ClickHouse的Join算法
ClickHouse是一款开源的列式分析型数据库(OLAP),专为需要超低延迟分析查询大量数据的场景而生。为了实现分析应用可能达到的最佳性能,分析型数据库(OLAP)通常将表组合在一起形成一个大宽表,这个过程称为数据反规范化(data denormalization)。大宽表通过避免JOIN连接来帮助提升查询效率,代价是增加了ETL(从业务系统OLTP数据库里导出数据到ClickHouse)复杂性。
然而,在某些情况下并不能总是用大宽表来替代JOIN连接,有时分析查询的源数据的一部分需要保持规范化。这些规范化表占用较少的存储并提供数据组合的灵活性,但它们需要在查询时进行某些类型的JOIN连接操作。
虽然是分析型数据库并且倾向于大宽表的方式,但是ClickHouse是完全支持连接运算的。除了支持所有标准的SQL连接类型外,ClickHouse还提供更多的特殊连接类型。这些特殊的连接类型对分析工作负载和时间序列分析非常有用。ClickHouse提供6种不同的JOIN连接算法,并且可以选择让查询计划器根据具体情况选择或者在运行时动态更改JOIN连接算法。
即使在ClickHouse中对超大的数据表做JOIN连接运算,我们也可以通过精心选择连接算法和调优相关设置,从而得到非常良好的性能。虽然可以让ClickHouse更加聪明地帮用户做选择,但是目前效果毕竟有限,而且真正高级的性能调优是离不开人的,因为人能掌握更全面的情况,以及实际业务特点和需求。本文可以帮助你理解ClickHouse内部连接的工作方式,从而帮助你做相关的优化。
ClickHouse目前(2023年3月的版本)有6种JOIN连接算法:
- Hash Join
- Parallel Hash Join
- Grace Hash Join
- Full Sorting Merge Join
- Partial Merge Join
- Direct Join
以及CH支持的连接操作的种类有以下几种。除了Hash Join之外,其他JOIN连接算法只支持部分种类,因此如果需要某种JOIN连接运算时,只能在支持它的JOIN算法中选择。
- INNER JOIN
- OUTER JOIN
- CROSS JOIN
- SEMI JOIN
- ANTI JOIN
- ANY JOIN
- ASOF JOIN
不同的JOIN算法的特点
不同的JOIN的算法有不一样的时间和空间的执行代价,基本上是要么”时间换空间“,要么”空间换时间“,不会满足“既要-又要-还要”的。并且在不同特性的数据集(例如是否已按照JOIN关键字排过序)上各个JOIN算法的表现(时间和空间执行代价)也不一样。因此根据自身数据的特点、业务需求的特点以及计算和存储资源等限制,选择合适的JOIN算法变得非常有意义。

