目标分类
- 一、目标分类介绍
- 1.1 二分类和多分类的区别
- 1.2 单标签和多标签输出的区别
- 二、代码获取
- 三、数据集准备
- 四、环境搭建
- 4.1 环境测试
- 五、模型训练
- 六、模型测试
- 6.1 多标签训练-单标签输出结果
- 6.2 多标签训练-多标签输出结果
一、目标分类介绍
目标分类是一种监督学习任务,其目标是根据输入数据的特征将其分配到预定义的类别中。这种分类方法在许多实际应用中都有广泛的应用,如垃圾邮件检测、图像识别、情感分析等。
目标分类的基本流程包括:数据预处理(如清洗、标准化)、特征提取、模型选择和训练、模型评估和优化。其中,模型的选择和训练是关键步骤,常见的分类算法有决策树、支持向量机、神经网络等。
目标分类的优点是可以自动地进行分类,无需人工干预,同时也可以通过调整模型参数来提高分类的准确性。但是,目标分类也存在一些挑战,如数据的不平衡问题、过拟合问题等。
1.1 二分类和多分类的区别
二分类是指将样本分为两个类别,多分类是指将样本分为多个类别。在机器学习中,常见的分类算法有决策树、支持向量机、神经网络等。其中,决策树是一种基于规则的分类算法,支持向量机是一种基于间隔最大化的分类算法,神经网络是一种基于非线性映射的分类算法。对于多分类问题,可以采用一对多的模型,即将一个二分类器用于多个类别的预测;也可以采用多对多的模型,即将多个二分类器用于多个类别的预测 。
