可以分为三部分学习树模型:
- 基本树(包括 ID3、C4.5、CART).
- Random Forest、Adaboost、GBDT
- Xgboost 和 LightGBM。
基本树
选择特征的准则
ID3:信息增益max
C4.5:信息增益比max
CART:基尼指数min
优缺点
ID3
核心思想是奥卡姆剃刀(决策树小优于大)
缺点:
- ID3 没有剪枝策略,容易过拟合;
- 信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1;
- 只能用于处理离散分布的特征;
- 没有考虑缺失值。
C4.5
有剪枝策略。最大的特点是克服了 ID3 对特征数目的偏重这一缺点,引入信息增益率来作为分类标准。
缺点:
- C4.5 只能用于分类;
- C4.5 使用的熵模型拥有大量耗时的对数运算,连续值还有排序运算;
- C4.5 在构造树的过程中,对数值属性值需要按照其大小进行排序,从中选择一个分割点,所以只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时,程序无法运行。
CART
ID3 和 C4.5 虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但是其生成的决策树分支、规模都比较大,CART 算法的二分法可以简化决策树的规模,提高生成决策树的效率。
集成学习/决策树
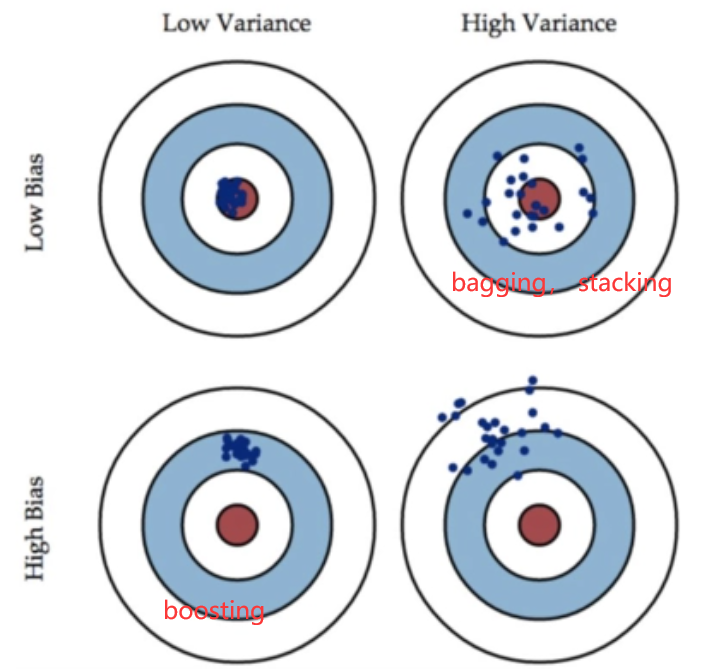
常见的集成学习框架有三种:Bagging,Boosting 和 Stacking
Bagging
投票法
随机森林random forest
RF 算法由很多决策树组成,每一棵决策树之间没有关联。建立完森林后,当有新样本进入时,每棵决策树都会分别进行判断,然后基于投票法给出分类结果。
在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机特征选择,算法包括四个部分:
- 随机选择样本(放回抽样);
- 随机选择特征;
- 构建决策树;
- 随机森林投票(平均)。
优点
- 在数据集上表现良好,相对于其他算法有较大的优势
- 易于并行化,在大数据集上有很大的优势;
- 能够处理高维度数据,不用做特征选择。
Boosting
每个基模型都会在前一个基模型学习的基础上进行学习,最终综合所有基模型的预测值产生最终的预测结果
AdaBoost(Adaptive Boosting,自适应增强)
核心思想是:利用错分样本来弥补模型的不足
可以加入正则化项
自适应在于:
- 前一个基本分类器分错的样本会得到加强,加权后的全体样本再次被用来训练下一个基本分类器。
- 在每一轮中加入一个新的弱分类器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数
算法有三步:
- 初始化训练样本的权值分布,每个样本具有相同权重;
- 训练弱分类器,如果样本分类正确,则在构造下一个训练集中,它的权值就会被降低;反之提高。用更新过的样本集去训练下一个分类器;
- 将所有弱分类组合成强分类器,各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,降低分类误差率大的弱分类器的权重。
| 优 |
|
| 缺 | 对异常点敏感,异常点会获得较高权重 |
GBDT(Gradient Boosting Decision Tree)
核心思想是:通过算梯度来弥补模型的不足(利用残差)
GBDT 由三个概念组成:Regression Decision Tree(即 DT)、Gradient Boosting(即 GB),和 Shrinkage(一个重要演变)
- 回归树:对于分类树而言,其值加减无意义(如性别),而对于回归树而言,其值加减才是有意义的(如说年龄)。GBDT 的核心在于累加所有树的结果作为最终结果,所以 GBDT 中的树都是回归树,不是分类树
- 梯度迭代(Gradient Boosting):
- Shrinkage 的思想认为,每走一小步逐渐逼近结果的效果要比每次迈一大步很快逼近结果的方式更容易避免过拟合。即它并不是完全信任每一棵残差树
| 优 |
|
| 缺 | 对异常点敏感 |
XGBoost(Extreme Gradient Boosting)
核心思想是:在GBDT的基础上,通过正则化以及更高阶的优化方法来防止过拟合;
同时通过特殊的数据存储和并行计算来提高计算效率;并且可以自动处理缺失值
GBDT在优化过程中只使用了损失函数的一阶导数信息,而XGBoost使用了损失函数的一阶和二阶导数。这使得XGBoost在优化过程中考虑了目标函数的曲率,可以更准确快速地找到最优解。
缺点:1、空间消耗大。要保存数据的特征值和特征排序的结果。2、时间开销大,遍历分割点的时候需要进行分裂增益的计算,消耗的代价大。3、对cache优化不友好。在预排序后,特征对梯度的访问是一种随机访问,并且不同的特征访问的顺序不一样,无法对cache进行优化
XGBoost、LightGBM-深度简化版 - 知乎 (zhihu.com)
LightGBM(Light Gradient Boosting Machine)
是对传统GBDT和XGBoost的优化和改进
| 优 |
|
| 缺 |
|
Stacking
- 先用全部数据训练好基模型
- 每个基模型都对每个训练样本进行的预测,其预测值将作为训练样本的特征值,最终会得到新的训练样本
- 基于新的训练样本进行训练得到模型,然后得到最终预测结果。
总结
偏差(Bias)描述的是预测值和真实值之差;方差(Variance)描述的是预测值作为随机变量的离散程度。