文章目录
- 前言
- 1. 开启ssh服务
- 2. ssh连接
- 3. 安装cpolar内网穿透
- 4. 配置绿联NAS公网地址
前言
本文主要介绍如何在绿联NAS中使用ssh远程连接后,使用一行代码快速安装cpolar内网穿透工具,轻松实现随时随地远程访问本地内网中的绿联NAS,无需公网IP也不用设置路由器那么麻烦。
1. 开启ssh服务
本例中使用的绿联NAS型号为4600+,其他型号也可以使用下方流程进行安装。
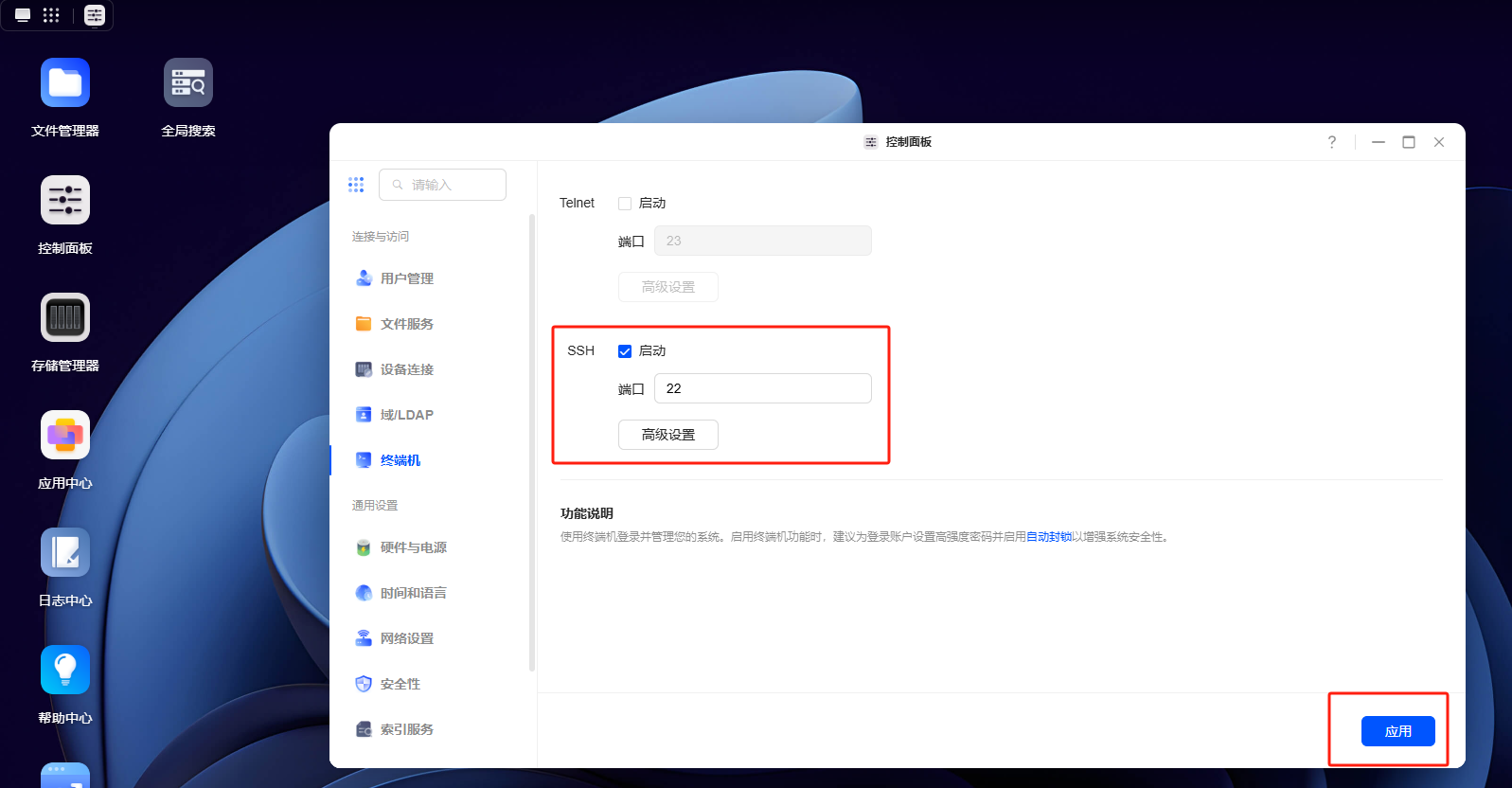
