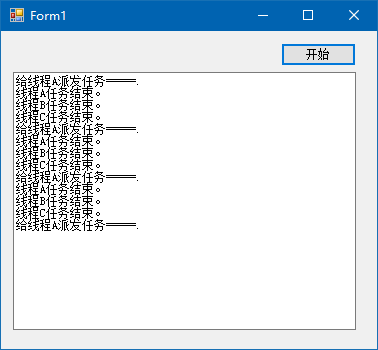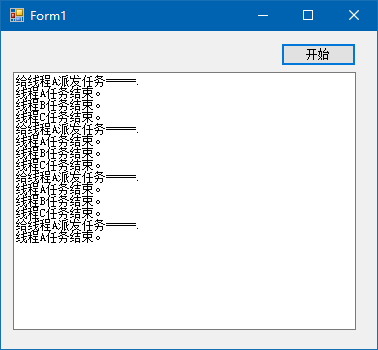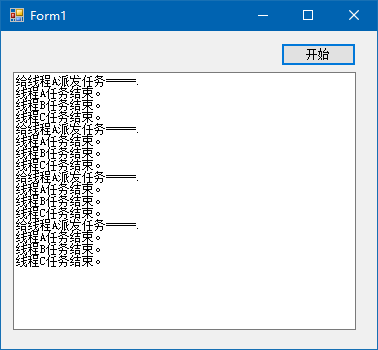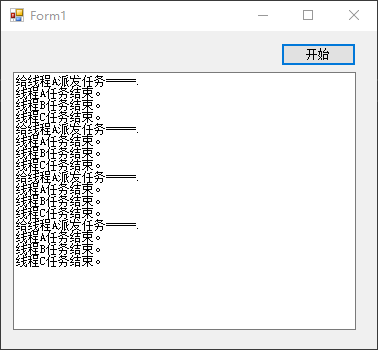
课程资源:(林子雨)Spark编程基础(Python版)_哔哩哔哩_bilibili
第4章 RDD编程(21节)
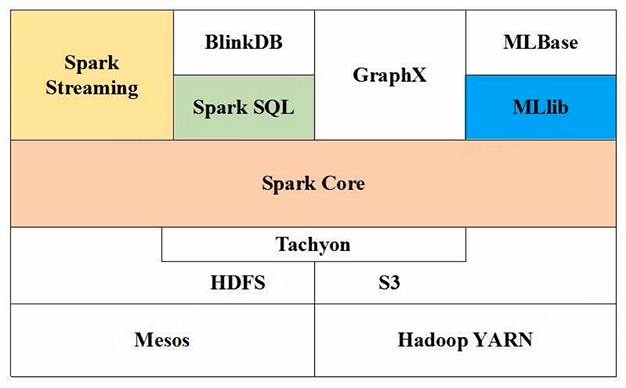
Spark生态系统:
- Spark Core:底层核心(RDD编程是针对这个)
- Spark SQL:SQL查询
- Spark Streaming:流计算(Structured Streaming:结构化数据流)
- Spark MLlib:机器学习
RDD编程:对RDD进行一次又一次的转换操作
(一)RDD编程基础
1、创建
两种方式:
- 从文件系统中加载数据创建RDD:分布式文件系统hdfs 或 本地文件系统 或 云端文件如Amazon S3(Amazon云端存储服务)
- 通过并行集合(数组)创建RDD:对集合进行并行化
(1)从文件系统中加载数据:Spark的SparkContext通过 sc.textFile() 读取数据,生成内存中的RDD
Driver节点为指挥所;SparkContext对象为指挥官

# 从本地文件系统中加载数据创建RDD
# sc即driver节点里的SparkContext对象
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt") # 本地文件是///
lines.foreach(print) # 遍历RDD每个元素并输出SparkContext在独立应用程序(即代码文件)里需要编写代码生成;但在pyspark交互式执行环境里,系统会默认创建sc,不需再人为创建
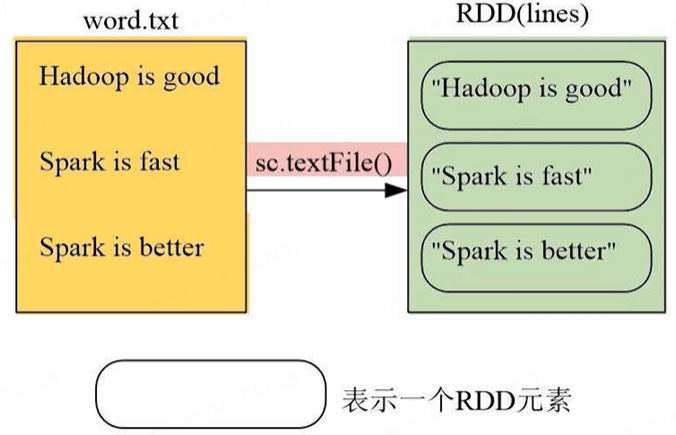
(2)从分布式文件系统HDFS中加载数据:
# 三条语句完全等价,可以使用其中任一种
lines = sc.textFile("hdfs://localhost:9000/user/hadoop/word.txt") # hdfs://,localhost为主机名,9000为端口号(系统默认去当前登录Ubuntu系统的用户在HDFS中所对应的用户主目录去找)
lines = sc.textFile("/user/hadoop/word.txt") # 用户主目录,Linux系统默认/home/用户名,简写为/~
lines = sc.textFile("word.txt") # txt文件放在当前用户主目录下- Linux系统主目录默认为/home/用户名,简写为~
- Hadoop文件系统默认为当前登录Linux系统的用户,hdfs://localhost:9000/user/用户名/(全称路径),可以只写为 /user/用户名/
(3)通过并行集合(数组/列表)创建RDD:SparkContext 的 sc.parallelize() 方法,可以对array并行化,生成内存中的RDD
array = [1,2,3,4,5]
rdd = sc.parallelize(array)
rdd.foreach(print) # 遍历取出打印
# 结果:
# 1
# 2
# 3
# 4
# 5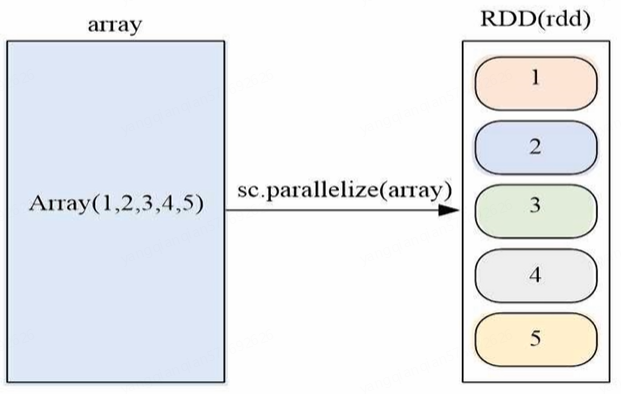
2、基本操作
RDD操作:
- 转换操作(Transformation):
- filter(过滤)
- map(一对一映射)
- flatMap(输出0~多个结果)
- groupByKey(Key相同的分组)
- reduceByKey(根据Key分组后对分组的值计算)
- 行动操作(Action):
- count(数据集中元素个数)
- collect(以列表形式返回数据集中所有元素)
- first(数据集中第一个元素)
- take(n)(以列表形式返回数据集中前n个元素)
- reduce(func)(聚合数据集中的元素)
- foreach(func)(将数据集中每个元素传到func运行)
- 惰性机制:转换操作只记录轨迹,行动操作才真正执行计算
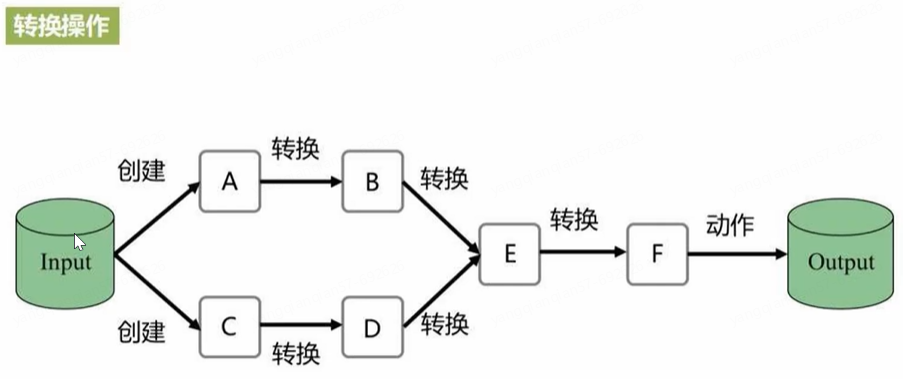
RDD转换 <=> 业务逻辑完成一次又一次转换(形成DAG有向无环图,Spark即解析DAG,生成很多个Stage,每个阶段的子任务提交到不同工作节点的线程去运行)。很多简单的转换组合后可实现复杂的业务逻辑
- 对于RDD而言,每一次转换操作都会产生不同的RDD,供一个操作使用(RDD是只读的,一旦生成无法修改,只有在转换的过程中才能修改,生成新的RDD后又无法修改)
- 转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,只有遇到行动操作(动作类型操作Action)时才会发生真正的计算,从血缘关系的源头开始进行从头到尾的计算操作
(1)转换操作

