2023-09-12 14:00——2023.09.13 20:06
目录
00、软件版本
01、阿里云服务器部署hadoop
1.1、修改四个配置文件
1.1.1、core-site.xml
1.1.2、hdfs-site.xml
1.1.3、mapred-site.xml
1.1.4、yarn-site.xml
1.2、修改系统/etc/hosts文件与系统变量
1.2.1、修改主机名解析文件/etc/hosts
1.2.2、修改系统环境变量/etc/profile.d/my_env.sh
02、阿里云服务器部署elasticsearch
2.1、三节点的同样操作
2.2、修改es的elasticsearch.yml文件
00、软件版本
环境及软件版本:
- centOS 7
- jdk-1.8
- hadoop-3.3.4
- elasticsearch-7.17.6
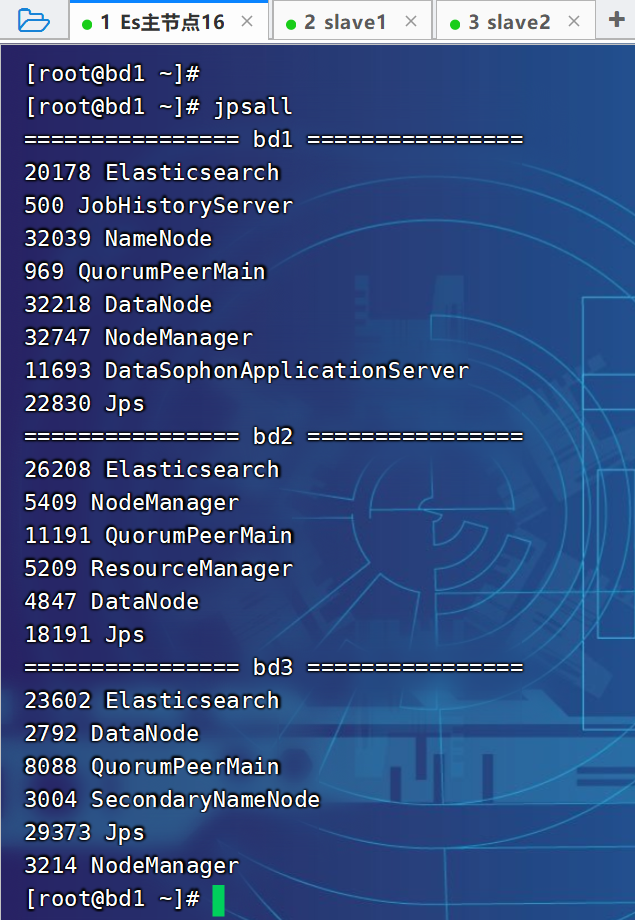
01、阿里云服务器部署hadoop
按照尚硅谷的教程安装hadoop-3.3.4,尚硅谷大数据技术之Hadoop.docx。
1.1、修改四个配置文件
/opt/module/hadoop/hadoop-3.3.4/etc/hadoop
1.1.1、core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://bd1:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop/hadoop-3.3.4/data</value>
</property><!-- 配置HDFS网页登录使用的静态用户为atguigu --><property><name>hadoop.http.staticuser.user</name><value>xxh</value>
</property><!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 --><property><name>hadoop.proxyuser.xxh.hosts</name><value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 --><property><name>hadoop.proxyuser.xxh.groups</name><value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户--><property><name>hadoop.proxyuser.xxh.users</name><value>*</value>
</property>
</configuration>1.1.2、hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>bd1:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>bd3:9868</value></property><!-- 测试环境指定HDFS副本的数量1 --><property><name>dfs.replication</name><value>3</value>
</property><!-- 关闭 hdfs 文件权限检查 -->
<property><name>dfs.permissions</name><value>false</value>
</property>
</configuration>1.1.3、mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>bd1:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>bd1:19888</value>
</property>
</configuration>1.1.4、yarn-site.xml
<?xml version="1.0"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
-->
<configuration><!-- Site specific YARN configuration properties -->
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>bd2</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property><!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>4096</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><!-- 关闭yarn对物理内存和虚拟内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property><!-- 设置日志聚集服务器地址 -->
<property><name>yarn.log.server.url</name><value>http://bd1:19888/jobhistory/logs</value>
</property><!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>
</configuration>1.2、修改系统/etc/hosts文件与系统变量
1.2.1、修改主机名解析文件/etc/hosts
[root@bd1 ~]# vim /etc/hosts
# 外网ip地址
x.x.x.x bd1
x.x.x.x bd2
x.x.x.x bd3# 内网ip地址(使用命令ifconfig命令进行查看)
x.x.x.x bd1
x.x.x.x bd2
x.x.x.x bd31.2.2、修改系统环境变量/etc/profile.d/my_env.sh
[root@bd1 ~]# vim /etc/profile.d/my_env.sh
# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin# HADOOP相关配置【重中之重,使得root用户可以直接运行hadoop】