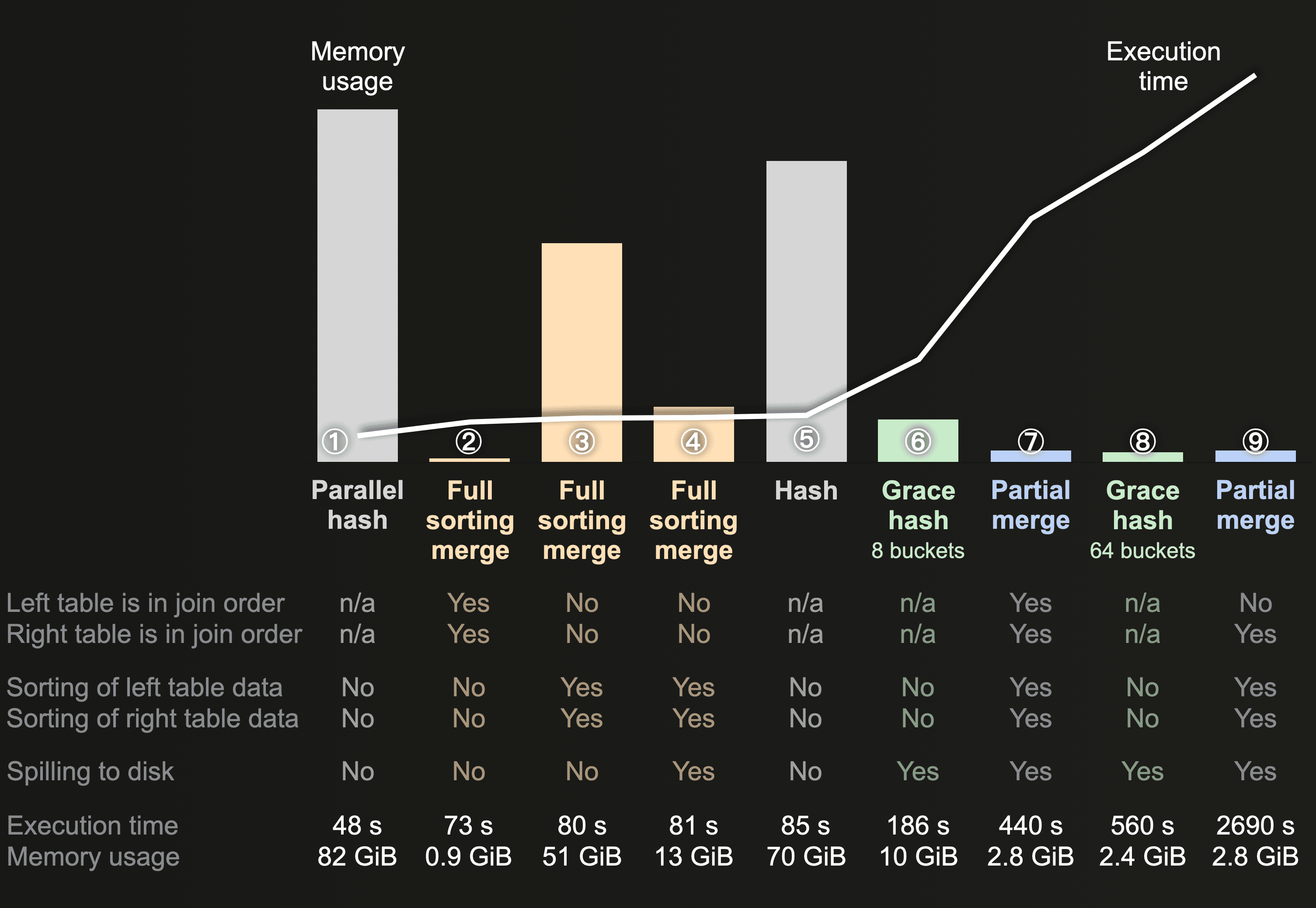
根据上图,我们可以知道:(以上图表并不一定精确,受实际环境影响,但是上图勾勒出了大概的样子)
- 最快的JOIN算法是DIRECT,但是要求条件是右表是已经构建好的Hash Map,或者严谨点来说是”可以快速读取的Key-Value容器“,目前支持这样的表引擎只有Dictionary和Join(对,有个表引擎叫Join Table Engine);
- 除了DIRECT可能最快的JOIN算法是Parallel hash(实际上也不绝对,具体得看硬件配置),但也是最耗费内存的;
- 最省内存的JOIN算法是Partial merge,但同时也是最慢的;
- Grace hash的表现受buckets数量的配置影响,buckets数量增大后在节省内存方面媲美Partial merge,但是也牺牲了时间;
- Full sorting merge的表现受JOIN运算的表是否按照JOIN关键字排序的影响(或者近似排序,后面会解释,只要相同JOIN关键字的行能聚在一起就行了)。在表是预先排序的情况下可以做到”既要-又要“的,这点是值得关注的。
Hash Join
Hash join算法是通过哈希表查表的连接运算算法。

工作原理:
- 右侧表中的所有数据都被读取(通过 2 个线程并行,因为 max_threads = 2)并填充到内存中的哈希表中,哈希表的Key为Join Key,Value为需要用到的右侧表的列;
- 来自左侧表的数据被分数据块流式读取(由 2 个线程并行传输,因为 max_threads = 2,以下不再赘述);
- 通过查找哈希表来连接。
特点:
- 支持所有的连接类型,对表引擎不限制;
- 速度较快;
- 内存消耗与右侧表的数据大小成正比;
- 哈希表的构建和填充的最后一个合并步骤是单线程的,是可能的瓶颈。
Parallel Hash
Parallel hash join算法是在Hash join算法基础上引入了“分桶-多哈希表”的方式增加并行度而形成的连接算法。