- filter(func)
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt") # 从底层文本文件加载生成内存中RDD
linesWithSpark = lines.filter(lambda line:"Spark" in line) # 匿名函数/lambda表达式
linesWithSpark.foreach(print) # 输出包含Spark的行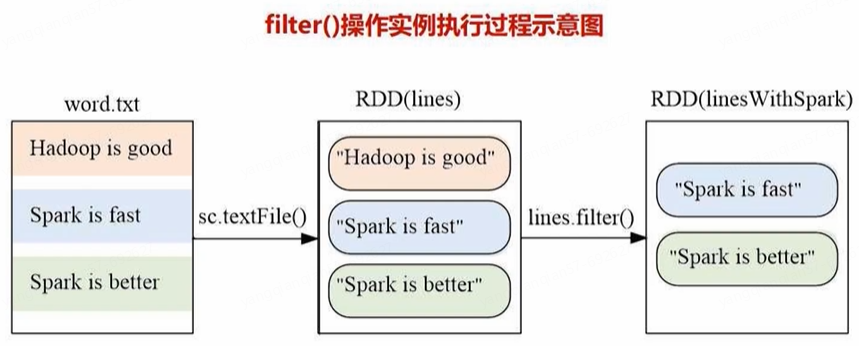
- map(func)
data = [1,2,3,4,5]
rdd1 = sc.parallelize(data) # 得到一个RDD
rdd2 = rdd1.map(lambda x:x+10)
rdd2.foreach(print)
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
words = lines.map(lambda line:line.split(" ")) # 一行语句被拆分后得到的是list
words.foreach(print) # 包含3个元素,每个元素都是list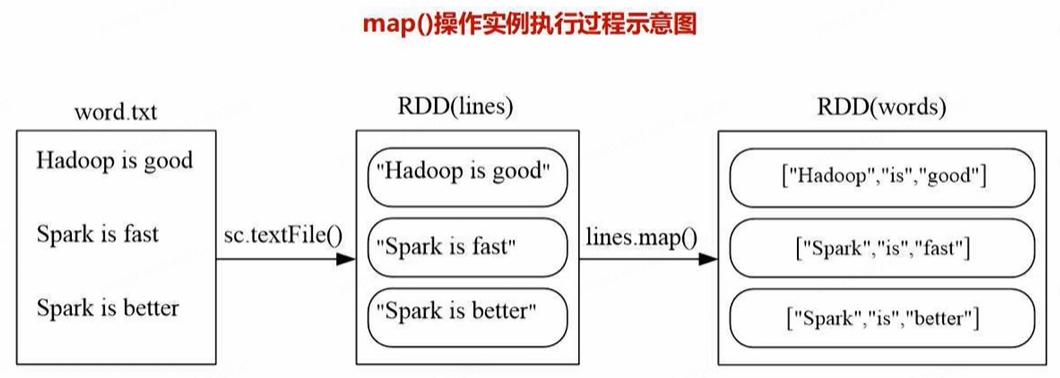
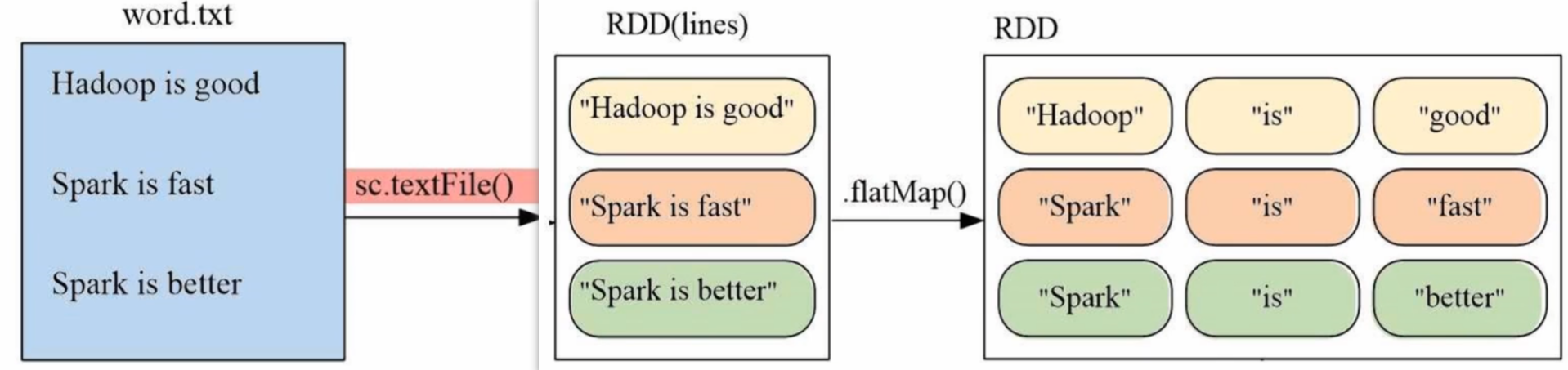
- flatMap(func)
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt")
words = lines.flatMap(lambda line:line.split(" "))
words.foreach(print) # 包含9个元素(英文单词)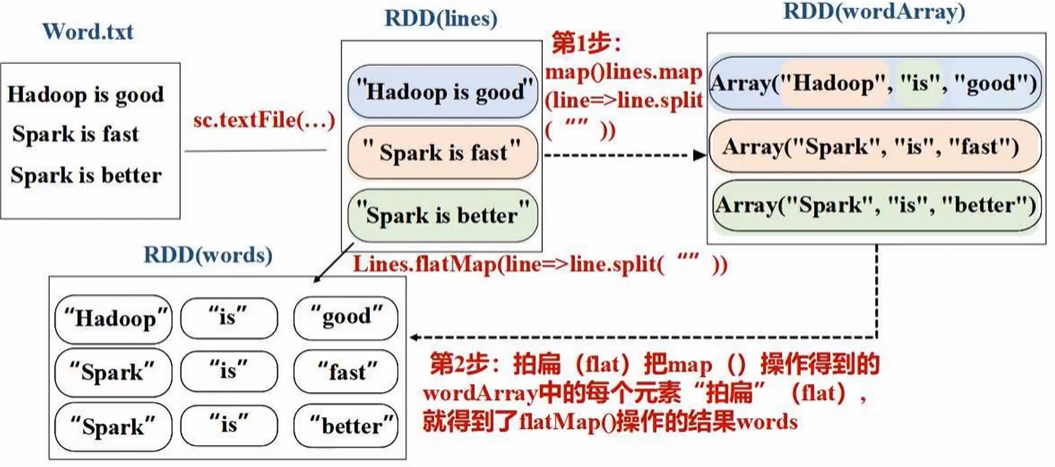
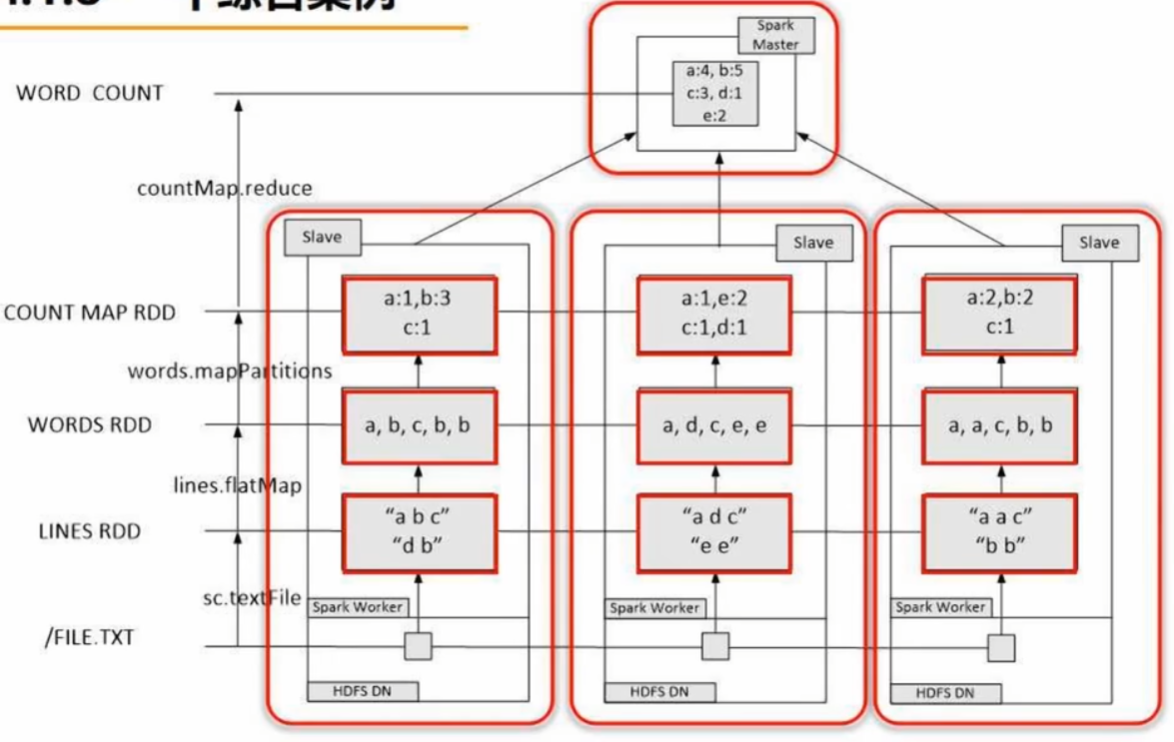
词频统计就是用 flatMap 将一行行语句打散成一个个单词
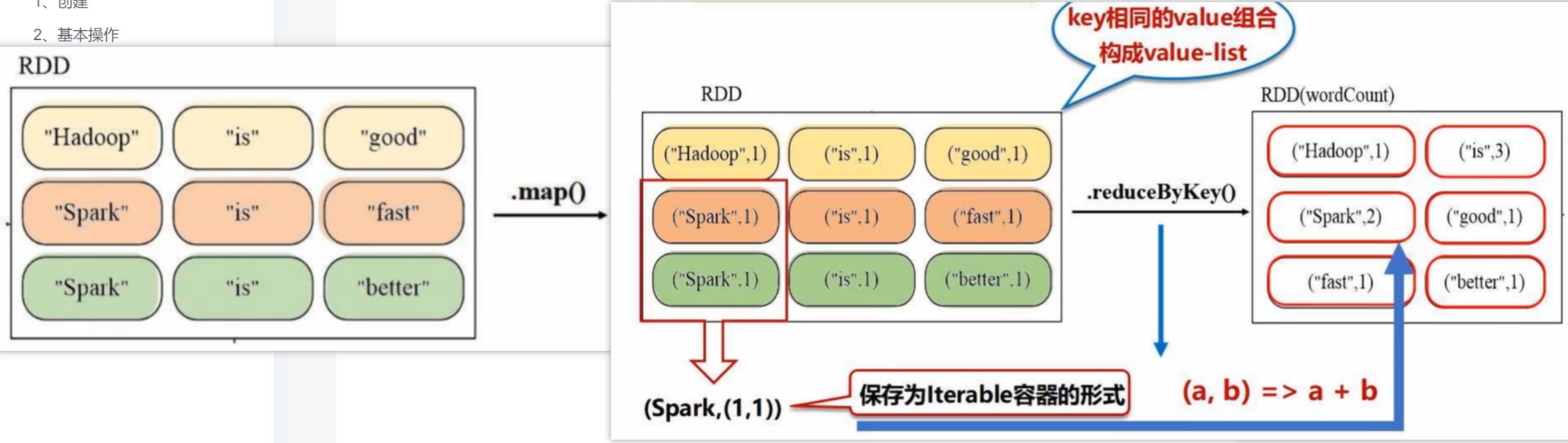
- groupByKey()
应用于key-value键值对数据集,返回(key, iterable),即把key相同的值封装成一个可迭代对象
# 并行化方式生成列表封装的数据集,列表里的元素为键值对
words = sc.parallelize([("Hadoop",1), ("is",1), ("good",1), ("Spark",1), ("is",1)])
words1 = words.groupByKey() # 相同key的值会归并起来,pyspark.resultiterable.ResultIterable object封装
words1.foreach(print)
- reduceByKey(func)
在groupByKey基础上对value list按照func进行计算
words = sc.parallelize([("Hadoop",1), ("is",1), ("good",1), ("Spark",1), ("is",1)])
words1 = words.reduceByKey(lambda a,b:a+b)
words1.foreach(print) # 如('is',2) 即 is出现2次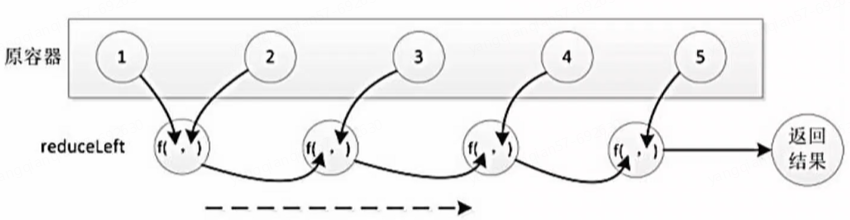
如若("is",(1,1,1)),第一个1赋给a,第二个1赋给b,求和得到2赋给a,第三个1赋给b,求和得到3,返回最终结果

(2)行动操作
转换类型操作为惰性机制,并不真正发生计算,只记录轨迹;当遇到第一个行动类型操作时执行真正的计算(从底层磁盘加载数据、生成数据、转换、得到结果)
- count():返回数据集中的元素个数
- collect():以数组/列表的形式返回数据集中的所有元素(封装在列表里返回)
- first():返回数据集中的第一个元素
- take(n):以数组/列表的形式返回数据集中的前n个元素
- reduce(func):通过函数func(输入两个参数并返回一个值)聚合数据集中的元素
- foreach(func):将数据集中的每个元素传递到函数func中运行
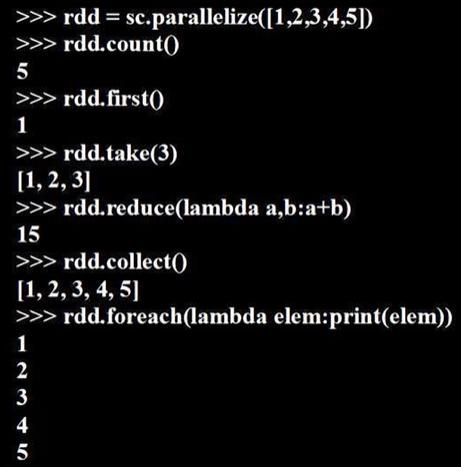
rdd.reduce(lambda a,b:a+b):
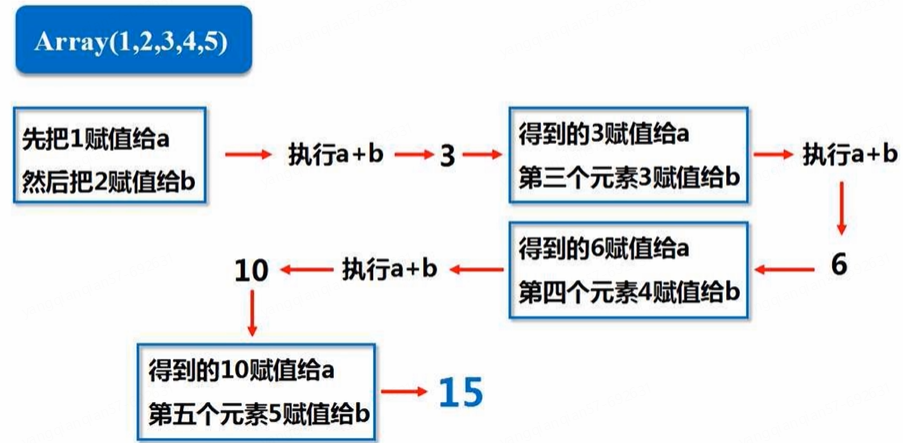
惰性机制:
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/word.txt") # 转换操作,只是记录轨迹,并未真正加载
lineLengths = lines.map(lambda s:len(s)) # 转换操作,只是记录轨迹,并未真正加载
totalLength = lineLengths.reduce(lambda a,b:a+b) # 行动操作,真正执行从头到尾计算
print(totalLength) # 每行长度相加,得到总长度3、持久化
多次反复访问同样一组值,不做持久化的话,每次访问都需要重新生成,非常耗时(对于迭代计算而言代价很大,经常需要多次重复使用同一组数据)。持久化将其保存到内存中,下次使用时不需要从头计算

可以通过持久化(缓存)机制避免这种重复计算的开销。持久化后的RDD将会被保留在计算节点的内存中被后面的行动操作重复利用
可以使用 persist() 方法对一个RDD标记为持久化(之所以说标记为持久化,是因为出现 persist() 语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化)
参数:
- MEMORY_ONLY(只存在内存中):把RDD作为反序列化的对象存在JVM中,若内存不足,就按先进先出原则替换内容 RDD.cache() = RDD.persist(MEMORY_ONLY)
- MEMORY_AND_DISK(同时保存内存和磁盘):优先保存在内存中,内存不足的部分再存放磁盘

.unpersist() 方法手动把持久化的RDD从缓存中移除
4、分区
RDD就是弹性分布式数据集,可以在计算过程中不断动态调整分区个数
(1)好处:增加并行度(可以在多个节点上同时发生计算);减少通信开销
- 增加并行度:

- 减少通信开销:
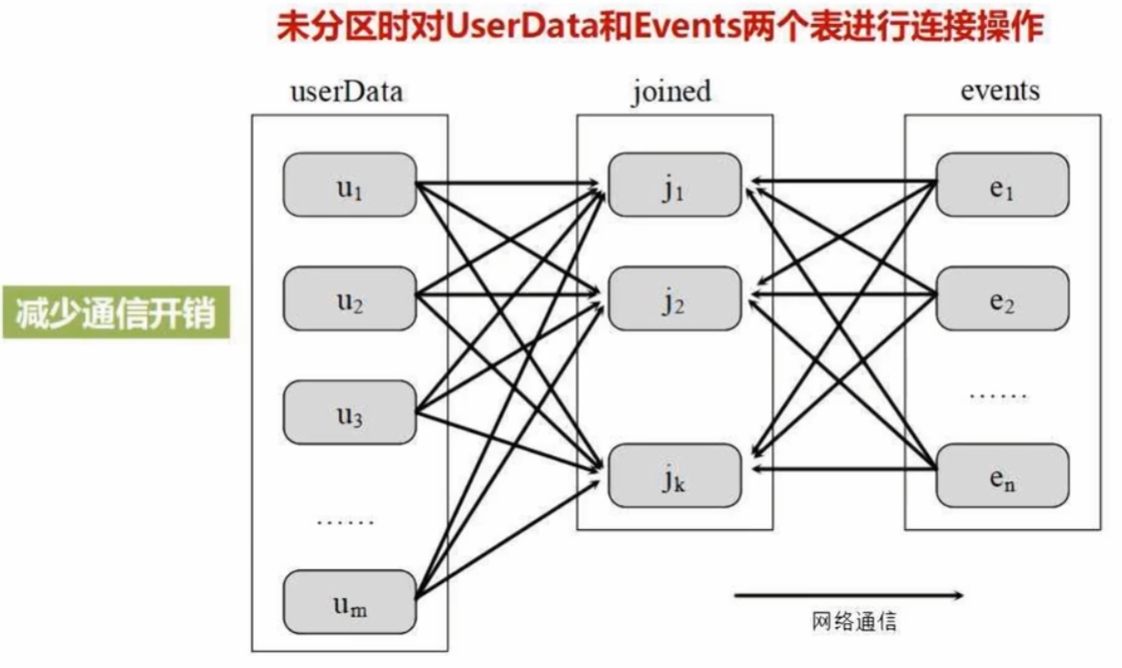
- userData表:大表,成千上百万用户,包括userID 和 userInfo(数据分块保存在不同机器上,每个块的用户ID都散布在0-1000万之间)
- Events表:小表,包括userID 和 LinkInfo,记录用户在过去五分钟内所访问的网站链接
连接两表,让j1负责连接0-100w的用户id,以此类推
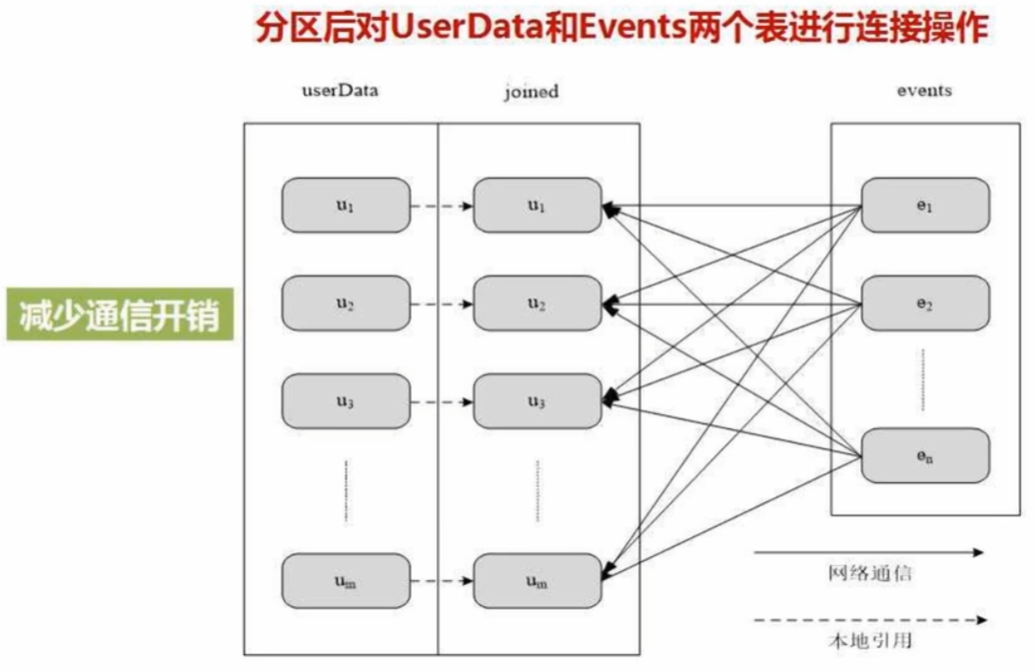
分区后只涉及events表多次的数据分发
(2)分区原则:分区个数 = 集群中CPU核心数目