首先点击控制面板-终端机:

在SSH服务后勾选启动,端口为22,点击应用。
2. ssh连接
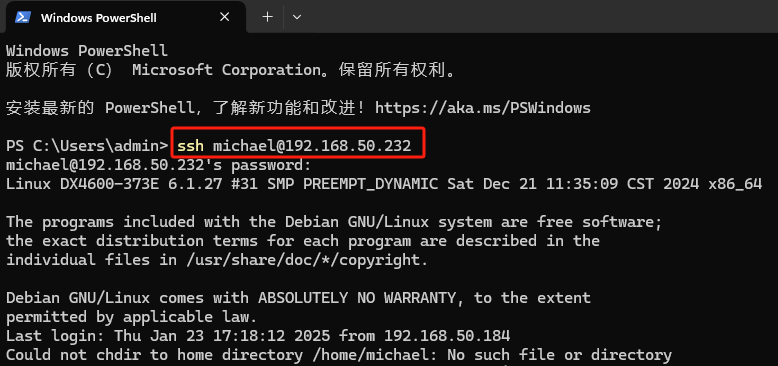
接下来,在电脑中使用终端ssh连接绿联NAS,我这里使用的是Windows11系统使用powershell进行演示:
执行命令:
## ssh 管理员用户名@绿联NAS的IP地址,本例为michael,在初始化时可以改为自己的。
ssh michael@192.168.50.232
输入密码后,成功登录:
3. 安装cpolar内网穿透
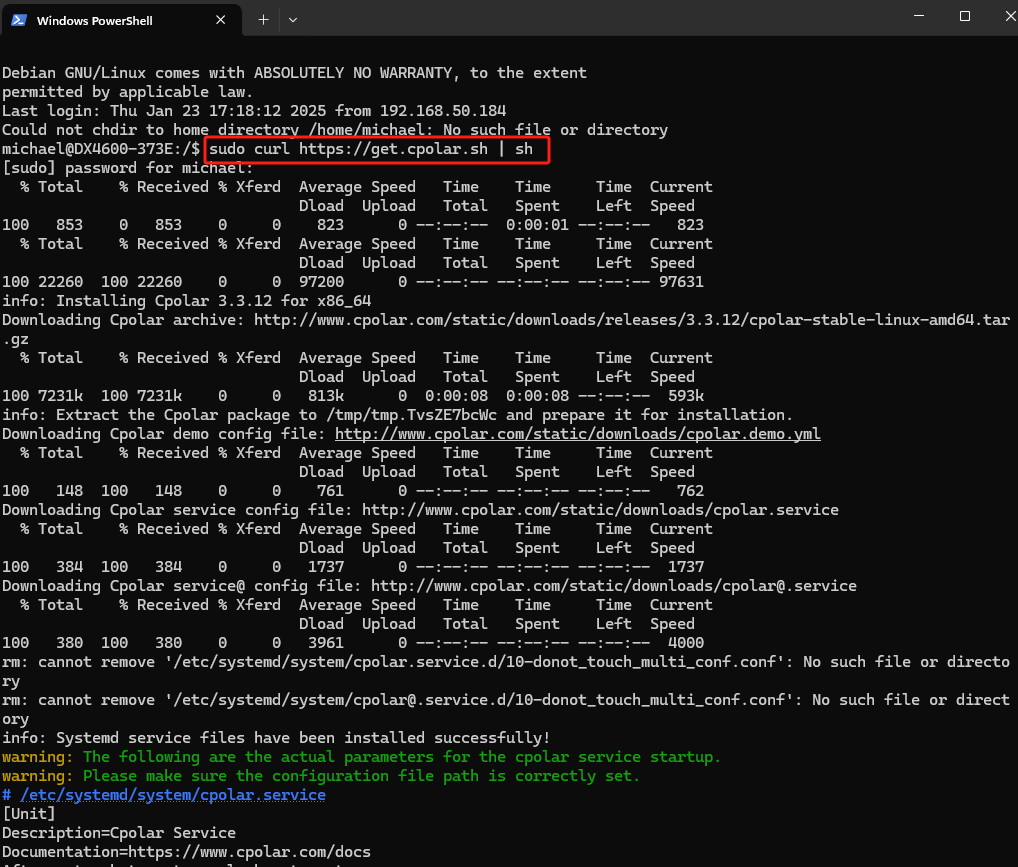
登录后,执行一键安装脚本:
sudo curl https://get.cpolar.sh | sh
输入管理员密码即可自动安装cpolar并启动服务:
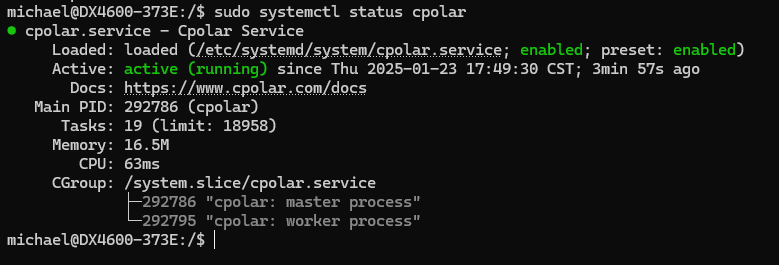
安装完成后,执行下方命令查看cpolar服务状态:(如图所示即为正常启动)
sudo systemctl status cpolar