1.2 单标签和多标签输出的区别
单标签输出是指模型的输出只有一个预测值,即 f (x) = y。多标签输出是指模型的输出具有多个预测值,即 f (x_1,x_2,…,x_n) = y_1, y_2,…,y_n。在多标签分类中,每个输入样本需要零个或多个标签作为输出,同时需要输出 。
二、代码获取
- 支持自定义数据集训练
- 支持网络架构:resnet18,resnet50,mobilenet_v2,googlenet
- 整套训练代码和测试代码(Pytorch版本)
- 支持多种优化器选择
- 支持选择多种损失函数:交叉熵、labelSmoothing、BCE等
- 所有的配置文件写在yaml文件,更方便管理

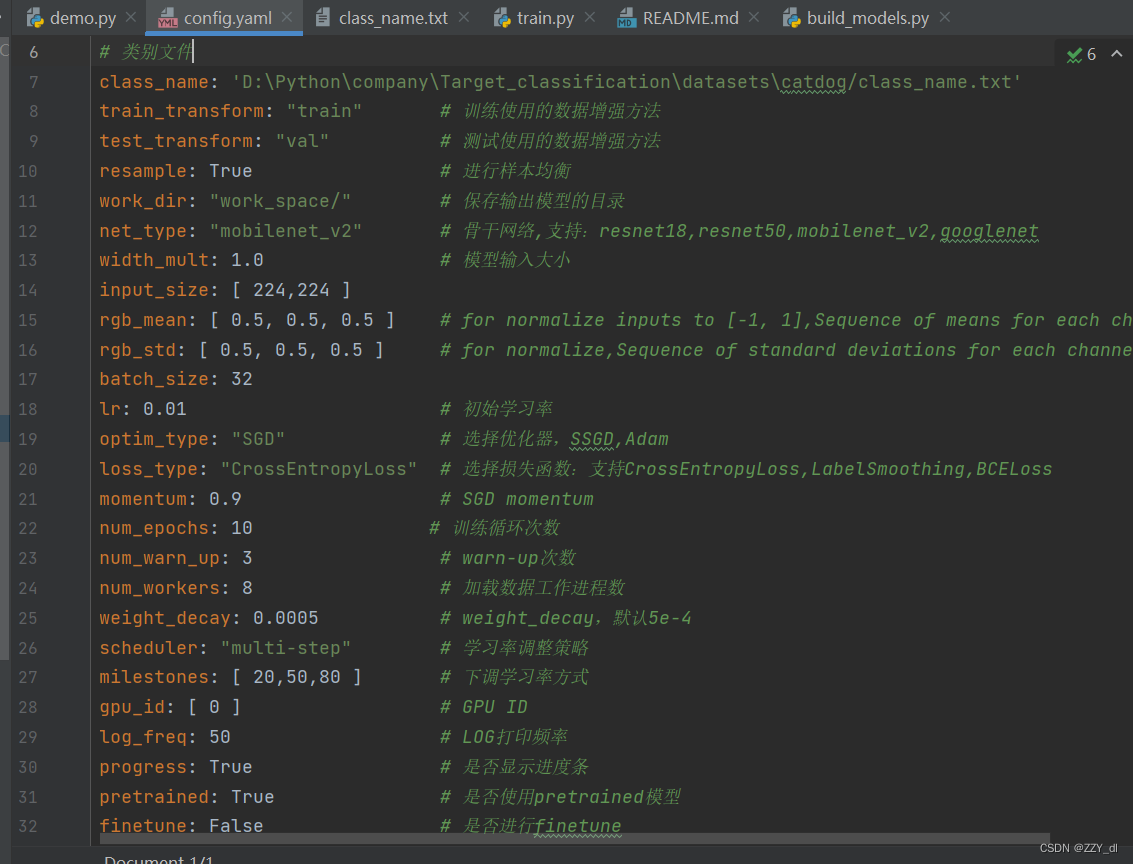
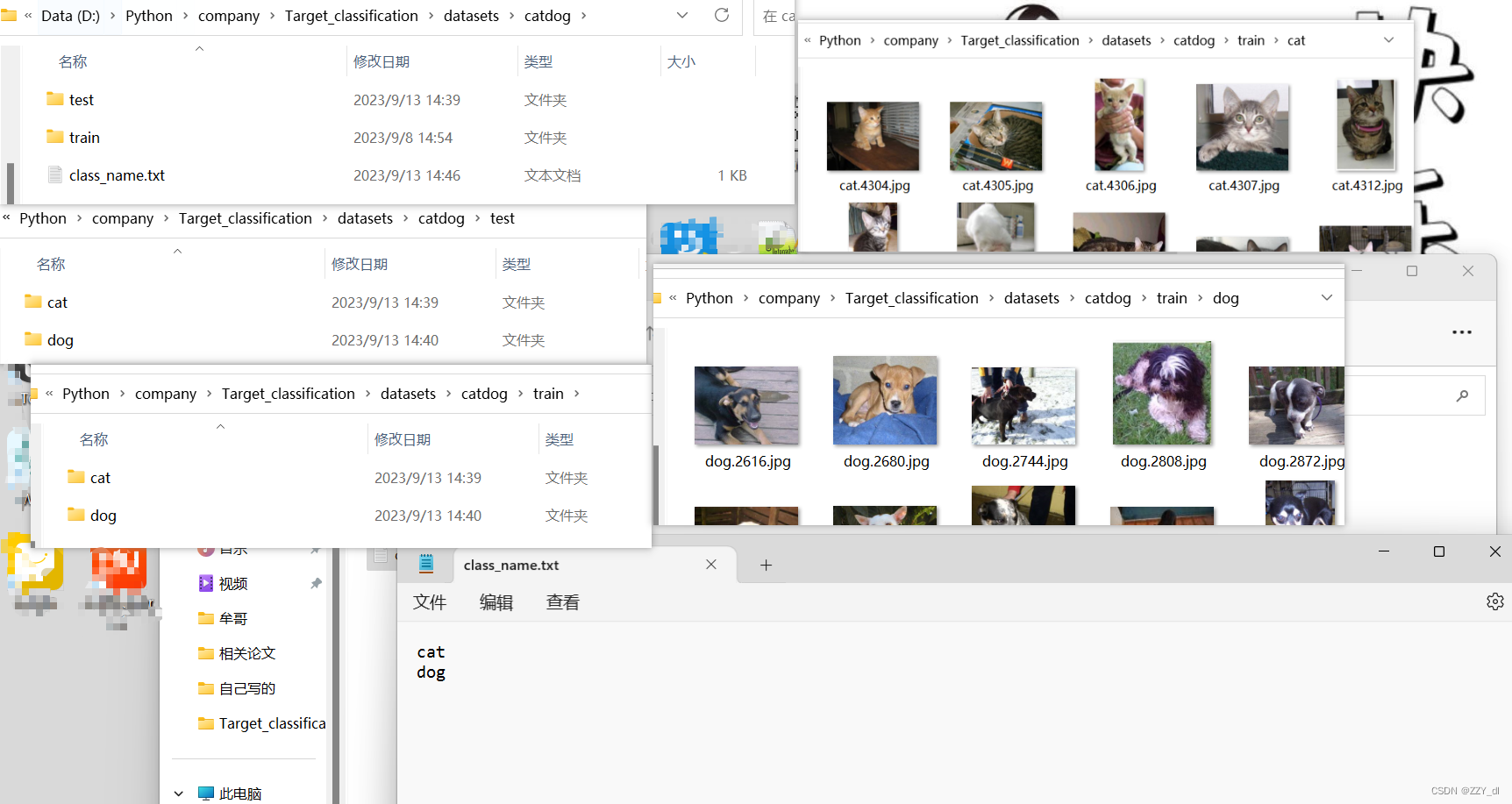
三、数据集准备
四、环境搭建
安装python、torch、torchvision和pip安装requirements
安装python可以通过anaconda安装虚拟环境,python == 3.7.11
torch和torchvision版本是torch 1.8.0+cpu和torchvision 0.9.0+cpu