工作原理:
- 右侧表中的所有数据都被读取(通过 2 个线程并行,因为 max_threads = 2)并填充到内存中的“分桶的”多个哈希表(按照“分桶”策略,根据桶哈希函数选择某个哈希表),每个哈希表的Key为Join Key,Value为需要用到的右侧表的列;
- 来自左侧表的数据被分数据块流式读取;
- 根据相同“桶哈希函数”为左侧表的每行确定相应的哈希表,通过查找哈希表来连接。
跟Hash join的主要区别是“分桶”,这样解决了Hash join的“哈希表的构建和填充的最后一个合并步骤是单线程的”的瓶颈问题,Parallel hash join是多线程填充每个分桶的哈希表。
特点:
- 支持INNER and LEFT JOIN,不支持ASOF,对表引擎不限制;
- 速度很快;
- 内存消耗与右侧表的数据大小成正比,比Hash join更消耗内存;
- 分桶数决定性能,通常分桶数越多(但不要超过CPU核数)性能越好,但内存消耗更多;
- 内存可能是瓶颈。
Grace Hash
Grace hash join算法是在Hash join算法中加上“分而治之”的策略。

工作原理:
- 右侧表中的所有数据都被读取(通过 2 个线程并行,因为 max_threads = 2)并按照分区哈希函数进行分桶,把属于第一个桶的数据填充到内存中的哈希表中,其他桶的数据临时存放在外存中,按桶区分(注意不是内存);
- 来自左侧表的数据被分数据块流式读取,同样分桶;
- 对于属于第一个桶的数据,通过查找当前内存中的第一个桶的哈希表(内存中也只有第一个桶的哈希表)来进行连接运算,完成后销毁哈希表;
- 对于其他桶的数据,按桶区分也临时存放在外存中;
- 第3和4步完成后,得到第一个桶的数据的连接结果已经分桶临时存放的左右两侧表的数据块;
- 对于桶编号 i(2 <= i <= n,n为桶最大编号),把右侧表桶i的数据填充到哈希表中;
- 读取左表桶i的数据,通过查找当前内存中哈希表来进行连接运算,完成后销毁哈希表;
- 依次完成桶2到桶n。
特点:
- 支持INNER and LEFT JOIN,不支持ASOF,对表引擎不限制;
- 涉及到分桶且存取外存,速度慢;
- 连接用的哈希表总是局部数据,节约内存;
- 内存消耗与左右侧表的数据大小没关系,理论上可以支持无限大小的左右表(只要外存够用);
- 桶数越多,哈希表的数据越少,内存越省,但外存存取次数更多,速度更慢;
- 外存存取是瓶颈。
Full Sorting Merge Join
首先需要知道Full sorting merge join与Partial merge join的思路与Hash类JOIN算法是不同的,属于另一类JOIN算法。