对于Spark不同部署模式(Local模式、Standalone模式、YARN模式、Mesos模式)而言,通过设置具体参数值(spark.default.parallelism)指定默认的分区数目
- Local模式:默认为本地机器的CPU数目,若设置了Local[N],则默认为N
- Apache Mesos模式:默认分区数为8
- Standalone模式:集群中所有CPU核心数目总和 和 2 中取较大值
- YARN模式:集群中所有CPU核心数目总和 和 2 中取较大值
(3)指定分区个数:在调用 textFile() 和 parallelize() 方法时指定分区个数
sc.textFile(path, partitionNum)
# path指定要加载的文件的地址
# partitionNum用于指定分区个数list = [1,2,3,4,5]
rdd = sc.parallelize(list,2) # 设置两个分区(4)使用repartition()方法重新设置分区个数:通过转换操作得到新RDD时,直接调用repartition方法即可

(5)自定义分区方法:
- 哈希分区 HashPartitioner
- 区域分区 RangePartitioner
- 自定义分区
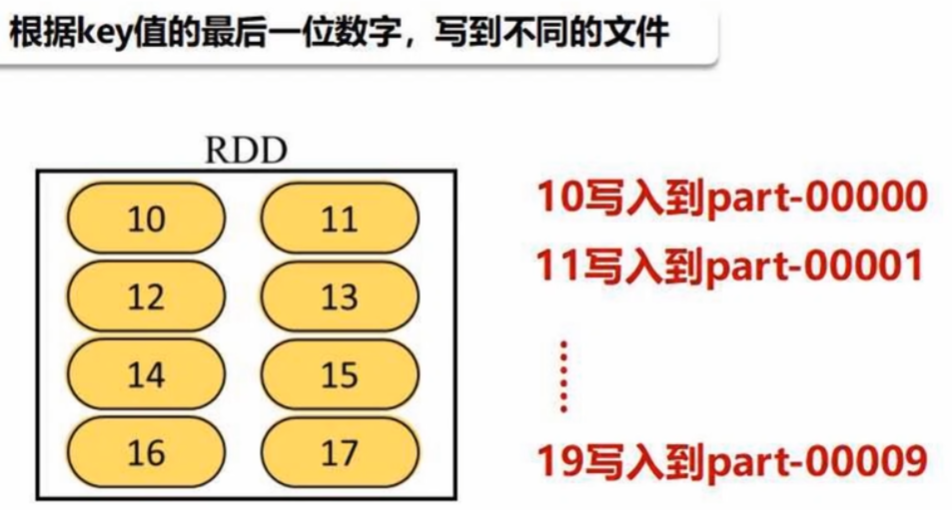
from pyspark import SparkConf, SparkContextdef MyPatitioner(key):print("MyPatitioner is running")print("The key is %d" %key)return key%10 # 作为分区编号返回def main():print("The main function is running")conf = SparkConf().setMaster("local").setAppName("MyApp")sc = SparkContext(conf=conf)data = sc.parallelize(range(10),5) # 分成5个分区data.map(lambda x:(x,1)) \ # 键值对.partitionBy(10, Mypartitioner) \ # 根据key分区。.partitionBy只接受键值对类型.map(lambda x:x[0]) \ # 再从键值对转回原格式.saveAsTextFile("file:///usr/local/spark/mycode/rdd/partitioner") # 写入10个分区,每个分区各1个文件if __name__ == '__main__':main().partitionBy只接受键值对类型
使用如下命令运行 TestPartitioner.py:
cd /usr/local/spark/mycode/rdd
python3 TestPartitioner.py或者,使用如下命令运行 TestPartitioner.py:
cd /usr/local/spark/mycode/rdd
/usr/local/spark/bin/spark-submit TestPartitioner.py5、基本实例(词频统计)
再次强调:
本地文件是三个/,即file:///
hdfs文件是两个/,即hdfs://

在一个集群中同时部署Hadoop和Spark,把集群中某个节点既作为HDFS的存储节点,也作为Spark的WorkerNode,即Spark的计算组件和HDFS的存储组件放在同一台机器上
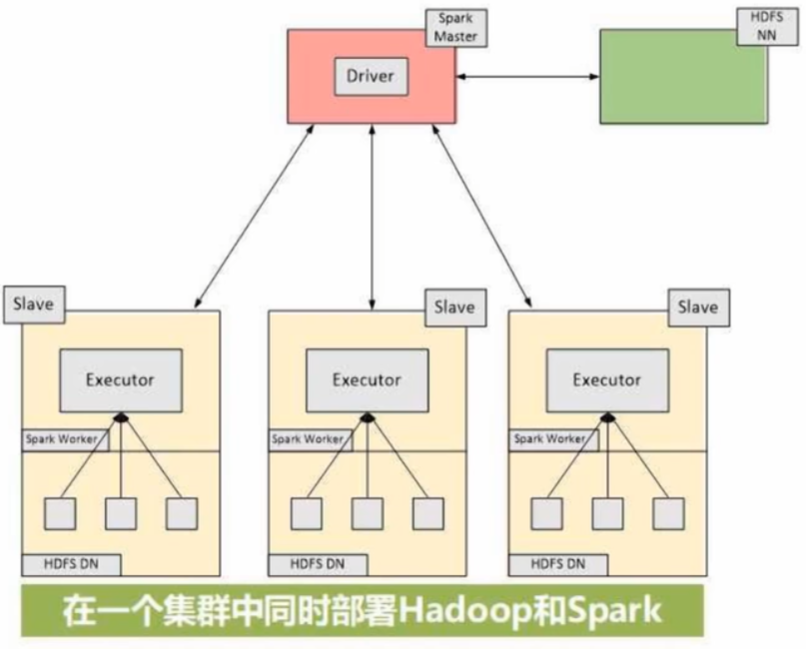
分布式词频统计:
(二)键值对RDD
键值对RDD:RDD的每个元素都是一个键值对 (key, value)
1、创建
(1)从文件中加载
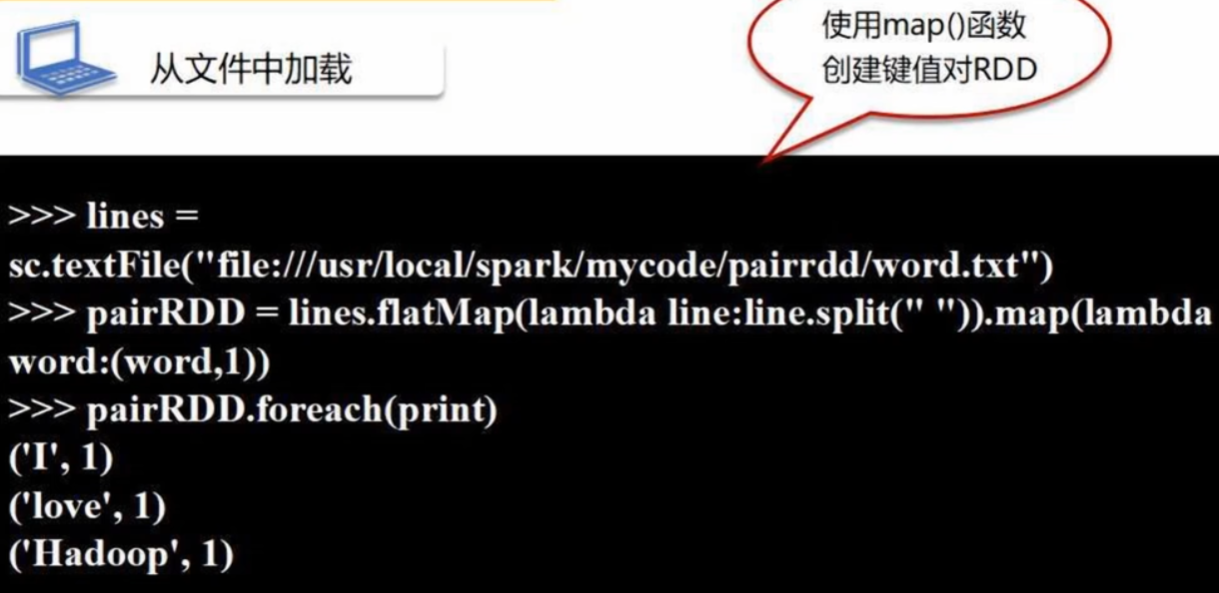
(2)通过并行集合(列表)创建

2、常用的键值对RDD转换操作
- reduceByKey(func):使用func函数合并具有相同键的值
- groupByKey():对具有相同键的值进行分组(ResultIterable对象封装)
总结:groupByKey是对每个key进行操作,但只生成一个sequence,本身不能自定义函数,需要先用groupByKey生成RDD,然后才能对此RDD通过map进行自定义函数操作;reduceByKey用于对每个key对应的多个value进行merge操作,能在本地先进行merge操作,且merge操作可以通过函数自定义
- keys:把Pair RDD中的key返回形成一个新的RDD
- values:把Pair RDD中的value返回形成一个新的RDD
- sortByKey():返回一个根据键排序的RDD,默认True(升序)
- mapValues(func):对键值对RDD中的每个value都应用一个函数,key不会发生变化
- join:内连接。对于给定的两个输入数据集 (K, V1) 和 (K, V2),只有在两个数据集中都存在的key才会被输出,最终得到一个 (K, (V1,V2)) 类型的数据集
- combineByKey
(1)reduceByKey(func):先把key相同的值归并起来,再对值列表用func进行聚合计算

(2)groupBykey()


对比 reduceByKey 和 groupByKey:

一个 reduceByKey 等价于 一个 groupByKey + map
(3)keys()

(4)values()

(5)sortByKey()

- sortByKey() 和 sortBy() 的区别:sortBy()可以根据值进行排序,而sortByKey() 只能根据键

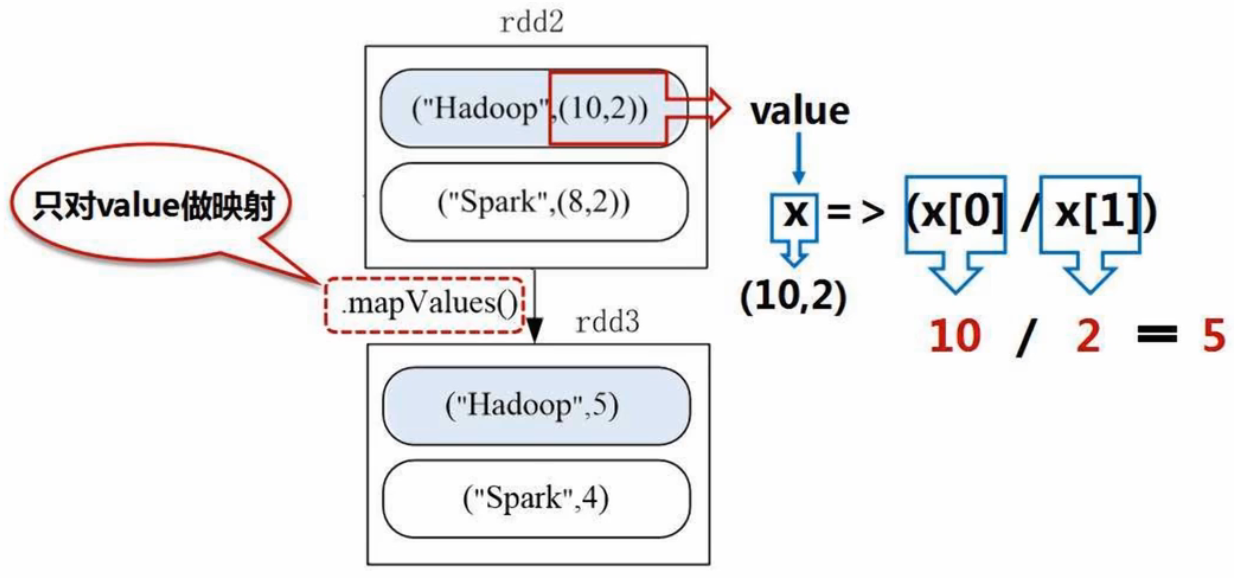
(6)mapValues(func):key不变,value用func(lambda表达式)进行计算