- 如果安装gpu就去这里面下载对应的torch和torchvision的版本就行,需要先安装cuda
- https://download.pytorch.org/whl/torch_stable.html
参考这篇博客:点击
4.1 环境测试
五、模型训练
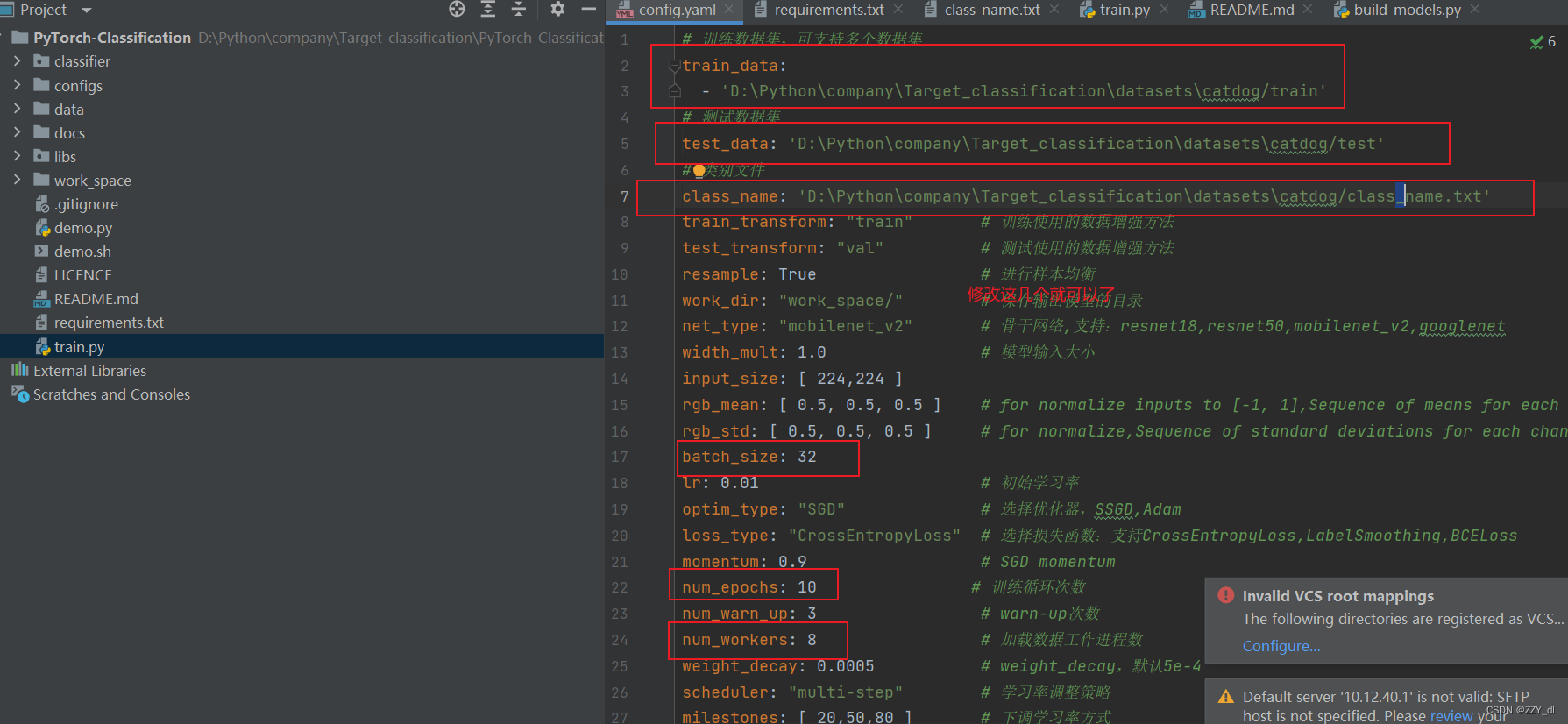
然后运行python train.py即可开始训练。
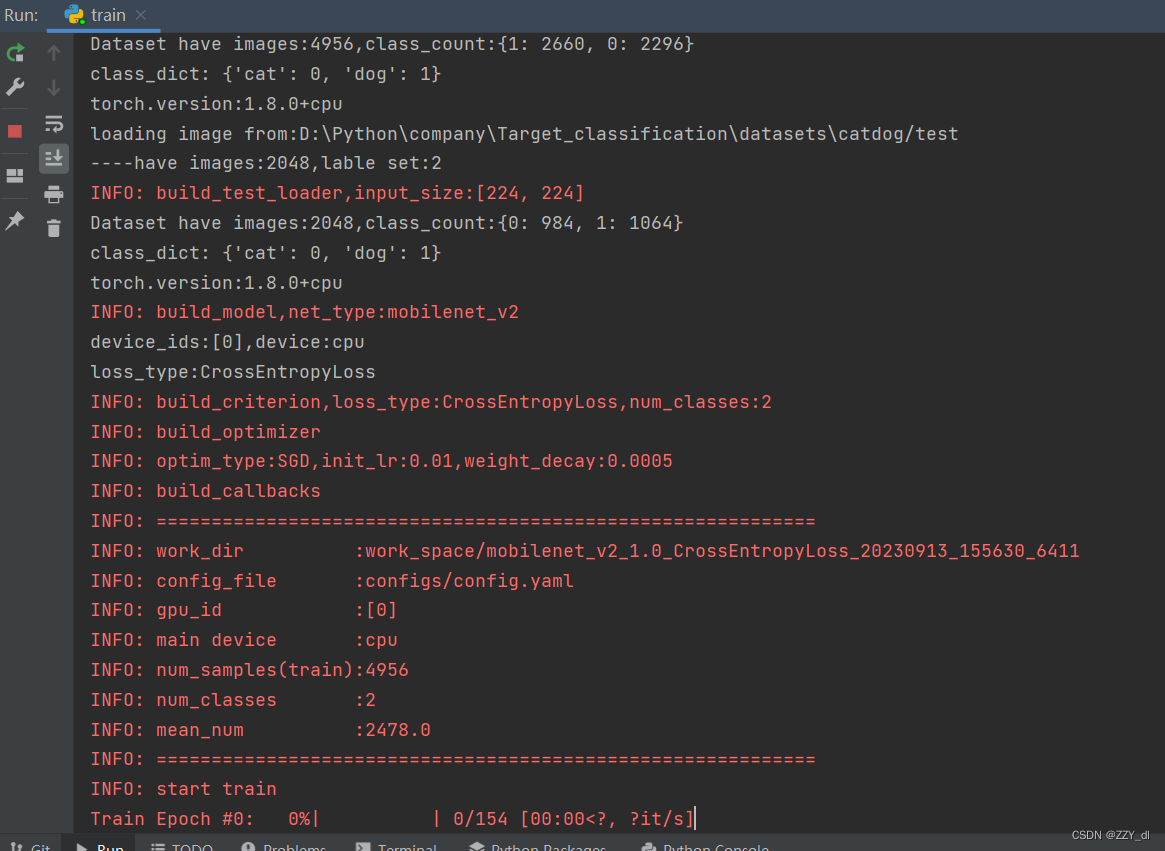
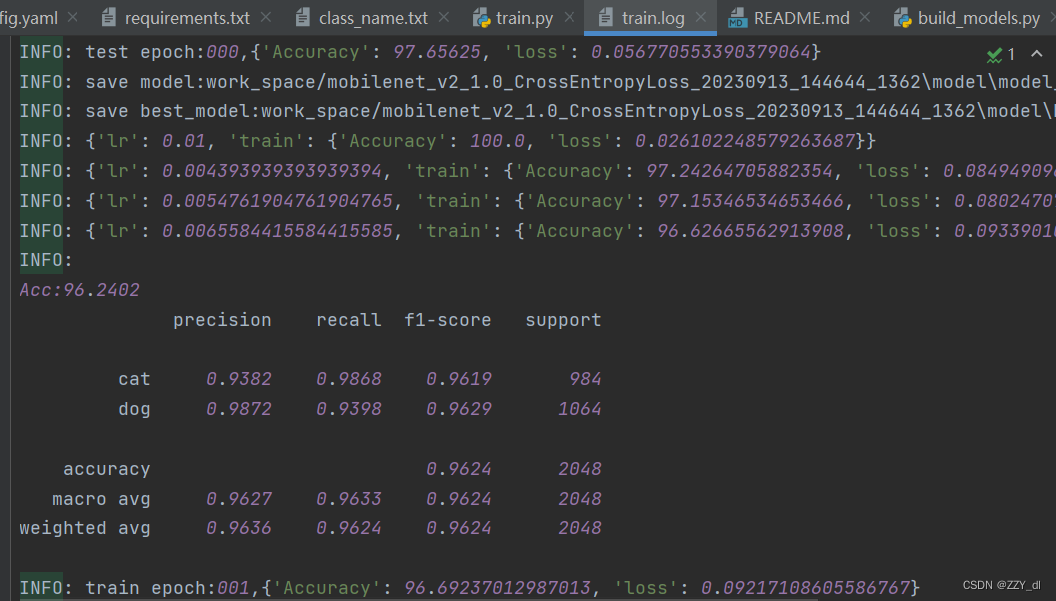