Full sorting merge join算法利用了两个有序表之间可以直接匹配的特性(想象一下拉链),不需要构建哈希表。算法描述如下:
假设左侧表和右侧表均按照Join Key升序排序,设定两个游标L和R,L指向左侧表的第一行,R指向右侧表第一行。L指向行的Join Key与R指向的行的Join Key的比较关系只会有三种:
等于
匹配上了,得到两行连接结果。
大于
右表游标R向下移动一行,因为右表能匹配上的行只会在后面。
小于
左表游标L向下移动一行,因为左表能匹配上的行只会在后面。
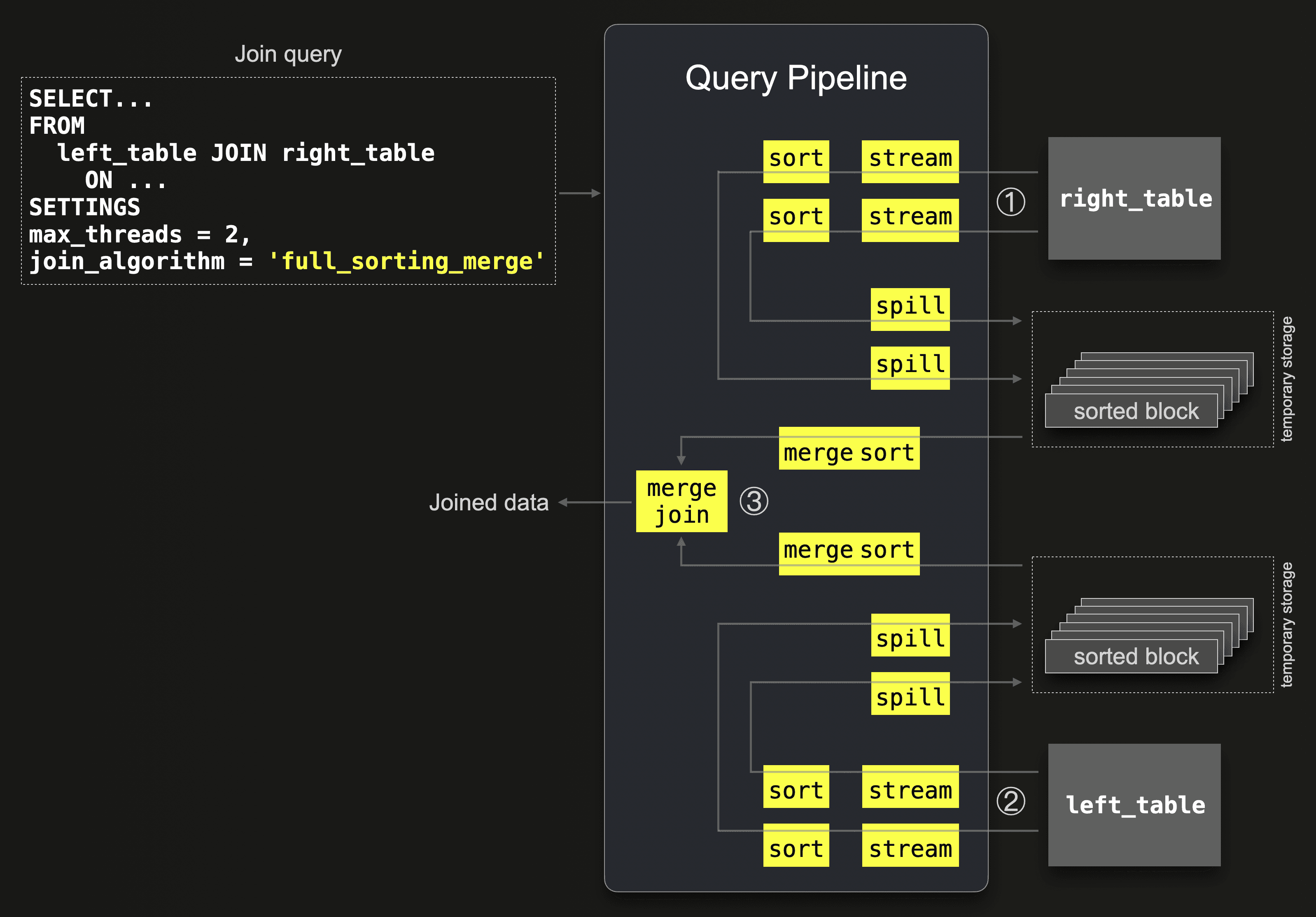
工作原理:
- 左侧表和右侧表分别合并排序,并在可能的情况下借助外存(参见借助外存的合并排序);
- 按照上述的算法进行连接运算。
可能的优化办法有两个:
- 减少参与排序和合并理解的数据量;
- 事先将表按照Join Key排序(或者反过来说,只在这个情况下选择此算法)。
第一个优化办法是假设左右两侧表中的很多数据并不在连接结果里(即有很多根本不会匹配上的行)。这个方法会试图建立左右两侧表的Join Key集合,通过过滤掉左右侧表的“不可能连接”的数据行来减少排序和合并连接的数据量。Join Key集合不可能无限大,由max_rows_in_set_to_optimize_join设置控制,超过限制则取消优化。
第二个优化办法就是直接跳过最耗时的排序步骤,直接合并连接。
特点:
- 支持INNER, LEFT, RIGHT, and FULL连接类型,对表引擎不限制;
- 在左右两侧表事先按照Join Key排序(或者Join Key是排序键列表的前部分)存储的情况下速度较快且内存省;
- 内存消耗与左右侧表的数据大小没关系,理论上可以支持无限大小的左右表(只要外存够用);
- 左右侧表排序是瓶颈,特别是数据量大需要借用外存进行排序的情况。
关于Join Key是排序键列表的前部分的解释:
假设表T的排序键是A、B、C,Join Key A、B就是属于这种情况。
Partial Merge Join
Partial merge join算法与Full sorting merge join算法类似,不同的是它不会全局排序左表,只会排序右表并按数据块存储在外存中,并建立min-max索引(该索引记录了每个数据块的最小Join Key和最大Join Key)。扫描左表执行JOIN连接运算。

工作原理:
- 用外部排序算法排序右侧表,存入外存并建立min-max索引;
- 分数据块流式读取左侧表的数据,对数据块局部排序,根据min-max索引定位到右侧表可能的数据块范围;
- 按照merge-join算法(与full sorting merge join一样的)完成左侧表该数据块的连接JOIN运算;
- 重复2,3步,完成左侧表所有的数据的JOIN运算。

