd64volumes:- "${HOST_REPO_DIR}:${WORKER_VM_CODE}/repo"image: ${DOCKER_IMAGE_PROJECT_ROOT_NAME}_worker:${COMMIT_ID}restart: alwaysruntime: nvidiaenvironment:NVIDIA_VISIBLE_DEVICES: "0"PROJECT_APP: "${WORKER_VM_PROJECT_APP}"REDIS_HOST: "redis"REDIS_PORT: "${REDIS_PORT}"CELERY_BROKER_URL: "redis://redis:${REDIS_PORT}"CELERY_RESULT_BACKEND: "redis://redis:${REDIS_PORT}"
.env 文件包含运行 docker-compose 时运行的所有参数,可以在 boot/docker/compose/trip_duration_prediciton/.env中找到。DC_UNIVERSE=../../../..HTTP_PORT=8182
REDIS_PORT=6379
GPU_MEMORY_SET=800WEB_VERSION=v1
WEB_VM_FILE=boot/docker/uvicorn/Dockerfile
WEB_VM_BASE=python:3.8-alpine
WEB_VM_USER=docker
WEB_VM_HOME=/home/docker
WEB_VM_CODE=/home/docker/workspace
WEB_VM_PIP=./boot/docker/uvicorn/requirements.txt
WEB_VM_PROJECT_APP=apps.apiWORKER_VM_FILE=boot/docker/celery/trip/Dockerfile
WORKER_VM_BASE=nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04
WORKER_VM_USER=docker
WORKER_VM_HOME=/home/docker
WORKER_VM_CODE=/home/docker/workspace
WORKER_TORCH_DIR=/home/docker/.torch/models
WORKER_VM_CONDA=./boot/docker/celery/cuda90.yml
WORKER_VM_PROJECT_APP=tasks.trip
5、测试应用程序
运行整个应用程序。 如下图所示,当我启动 API 时,有三个正在运行的容器。
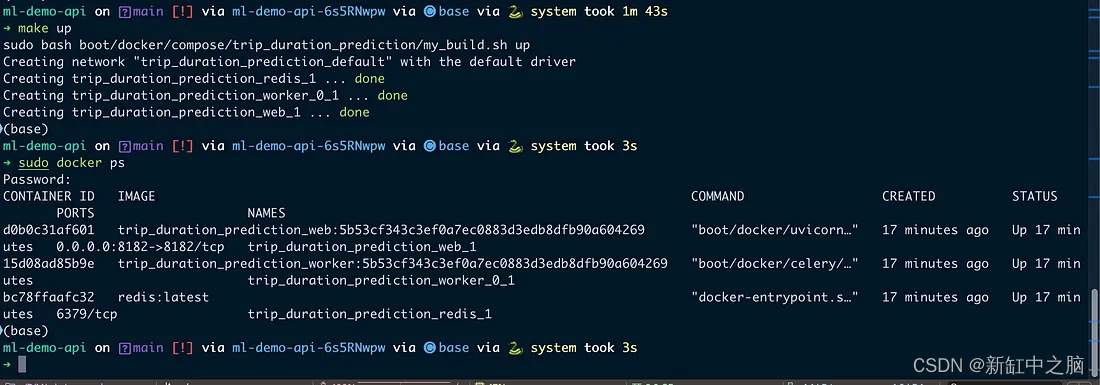
3个 docker 容器已启动并运行
Web容器运行在端口8182,我们可以通过地址:localhost:8182/docs访问API文档。 这是 FastAPI 的利基功能之一,当我们以零的努力完成 API 实现时,我们将立即获得 Swagger 文档。
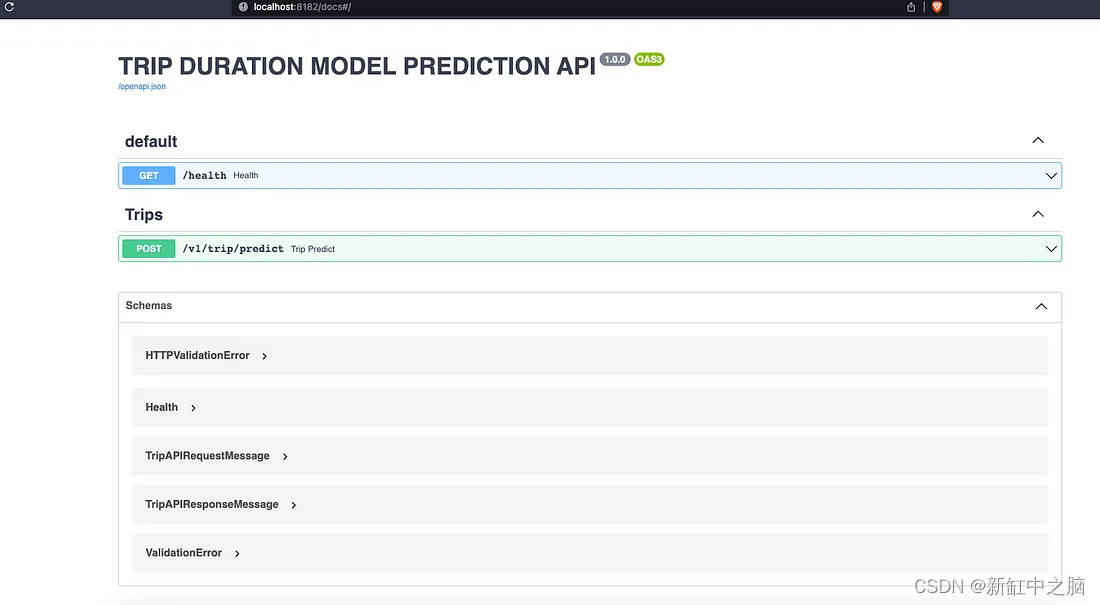