Cpolar安装和成功启动服务后,在浏览器上输入你的绿联NAS主机IP加9200端口,本例中为:【http://192.168.50.232:9200】访问Cpolar管理界面:
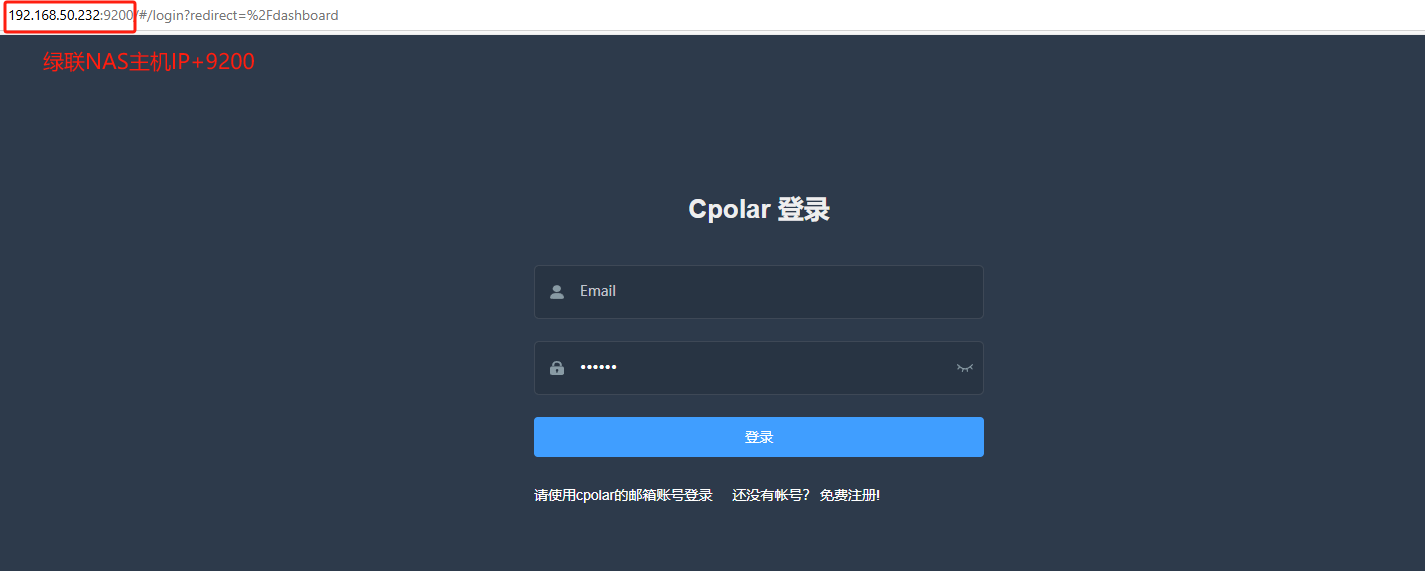
使用Cpolar官网注册的账号登录,登录后即可看到配置界面,在该界面配置即可:
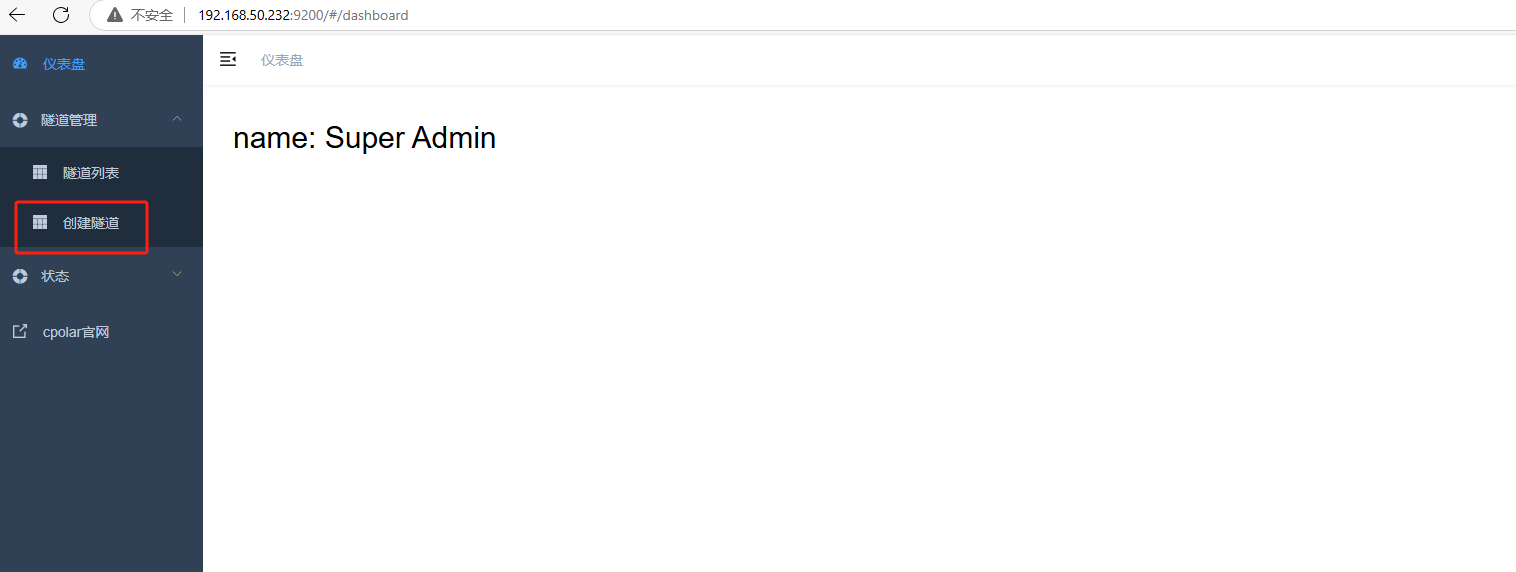
4. 配置绿联NAS公网地址
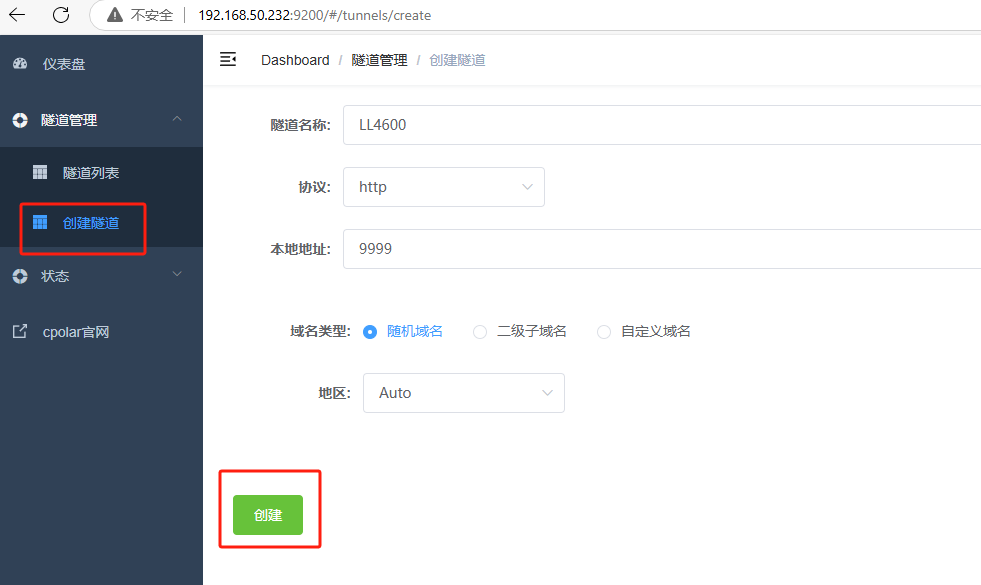
点击创建隧道:
隧道名称:自定义即可,我这里演示使用的是LL4600
协议:http
本地地址:9999 (9999为绿联系统的对外连接端口)
域名类型:随机域名
地区:Auto(默认自动分配,之后可根据实际使用地手动更改)
完成上述信息填写后,点击创建按钮即可创建隧道:
点击右侧在线隧道列表,可以看到cpolar已经为绿联NAS创建了两条随机公网地址:
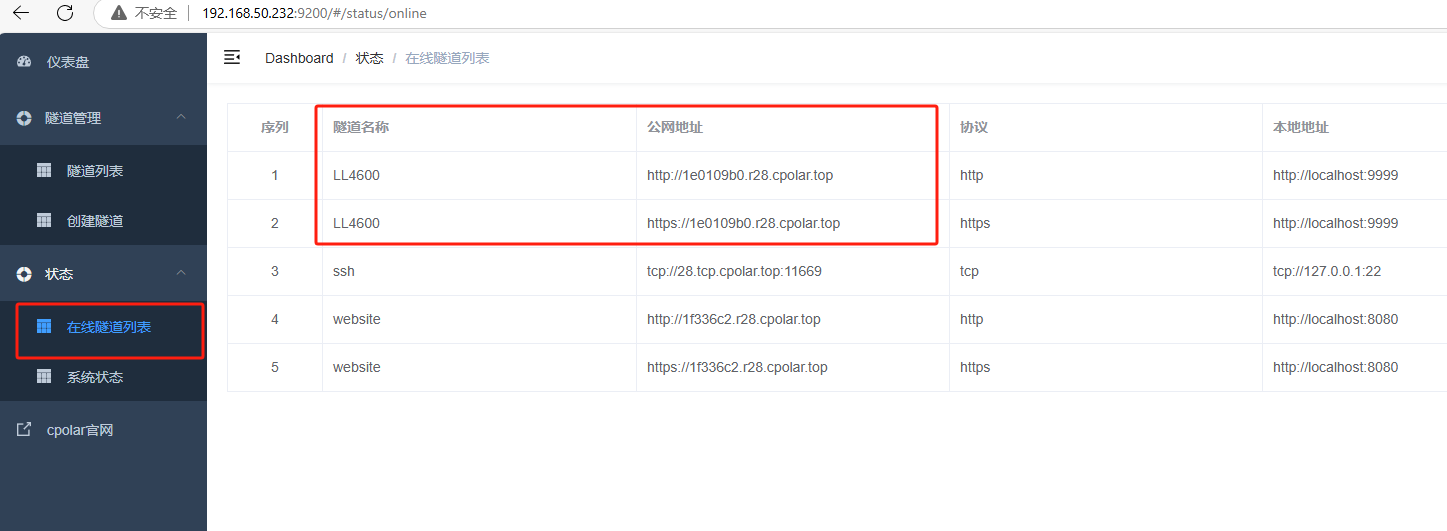
使用任意一个地址在浏览器中访问即可:
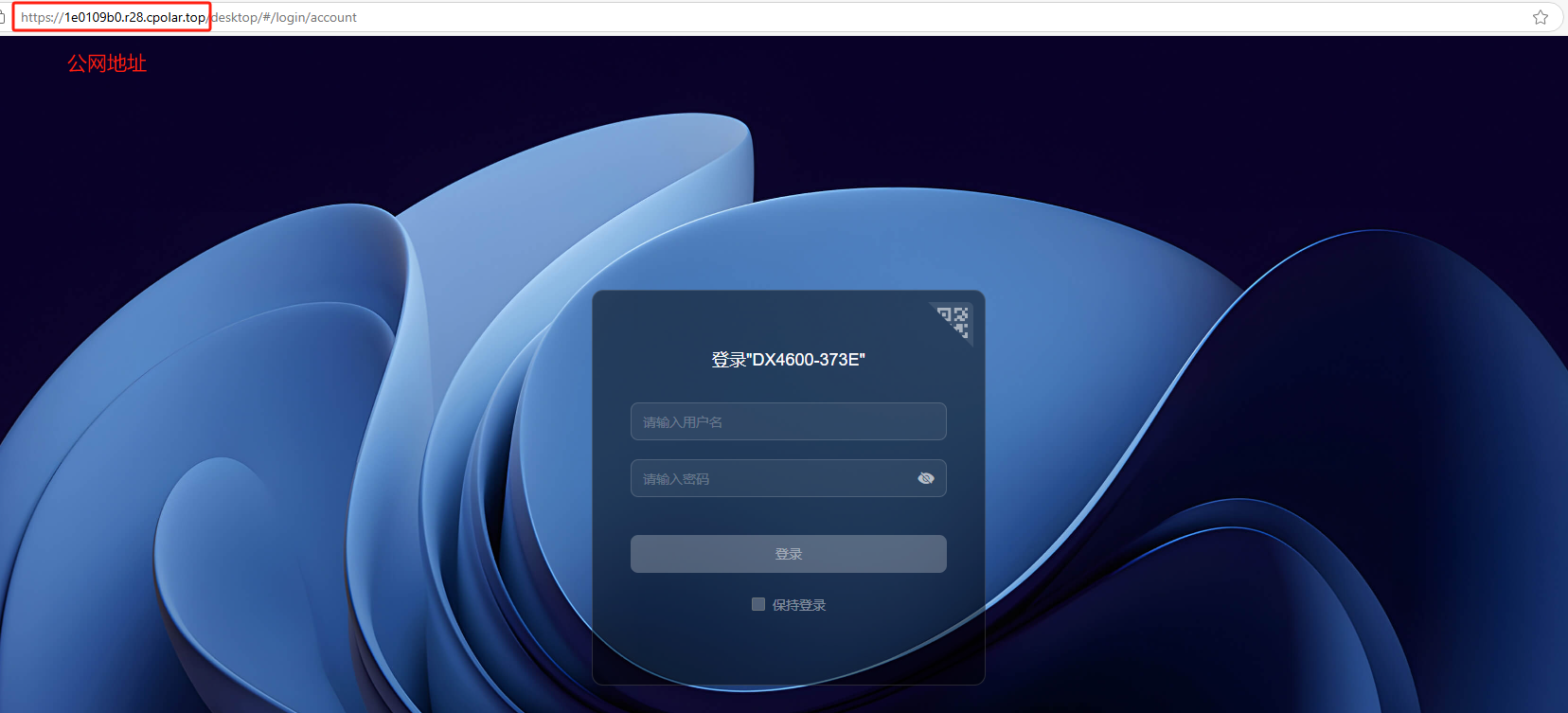
如下图所示,现在就已经成功实现使用cpolar生成的公网地址随时随地远程访问本地的绿联NAS进行管理了。











![[Python人工智能] 四十九.PyTorch入门 (4)利用基础模块构建神经网络并实现分类预测](https://i-blog.csdnimg.cn/blog_migrate/d7f85c976b50a7792f5b855305bcc930.png#pic_center)