3、综合实例
给定一组键值对,key为图书名称,value为某天图书销量。计算每种图书的每天平均销量

reduceByKey():
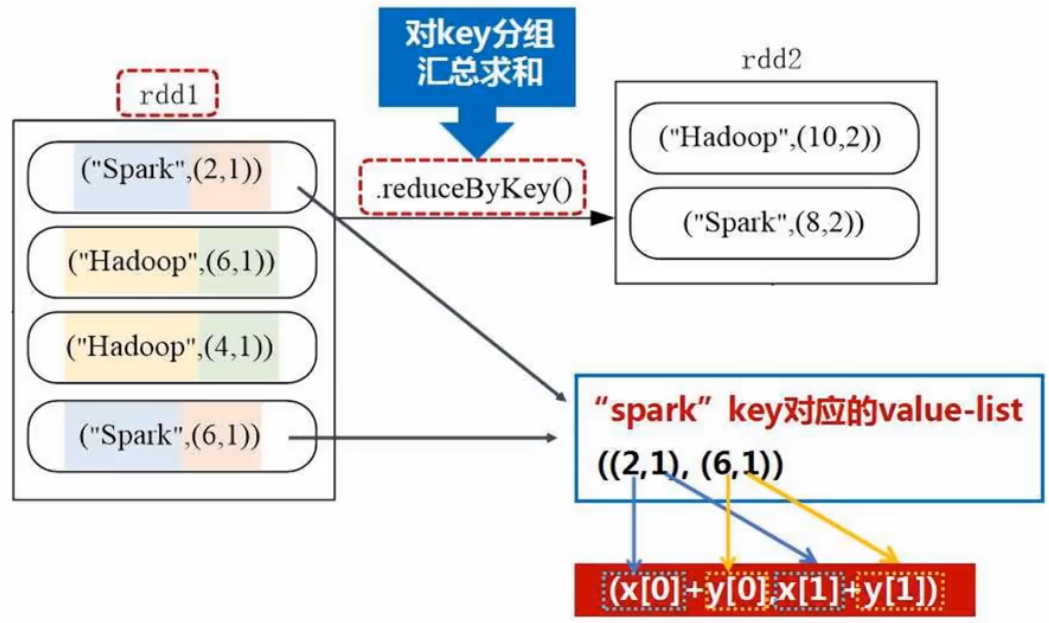
mapValues():
(三)数据读写
1、文件数据读写
(1)本地文件系统数据读写:

- 注意:Spark采用惰性执行机制,即使输入了错误的语句,Spark-Shell也不会马上报错
把RDD写入到文本文件中 .saveAsTextFile(给出的是目录,而不是具体文件,因为存在分区的概念):

再次把数据加载到RDD中,也要写目录,而不是文件:

(2)分布式文件系统HDFS数据读写:
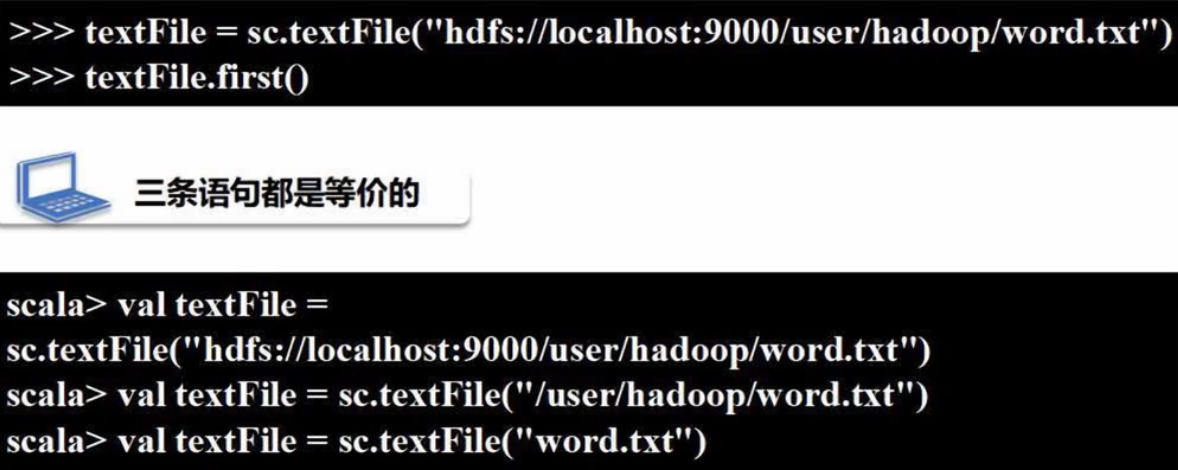
把RDD中的数据保存到HDFS文件中(路径是目录,而不是具体文件):

再次强调,本地文件是file:///开头,而分布式文件是hdfs://开头
2、读写HBase数据
(1)HBase简介
HBase(分布式数据库)是Google BigTable的开源实现,也是Hadoop的成员组件,构建在Hadoop分布式文件系统HDFS基础上。即HBase的数据是保存在底层HDFS中的

特性:
- 每个值是一个未经解释的字符串,没有数据类型
- 用户在表中存储数据,每一行都有一个可排序的行键和任意多的列
- 表在水平方向由一个或者多个列族组成,一个列族中可以包含任意多个列,同一个列族里面的数据存储在一起
- 列族支持动态扩展,可以很轻松地添加一个列族或列,无需预先定义列的数量以及类型,所有列均以字符串形式存储,用户需要自行进行数据类型转换
- HBase中执行更新操作时,并不会删除数据旧的版本,而是生成一个新的版本,旧版本仍然保留(这是和HDFS只允许追加、不允许修改的特性相关的)
概念:
- 表:HBase采用表来组织数据,表由行和列组成,列划分为若干个列族
- 行:每个HBase表都由若干行组成,每个行由行键(row key)来标识
- 列族:一个HBase表被分组成许多列族(Column Family)的集合,它是基本的访问控制单元
- 列限定符:列族里的数据通过列限定符(或列)来定位
- 时间戳:每个单元格都保存着同一份数据的多个版本,这些版本采用时间戳进行索引
- 单元格:在HBase表中,通过行、列族和列限定符确定一个单元格(cell),单元格中存储的数据没有数据类型,总被视为字节数组byte[]
HBase - 稀疏、多维度、排序、映射表
- 相关信息全部汇总在一个表里,不需进行多表连接操作,有利于在大数据时代获得高的数据读写性能
- 一个表分为若干行和若干列族,一个列族又包含很多列/列限定符,每个行由行键(row key)来标识
- 行键和列限定符交叉的位置叫单元格,值是以一个单元格的形式写入的(关系型数据库是一行行存储写入的)
- 每个单元格的值可能会发生变化,但HBase底层存储是基于HDFS(只读,不可修改),通过将指针指向新版本数据间接实现修改

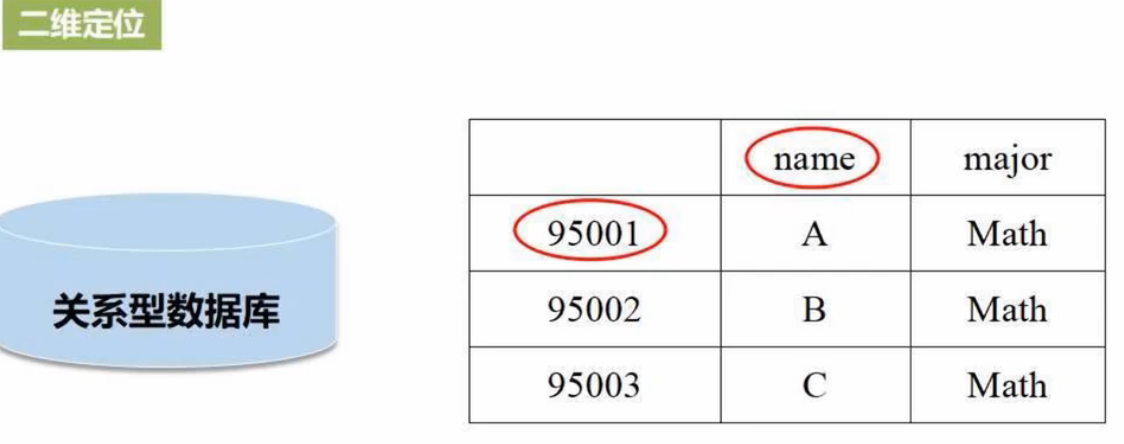
四维坐标定位:行键-列族-列限定符-版本时间戳
- 关系数据库是二维定位,给出行、列即可唯一确定一个单元格值
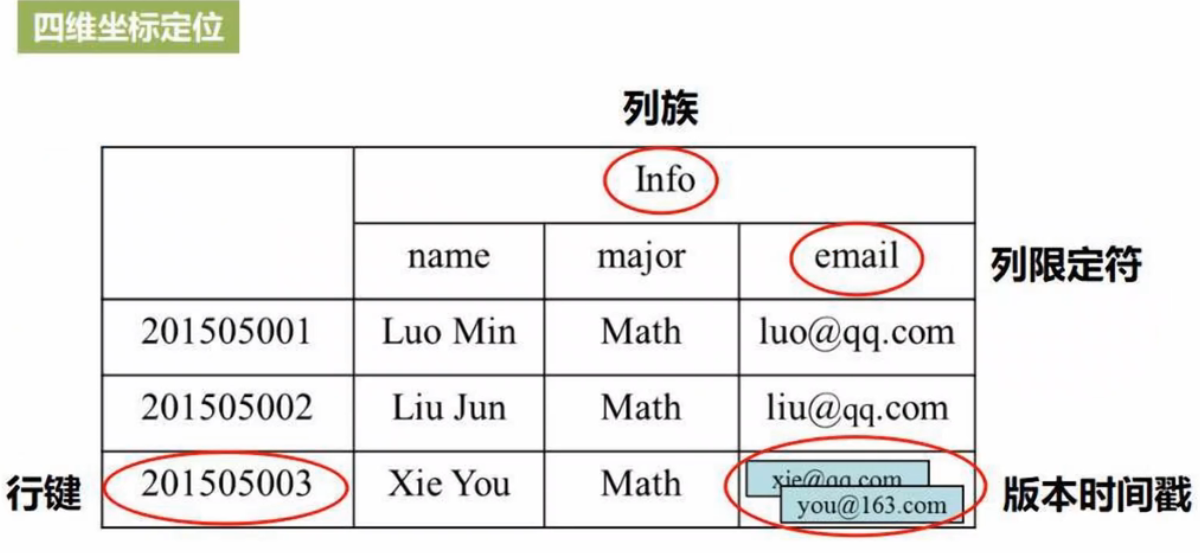
HBase概念视图:列族contents、列限定符html
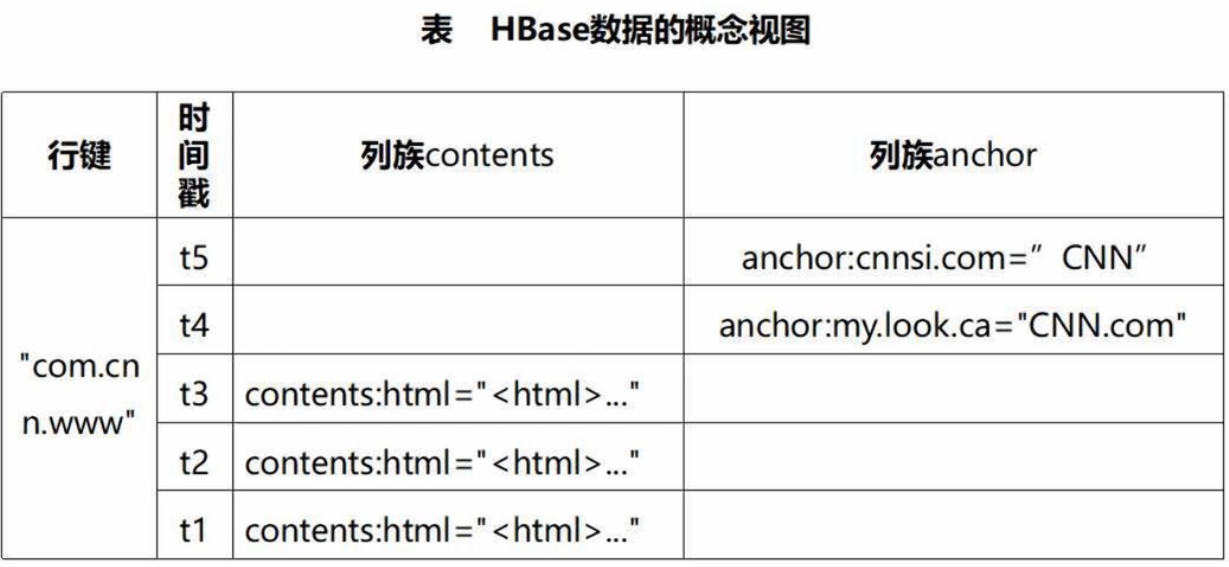
HBase物理视图:底层为行键+列族+时间戳
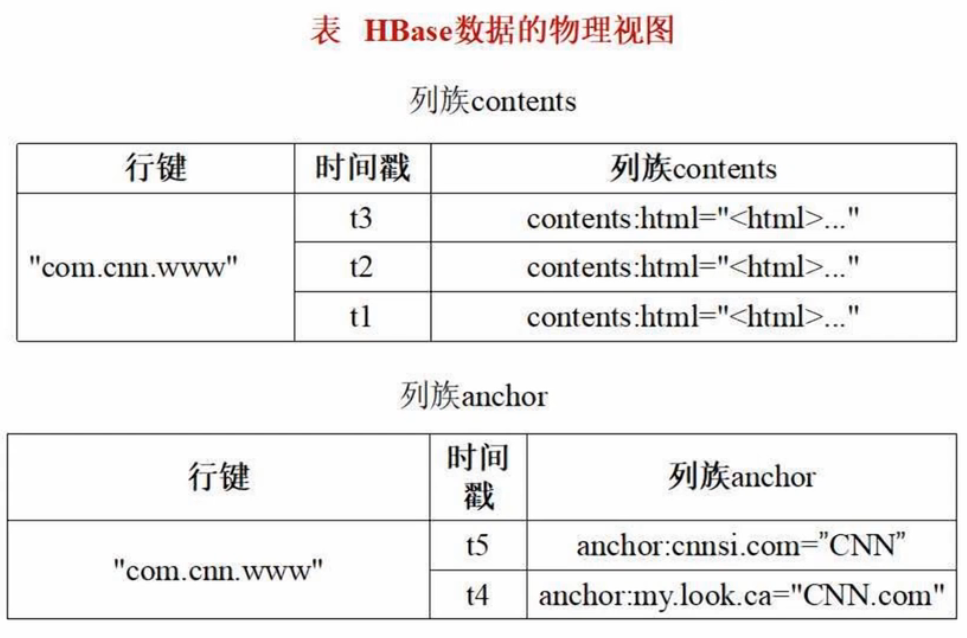
保存机制:水平分区+切分成很多列族(分布式存储)
(2)创建HBase表
启动HBase(底层存储基础为HDFS,故要先启动Hadoop):
# 启动Hadoop
cd /usr/local/hadoop # 进入Hadoop安装目录
./sbin/start-all.sh # 启动Hadoop
# 或start-dfs.sh(启动hdfs)# 启动HBase
cd /usr/local/hbase # 进入HBase安装目录
./bin/start-hbase.sh # 启动HBase
./bin/hbase shell # 启动HBase Shell创建student表(确保数据库里不存在student表):
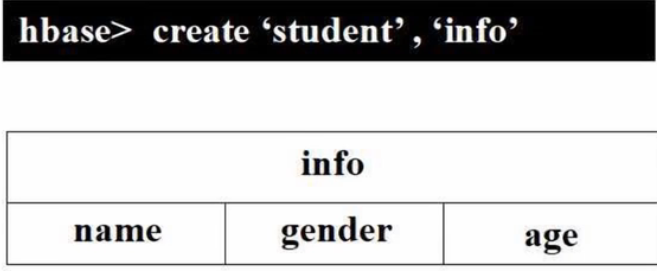
disable 'student'
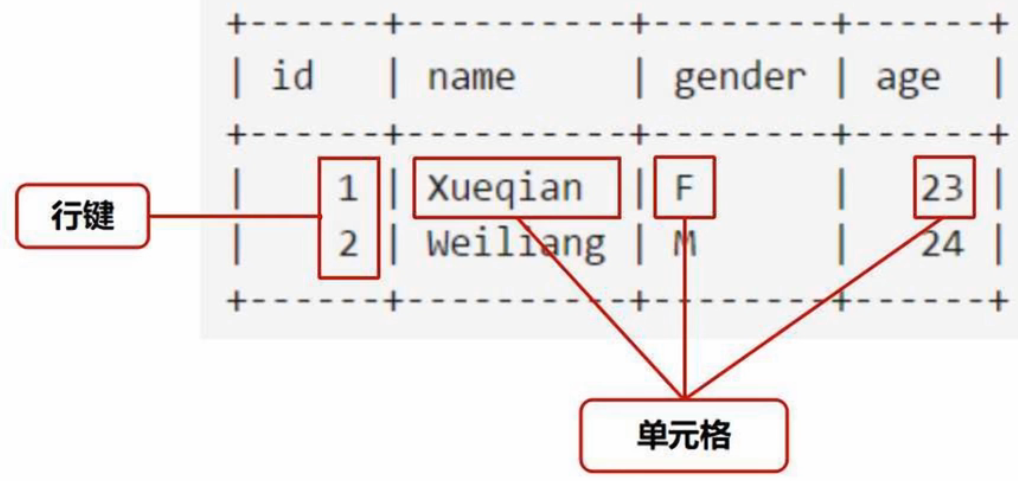
drop 'student'create 'student', 'info' # 表、列族# 录入student表第一个学生记录
put 'student', '1', 'info:name', 'Xueqian'
put 'student', '1', 'info:gender', 'F'
put 'student', '1', 'info:age', '23'# 录入student表第二个学生记录
put 'student', '2', 'info:name', 'Weiliang'
put 'student', '2', 'info:gender', 'M'
put 'student', '2', 'info:age', '24'- 关系型数据库插入数据的方式为 insert into... values...(一次插入一行数据)
(3)配置Spark
把程序运行过程中所需jar包(lib目录下)拷贝到Spark安装目录下(jars目录),需要拷贝:
- 所有以hbase开头的jar包
- guava-12.0.1.jar
- htrace-core-3.1.0-incubating.jar
- protobuf-java-2.5.0.jar
cd /usr/local/spark/jars
mkdir hbase
cd hbase
cp /usr/local/hbase/lib/hbase*.jar ./
cp /usr/local/hbase/lib/guava-12.0.1.jar ./
cp /usr/local/hbase/lib/htrace-core-3.1.0-incubating.jar ./
cp /usr/local/hbase/lib/protobuf-java-2.5.0.jar ./此外,在Spark2.0以上版本中,缺少把HBase数据转换成Python可读取数据的jar包,需要另行下载。可以访问下面地址下载spark-examples_2.11-1.6.0-typesafe-001.jar。下载以后保存到 /usr/local/spark/jars/hbase/ 目录中https://mvnrepository.com/artifact/org.apache.spark/spark-examples_2.11/1.6.0-typesafe-001
使用vim编辑器打开spark-env.sh文件,设置Spark的spark-env.sh文件,告诉Spark可以在哪个路径下找到HBase相关的jar文件,命令如下:
cd /usr/local/spark/conf
vim spark-env.sh打开spark-env.sh文件后,可以在文件最前面增加下面一行内容,这样后面编译和运行过程才不会出错:
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath):$(/usr/local/hbase/bin/hbase classpath):/usr/local/spark/jars/hbase/*(4)编写程序读取HBase数据
Spark读取HBase:用SparkContext提供的 newAPIHadoopRDD API将表的内容以RDD的形式加载到Spark中
SparkOperateHBase.py(从HBase读取数据、生成字符串格式并打印到屏幕上):
#!/usr/bin/env python3from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster('local').setAppName("ReadHBase") # 设置连接方式为本地模式,应用名称为ReadHBase
sc = SparkContext(conf = conf) # 生成SparkContext对象
host = 'localhost' # ZooKeeper服务器地址(分布式协调一致性作用)
table = 'student' # 表名
conf = {"hbase.zookeeper.quorum": host,"hbase.mapreduce.inputtable": table} # 配置ZooKeeper服务器地址、当前读取的输入表
keyConv = "org.apache.spark.examples.pythonconverters.ImmutableBytesWritableToStringConverter" # 键转换器,把key从HBase格式转换成字符串格式
valueConv="org.apache.spark.examples.pythonconverters.HBaseResultToStringConverter"
hbase_rdd=sc.newAPIHadoopRDD("org.apache.hadoop.hbase.mapreduce.TableInputFormat","org.apache.hadoop.hbase.io.ImmutableBytesWritable","org.apache.hadoop.hbase.client.Result",keyConverter=keyConv,valueConverter=valueConv,conf=conf) # 读取表的格式、从HBase读取的key的类型、从HBase读取的value的类型、指定key的转换类、指定value的转换类、配置信息
count=hbase_rdd.count() # 有多少个行键(键值对)
hbase_rdd.cache() # 缓存
output=hbase_rdd.collect() # 封装在一个列表中返回
for (k,v) in output:print(k,v)执行该代码文件:
cd /usr/local/spark/mycode/rdd
/usr/local/spark/bin/spark-submit SparkOperateHBase.py执行结果:

