对于任何一个互联网公司来说,必定涉及到存储系统,而一般主流的使用MySQL进行存储数据,但是如果只是部署一台数据库,数据丢失的话,其实没有办法进行有效的恢复,那么就会造成一定的损失。要么就是直接的损失,比如针对对账、支付系统,一旦数据金额不对,那么影响非常大。另一种是由于数据系统出现故障,导致业务受到影响。
在分布式系统中,为了实现数据的高可用,一般的方式就是采用数据复制、分片。说白了就是将一份数据同时存储多份,副本可以提供读写功能,或者只提供备份功能。
数据备份和恢复
全量备份
全量备份其实就是将从数据开始存储到现在时间点 全部数据进行备份。然后出现数据问题的时候,在执行全量备份的SQL文件。
mysql提供的 mysqldump 就是执行全量备份的。
我使用的是8.0 一直执行报错。
mysqldump -uroot -prootroot --all-databases > /tmp/all.sql
全量备份虽然可以保存某一时刻之前的所有数据,但是由于保存的是全部的数据,所以进行恢复的时候,对于数据库服务器的CPU、IO都会占用比较高。并且之后新增加的数据无法进行恢复。所以需要增量备份。
增量备份
增量备份其实就是试试备份,使用的就是bin log文件。mysql的每次更新数据操作,都会记录到Binlog中。并且binlog可以进行回放的。
show VARIABLES like '%log_bin%';

可以看到默认是开启binlog的。还有对应binlog的存储地址,索引位置。
show master status;
显示正在写入的binlog文件,当前位置。

所以配合使用全量+增量备份,可以保证数据即使丢失,也可以进行恢复。
- 不要把数据都只存储在一个服务器上。
- 回放binlog文件,时间点稍微提前一点。
配置MySQL HA实现高可用
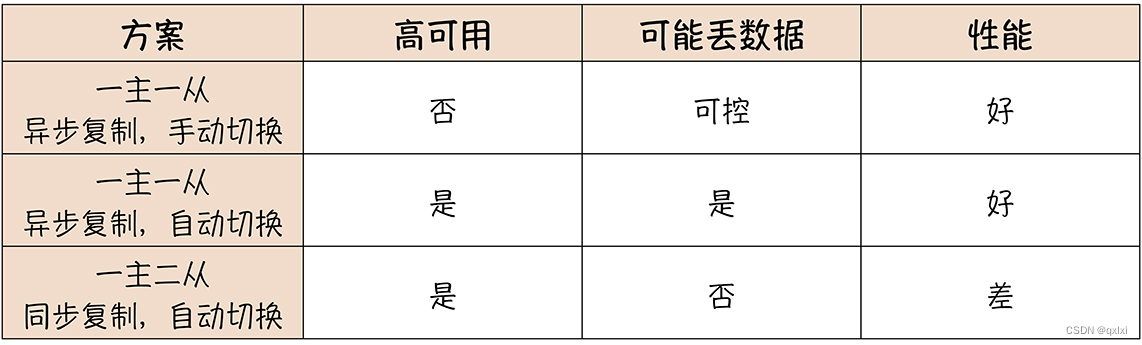
上述虽然使用全量和增量的备份方式,但是当出现数据故障的时候,如果在去进行数据恢复,这个时间是不可预估的。所以更好的方式是同时启用备用库,实时同步主库的binlog文件。一旦主库宕机,立马切到备用库。这就是MySQL的HA方案。
更新数据流程
- 主库进行更新数据然后写入bin log
- 主库更新存储引擎中的数据
- 返回客户端成功响应
- 主库把binlog复制从库
- 从库回放binlog,更新存储引擎中数据。
正常情况下,主从之间的延迟大概在毫秒级别,但是当出现主从之间数据延迟过高的时候,从库就获取不到最新的数据。并且一般数据库都是先繁忙,然后性能下降,最终宕机。这种情况下,如果我们直接切换从库,那么从库的数据就可能丢失部分数据。并且后续没有办法进行恢复,因为数据是冲突的。
所以在主库宕机并且主从有延时的情况下,是切换到从库继续提供服务,还是为了保证数据一致性,不切,是一个权衡。
也就是数据一致性和可用性之前权衡,则中的方式也有,但是需要主库写完从库之后,在返回客户端成功写入数据。如果一个从库的话,可能回阻塞。所以一般就是采用2台从库,一台主库。
小结
本篇主要介绍了数据恢复,全量和增量复制,高可用依靠的就是数据复制,数据复制其实就是将数据从一台复制到另一台。而在复制的过程中,选择同步复制、还是异步复制。等都需要结合业务进行选择。