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin# HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop/hadoop-3.3.4
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin# zookeeper
export ZK_HOME=/opt/module/zookeeper
export PATH=$ZK_HOME/bin:$PATH# kafka
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/binexport PATH=$PATH:/opt/software/tool# HADOOP相关配置
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
02、阿里云服务器部署elasticsearch
es安装教程
- Linux搭建es集群详细教程(最终版)_es集群搭建_Nick丶Xin的博客-CSDN博客
- Linux安装elk_upward337的博客-CSDN博客
- [2020-04-06T12:57:13,793][WARN ][o.e.b.ElasticsearchUncaughtExceptionHandler] [node-1] uncaught exce_Lan_Se_Tian_Ma的博客-CSDN博客
2.1、三节点的同样操作
三节点集群的服务器,每台服务器都需要:
- 创建es用户,useradd es、passwd es
- 安装elasticsearch,tar -zxvf elasticsearch-7.17.6-linux-x86_64.tar.gz -C /opt/module/es/
- 修改elasticsearch文件夹权限,chown -R es:es /opt/module/es/
- 修改/etc/...目录下的若干配置文件,vi /etc/security/limits.conf、vi /etc/security/limits.d/20-nproc.conf、vi /etc/sysctl.conf
- 修改/opt/module/es/elasticsearch-7.17.6/config/jvm.options文件。
启动elasticsearch时,需要切换到es用户,使用如下命令在后台启动es:
- [es@bd1 root]$ nohup /opt/module/es/elasticsearch-7.17.6/bin/elasticsearch & # 后台运行elasticsearch
- [es@bd2 root]$ nohup /opt/module/es/elasticsearch-7.17.6/bin/elasticsearch & # 后台运行elasticsearch
- [es@bd3 root]$ nohup /opt/module/es/elasticsearch-7.17.6/bin/elasticsearch & # 后台运行elasticsearch
2.2、修改es的elasticsearch.yml文件
修改每台服务器的elasticsearch.yml文件(/opt/module/es/elasticsearch-7.17.6/config/elasticsearch.yml),如下两个参数的配置每台服务器都不一样:
- node.name: node-1 # 节点名称,每个节点的名称不能重复
- network.host: 内网ip地址 # 内网ip地址,每个节点的地址不能重复
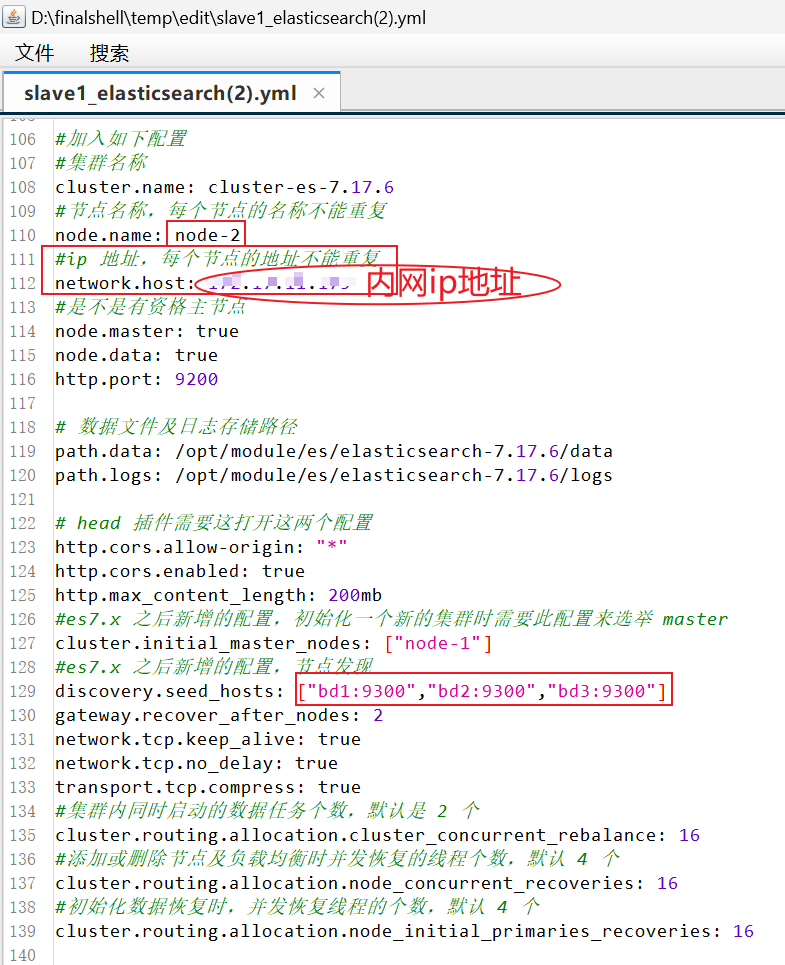
# /opt/module/es/elasticsearch-7.17.6/config/elasticsearch.yml#es加入如下配置#集群名称
cluster.name: cluster-es-7.17.6
#节点名称,每个节点的名称不能重复
node.name: node-1
#内网ip地址,每个节点的地址不能重复
network.host: 内网ip地址
#是不是有资格主节点
node.master: true
node.data: true#http端口
http.port: 9200
# 服务通信端口
transport.port: 9300# 数据文件及日志存储路径
path.data: /opt/module/es/elasticsearch-7.17.6/data
path.logs: /opt/module/es/elasticsearch-7.17.6/logs# head 插件需要这打开这两个配置
http.cors.allow-origin: "*"
http.cors.enabled: true
http.max_content_length: 200mb
#es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举 master
cluster.initial_master_nodes: ["node-1"]
#es7.x 之后新增的配置,节点发现
discovery.seed_hosts: ["bd1:9300","bd2:9300","bd3:9300"]
gateway.recover_after_nodes: 2
network.tcp.keep_alive: true
network.tcp.no_delay: true
transport.tcp.compress: true
#集群内同时启动的数据任务个数,默认是 2 个
cluster.routing.allocation.cluster_concurrent_rebalance: 16
#添加或删除节点及负载均衡时并发恢复的线程个数,默认 4 个
cluster.routing.allocation.node_concurrent_recoveries: 16
#初始化数据恢复时,并发恢复线程的个数,默认 4 个
cluster.routing.allocation.node_initial_primaries_recoveries: 16😊😘加油~