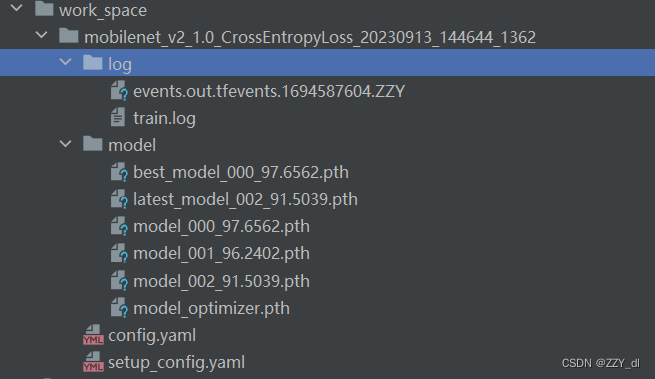
六、模型测试
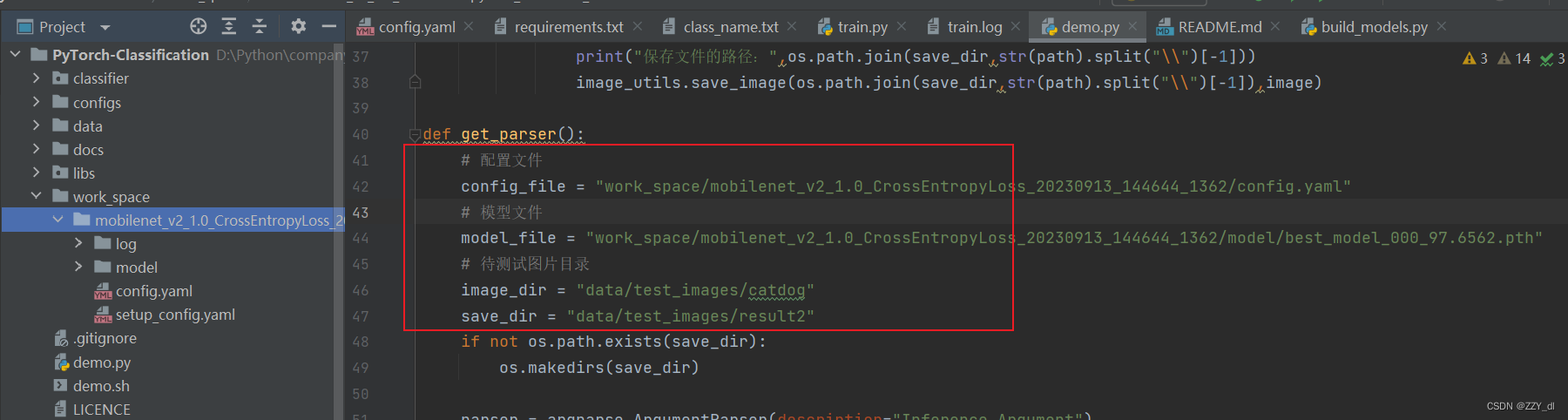
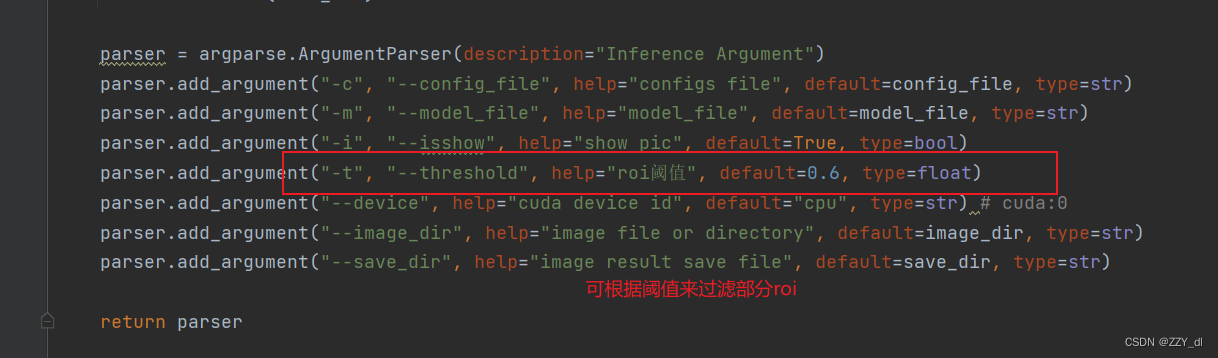
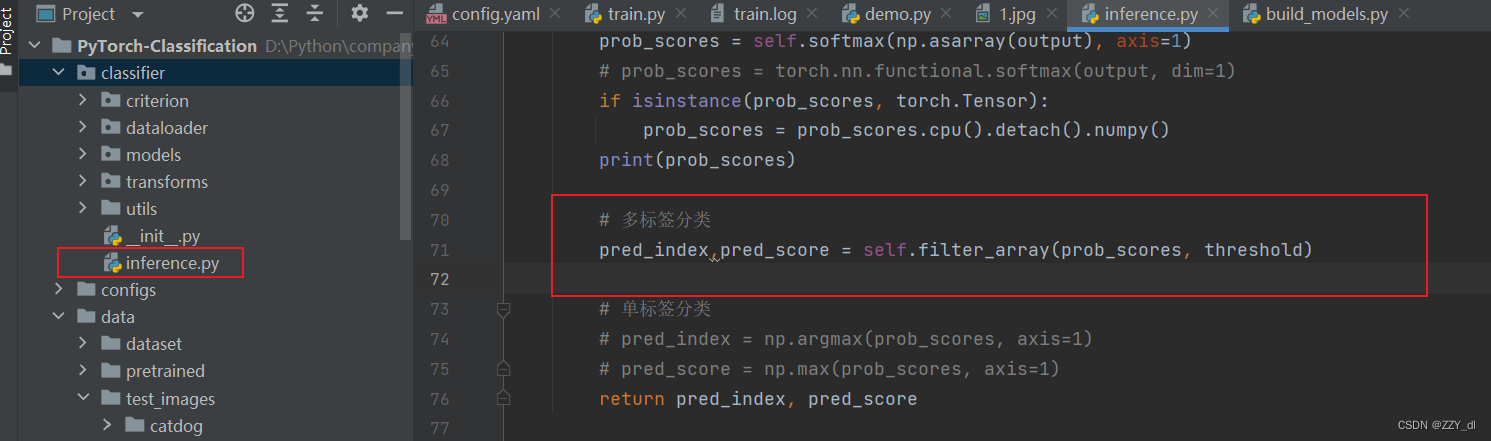
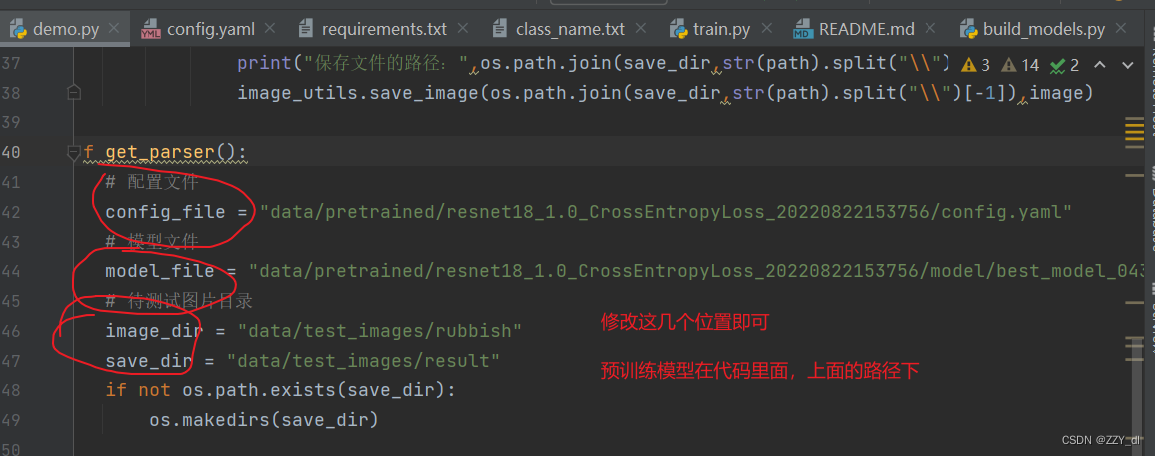
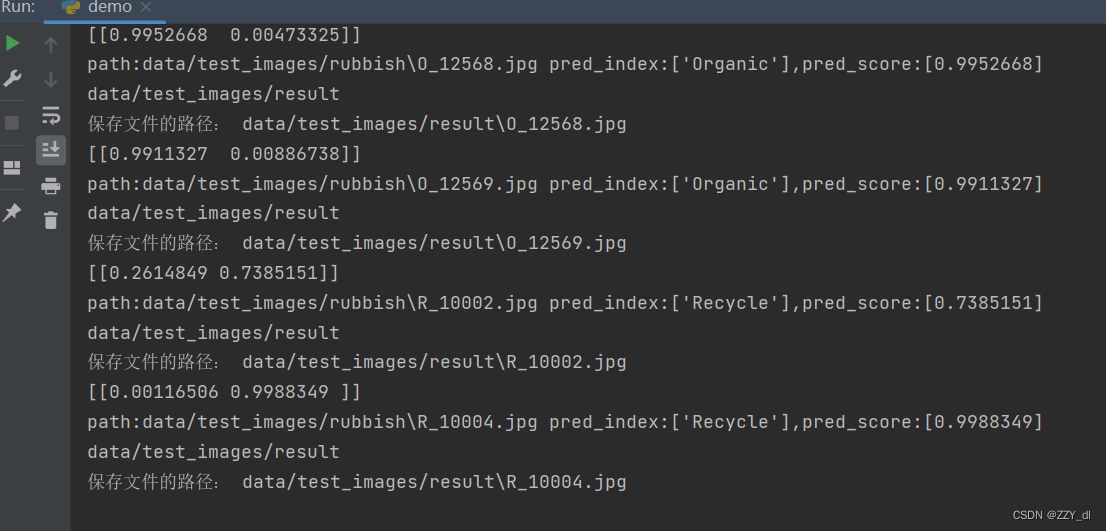
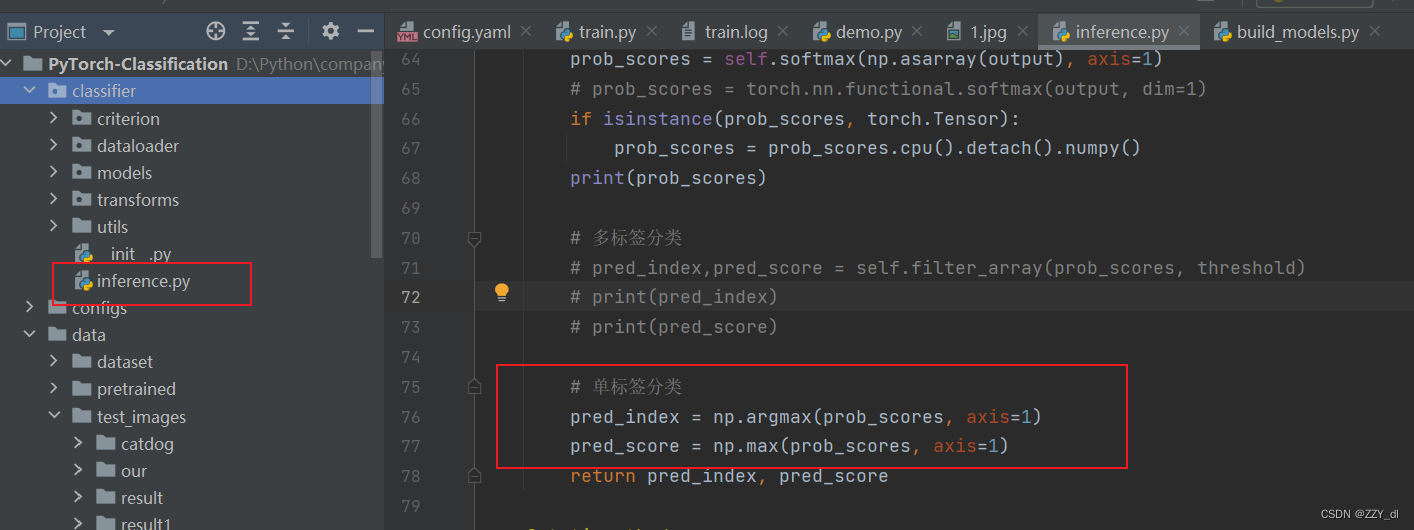