缓存在外存中的排好序的右侧表的数据块不应该全部参与某个左侧表数据块的连接运算,而是应该尽量利用Min-max索引过滤掉哪些不需要参与连接运算的右侧表的数据块。如果左表的物理行顺序与连接键排序顺序匹配,则左表中某个数据块的Join Key的最大值和最小值变得很窄,可以过滤掉大部分的右侧表的数据块。但是如果左侧表的数据在Join Key上分布很平均,意味着每个左侧表的数据块的Join Key的最大值和最小值都差不多,这种情况下是过滤不了多少右侧表的数据块的,效率就变得非常低。
特点:
- 支持INNER, LEFT, RIGHT, and FULL连接类型,对表引擎不限制;
- 在左右两侧表事先按照Join Key排序(或者Join Key是排序键列表的前部分)存储的情况下速度较快且内存省;
- 内存消耗与左右侧表的数据大小没关系,理论上可以支持无限大小的左右表(只要外存够用);
- 通常内存效率非常高,但是执行速度相应地比Full sorting merge join要低;
- 当左侧表是排序的时候,右侧表的min-max索引能够发挥最大作用,反之左侧表越无序,右侧表的min-max索引的作用就越小;
- 右侧表排序是瓶颈,左侧表在Join Key上无序情况下是Merge join的操作是瓶颈。
Direct Join
Direct join连接算法是高速版的Hash join连接算法,高速的原因是省去了构建哈希表的这个费时过程。

工作原理:
- 右侧表是Key-value结构的表引擎,其数据驻留内存可以直接当哈希表使用;
- 来自左侧表的数据被分数据块流式读取,通过查找右侧表来完成连接运算。
特点:
- 仅支持LEFT ANY连接,右表引擎必须为Dictionary或者Join,且Join Key必须是右侧表的Key;
- 速度很快;
- 无额外内存消耗(但右侧表数据本来就在内存中);
- 几乎无瓶颈。
JOIN算法的选择
首先确定哪些JOIN算法支持所需要执行的连接的场景,然后根据性能图谱按照速度优先或者内存优先来选择合适的JOIN算法。
过滤不支持的JOIN算法
根据应用场景过滤掉不支持的连接类型。如下表所示,Hash join支持的最全,也是最早投入使用的Join算法之一。Direct join支持的最少且对右侧表的表引擎有额外限制。另外一个支持比较多的且性能比较好的是Full sorting merge join。

性能图谱
下图展示了所有JOIN算法的时间和空间性能的特点。Direct是最快的,但通用性不强;Parallel在速度上仅次于Direct join,但是内存使用是最高的;Full sorting merge join根据表的排序情况在性能上有很大差别;Grace hash join的性能受buckets数量影响很大;最省内存也是通常最慢的,这就是Partial merge join。

性能评测参考结果
下面是一些用IMDB数据为测试数据的各种JOIN连接算法的性能评测。
1百万 连接 1亿

1亿 连接 10亿
根据以上性能图谱和实际评测结果,形成以下JOIN算法选择策略。
以性能为优先选择
按照从上到下的优先级顺序以此判断:
- 以下条件满足时,选择Direct join
- 右侧表的表引擎为Dictionary或者Join的时候,且Join Key是或者可以转化为是右侧表的Key属性(Dictionary和Join表引擎都会定义Key属性)
- 连接类型为LEFT ANY JOIN
- 以下条件满足时,选择Full sorting merge join(需要把max_rows_in_set_to_optimize_join设置为0以启用相应优化)
- 左侧表的物理顺序匹配连接运算的Join Key
- 右侧表的物理顺序匹配连接运算的Join Key
- 以下条件满足时,选择Hash join或者Parallel hash join
- 右侧表数据可以全部填充进内存中的哈希表中
- 如果内存足够且希望充分利用多核,选择Parallel hash join
- 其他情况下,选择Grace hash join、Full sorting merge join或者Partial merge join,并可以做以下微调:
- Grace hash可以根据调整bucket数量在 (速度慢,内存少)到(速度快,内存多)之间找一个平衡点
- 如果左表的Join Key分布平均,则避免使用Partial merge join
- 调整max_rows_in_set_to_optimize_join设置以达到Full sorting merge join的in-set 过滤优化的最佳效果
以内存为优先选择
按照从上到下的优先级顺序以此判断:
- 以下条件满足时,选择Full sorting merge join
- 左侧表的物理顺序匹配连接运算的Join Key
- 右侧表的物理顺序匹配连接运算的Join Key
- 内存哈希表无法装下右侧表数据的情况下,选择 Grace hash join或者Partial merge join
- Hash join
- Parallel hash join