(5)编写程序向HBase写入数据
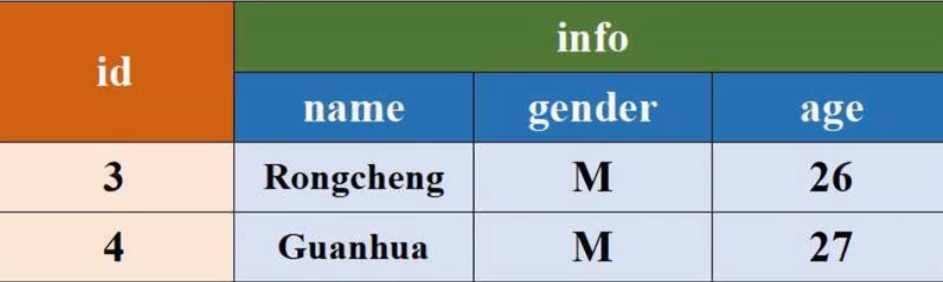
把表中的两个学生信息插入到HBase的student表中:
SparkWriteHBase.py:
#!/usr/bin/env python3from pyspark import SparkConf,SparkContextconf = SparkConf().setMaster('local').setAppName("WriteHBase")
sc = SparkContext(conf = conf)
host = 'localhost'
table = 'student'
keyConv = "org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter" # key转换器,String类型转换成内部格式
valueConv = "org.apache.spark.examples.pythonconverters.StringListToPutConverter" # value转换器,字符串列表转换成Put单元格
conf = {"hbase.zookeeper.quorum": host,"hbase.mapred.outputtable": table,"mapreduce.outputformat.class":"org.apache.hadoop.hbase.mapreduce.TableOutputFormat","mapreduce.job.output.key.class":"org.apache.hadoop.hbase.io.ImmutableBytesWritable","mapreduce.job.output.value.class":"org.apache.hadoop.io.Writable"}rawData=['3,info,name,Rongcheng','3,info,gender,M','3,info,age,26','4,info,name,Guanhua','4,info,gender,M','4,info,age,27']
# 首先将6个字符串加载到内存生成RDD,再写入HBase
sc.parallelize(rawData).map(lambda x: (x[0],x.split(','))).saveAsNewAPIHadoopDataset(conf=conf,keyConverter=keyConv,valueConverter=valueConv) # x[0]为行键,map后6个字符串变为6个键值对(key,value),key为行键,value为字符串列表(即单元格值)- StringList:[行键,列族,列,值]
执行:
cd /usr/local/spark/mycode/rdd
/usr/local/spark/bin/spark-submit SparkWriteHBase.py去HBase Shell查看写入结果:scan 'student' 
(四)综合案例
1、求TOP值
对一个目录下的所有文件的某字段排序,取top5(topN.py)

from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf = conf)
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/file")
# line.strip() 去掉字符串后面的空格(去掉空行)
# split后==4,即去掉缺失字段的行
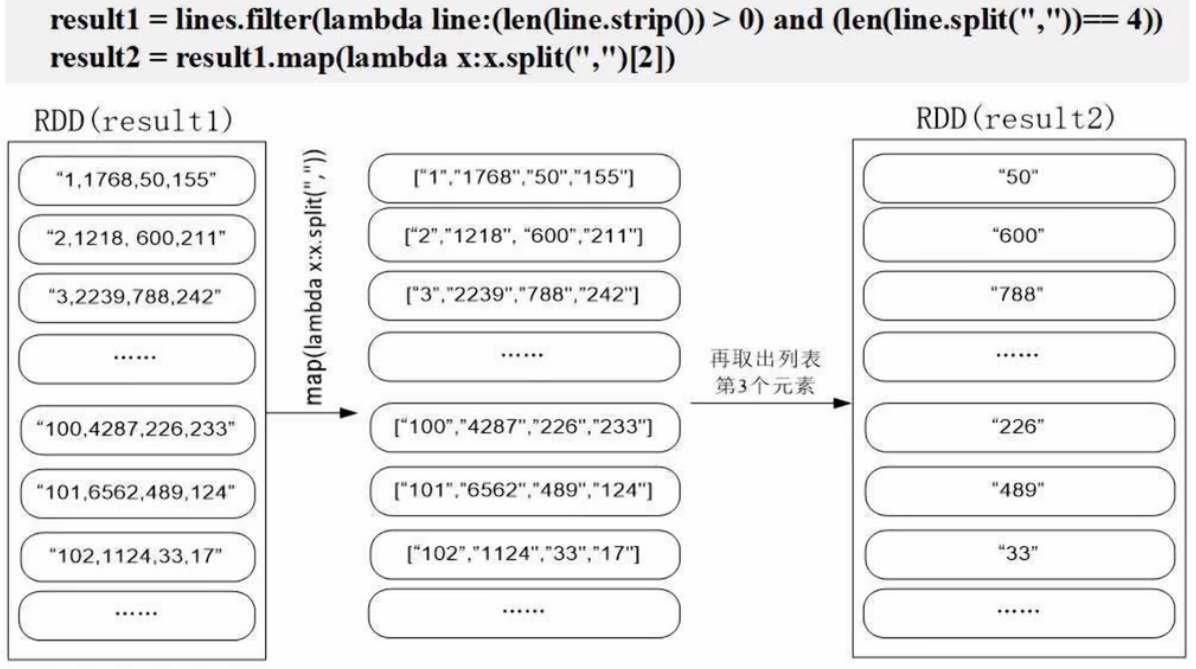
result1 = lines.filter(lambda line:(len(line.strip()) > 0) and (len(line.split(",")) == 4))
result2 = result1.map(lambda x:x.split(",")[2]) # 取出payment
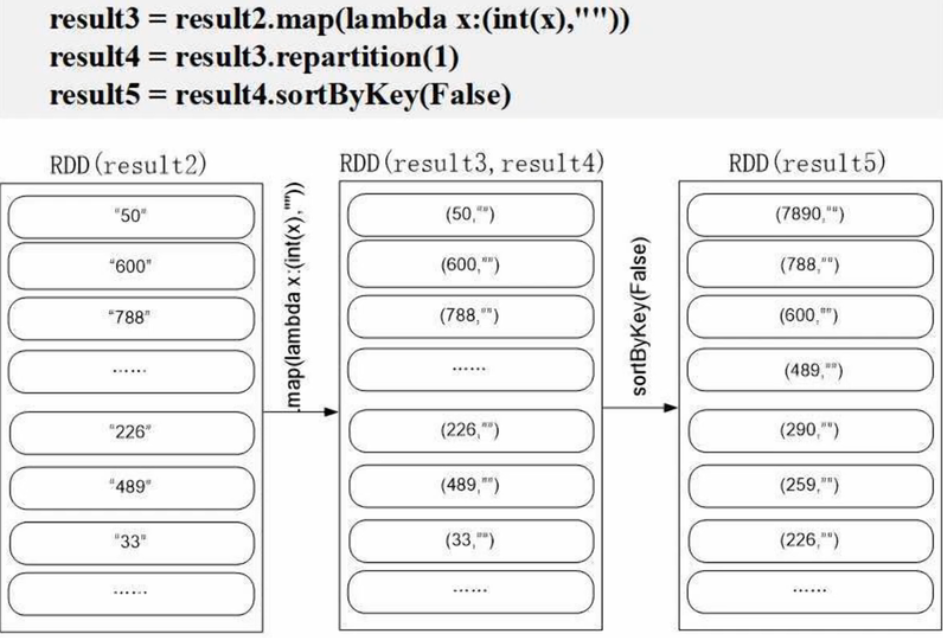
result3 = result2.map(lambda x:(int(x),"")) # 转换为(key, value),为了后面排序
result4 = result3.repartition(1) # 为了保证全局有序,否则可能分区有序,但全局无序
result5 = result4.sortByKey(False) # sortByKey()必须根据key来排,即输入是(key,value)。False为降序
result6 = result5.map(lambda x:x[0]) # 去掉value的""
result7 = result6.take(5) # 取出前五名
for a in result7:print(a)过程解析:


参考:Spark求TOP值_11号的乔乔的博客-CSDN博客
2、文件排序
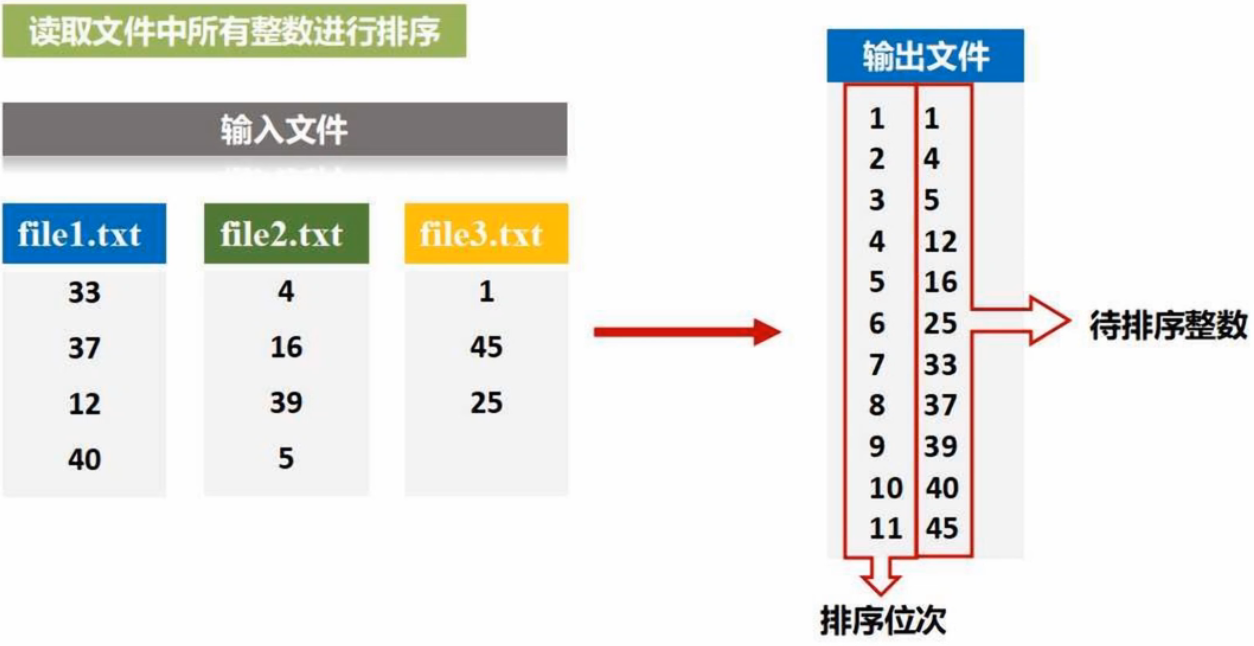
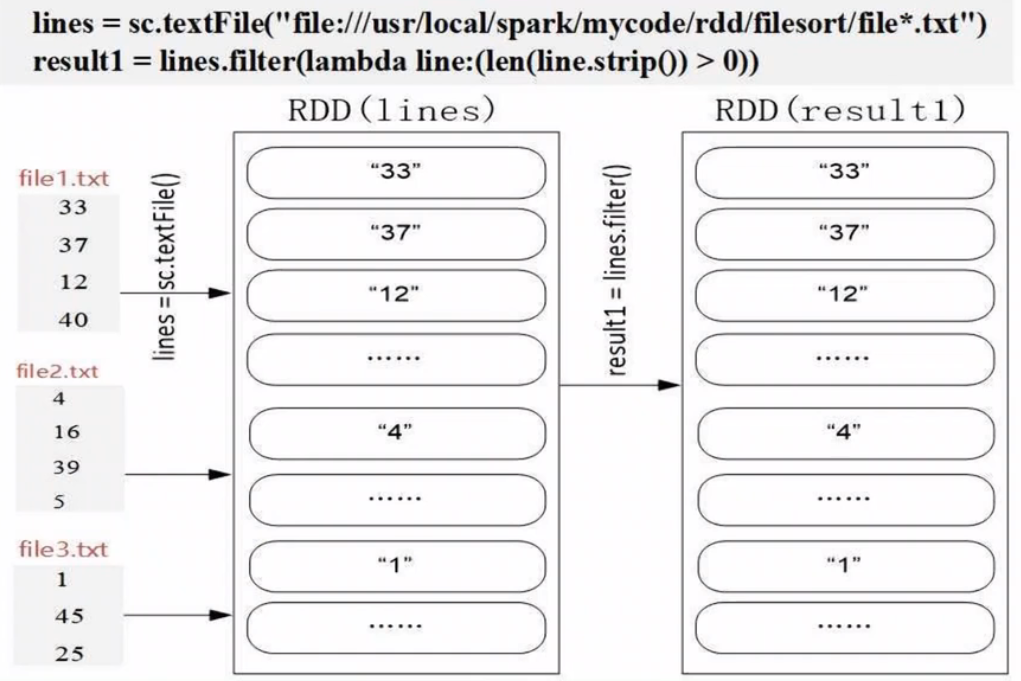
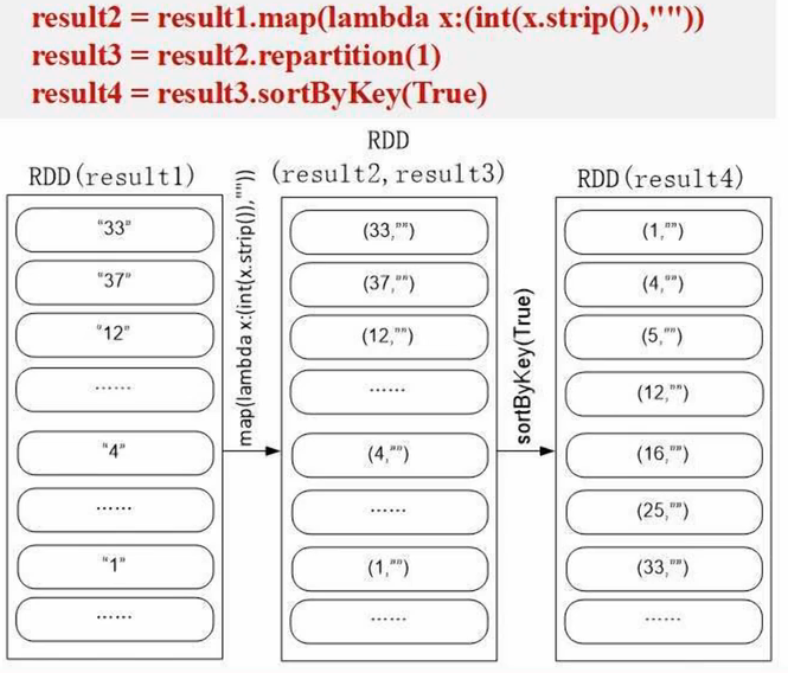
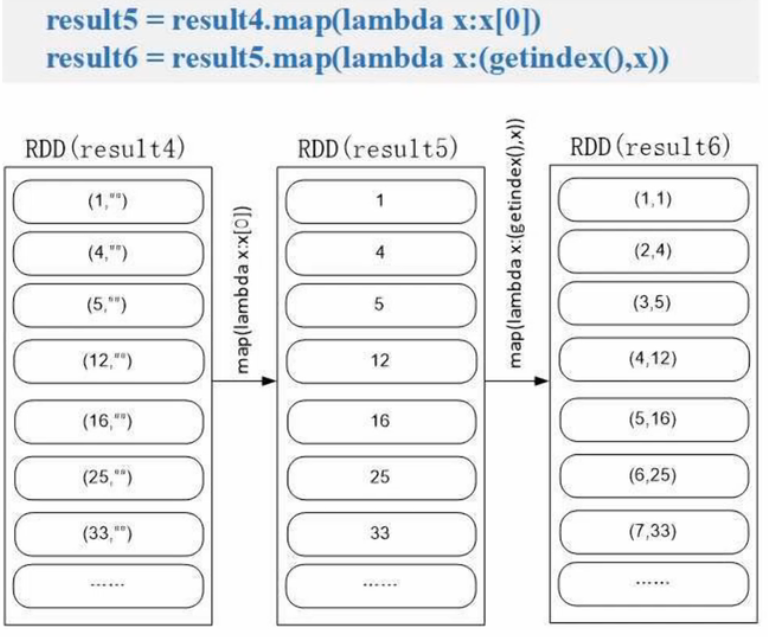
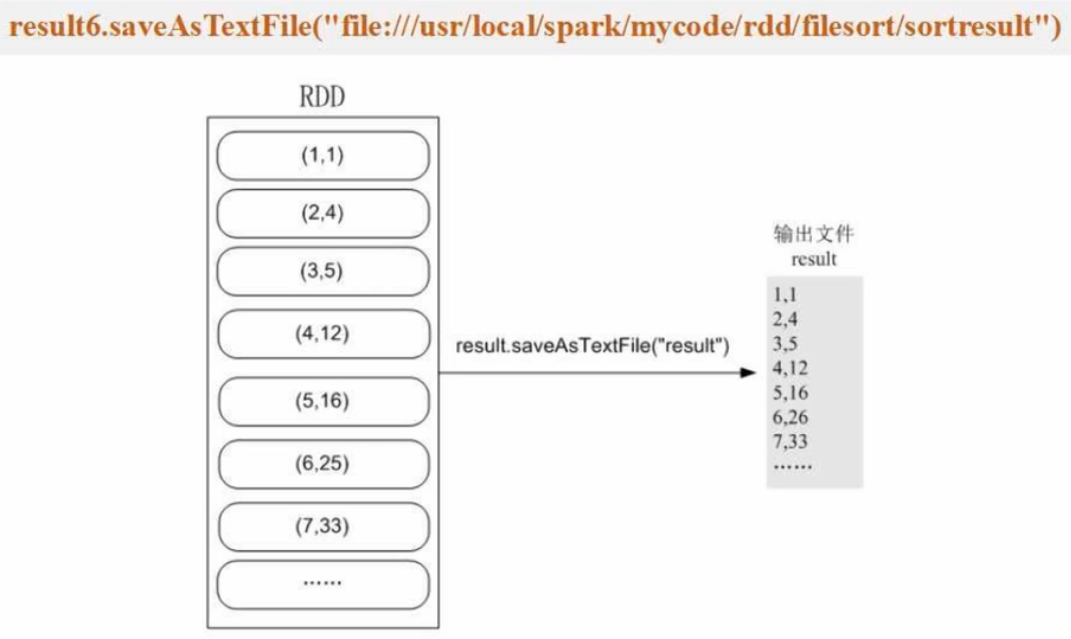
读取文件中所有整数并进行排序(FileSort.py)
#!/usr/bin/env python3
from pyspark import SparkContext, SparkConfindex = 0
def getindex(): # 获取全局排序,依次递增global indexindex += 1return indexdef main():conf = SparkConf().setMaster('local[1]').setAppName('FileSort')sc = SparkContext(conf=conf)lines = sc.textFile("file:///usr/local/spark/mycode/rdd/filesort/file*.txt") # 把某个目录下所有文件加载进来生成RDDresult1 = lines.filter(lambda line:(len(line.strip())>0)) # 消除空行result2 = result1.map(lambda x:(int(x.strip()),"") # 生成(key,value)result3 = result2.repatition(1) # 1个分区确保全局有序result4 = result3.sortByKey(True)result5 = result4.map(lambda x:x[0])result6 result5.map(lambda x:(getindex(),x))result6.saveAsTextFile("file:///usr/local/spark/mycode/rdd/filesort/sortresult")sortByKey() 的输入必须是 (key, value)
过程解析:
3、二次排序
先根据第一列降序排序,第一列值相等再根据第二列降序排序(SecondarySortKey.py)
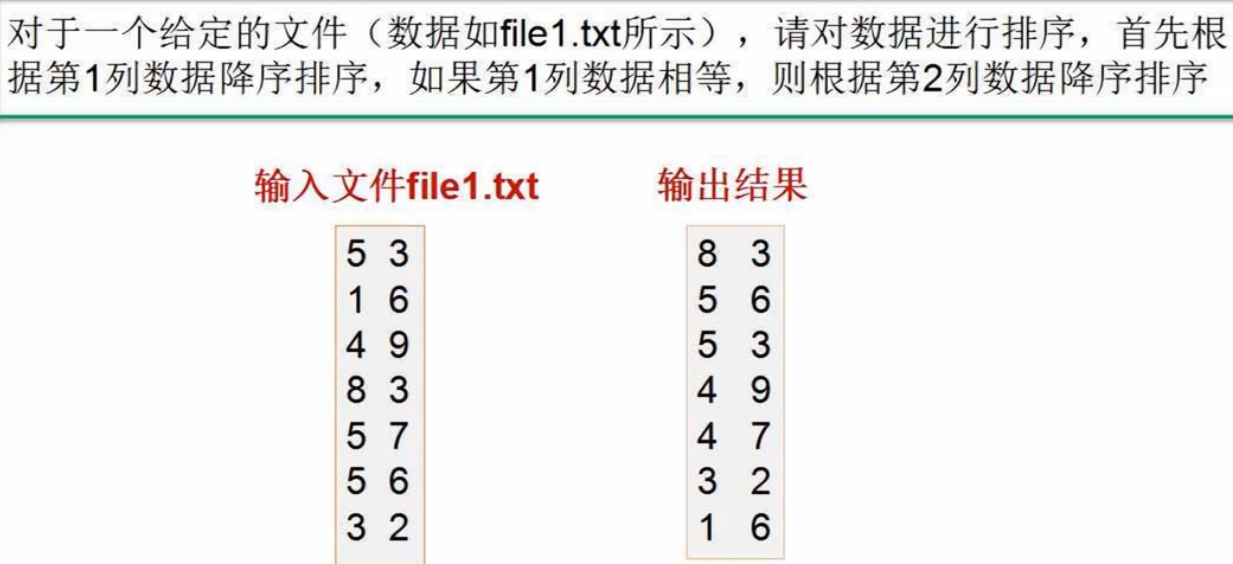
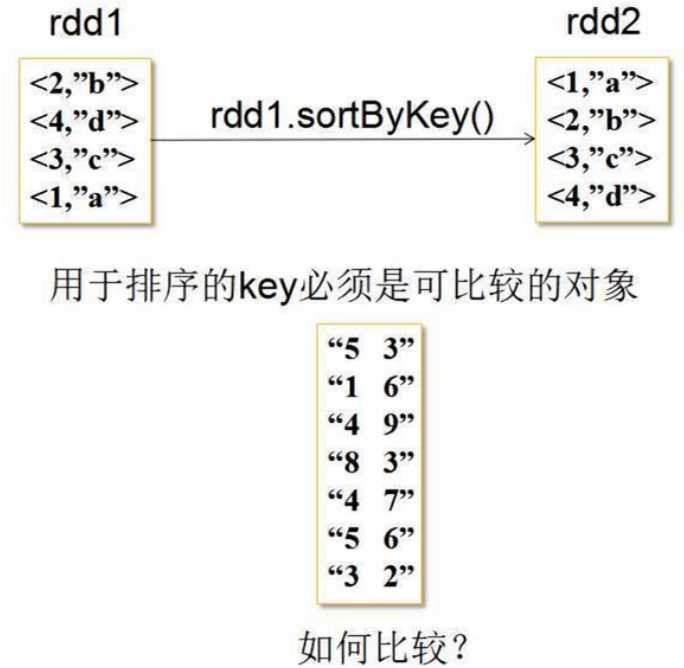
若就把字符串构建(key,value) 输入sortBykey(),是根据字母的升序排序。故本题必须生成一个可比较的key,即下图中的 SecondarySortKey(5,3)
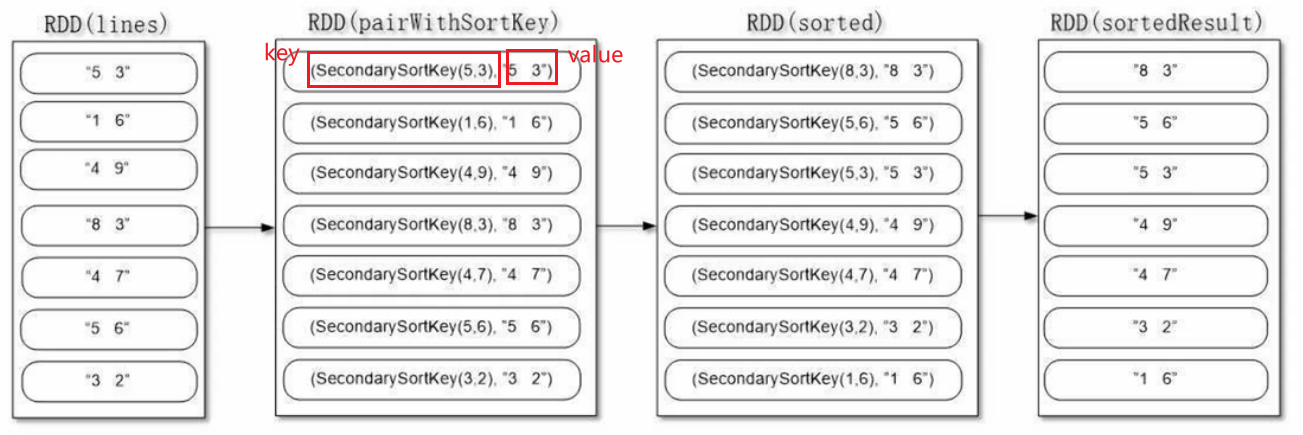
实现思路:
- 按照Ordered 和 Serializable 接口实现自定义排序的key(人工定义类SecondarySortKey)
- 将要进行二次排序的文件加载进来生成 <key, value> 类型的RDD,key即人工定义的用于排序的SecondarySortKey,值即文本中的一行
- 使用sortByKey基于自定义的key进行二次排序
- 去除掉排序的key只保留排序的结果
from operator import gt
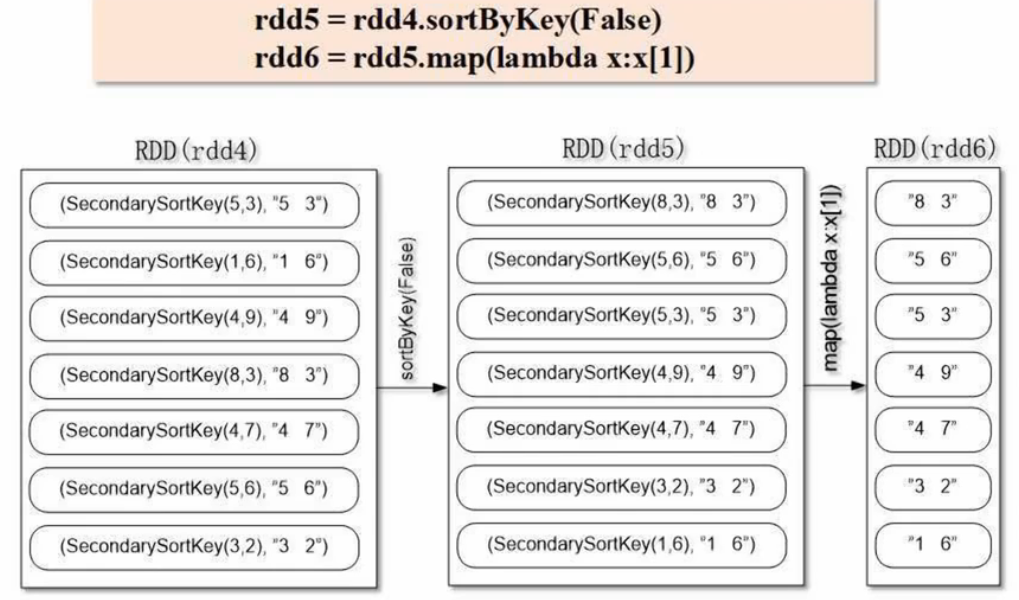
from pyspark import SparkContext, SparkConfclass SecondarySortKey():def __init__(self, k): # __init__为构造函数,k为传入参数,格式为(key,value)self.column1 = k[0]self.column2 = k[1]def __gt__(self, other): # 重写比较函数if other.column1 == self.column1:return gt(self.column2,other.column2) # 若第1列相等,比较第2列else:return gt(self.column1, other.column1)def main():conf = SparkConf().setAppName('spark_sort').setMaster('local[1]')sc = SparkContext(conf=conf)file="file:///usr/local/spark/mycode/rdd/secondarysort/file4.txt"rdd1 = sc.textFile(file)rdd2=rdd1.filter(lambda x:(len(x.strip()) > 0)) # 去除空行rdd3=rdd2.map(lambda x:((int(x.split(" ")[0]),int(x.split(" ")[1])),x)) # x为字符串rdd4=rdd3.map(lambda x: (SecondarySortKey(x[0]),x[1]))rdd5=rdd4.sortByKey(False)rdd6=rdd5.map(lambda x:x[1]) # 去掉左边的可排序key,只保留右边的字符串rdd6.foreach(print)if __name__ == '__main__':main()过程解析:


第5章 Spark SQL(9节)
(一)Spark SQL简介
1、Hive:SQL-on-Hadoop

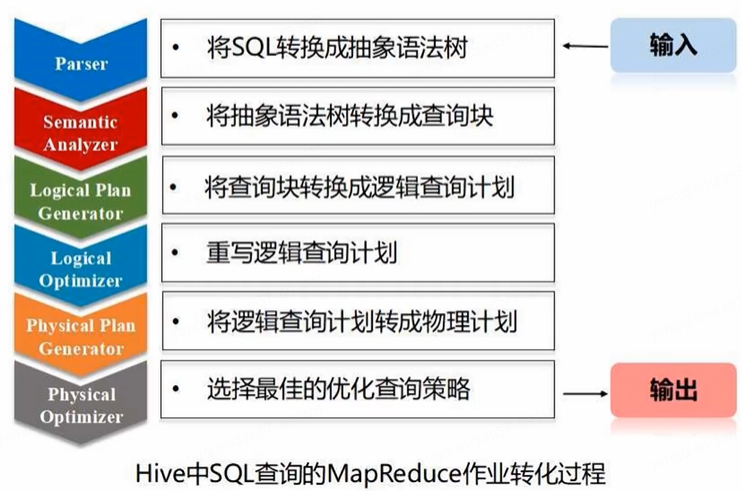
Hive:SQL-on-Hadoop(Hadoop平台上提供了SQL查询的能力,在Hadoop平台上构建数据仓库,把SQL语句转换成底层MapReduce程序,对底层HDFS数据进行查询分析)
- Hive本身不存储数据,借助底层HDFS存储数据
- Hive可以看成是编程接口,把SQL语句转换成MapReduce作业
2、Shark:Hive on Spark
Shark即Hive on Spark。为了实现和Hive兼容,Shark在HiveQL方面重用了Hive中HiveQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MapReduce作业替换成了Spark作业,通过Hive的HiveQL解析,把HiveQL翻译成Spark上的RDD操作
- SQL-on-Spark性能比Hive有了10-100倍的提高
- Shark导致的两个问题:
- 执行计划优化完全依赖Hive,不方便添加新的优化策略
- MapReduce是进程级并行,而Spark是线程级并行,故Spark为了兼容Hive就存在线程安全的问题,导致Shark不得不使用另外一套独立维护的打了补丁的Hive源码分支
3、Spark SQL

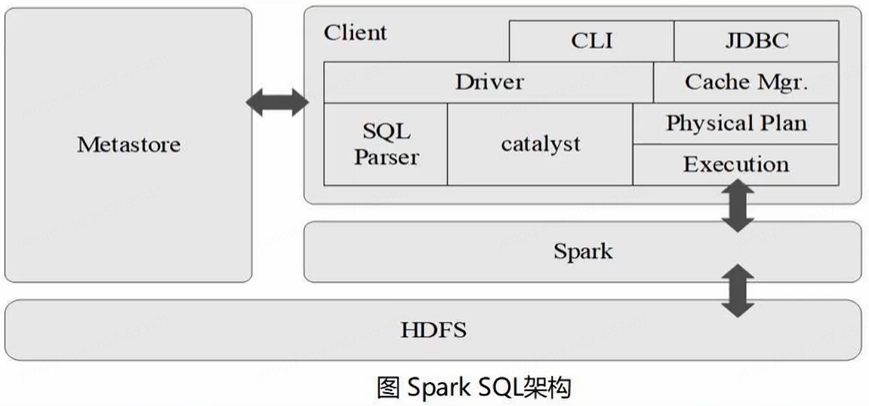
Spark SQL在Hive兼容层面仅依赖HiveQL解析、Hive元数据模块,其他模块全部重新开发。也就是说,从HQL被解析成抽象语法树AST开始,就全部由Spark SQL接管了。Spark SQL执行计划生成和优化都由Catalyst(函数式关系查询优化框架)负责
Spark SQL增加了DataFrame(即带有Schema信息的RDD),使用户可以在Spark SQL中执行SQL语句。数据既可以来自RDD,也可以是Hive、HDFS、Cassandra等外部数据源,还可以是JSON格式的数据
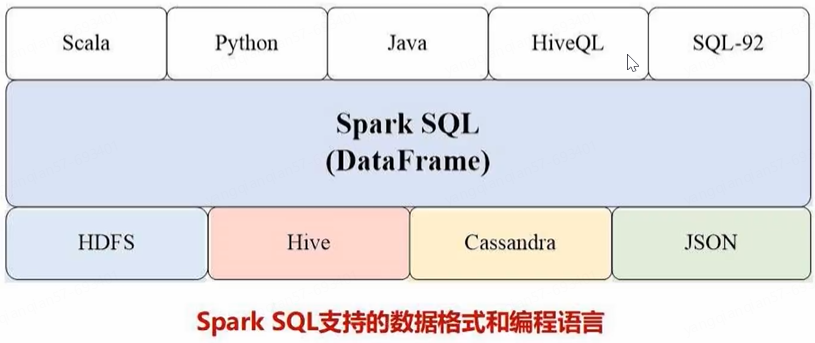
- Spark SQL目前支持三种语言:Java、Scala、Python
Why Spark SQL?
- 关系型数据库已经很流行,但在大数据时代已经不能满足要求
- 首先,用户需要从不同数据源执行各种操作,包括结构化和非结构化数据;
- 其次,用户需要执行高级分析,比如机器学习和图像处理。在实际大数据应用中,经常需要融合关系查询和复杂分析算法(比如机器学习或图像处理),但是,缺少这样的系统
Spark SQL填补了这个鸿沟
- 首先,可以提供DataFrame API,可以对内部和外部各种数据源执行各种关系操作
- 其次,可以支持大量的数据源和数据分析算法,Spark SQL可以融合传统关系数据库的结构化数据管理能力和机器学习算法的数据处理能力
(二)DataFrame概述
DataFrame的推出,让Spark具备了处理大规模结构化数据的能力,不仅比原有的RDD转化方式更加简单易用,而且获得了更高的计算性能。Spark能够轻松实现从Mysql到DataFrame的转化,并且支持SQL查询
RDD是Spark Core核心组件的数据抽象,Spark SQL的数据抽象是DataFrame

- RDD是分布式的Java对象的集合,看不到对象内部结构;
- DataFrame是以RDD为基础的分布式数据集,提供了详细的结构信息
1、创建
从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转换、处理等功能。SparkSession实现了SQLContext及HiveContext所有功能
SparkSession支持从不同的数据源加载数据,并把数据转换成DataFrame,并支持把DataFrame转换成SQLContext自身中的表,然后使用SQL语句来操作数据。SparkSession也提供了HiveQL以及其他依赖于Hive的功能的支持
- SparkSession接口(Spark SQL程序的指挥官)
- SparkContext对象(RDD应用程序的指挥官)
(1)创建SparkSession对象
- 在启动进入Pyspark以后,pyspark就默认提供了一个SparkContext对象(名称为sc)和一个SparkSession对象(名称为spark)
- 在写独立应用程序时,需要用下面代码生成:
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()(2)创建DataFrame
spark.read() 操作或 spark.read.format().load() 操作
spark.read.text("xxx.txt")
spark.read.json("xxx.json")
spark.read.parquet("xxx.parquet")spark.read.format("text").load("xxx.txt")
spark.read.format("json").load("xxx.json")
spark.read.format("parquet").load("xxx.parquet")调用 .show() 可以查看数据
2、保存
使用 spark.write 操作保存DataFrame
df.write.txt("xxx.txt")
df.write.json("xxx.json")
df.write.parquet("xxx.parquet")df.write.format("text").save("xxx.txt")
df.write.format("json").save("xxx.json")
df.write.format("parquet").save("xxx.parquet")
目录名称读取即可加载(注意不是文件名称)
3、常用操作
printSchema():打印模式信息
select():选取列显示