设置以上五个地方。由于网络真实预测的时候,可能会出现一张图片包含多种分类的目标。考虑到这种情况就不能简单的用argmax来获取最大值的索引了,所以我们应该通过设置阈值来记录相应类别的索引,然后再根据索引回溯到我们原始的目标信息。
修改后的代码如下:
# 单标签分类pred_index = np.argmax(prob_scores, axis=1)pred_score = np.max(prob_scores, axis=1)
修改为
def filter_array(self, arr, threshold):# 获取满足条件的索引和值arr = arr.flatten()indices = np.where(arr >= threshold)[0]values = arr[indices]return indices, valuespred_index,pred_score = self.filter_array(prob_scores, threshold)
这里的阈值可以直接通过参数来进行设置。
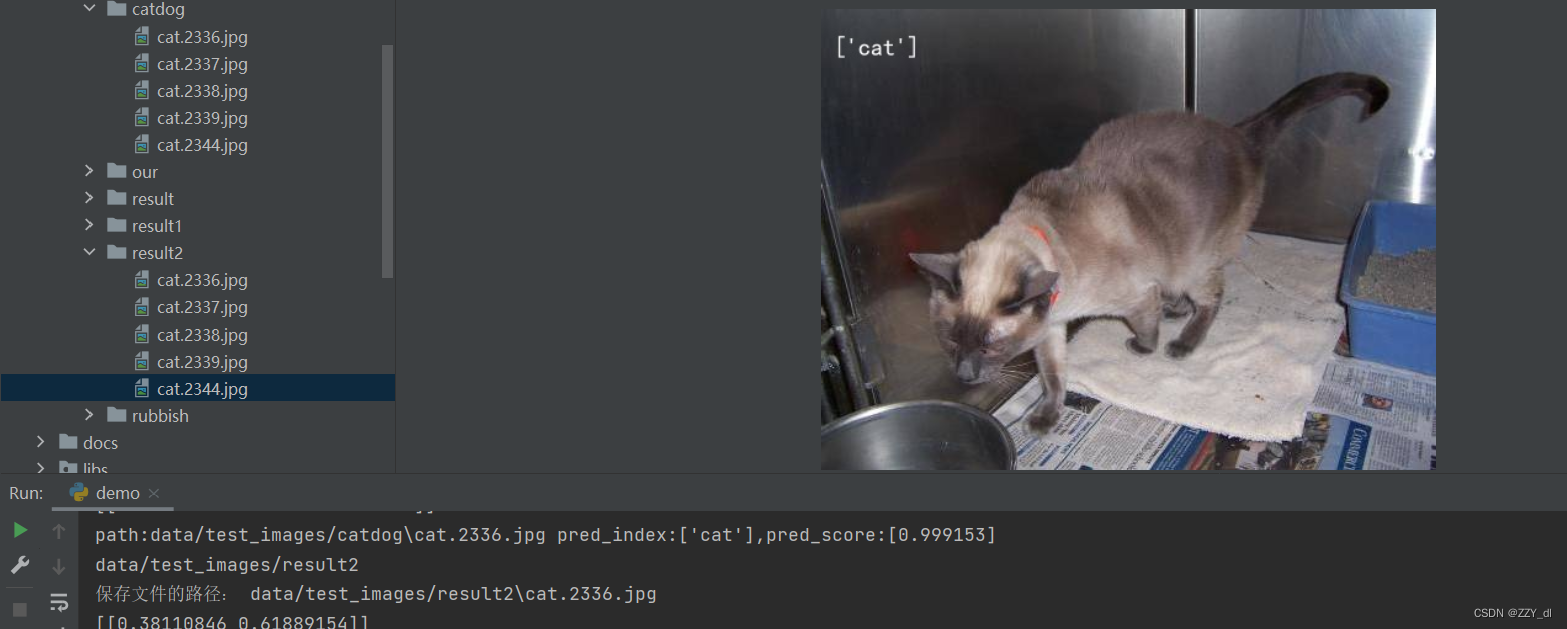
6.1 多标签训练-单标签输出结果
如果只需要输出单个目标,需要修改成以下地方
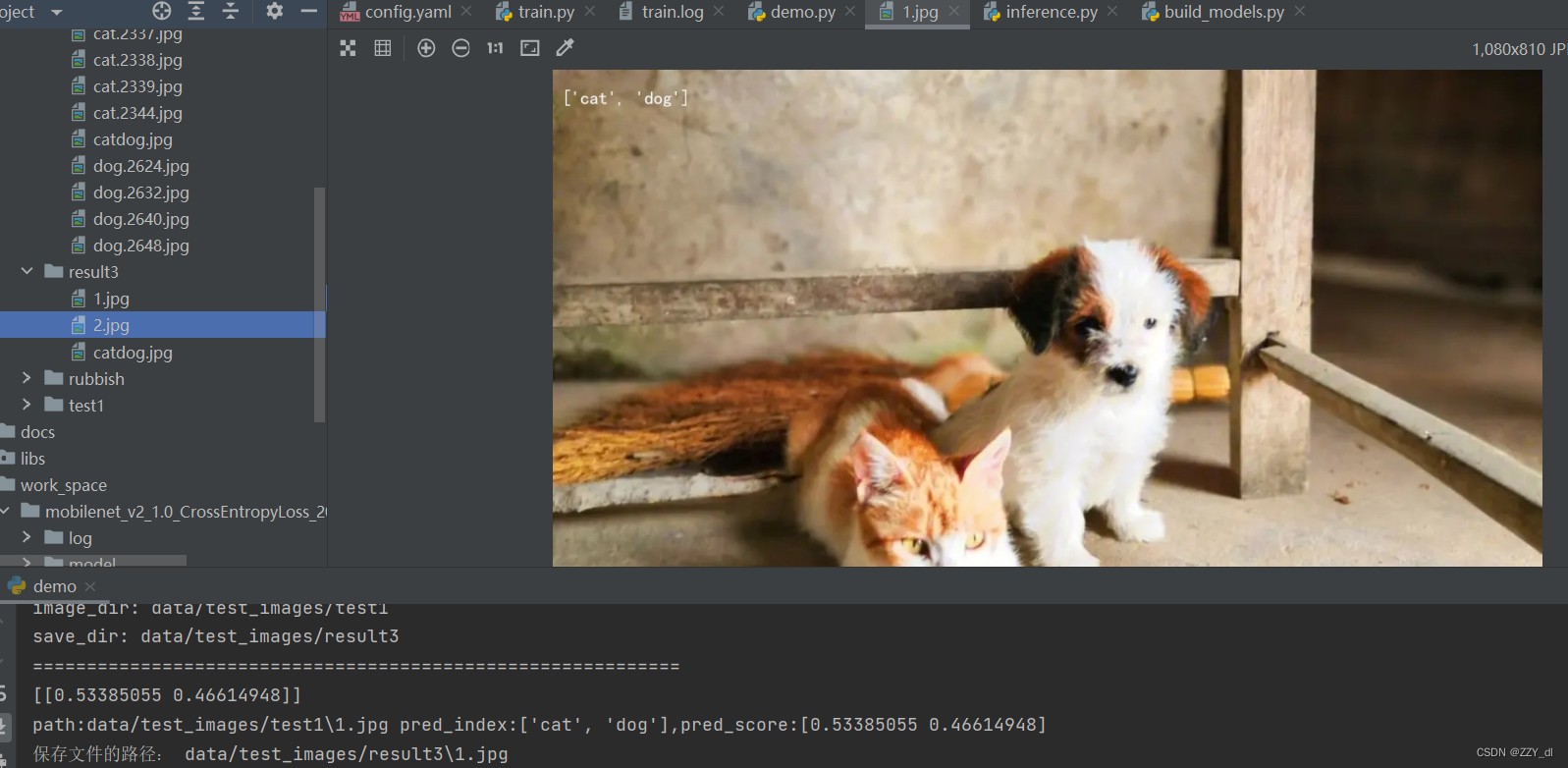
6.2 多标签训练-多标签输出结果
修改成这样