API Swagger 文档
然后,让我们尝试在 /v1/trip/predict 运行 API 端点,查看预测并检查日志返回。
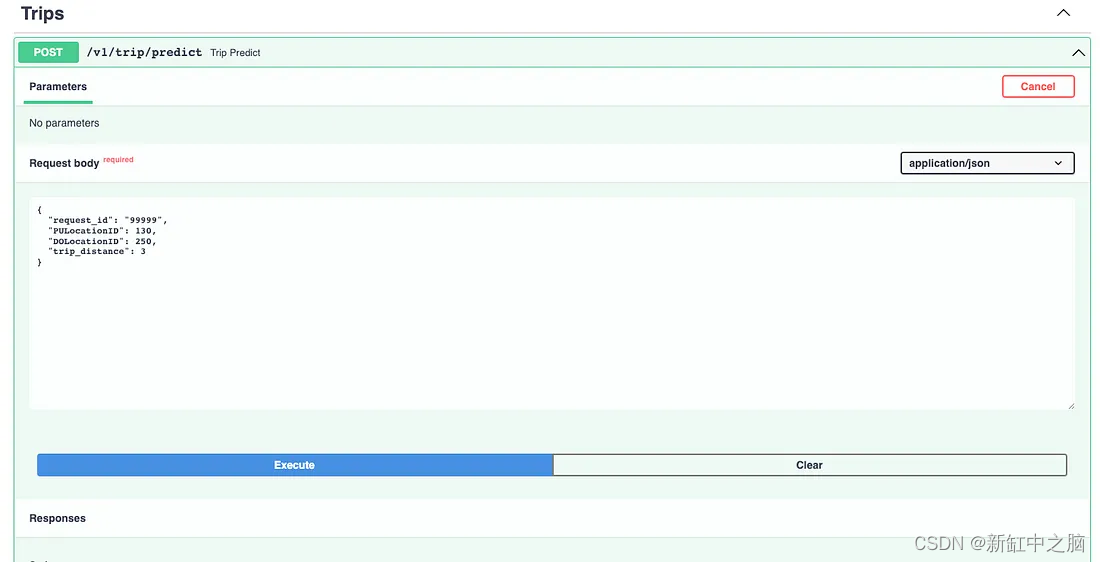
行程预测端接点
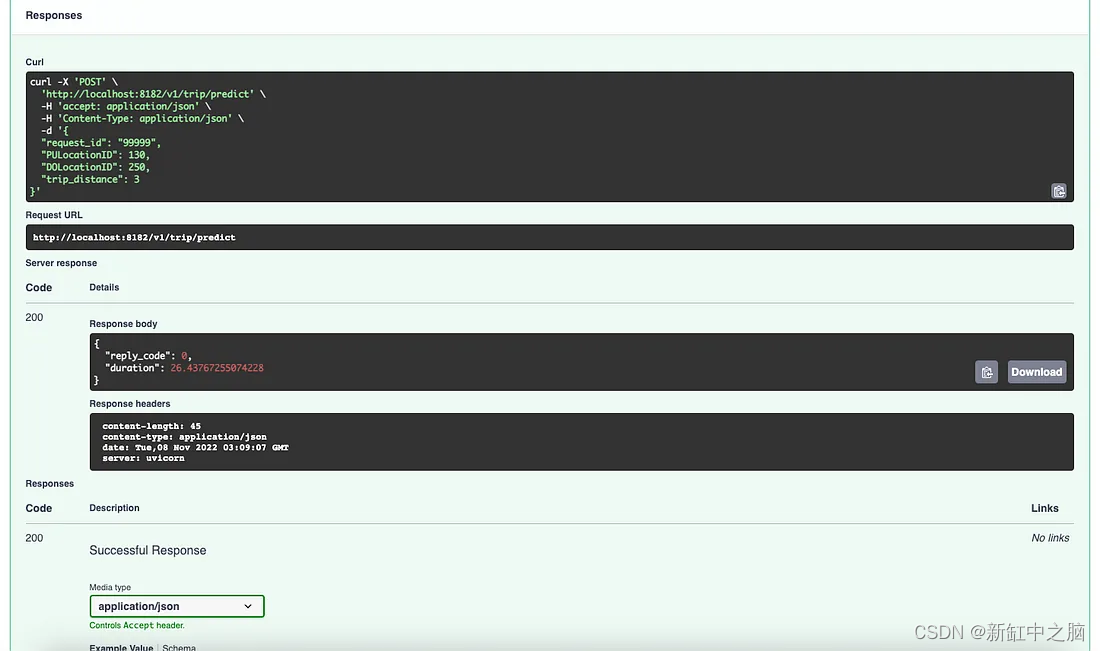
行程预测响应

web模块的日志记录
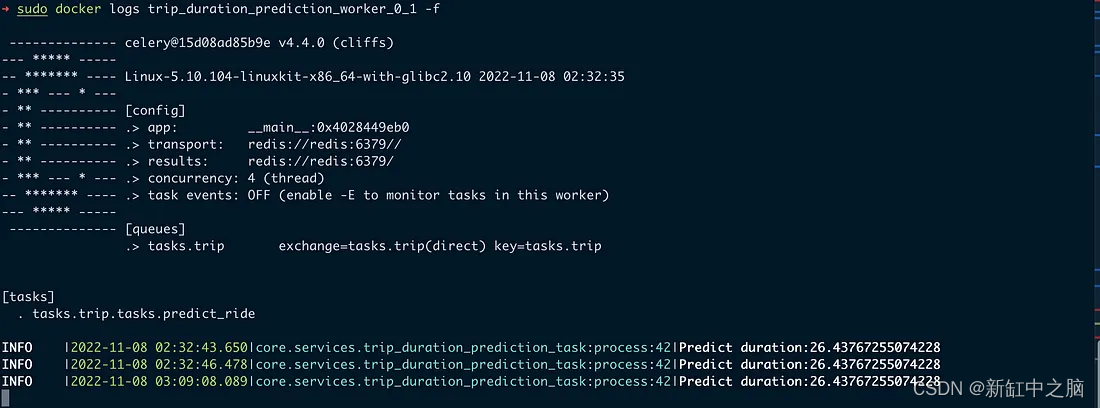
worker模块的日志记录
一旦请求从客户端发送到 Web 模块,它将在工作线程中使用 Celery 作为单独的进程或线程进行异步处理。 这带来了很多好处:
- 繁重的任务在单独的进程/线程中处理,这可以帮助增加我们可以处理的请求数量,因为它不会阻止客户端调用。
- ML 模块在另一个线程中实现,包装在单独的 docker 映像中,这意味着数据科学家或机器学习工程师可以独立保留其实现代码和包。
- 如果请求数量增加,我们可以轻松增加 ML 模块的数量来处理请求的激增,同时 Web 模块可以保持不变
6、结束语
在这篇博客中,我介绍了如何使用任务队列分布式架构来实现服务于ML模块的API。 使用Celery、FastAPI和Redis可以帮助更好地处理ML运行过程等长时间运行的任务,从而提高整体性能。
最初的想法是我在以前的公司工作时不断发展和改进的。 感谢山洪和乔纳森,他们是很棒的前同事,我从他们身上学到了很多好东西。
如果你想参考完整代码,请查阅github。
原文链接:基于队列的ML服务实现 — BimAnt