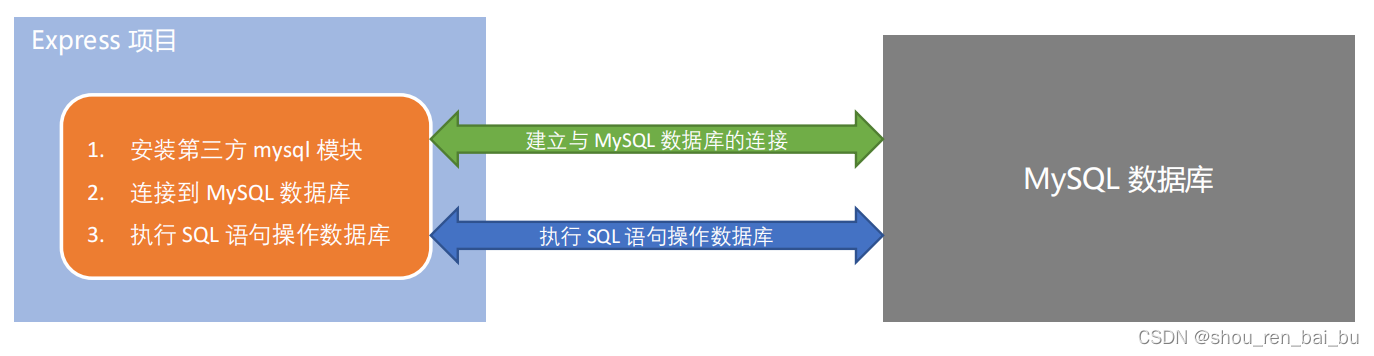
前言:与传统的AI攻防(后门攻击、对抗样本、投毒攻击等)不同,如今的大模型攻防涉及以下多个方面的内容:

目录
- 一、大模型的可信问题
- 1.1 虚假内容生成
- 1.2 隐私泄露
- 二、大模型的模型安全问题(传统AI攻防)
- 2.2 数据窃取攻击
- 2.3 Prompt攻击
- 2.4 对抗样本攻击
- 2.5 后门攻击
- 2.6 数据投毒
- 三、基于大模型的隐蔽通信(大模型隐写)
- 四、大模型的产权问题
- 五、 大模型的伦理问题
- 5.1 意识形态
- 5.2 偏见歧视
- 5.3 政治斗争
- 5.4 就业公平
- 5.5 信息茧房
一、大模型的可信问题
1.1 虚假内容生成
攻击:大模型可能会进行虚假内容的生成和传播,诱导和操控用户的观点和行为。(AI的幻觉问题)。
防御:对大模型进行可信输出度量。类似于一般模型的置信度,大模型可在训练过程中添加对输出内容的可行性评估,将置信度同时提供给用户作为参考。
1.2 隐私泄露
攻击:大模型导致的隐私泄露分为两种:
(1)显式隐私泄露:大模型将用户的指令作为训练数据,不经意间会将训练数据转换为生成内容,而这些训练数据可能包含用户敏感信息。大模型会将对话框的内容存储,包括而不限于用户个人信息如姓名,电子邮箱账户等。
(2)隐式隐私泄露:通过对对话框内容的收集,大模型能够推断出潜在的敏感信息如用户的偏好、兴趣、行为等,基于此进行精准的广告推荐。
防御:对输入输出数据进行隐私保护
二、大模型的模型安全问题(传统AI攻防)
ChatGPT等生成式大模型本质上是基于深度学习的一个大型模型,也面临着人工智能安全方面的诸多威胁,包括模型窃取,以及各种传统攻击(对抗样本攻击,后门攻击,prompt攻击,数据投毒等)来引起输出的错误。 2.1 模型窃取攻击
攻击:模型窃取指的是攻击者依靠有限次数的模型询问,从而得到一个和目标模型 的功能和效果一致的本地模型。攻击者尝试通过分析模型的输入输出和内部结构来还原模型的设计和参数。这可能导致模型的知识产权泄露,带来安全风险。
防御:为防止模型窃取,可采取如下技术保护模型参数:
(1) 模型加密:对模型的参数进行加密。
(2) 模型水印:对大模型进行溯源和验证,以确保其来源和合法性。
(3) 模型集成:通过将多个模型集成在一起,可以提高模型的鲁棒性和安全性。集成学习技术可以通过组合多个模型的预测结果来提高模型的性能和安全性。
(4) 模型蒸馏:降低模型规模,小模型对于噪音和扰动的容忍能力更强。
(5) 访问控制:确保大模型在部署和使用过程中的安全性,包括访问控制、身份认证、权限管理和数据保护等方面。这有助于防止未经授权的访问和滥用。
2.2 数据窃取攻击
攻击:大模型通常需要处理大量的敏感数据,攻击者可能试图通过访问模型或截获模型的输入输出来获取训练过程中使用过的数据的分布,从而获取敏感信息[1]。
防御:(1)设立相应机制判断用户是否在进行以窃取为目的的查询。(2)对用户敏感信息进行加密上传。
2.3 Prompt攻击
Prompt的构建使得预训练大模型能够输出更加符合人类语言和理解的结果,但是不同的prompt的模板依旧有可能会导致一些安全问题和隐私问题的出现。
2.4 对抗样本攻击
攻击者通过对输入样本进行微小的修改,使其能够欺骗模型,导致错误的预测结果。这可能会对模型的可靠性和安全性产生负面影响。
2.5 后门攻击
攻击者在模型中插入后门,使其在特定条件下产生错误的输出结果或泄露敏感信息。这可能导致模型被滥用或被攻击者控制。
2.6 数据投毒
……
三、基于大模型的隐蔽通信(大模型隐写)
攻击:由于训练数据的规模庞大,大模型在隐蔽通信中具有天然优势——其能够更加合理地模拟真实数据分布,一定程度上提升生成载密文本的统计不可感知性。攻击者通过使用大模型生成流畅的载密文本,在公共信道中进行传输。目前,跨模态隐写逐渐引起研究人员关注,结合大模型完成跨模态隐写值得尝试。
防御:针对生成式大模型的隐写分析算法有待提出。
四、大模型的产权问题
问题:大模型生成作品的版权归属如今尚不明朗。
措施:
(1)在大模型的训练过程中,除原始输入本身,还需要将数据来源以及产权信息作为训练数据。这将使得在使用大模型进行创作任务时,能够准确查询是否涉及到某些产权,而需要引用和付费等。这一功能的实现将能够极大提升数据价值,避免产权纠纷,也能够让ChatGPT更好地辅助科研和创作。
(2)使用区块链技术对数据源版权进行记录保护,区块链技术的使用也方便于之后产权纠纷处理中的溯源分析。
(3)使用电子水印技术保护数据源的版权和实用模型的版权。
五、 大模型的伦理问题
5.1 意识形态
5.2 偏见歧视
5.3 政治斗争
5.4 就业公平
5.5 信息茧房
针对大模型存在的伦理问题,需要建立各类信息的检测机制,设立实时监管系统,对大模型的违规行为进行记录。
以上是大模型攻防的一些常见内容,个人感觉大模型攻防与传统AI攻防的主要区别在于程度的差异——大模型由于其广泛被用于各个场景,对人类社会的影响自然要大于普通模型,也正因此,大模型的攻防研究颇为关键,亟待开展。
参考资料
- 微软ChatGPT版必应被黑掉了:全部Prompt泄露 - 安全内参 | 决策者的网络安全知识库 (secrss.com)
- 2023生成式大模型安全与隐私白皮书, 之江实验室, 2023.
- Survey of Hallucination in Natural Language Generation (acm.org)