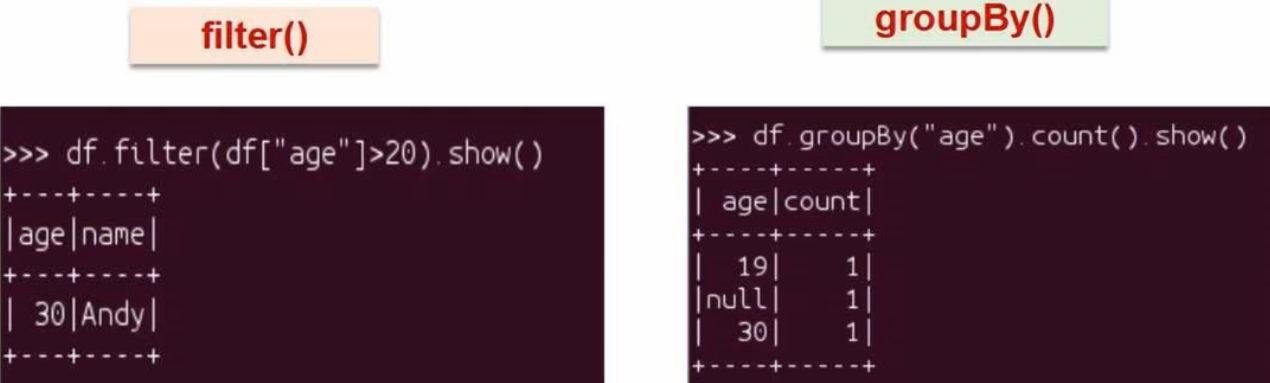
filter():过滤
groupBy():分组
sort():排序

(三)利用反射机制推断RDD模式
1、利用反射机制去推断RDD模式
/usr/local/spark/examples/src/main/resources/ 目录下:
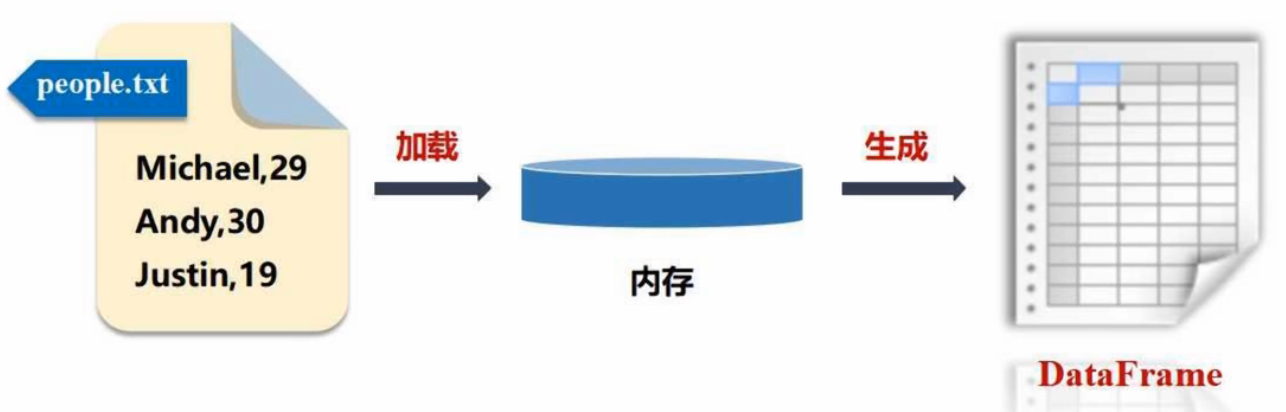
from pyspark.sql import Row # 生成row对象封装一行数据
# spark为SparkSession对象
people = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt").map(lambda line:line.split(",")).map(lambda p:Row(name=p[0],age=int(p[1]))) # people为RDD
schemapeople = spark.createDataFrame(people)# 必须注册为临时表才能供下面的查询使用
schemapeople.createOrReplaceTempView("people") # people为临时表名称
personDF = spark.sql("select name,age from people where age>20")
# 查询得到的结果会被封装在DataFrame中
personDF.show()# DataFrame中的每个元素都是一行记录,包含name和age两个字段,分别用p.name和p.age来获取值
personRDD = personDF.rdd.map(lambda p:"Name:"+p.name+","+"Age:"+str(p.age))
personRDD.foreach(print)

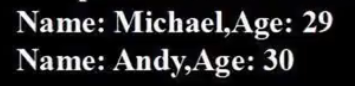
2、用编程方式去定义RDD模式
当无法提前获知数据结构时,采用编程方式定义RDD模式
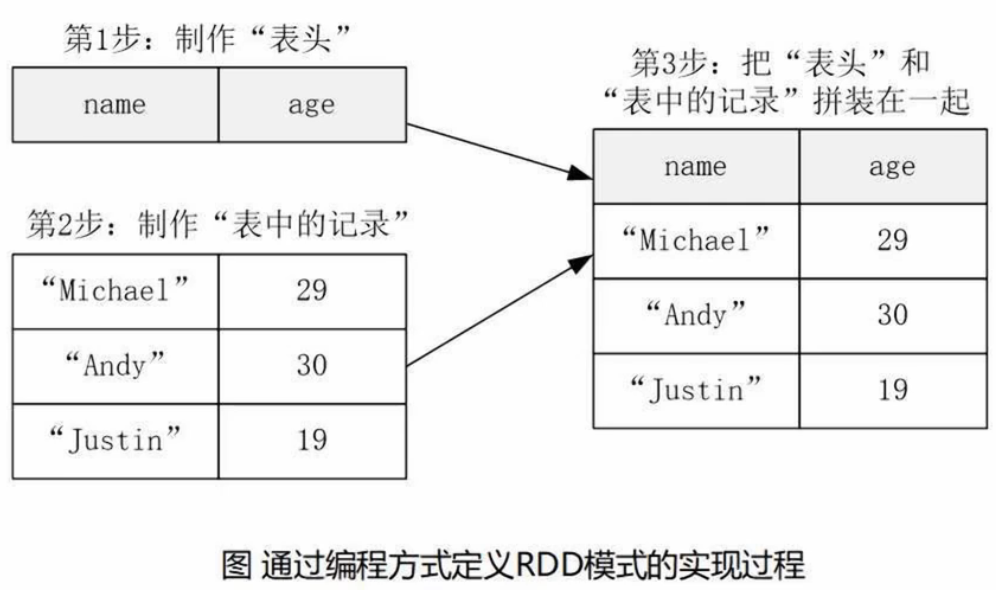
from pyspark.sql.types import *
from pyspark.sql import Row# 生成表头
schemaString = "name age" # 包含两个字段 name 和 age
fields = [StructField(field_name,StringType(),True) for field_name in schemaString.split(" ")] # 列表里每个元素都是一个StructField对象(用来描述字段)
schema = StructType(fields)# 生成表中的记录
lines = spark.sparkContext.textFile("file:///usr/local/spark/examples/src/main/resources/people.txt")
parts = lines.map(lambda x:x.split(","))
people = parts.map(lambda p:Row(p[0],p[1].strip())) # p为列表# 表头和内容拼接
schemapeoples = spark.createDataFrame(people,schema) # (表中记录,表头)# 注册临时表才能查询
schemapeoples.createOrReplaceTempView("people")
results = spark.sql("select name,age from people")
results.show()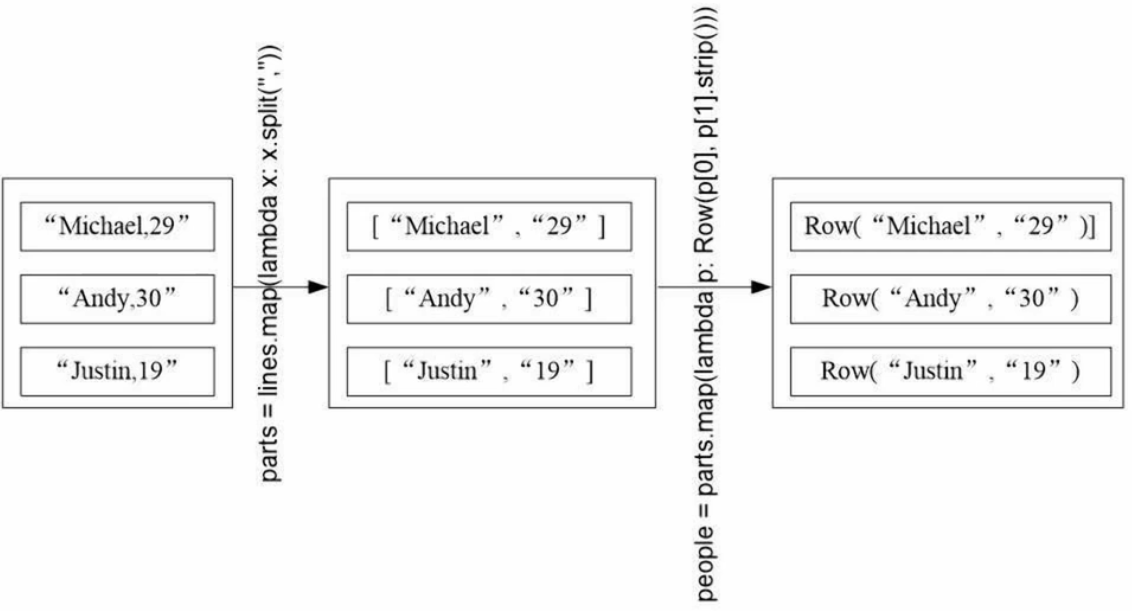
- StructField(字段名称,字段类型,是否可以为空) 用来描述字段
- StructType() 生成的对象用来描述数据库模式,即表头
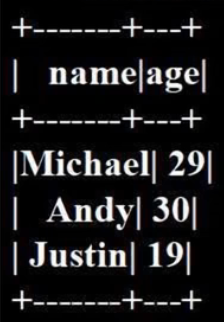
查询的结果被封装在DataFrame里
(四)Spark SQL读取MySQL数据库
1、MySQL准备工作
在Linux系统中安装MySQL数据库:Ubuntu安装MySQL及常用操作_厦大数据库实验室博客
# 在Linux中启动MySQL数据库
service mysql start
mysql -u root -p # 屏幕会提示你输入密码(MySQL root用户密码)# 完成数据库和表的创建
create database spark
use spark
create table student(id int(4), name char(20), gender char(4), age int(4))
insert into student values (1, "Xueqian", 'F', 23)
insert into student values (2, "Weiliang", 'M', 24)
select * from student
Spark SQL通过jdbc连接关系型数据库MySQL,需要安装MySQL的jdbc驱动程序:Linux 下搭建 Hive 环境_mysql-connector-java-5.1.40.tar 对应的mysql版本_GreyZeng的博客-CSDN博客
下载后放入 /usr/local/spark/jars
# 启动pyspark
cd /usr/local/spark
./bin/pyspark2、Spark SQL读写MySQL
(1)通过jdbc连接MySQL数据库
>>>jdbcDF = spark.read.format("jdbc") \
.option("url","jdbc:mysql://localhost:3306/spark") \ # 访问数据库地址及数据库(spark数据库)
.option("driver","com.mysql.jdbc.Driver") \ # 指定驱动程序
.option("dbtable", "student") \ # 访问student表
.option("user", "root") \
.option("password", "mysql密码").load()# .option()增加连接参数
(2)向MySQL数据库中写入数据
use spark
select * from student往 spark.student 中插入两条记录:
from pyspark.sql.types import Row
from pyspark.sql.types import *
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession# 生成SparkSession对象(Spark SQL指挥官)
spark = SparkSession.builder.config(conf=SparkConf()).getOrCreate()# 下面要设置模式信息
>>> schema = StructType([StructField("id", IntegerType(), True), \ # True说明可以为空
StructField("name", StringType(), True), \
StructField("gender", StringType(), True), \
StructField("age",IntegerType(), True)])# 设置两条数据,表示两个学生信息(封装Row对象)
studentRDD = spark.sparkContext.parallelize(["3 Rongcheng M 26","4 Guanhua M 27"]).map(lambda x:x.split(" "))# 创建Row对象,每个Row对象都是rowRDD的一行
rowRDD = studentRDD.map(lambda p:Row(int(p[1].strip()), p[1].strip(), p[2].strip(), int(p[3].strip())))# 建立起Row对象和模式之间的对应关系,也就是把数据和模式对应起来
studentDF = spark.createDataFrame(rowRDD, schema) # 把DataFrame写入数据库
prop = {}
prop['user'] = 'root'
prop['password'] = '填写mysql密码'
prop['driver'] = "com.mysql.jdbc.Driver" # 驱动程序名称
# 库名, 表名, 追加, prop为属性集合
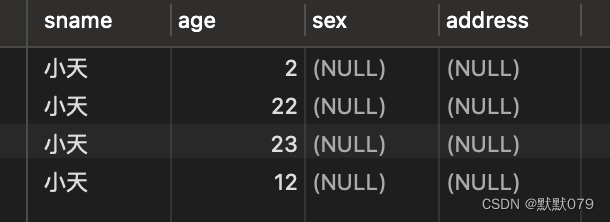
studentDF.write.jdbc("jdbc:mysql://localhost:3306/spark",'student','append', prop)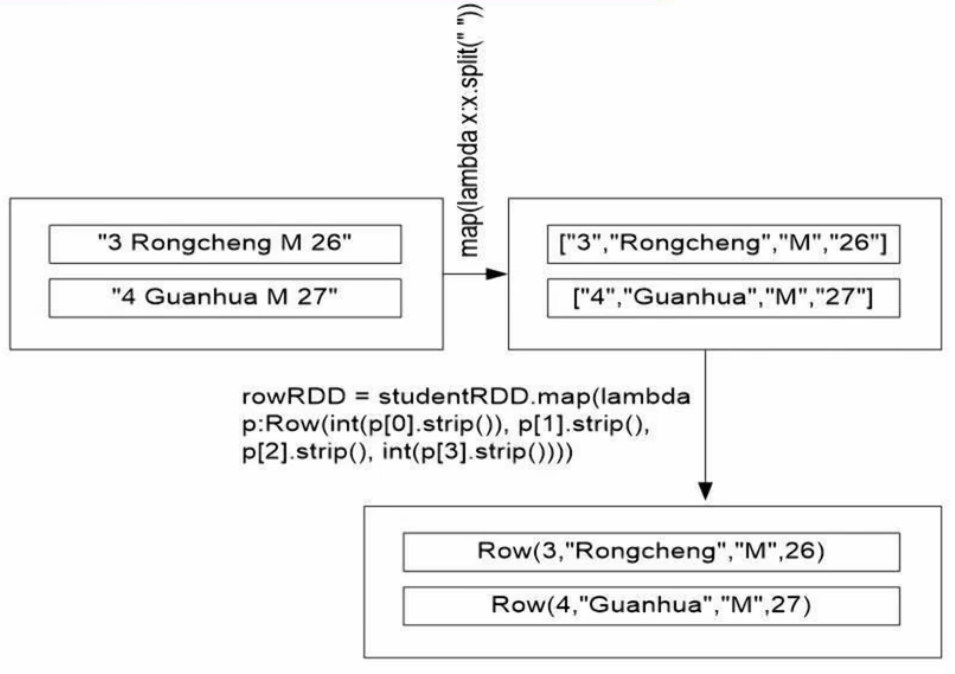
结果如下: