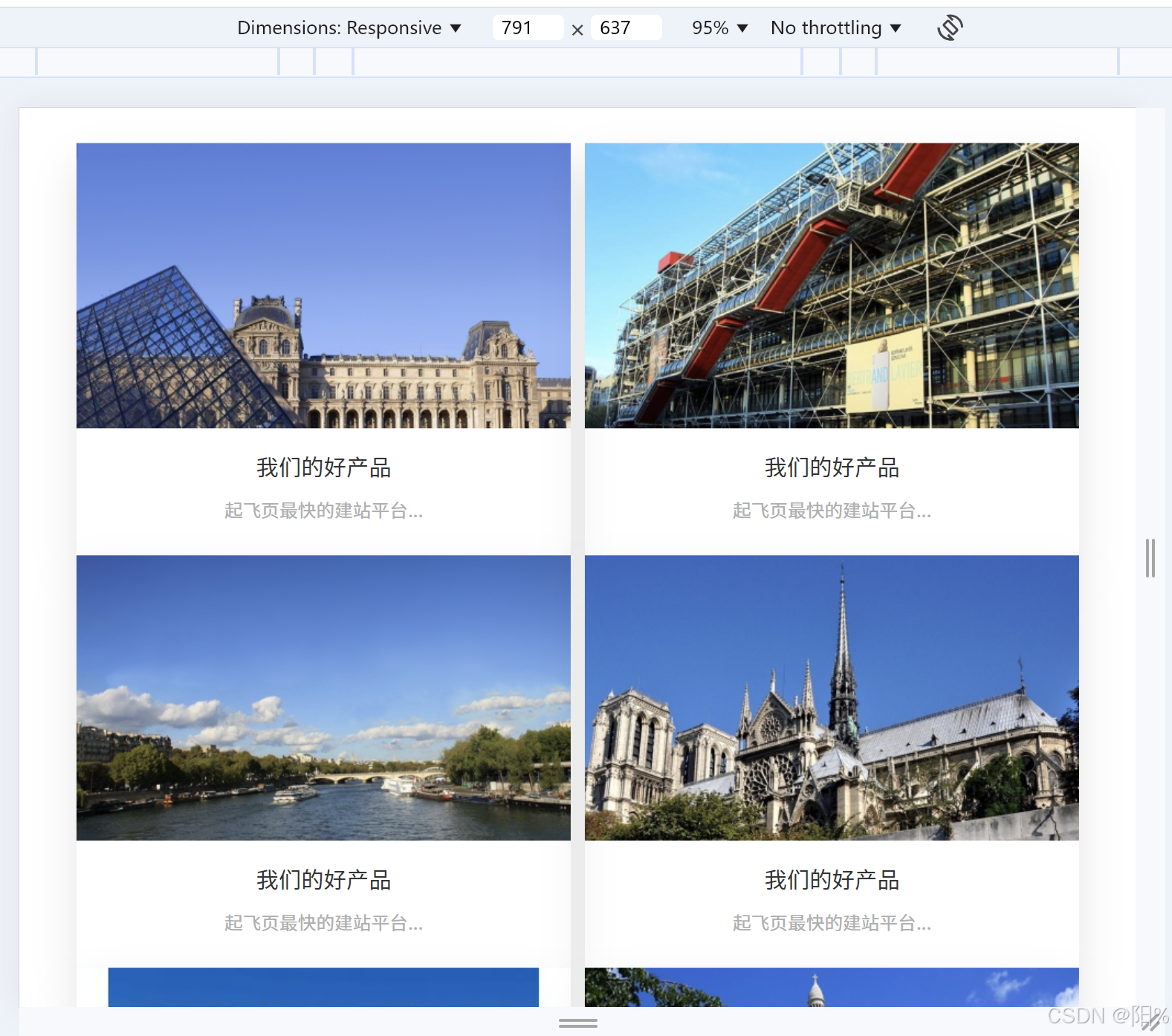
图:


代码:
index.html
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>My UI Library</title><link rel="stylesheet" href="styles/main.css"><!-- 添加图标库 --><link rel="stylesheet" href="icons/bootstrap-icons.css"><style>body {margin: 0;padding-top: 0;}.demo-section {padding: 20px;border-bottom: 1px solid var(--border-color);}.demo-section h2 {margin-bottom: 20px;color: var(--text-primary);}.demo-item {margin: 10px 0;}.demo-item > * {margin-right: 10px;margin-bottom: 10px;}.demo-card-container1 { /* 新增的容器类 */display: grid; /* 使用网格布局 */grid-template-columns: repeat(auto-fill, minmax(300px, 1fr)); /* 自动填充,最小宽度300px,最大宽度1fr */gap: 20px; /* 设置网格项之间的间隙 */padding: 10px; /* 设置容器内边距 */}</style>
</head>
<body><!-- 导航栏 --><nav class="my-navbar"><a href="#" class="my-navbar__brand">My UI</a><ul class="my-navbar__nav"><li class="my-navbar__item is-active">首页</li><li class="my-navbar__item my-navbar__dropdown">组件<div class="my-navbar__dropdown-menu"><div class="my-navbar__dropdown-item"><a href="#buttons" >按钮</a></div><div class="my-navbar__dropdown-item"><a href="#input" >输入框</a></div><div class="my-navbar__dropdown-item"><a href="#card" >卡片</a></div><div class="my-navbar__dropdown-item"><a href="#dialog" >弹出框</a></div><div class="my-navbar__dropdown-item"><a href="#navbar" >导航栏</a></div><div class="my-navbar__dropdown-item"><a href="#table" >表格</a></div><div class="my-navbar__dropdown-item"><a href="#pagination" >分页</a></div><div class="my-navbar__dropdown-item"><a href="#datepicker" >日期选择器</a></div><div class="my-navbar__dropdown-item"><a href="#number-input" >数字输入框</a></div><!-- 底部 --><div class="my-navbar__dropdown-item"><a href="#footer" >底部</a></div></div></li><li class="my-navbar__item"><a href="emoji.html" >🌞Emoji 图标库</a></li><li class="my-navbar__item"><a href="icons/icons.html" >🎭Icons 图标库</a></li><li class="my-navbar__item">关于</li></ul><div class="my-navbar__search"><input type="text" class="my-navbar__search-input" placeholder="搜索..."><i class="bi bi-search my-navbar__search-icon"></i></div><div class="my-navbar__right"><div class="my-navbar__item my-navbar__dropdown"><i class="bi bi-person-circle"></i> 用户<div class="my-navbar__dropdown-menu"><div class="my-navbar__dropdown-item">个人中心</div><div class="my-navbar__dropdown-item">设置</div><div class="my-navbar__dropdown-item" style="color: var(--danger-color);">退出登录</div></div></div><div class="my-navbar__item "><i class="bi bi-github"></i></div></div><div class="my-navbar__toggle"><i class="bi bi-list"></i></div></nav><div class="demo-section" id="buttons"><h2>按钮 Buttons</h2><!-- 基础按钮 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础按钮</div></div><div class="my-card__body"><div class="demo-item"><button class="my-button">默认按钮</button><button class="my-button my-button--primary">主要按钮</button><button class="my-button my-button--success">成功按钮</button><button class="my-button my-button--warning">警告按钮</button><button class="my-button my-button--danger">危险按钮</button></div><!-- 添加代码展示区域 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础按钮示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><button class="my-button">默认按钮</button>
<button class="my-button my-button--primary">主要按钮</button>
<button class="my-button my-button--success">成功按钮</button>
<button class="my-button my-button--warning">警告按钮</button>
<button class="my-button my-button--danger">危险按钮</button></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-button {display: inline-flex;justify-content: center;align-items: center;line-height: 1;height: 32px;white-space: nowrap;cursor: pointer;color: var(--text-regular);text-align: center;box-sizing: border-box;outline: none;transition: .1s;font-weight: 500;padding: 8px 15px;font-size: 14px;border-radius: 4px;border: 1px solid var(--border-color);background-color: var(--background-color);
}.my-button--primary {color: #fff;background-color: var(--primary-color);border-color: var(--primary-color);
}.my-button--success {color: #fff;background-color: var(--success-color);border-color: var(--success-color);
}.my-button--warning {color: #fff;background-color: var(--warning-color);border-color: var(--warning-color);
}.my-button--danger {color: #fff;background-color: var(--danger-color);border-color: var(--danger-color);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 按钮组 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">按钮组</div></div><div class="my-card__body"><!-- 基础按钮组 --><div class="demo-item"><div class="my-button-group"><button class="my-button">左边</button><button class="my-button">中间</button><button class="my-button">右边</button></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础按钮组</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-button-group"><button class="my-button">左边</button><button class="my-button">中间</button><button class="my-button">右边</button>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-button-group {display: inline-flex;vertical-align: middle;
}.my-button-group .my-button {position: relative;margin: 0;border-radius: 0;
}.my-button-group .my-button:not(:first-child) {margin-left: -1px;
}.my-button-group .my-button:first-child {border-top-left-radius: 4px;border-bottom-left-radius: 4px;
}.my-button-group .my-button:last-child {border-top-right-radius: 4px;border-bottom-right-radius: 4px;
}.my-button-group .my-button:hover {z-index: 1;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div><!-- 不同颜色的按钮组 --><div class="demo-item"><div class="my-button-group"><button class="my-button my-button--primary">编辑</button><button class="my-button my-button--success">保存</button><button class="my-button my-button--danger">删除</button></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">不同颜色的按钮组</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-button-group"><button class="my-button my-button--primary">编辑</button><button class="my-button my-button--success">保存</button><button class="my-button my-button--danger">删除</button>
</div></code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div><!-- 带图标的按钮组 --><div class="demo-item"><div class="my-button-group"><button class="my-button"><i class="bi bi-arrow-left"></i>上一页</button><button class="my-button">下一页<i class="bi bi-arrow-right"></i></button></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">带图标的按钮组</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-button-group"><button class="my-button"><i class="bi bi-arrow-left"></i>上一页</button><button class="my-button">下一页<i class="bi bi-arrow-right"></i></button>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-button-group .my-button i {font-size: 14px;vertical-align: middle;
}.my-button-group .my-button i:first-child:not(:last-child) {margin-right: 5px;
}.my-button-group .my-button i:last-child:not(:first-child) {margin-left: 5px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div><!-- 圆角按钮组 --><div class="demo-item"><div class="my-button-group my-button-group--round"><button class="my-button my-button--primary">选项1</button><button class="my-button my-button--primary">选项2</button><button class="my-button my-button--primary">选项3</button></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">圆角按钮组</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-button-group my-button-group--round"><button class="my-button my-button--primary">选项1</button><button class="my-button my-button--primary">选项2</button><button class="my-button my-button--primary">选项3</button>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-button-group--round .my-button:first-child {border-top-left-radius: 20px;border-bottom-left-radius: 20px;
}.my-button-group--round .my-button:last-child {border-top-right-radius: 20px;border-bottom-right-radius: 20px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div><!-- 垂直按钮组 --><div class="demo-item"><div class="my-button-group my-button-group--vertical"><button class="my-button">上传<i class="bi bi-upload" style="margin-left: 5px;"></i></button><button class="my-button">下载<i class="bi bi-download" style="margin-left: 5px;"></i></button><button class="my-button">分享<i class="bi bi-share" style="margin-left: 5px;"></i></button></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">垂直按钮组</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-button-group my-button-group--vertical"><button class="my-button">上传<i class="bi bi-upload" style="margin-left: 5px;"></i></button><button class="my-button">下载<i class="bi bi-download" style="margin-left: 5px;"></i></button><button class="my-button">分享<i class="bi bi-share" style="margin-left: 5px;"></i></button>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-button-group--vertical {display: inline-flex;flex-direction: column;vertical-align: middle;
}.my-button-group--vertical .my-button {margin: 0;border-radius: 0;
}.my-button-group--vertical .my-button:not(:first-child) {margin-top: -1px;margin-left: 0;
}.my-button-group--vertical .my-button:first-child {border-top-left-radius: 4px;border-top-right-radius: 4px;
}.my-button-group--vertical .my-button:last-child {border-bottom-left-radius: 4px;border-bottom-right-radius: 4px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 其他按钮样式 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">其他按钮样式</div></div><div class="my-card__body"><!-- 圆角和禁用按钮 --><div class="demo-item"><button class="my-button my-button--primary my-button--round">圆角按钮</button><button class="my-button my-button--primary is-disabled">禁用按钮</button></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">圆角和禁用按钮</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><button class="my-button my-button--primary my-button--round">圆角按钮</button>
<button class="my-button my-button--primary is-disabled">禁用按钮</button></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 圆角按钮 */
.my-button--round {border-radius: 20px;
}/* 禁用状态 */
.my-button.is-disabled {cursor: not-allowed;opacity: 0.5;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div><!-- 不同尺寸按钮 --><div class="demo-item"><button class="my-button my-button--primary my-button--large">大型按钮</button><button class="my-button my-button--primary">默认按钮</button><button class="my-button my-button--primary my-button--small">小型按钮</button></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">不同尺寸按钮</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><button class="my-button my-button--primary my-button--large">大型按钮</button>
<button class="my-button my-button--primary">默认按钮</button>
<button class="my-button my-button--primary my-button--small">小型按钮</button></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 按钮尺寸 */
.my-button--large {height: 40px;padding: 12px 19px;font-size: 14px;
}.my-button {height: 32px;padding: 8px 15px;font-size: 14px;
}.my-button--small {height: 24px;padding: 5px 11px;font-size: 12px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div><!-- 带图标的按钮 --><div class="demo-item"><button class="my-button my-button--primary"><i class="bi bi-search" style="margin-right: 5px;"></i>搜索</button><button class="my-button my-button--success">上传<i class="bi bi-upload" style="margin-left: 5px;"></i></button><button class="my-button my-button--warning"><i class="bi bi-bell" style="margin-right: 5px;"></i>提醒</button></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">带图标的按钮</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><button class="my-button my-button--primary"><i class="bi bi-search" style="margin-right: 5px;"></i>搜索
</button>
<button class="my-button my-button--success">上传<i class="bi bi-upload" style="margin-left: 5px;"></i>
</button>
<button class="my-button my-button--warning"><i class="bi bi-bell" style="margin-right: 5px;"></i>提醒
</button></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-button {display: inline-flex;justify-content: center;align-items: center;
}.my-button i {font-size: 14px;line-height: 1;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div></div><!-- 输入框 Input --><div class="demo-section" id="input"><h2>输入框 Input</h2><!-- 基础输入框 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础输入框</div></div><div class="my-card__body"><div class="demo-item" style="max-width: 300px;"><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入内容"></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础输入框示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入内容">
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-input {position: relative;font-size: 14px;display: inline-block;width: 100%;
}.my-input__inner {background-color: var(--background-color);border-radius: 4px;border: 1px solid var(--border-color);box-sizing: border-box;color: var(--text-regular);display: inline-block;font-size: inherit;height: 32px;line-height: 32px;outline: none;padding: 0 15px;transition: border-color .2s;width: 100%;
}.my-input__inner:hover {border-color: var(--text-secondary);
}.my-input__inner:focus {border-color: var(--primary-color);outline: none;
}.my-input__inner::placeholder {color: var(--text-placeholder);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 禁用状态 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">禁用状态</div></div><div class="my-card__body"><div class="demo-item" style="max-width: 300px;"><div class="my-input is-disabled"><input type="text" class="my-input__inner" placeholder="禁用状态" disabled></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">禁用状态示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-input is-disabled"><input type="text" class="my-input__inner" placeholder="禁用状态" disabled>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 禁用状态 */
.my-input.is-disabled .my-input__inner {background-color: var(--background-color-light);border-color: var(--border-color);color: var(--text-placeholder);cursor: not-allowed;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 不同尺寸 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">不同尺寸</div></div><div class="my-card__body"><div style="display: flex; gap: 20px; align-items: center;"><div class="my-input my-input--large" style="margin-bottom: 16px;"><input type="text" class="my-input__inner" placeholder="大型输入框"></div><div class="my-input" style="margin-bottom: 16px;"><input type="text" class="my-input__inner" placeholder="默认输入框"></div><div class="my-input my-input--small"><input type="text" class="my-input__inner" placeholder="小型输入框"></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">不同尺寸示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-input my-input--large"><input type="text" class="my-input__inner" placeholder="大型输入框">
</div><div class="my-input"><input type="text" class="my-input__inner" placeholder="默认输入框">
</div><div class="my-input my-input--small"><input type="text" class="my-input__inner" placeholder="小型输入框">
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 尺寸 */
.my-input--large .my-input__inner {height: 40px;line-height: 40px;font-size: 14px;
}.my-input .my-input__inner {height: 32px;line-height: 32px;font-size: 14px;
}.my-input--small .my-input__inner {height: 24px;line-height: 24px;font-size: 12px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div></div><!-- 卡片 Card --><div class="demo-section" id="card"><h2>卡片 Card</h2><div class="demo-card-container"><!-- 基础卡片 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础卡片</div></div><div class="my-card__body">这是一个基础卡片的内容区域。你可以在这里放置任何内容。</div></div><!-- 简单卡片 --><div class="my-card my-card--simple"><div class="my-card__body">这是一个没有标题的简单卡片。适合展示简单的内容。</div></div><!-- 无边框卡片 --><div class="my-card my-card--borderless"><div class="my-card__header"><div class="my-card__title">无边框卡片</div></div><div class="my-card__body">这是一个无边框卡片,默认具有阴影效果。</div></div><!-- 悬浮效果卡片 --><div class="my-card my-card--hover"><div class="my-card__header"><div class="my-card__title">悬浮效果卡片</div></div><div class="my-card__body">鼠标悬浮时会有上浮动画效果和更明显的阴影。</div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础卡片示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><!-- 基础卡片 -->
<div class="my-card"><div class="my-card__header"><div class="my-card__title">基础卡片</div></div><div class="my-card__body">这是一个基础卡片的内容区域。你可以在这里放置任何内容。</div>
</div><!-- 简单卡片 -->
<div class="my-card my-card--simple"><div class="my-card__body">这是一个没有标题的简单卡片。适合展示简单的内容。</div>
</div><!-- 无边框卡片 -->
<div class="my-card my-card--borderless"><div class="my-card__header"><div class="my-card__title">无边框卡片</div></div><div class="my-card__body">这是一个无边框卡片,默认具有阴影效果。</div>
</div><!-- 悬浮效果卡片 -->
<div class="my-card my-card--hover"><div class="my-card__header"><div class="my-card__title">悬浮效果卡片</div></div><div class="my-card__body">鼠标悬浮时会有上浮动画效果和更明显的阴影。</div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-card {border-radius: 4px;border: 1px solid var(--border-color-light);background-color: var(--background-color);overflow: hidden;color: var(--text-regular);transition: .3s;
}.my-card:hover {box-shadow: 0 2px 12px 0 rgba(0,0,0,.1);
}.my-card__header {padding: 18px 20px;border-bottom: 1px solid var(--border-color-light);box-sizing: border-box;
}.my-card__title {font-size: 16px;font-weight: bold;color: var(--text-primary);line-height: 1.5;
}.my-card__body {padding: 20px;
}/* 无边框卡片 */
.my-card--borderless {border: none;box-shadow: 0 2px 12px 0 rgba(0,0,0,.1);
}/* 简单卡片 */
.my-card--simple {border: none;
}/* 悬浮效果增强 */
.my-card--hover:hover {transform: translateY(-4px);box-shadow: 0 4px 16px rgba(0,0,0,.1);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div><!-- Bootstrap风格卡片 --><h3 style="margin-top: 30px;">Bootstrap风格卡片</h3><div class="demo-card-container"><!-- 图片卡片 --><div class="my-card my-card--hover"><img src="https://picsum.photos/300/200" class="my-card__image" alt="卡片图片"><div class="my-card__body"><div class="my-card__title">图片卡片</div><div class="my-card__subtitle">副标题</div><p class="my-card__text">这是一个带有图片的卡片示例。图片会自动适应卡片宽度,并保持适当的比例。</p><button class="my-button my-button--primary">查看详情</button></div></div><!-- 列表卡片 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">特色列表</div></div><ul class="my-card__list"><li class="my-card__list-item">响应式布局设计</li><li class="my-card__list-item">现代化的交互效果</li><li class="my-card__list-item">统一的设计风格</li><li class="my-card__list-item">丰富的组件类型</li></ul></div><!-- 带页脚的卡片 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">项目介绍</div></div><div class="my-card__body"><p class="my-card__text">这是一个模仿Element Plus设计的UI组件库,采用现代化的设计理念,提供了丰富的组件和样式选项。</p><button class="my-button">取消</button><button class="my-button my-button--primary">确定</button></div><div class="my-card__footer">最后更新于 2024-01-20</div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">Bootstrap风格卡片示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><!-- 图片卡片 -->
<div class="my-card my-card--hover"><img src="https://picsum.photos/300/200" class="my-card__image" alt="卡片图片"><div class="my-card__body"><div class="my-card__title">图片卡片</div><div class="my-card__subtitle">副标题</div><p class="my-card__text">这是一个带有图片的卡片示例。</p><button class="my-button my-button--primary">查看详情</button></div>
</div><!-- 列表卡片 -->
<div class="my-card"><div class="my-card__header"><div class="my-card__title">特色列表</div></div><ul class="my-card__list"><li class="my-card__list-item">响应式布局设计</li><li class="my-card__list-item">现代化的交互效果</li><li class="my-card__list-item">统一的设计风格</li><li class="my-card__list-item">丰富的组件类型</li></ul>
</div><!-- 带页脚的卡片 -->
<div class="my-card"><div class="my-card__header"><div class="my-card__title">项目介绍</div></div><div class="my-card__body"><p class="my-card__text">这是一个模仿Element Plus设计的UI组件库。</p><button class="my-button">取消</button><button class="my-button my-button--primary">确定</button></div><div class="my-card__footer">最后更新于 2024-01-20</div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 卡片图片样式 */
.my-card__image {width: 100%;height: 200px;object-fit: cover;
}/* 卡片列表样式 */
.my-card__list {list-style: none;padding: 0;margin: 0;
}.my-card__list-item {padding: 12px 20px;border-bottom: 1px solid var(--border-color-light);
}.my-card__list-item:last-child {border-bottom: none;
}/* 卡片页脚样式 */
.my-card__footer {padding: 12px 20px;background-color: var(--background-color-light);border-top: 1px solid var(--border-color-light);
}/* 卡片文本样式 */
.my-card__text {margin-bottom: 15px;line-height: 1.5;
}.my-card__subtitle {color: var(--text-secondary);font-size: 14px;margin-top: 5px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div><!-- 添加表格部分 --><div class="demo-section" id="table"><h2>表格 Table</h2><!-- 基础表格 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础表格</div></div><div class="my-card__body"><table class="my-table"><thead><tr><th>ID</th><th>姓名</th><th>职位</th><th>部门</th><th>操作</th></tr></thead><tbody><tr><td>1</td><td>张三</td><td>前端工程师</td><td>技术部</td><td><button class="my-button my-button--small my-button--primary">编辑</button><button class="my-button my-button--small my-button--danger">删除</button></td></tr><tr><td>2</td><td>李四</td><td>UI设计师</td><td>设计部</td><td><button class="my-button my-button--small my-button--primary">编辑</button><button class="my-button my-button--small my-button--danger">删除</button></td></tr><tr><td>3</td><td>王五</td><td>产品经理</td><td>产品部</td><td><button class="my-button my-button--small my-button--primary">编辑</button><button class="my-button my-button--small my-button--danger">删除</button></td></tr></tbody></table><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础表格示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><table class="my-table"><thead><tr><th>ID</th><th>姓名</th><th>职位</th><th>部门</th><th>操作</th></tr></thead><tbody><tr><td>1</td><td>张三</td><td>前端工程师</td><td>技术部</td><td><button class="my-button my-button--small my-button--primary">编辑</button><button class="my-button my-button--small my-button--danger">删除</button></td></tr>...</tbody>
</table></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-table {width: 100%;border-collapse: collapse;background-color: var(--background-color);font-size: 14px;margin-bottom: 20px;
}.my-table th,
.my-table td {padding: 12px 15px;text-align: left;border-bottom: 1px solid var(--border-color-light);
}.my-table th {font-weight: bold;color: var(--text-primary);background-color: var(--background-color-light);
}.my-table tbody tr {transition: .3s;
}.my-table tbody tr:hover {background-color: var(--background-color-light);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 斑马纹表格 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">斑马纹表格</div></div><div class="my-card__body"><table class="my-table my-table--striped"><thead><tr><th>订单号</th><th>商品名称</th><th>价格</th><th>状态</th><th>下单时间</th></tr></thead><tbody><tr class="my-table__row--success"><td>2024010101</td><td>商品A</td><td>¥199.00</td><td>已完成</td><td>2024-01-01 10:00</td></tr><tr class="my-table__row--warning"><td>2024010102</td><td>商品B</td><td>¥299.00</td><td>处理中</td><td>2024-01-01 11:00</td></tr><tr class="my-table__row--danger"><td>2024010103</td><td>商品C</td><td>¥399.00</td><td>已取消</td><td>2024-01-01 12:00</td></tr></tbody></table><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">斑马纹表格示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><table class="my-table my-table--striped"><thead><tr><th>订单号</th><th>商品名称</th><th>价格</th><th>状态</th><th>下单时间</th></tr></thead><tbody><tr class="my-table__row--success"><td>2024010101</td><td>商品A</td><td>¥199.00</td><td>已完成</td><td>2024-01-01 10:00</td></tr>...</tbody>
</table></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 斑马纹表格 */
.my-table--striped tbody tr:nth-child(even) {background-color: var(--background-color-light);
}.my-table--striped tbody tr:hover {background-color: #f0f2f5;
}/* 状态样式 */
.my-table__row--success {background-color: rgba(103, 194, 58, 0.1);
}.my-table__row--warning {background-color: rgba(230, 162, 60, 0.1);
}.my-table__row--danger {background-color: rgba(245, 108, 108, 0.1);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 带边框的表格 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">带边框的表格</div></div><div class="my-card__body"><table class="my-table my-table--bordered"><thead><tr><th>项目</th><th>完成度</th><th>负责人</th><th>截止日期</th></tr></thead><tbody><tr><td>UI设计</td><td>90%</td><td>张三</td><td>2024-02-01</td></tr><tr><td>前端开发</td><td>70%</td><td>李四</td><td>2024-02-15</td></tr><tr><td>后端开发</td><td>60%</td><td>王五</td><td>2024-03-01</td></tr></tbody></table><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">带边框的表格示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><table class="my-table my-table--bordered"><thead><tr><th>项目</th><th>完成度</th><th>负责人</th><th>截止日期</th></tr></thead><tbody><tr><td>UI设计</td><td>90%</td><td>张三</td><td>2024-02-01</td></tr>...</tbody>
</table></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 带边框的表格 */
.my-table--bordered {border: 1px solid var(--border-color-light);
}.my-table--bordered th,
.my-table--bordered td {border: 1px solid var(--border-color-light);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 固定表头 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">固定表头</div></div><div class="my-card__body"><div class="my-table-wrapper"><table class="my-table my-table--fixed-header"><thead><tr><th>序号</th><th>姓名</th><th>年龄</th><th>性别</th><th>城市</th></tr></thead><tbody><tr><td>1</td><td>张三</td><td>25</td><td>男</td><td>北京</td></tr><tr><td>2</td><td>李四</td><td>28</td><td>女</td><td>上海</td></tr><tr><td>3</td><td>王五</td><td>30</td><td>男</td><td>广州</td></tr><tr><td>4</td><td>赵六</td><td>22</td><td>女</td><td>深圳</td></tr><tr><td>5</td><td>钱七</td><td>35</td><td>男</td><td>杭州</td></tr></tbody></table></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">固定表头示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-table-wrapper"><table class="my-table my-table--fixed-header"><thead><tr><th>序号</th><th>姓名</th><th>年龄</th><th>性别</th><th>城市</th></tr></thead><tbody>...</tbody></table>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 固定表头 */
.my-table-wrapper {max-height: 400px;overflow: auto;
}.my-table--fixed-header {position: relative;
}.my-table--fixed-header thead th {position: sticky;top: 0;z-index: 1;background-color: var(--background-color-light);
}/* 响应式表格 */
@media screen and (max-width: 768px) {.my-table-wrapper {overflow-x: auto;}.my-table {min-width: 600px;}
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div></div><!-- 添加分页部分 --><div class="demo-section" id="pagination"><h2>分页 Pagination</h2><!-- 基础分页 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础分页</div></div><div class="my-card__body"><div class="my-pagination"><div class="my-pagination__item my-pagination__item--prev is-disabled"><i class="bi bi-chevron-left"></i></div><div class="my-pagination__item is-active">1</div><div class="my-pagination__item">2</div><div class="my-pagination__item">3</div><div class="my-pagination__item">4</div><div class="my-pagination__item">5</div><div class="my-pagination__item my-pagination__item--next"><i class="bi bi-chevron-right"></i></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础分页示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-pagination"><div class="my-pagination__item my-pagination__item--prev is-disabled"><i class="bi bi-chevron-left"></i></div><div class="my-pagination__item is-active">1</div><div class="my-pagination__item">2</div><div class="my-pagination__item">3</div><div class="my-pagination__item">4</div><div class="my-pagination__item">5</div><div class="my-pagination__item my-pagination__item--next"><i class="bi bi-chevron-right"></i></div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-pagination {display: flex;align-items: center;justify-content: center;gap: 8px;margin: 20px 0;
}.my-pagination__item {min-width: 32px;height: 32px;padding: 0 4px;display: flex;align-items: center;justify-content: center;border: 1px solid var(--border-color);border-radius: 4px;background-color: #fff;color: var(--text-primary);font-size: 14px;cursor: pointer;transition: all 0.3s;user-select: none;
}.my-pagination__item:hover {color: var(--primary-color);border-color: var(--primary-color);
}.my-pagination__item.is-active {background-color: var(--primary-color);color: #fff;border-color: var(--primary-color);
}.my-pagination__item.is-disabled {cursor: not-allowed;color: var(--text-disabled);background-color: var(--background-color-light);border-color: var(--border-color);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 带省略号的分页 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">带省略号的分页</div></div><div class="my-card__body"><div class="my-pagination"><div class="my-pagination__item my-pagination__item--prev"><i class="bi bi-chevron-left"></i></div><div class="my-pagination__item">1</div><div class="my-pagination__item my-pagination__item--more">...</div><div class="my-pagination__item">4</div><div class="my-pagination__item is-active">5</div><div class="my-pagination__item">6</div><div class="my-pagination__item my-pagination__item--more">...</div><div class="my-pagination__item">10</div><div class="my-pagination__item my-pagination__item--next"><i class="bi bi-chevron-right"></i></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">带省略号的分页示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-pagination"><div class="my-pagination__item my-pagination__item--prev"><i class="bi bi-chevron-left"></i></div><div class="my-pagination__item">1</div><div class="my-pagination__item my-pagination__item--more">...</div><div class="my-pagination__item">4</div><div class="my-pagination__item is-active">5</div><div class="my-pagination__item">6</div><div class="my-pagination__item my-pagination__item--more">...</div><div class="my-pagination__item">10</div><div class="my-pagination__item my-pagination__item--next"><i class="bi bi-chevron-right"></i></div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-pagination__item--prev,
.my-pagination__item--next {font-size: 12px;
}.my-pagination__item--more {border: none;background: none;cursor: default;
}.my-pagination__item--more:hover {color: var(--text-primary);border: none;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 禁用状态 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">禁用状态</div></div><div class="my-card__body"><div class="my-pagination"><div class="my-pagination__item my-pagination__item--prev is-disabled"><i class="bi bi-chevron-left"></i></div><div class="my-pagination__item is-disabled">1</div><div class="my-pagination__item is-disabled">2</div><div class="my-pagination__item is-disabled">3</div><div class="my-pagination__item my-pagination__item--next is-disabled"><i class="bi bi-chevron-right"></i></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">禁用状态示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-pagination"><div class="my-pagination__item my-pagination__item--prev is-disabled"><i class="bi bi-chevron-left"></i></div><div class="my-pagination__item is-disabled">1</div><div class="my-pagination__item is-disabled">2</div><div class="my-pagination__item is-disabled">3</div><div class="my-pagination__item my-pagination__item--next is-disabled"><i class="bi bi-chevron-right"></i></div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-pagination__item.is-disabled {cursor: not-allowed;color: var(--text-disabled);background-color: var(--background-color-light);border-color: var(--border-color);
}/* 响应式调整 */
@media (max-width: 768px) {.my-pagination {gap: 4px;}.my-pagination__item {min-width: 28px;height: 28px;font-size: 12px;}
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div></div><!-- 添加日期选择器部分 --><div class="demo-section" id="datepicker"><h2>日期选择器 DatePicker</h2><!-- 基础日期选择器 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础日期选择器</div></div><div class="my-card__body"><div class="my-datepicker"><input type="text" class="my-datepicker__input" placeholder="选择日期" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i></div><div class="my-datepicker__panel" style="position: static; margin-top: 20px;"><div class="my-datepicker__header"><div class="my-datepicker__arrow"><i class="bi bi-chevron-left"></i></div><div class="my-datepicker__current-month">2024年1月</div><div class="my-datepicker__arrow"><i class="bi bi-chevron-right"></i></div></div><div class="my-datepicker__weekdays"><div class="my-datepicker__weekday">日</div><div class="my-datepicker__weekday">一</div><div class="my-datepicker__weekday">二</div><div class="my-datepicker__weekday">三</div><div class="my-datepicker__weekday">四</div><div class="my-datepicker__weekday">五</div><div class="my-datepicker__weekday">六</div></div><div class="my-datepicker__days"><div class="my-datepicker__day is-other-month">31</div><div class="my-datepicker__day">1</div><div class="my-datepicker__day">2</div><div class="my-datepicker__day">3</div><div class="my-datepicker__day">4</div><div class="my-datepicker__day">5</div><div class="my-datepicker__day">6</div><div class="my-datepicker__day">7</div><div class="my-datepicker__day">8</div><div class="my-datepicker__day">9</div><div class="my-datepicker__day is-today">10</div><div class="my-datepicker__day">11</div><div class="my-datepicker__day">12</div><div class="my-datepicker__day">13</div><div class="my-datepicker__day">14</div><div class="my-datepicker__day is-selected">15</div><div class="my-datepicker__day">16</div><div class="my-datepicker__day">17</div><div class="my-datepicker__day">18</div><div class="my-datepicker__day">19</div><div class="my-datepicker__day">20</div><div class="my-datepicker__day">21</div><div class="my-datepicker__day">22</div><div class="my-datepicker__day">23</div><div class="my-datepicker__day">24</div><div class="my-datepicker__day">25</div><div class="my-datepicker__day">26</div><div class="my-datepicker__day">27</div><div class="my-datepicker__day">28</div><div class="my-datepicker__day">29</div><div class="my-datepicker__day">30</div><div class="my-datepicker__day">31</div><div class="my-datepicker__day is-other-month">1</div><div class="my-datepicker__day is-other-month">2</div><div class="my-datepicker__day is-other-month">3</div></div><div class="my-datepicker__footer"><button class="my-datepicker__btn">取消</button><button class="my-datepicker__btn my-datepicker__btn--primary">确定</button></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础日期选择器示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-datepicker"><input type="text" class="my-datepicker__input" placeholder="选择日期" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i>
</div>
<div class="my-datepicker__panel"><div class="my-datepicker__header"><div class="my-datepicker__arrow"><i class="bi bi-chevron-left"></i></div><div class="my-datepicker__current-month">2024年1月</div><div class="my-datepicker__arrow"><i class="bi bi-chevron-right"></i></div></div><div class="my-datepicker__weekdays"><div class="my-datepicker__weekday">日</div><div class="my-datepicker__weekday">一</div><div class="my-datepicker__weekday">二</div><div class="my-datepicker__weekday">三</div><div class="my-datepicker__weekday">四</div><div class="my-datepicker__weekday">五</div><div class="my-datepicker__weekday">六</div></div><div class="my-datepicker__days">...</div><div class="my-datepicker__footer"><button class="my-datepicker__btn">取消</button><button class="my-datepicker__btn my-datepicker__btn--primary">确定</button></div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-datepicker {position: relative;display: inline-block;
}.my-datepicker__input {width: 200px;height: 32px;padding: 0 30px 0 12px;border: 1px solid var(--border-color);border-radius: 4px;font-size: 14px;color: var(--text-primary);background-color: #fff;cursor: pointer;transition: all 0.3s;
}.my-datepicker__panel {position: absolute;top: calc(100% + 4px);left: 0;z-index: 1000;width: 280px;background-color: #fff;border: 1px solid var(--border-color);border-radius: 4px;box-shadow: 0 2px 12px rgba(0, 0, 0, 0.1);padding: 8px;
}.my-datepicker__day {height: 32px;display: flex;align-items: center;justify-content: center;font-size: 14px;cursor: pointer;border-radius: 4px;transition: all 0.3s;
}.my-datepicker__day.is-selected {background-color: var(--primary-color);color: #fff;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 禁用状态 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">禁用状态</div></div><div class="my-card__body"><div class="my-datepicker"><input type="text" class="my-datepicker__input" placeholder="选择日期" readonly disabled><i class="bi bi-calendar3 my-datepicker__icon"></i></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">禁用状态示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-datepicker"><input type="text" class="my-datepicker__input" placeholder="选择日期" readonly disabled><i class="bi bi-calendar3 my-datepicker__icon"></i>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-datepicker__input:disabled {background-color: var(--background-color-light);border-color: var(--border-color);color: var(--text-disabled);cursor: not-allowed;
}.my-datepicker__input:disabled + .my-datepicker__icon {color: var(--text-disabled);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 不同尺寸 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">不同尺寸</div></div><div class="my-card__body"><div style="display: flex; gap: 20px; align-items: center;"><div class="my-datepicker"><input type="text" class="my-datepicker__input my-datepicker__input--large" placeholder="大型日期选择器" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i></div><div class="my-datepicker"><input type="text" class="my-datepicker__input" placeholder="默认尺寸" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i></div><div class="my-datepicker"><input type="text" class="my-datepicker__input my-datepicker__input--small" placeholder="小型日期选择器" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">不同尺寸示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-datepicker"><input type="text" class="my-datepicker__input my-datepicker__input--large" placeholder="大型日期选择器" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i>
</div><div class="my-datepicker"><input type="text" class="my-datepicker__input" placeholder="默认尺寸" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i>
</div><div class="my-datepicker"><input type="text" class="my-datepicker__input my-datepicker__input--small" placeholder="小型日期选择器" readonly><i class="bi bi-calendar3 my-datepicker__icon"></i>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-datepicker__input--large {height: 40px;font-size: 16px;padding: 0 35px 0 15px;
}.my-datepicker__input {height: 32px;font-size: 14px;padding: 0 30px 0 12px;
}.my-datepicker__input--small {height: 24px;font-size: 12px;padding: 0 25px 0 8px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div></div><!-- 添加数字输入框部分 --><div class="demo-section" id="number-input"><h2>数字输入框 NumberInput</h2><!-- 基础数字输入框 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础数字输入框</div></div><div class="my-card__body"><div class="my-number-input"><input type="number" class="my-number-input__inner" value="1" min="0" max="100"><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础数字输入框示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-number-input"><input type="number" class="my-number-input__inner" value="1" min="0" max="100"><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-number-input {position: relative;display: inline-flex;width: 180px;border: 1px solid var(--border-color);border-radius: 4px;overflow: hidden;transition: all 0.3s;
}.my-number-input:hover {border-color: var(--primary-color);
}.my-number-input:focus-within {border-color: var(--primary-color);box-shadow: 0 0 0 2px rgba(24, 144, 255, 0.2);
}.my-number-input__inner {flex: 1;width: 100%;height: 32px;padding: 0 8px;border: none;outline: none;font-size: 14px;color: var(--text-primary);text-align: center;
}.my-number-input__controls {display: flex;flex-direction: column;border-left: 1px solid var(--border-color);
}.my-number-input__up,
.my-number-input__down {display: flex;align-items: center;justify-content: center;width: 32px;height: 16px;cursor: pointer;background-color: var(--background-color-light);transition: all 0.3s;user-select: none;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 禁用状态 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">禁用状态</div></div><div class="my-card__body"><div class="my-number-input is-disabled"><input type="number" class="my-number-input__inner" value="1" disabled><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">禁用状态示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-number-input is-disabled"><input type="number" class="my-number-input__inner" value="1" disabled><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 禁用状态 */
.my-number-input.is-disabled {background-color: var(--background-color-light);border-color: var(--border-color);cursor: not-allowed;
}.my-number-input.is-disabled .my-number-input__inner {background-color: var(--background-color-light);color: var(--text-disabled);cursor: not-allowed;
}.my-number-input.is-disabled .my-number-input__up,
.my-number-input.is-disabled .my-number-input__down {cursor: not-allowed;background-color: var(--background-color-light);
}.my-number-input.is-disabled .my-number-input__icon {color: var(--text-disabled);
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 不同尺寸 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">不同尺寸</div></div><div class="my-card__body"><div style="display: flex; gap: 20px; align-items: center;"><div class="my-number-input my-number-input--large"><input type="number" class="my-number-input__inner" value="1"><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div></div><div class="my-number-input"><input type="number" class="my-number-input__inner" value="1"><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div></div><div class="my-number-input my-number-input--small"><input type="number" class="my-number-input__inner" value="1"><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">不同尺寸示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-number-input my-number-input--large"><input type="number" class="my-number-input__inner" value="1"><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div>
</div><div class="my-number-input"><!-- 默认尺寸 -->
</div><div class="my-number-input my-number-input--small"><!-- 小型尺寸 -->
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 尺寸变体 */
.my-number-input--large {width: 200px;
}.my-number-input--large .my-number-input__inner {height: 40px;font-size: 16px;
}.my-number-input--large .my-number-input__up,
.my-number-input--large .my-number-input__down {width: 40px;height: 20px;
}.my-number-input--small {width: 130px;
}.my-number-input--small .my-number-input__inner {height: 24px;font-size: 12px;
}.my-number-input--small .my-number-input__up,
.my-number-input--small .my-number-input__down {width: 24px;height: 12px;
}.my-number-input--small .my-number-input__icon {font-size: 10px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div></div><!-- 添加弹出框部分 --><div class="demo-section" id="dialog"><h2>弹出框 Dialog</h2><!-- 基础弹出框 --><div class="my-card"><div class="my-card__header"><div class="my-card__title">基础弹出框</div></div><div class="my-card__body"><button class="my-button my-button--primary" onclick="document.getElementById('basicDialog').style.display='flex'">打开弹出框</button><!-- 基础弹出框 --><div class="my-dialog__wrapper" id="basicDialog" style="display: none;"><div class="my-dialog__mask" onclick="document.getElementById('basicDialog').style.display='none'"></div><div class="my-dialog"><div class="my-dialog__header"><span class="my-dialog__title">提示</span><button class="my-dialog__close" onclick="document.getElementById('basicDialog').style.display='none'"><i class="bi bi-x"></i></button></div><div class="my-dialog__body">这是一个基础弹出框的内容区域。</div><div class="my-dialog__footer"><button class="my-button" onclick="document.getElementById('basicDialog').style.display='none'">取消</button><button class="my-button my-button--primary" onclick="document.getElementById('basicDialog').style.display='none'">确定</button></div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">基础弹出框示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><button class="my-button my-button--primary" onclick="document.getElementById('basicDialog').style.display='flex'">打开弹出框
</button><div class="my-dialog__wrapper" id="basicDialog" style="display: none;"><div class="my-dialog__mask" onclick="document.getElementById('basicDialog').style.display='none'"></div><div class="my-dialog"><div class="my-dialog__header"><span class="my-dialog__title">提示</span><button class="my-dialog__close" onclick="document.getElementById('basicDialog').style.display='none'"><i class="bi bi-x"></i></button></div><div class="my-dialog__body">这是一个基础弹出框的内容区域。</div><div class="my-dialog__footer"><button class="my-button" onclick="document.getElementById('basicDialog').style.display='none'">取消</button><button class="my-button my-button--primary" onclick="document.getElementById('basicDialog').style.display='none'">确定</button></div></div>
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-dialog__wrapper {position: fixed;top: 0;right: 0;bottom: 0;left: 0;z-index: 2000;display: flex;align-items: center;justify-content: center;
}.my-dialog__mask {position: fixed;top: 0;right: 0;bottom: 0;left: 0;background-color: rgba(0, 0, 0, 0.5);z-index: 2001;
}.my-dialog {position: relative;background: #fff;border-radius: 4px;box-shadow: 0 1px 3px rgba(0, 0, 0, 0.3);margin: 0 auto;width: 50%;max-width: 600px;z-index: 2002;
}.my-dialog__header {padding: 20px;padding-bottom: 10px;display: flex;justify-content: space-between;align-items: center;
}.my-dialog__title {line-height: 24px;font-size: 18px;color: #303133;font-weight: 500;
}.my-dialog__close {border: none;background: transparent;padding: 0;cursor: pointer;font-size: 20px;color: #909399;
}.my-dialog__body {padding: 30px 20px;color: #606266;font-size: 14px;word-break: break-all;
}.my-dialog__footer {padding: 20px;padding-top: 10px;text-align: right;
}.my-dialog__footer .my-button + .my-button {margin-left: 10px;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 不同尺寸 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">不同尺寸</div></div><div class="my-card__body"><button class="my-button" onclick="document.getElementById('smallDialog').style.display='flex'">小型弹出框</button><button class="my-button" onclick="document.getElementById('largeDialog').style.display='flex'" style="margin-left: 10px;">大型弹出框</button><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">不同尺寸示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><!-- 小型弹出框 -->
<div class="my-dialog my-dialog--small"><!-- 弹出框内容 -->
</div><!-- 大型弹出框 -->
<div class="my-dialog my-dialog--large"><!-- 弹出框内容 -->
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>.my-dialog--small {width: 30%;
}.my-dialog--large {width: 70%;
}/* 响应式布局 */
@media screen and (max-width: 768px) {.my-dialog,.my-dialog--small,.my-dialog--large {width: 90%;}
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 不同方向的弹出框 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">不同方向的弹出框</div></div><div class="my-card__body"><button class="my-button" onclick="document.getElementById('topDialog').style.display='flex'">顶部弹出</button><button class="my-button" onclick="document.getElementById('bottomDialog').style.display='flex'" style="margin-left: 10px;">底部弹出</button><button class="my-button" onclick="document.getElementById('leftDialog').style.display='flex'" style="margin-left: 10px;">左侧弹出</button><button class="my-button" onclick="document.getElementById('rightDialog').style.display='flex'" style="margin-left: 10px;">右侧弹出</button><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">不同方向的弹出框示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><!-- 顶部弹出框 -->
<div class="my-dialog my-dialog--top"><!-- 弹出框内容 -->
</div><!-- 底部弹出框 -->
<div class="my-dialog my-dialog--bottom"><!-- 弹出框内容 -->
</div><!-- 左侧弹出框 -->
<div class="my-dialog my-dialog--left"><!-- 弹出框内容 -->
</div><!-- 右侧弹出框 -->
<div class="my-dialog my-dialog--right"><!-- 弹出框内容 -->
</div></code></pre></div></div><div class="code-block__source"><div class="code-block__content"><pre><code>/* 不同方向的弹出框样式 */
.my-dialog--top {position: fixed;top: 0;left: 0;width: 100%;max-width: 100%;margin: 0;border-radius: 0 0 4px 4px;
}.my-dialog--bottom {position: fixed;bottom: 0;left: 0;width: 100%;max-width: 100%;margin: 0;border-radius: 4px 4px 0 0;
}.my-dialog--left {position: fixed;top: 0;left: 0;height: 100vh;margin: 0;border-radius: 0 4px 4px 0;
}.my-dialog--right {position: fixed;top: 0;right: 0;height: 100vh;margin: 0;border-radius: 4px 0 0 4px;
}/* 动画效果 */
.my-dialog__wrapper {animation: fadeIn 0.3s ease-in-out;
}/* 中间弹出 */
.my-dialog {animation: slideIn 0.3s ease-in-out;
}/* 顶部弹出 */
.my-dialog--top {animation: slideDown 0.3s ease-in-out;
}/* 底部弹出 */
.my-dialog--bottom {animation: slideUp 0.3s ease-in-out;
}/* 左侧弹出 */
.my-dialog--left {animation: slideRight 0.3s ease-in-out;
}/* 右侧弹出 */
.my-dialog--right {animation: slideLeft 0.3s ease-in-out;
}</code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 自定义内容 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">自定义内容</div></div><div class="my-card__body"><button class="my-button my-button--primary" onclick="document.getElementById('customDialog').style.display='flex'">打开表单弹出框</button><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">自定义内容示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-dialog__wrapper" id="customDialog"><div class="my-dialog__mask"></div><div class="my-dialog"><div class="my-dialog__header"><span class="my-dialog__title">用户信息</span><button class="my-dialog__close"><i class="bi bi-x"></i></button></div><div class="my-dialog__body"><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">用户名</label><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入用户名"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">邮箱</label><div class="my-input"><input type="email" class="my-input__inner" placeholder="请输入邮箱"></div></div><div><label style="display: block; margin-bottom: 8px;">年龄</label><div class="my-number-input"><input type="number" class="my-number-input__inner" value="18" min="1" max="100"><div class="my-number-input__controls"><div class="my-number-input__up"><i class="bi bi-chevron-up my-number-input__icon"></i></div><div class="my-number-input__down"><i class="bi bi-chevron-down my-number-input__icon"></i></div></div></div></div></div><div class="my-dialog__footer"><button class="my-button">取消</button><button class="my-button my-button--primary">提交</button></div></div>
</div></code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div></div><!-- 登录弹窗示例 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">登录弹窗</div></div><div class="my-card__body"><button class="my-button my-button--primary" onclick="document.getElementById('loginDialog').style.display='flex'">打开登录弹窗</button><!-- 登录弹窗 --><div class="my-dialog__wrapper" id="loginDialog" style="display: none;"><div class="my-dialog__mask" onclick="document.getElementById('loginDialog').style.display='none'"></div><div class="my-dialog my-dialog--small"><div class="my-dialog__header"><span class="my-dialog__title">用户登录</span><button class="my-dialog__close" onclick="document.getElementById('loginDialog').style.display='none'"><i class="bi bi-x"></i></button></div><div class="my-dialog__body"><div style="text-align: center; margin-bottom: 20px;"><i class="bi bi-person-circle" style="font-size: 48px; color: var(--primary-color);"></i></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">用户名</label><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入用户名"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">密码</label><div class="my-input"><input type="password" class="my-input__inner" placeholder="请输入密码"></div></div><div style="display: flex; justify-content: space-between; margin-bottom: 20px;"><label style="display: flex; align-items: center; cursor: pointer;"><input type="checkbox" style="margin-right: 8px;">记住我</label><a href="#" style="color: var(--primary-color); text-decoration: none;">忘记密码?</a></div><button class="my-button my-button--primary" style="width: 100%; margin-bottom: 15px;">登录</button><div style="text-align: center;"><span style="color: #909399;">还没有账号?</span><a href="#" style="color: var(--primary-color); text-decoration: none;">立即注册</a></div><div style="margin-top: 20px; text-align: center;"><div style="color: #909399; margin-bottom: 10px;">其他登录方式</div><div style="display: flex; justify-content: center; gap: 20px;"><a href="#" style="color: #1DA1F2; font-size: 24px;"><i class="bi bi-twitter"></i></a><a href="#" style="color: #4267B2; font-size: 24px;"><i class="bi bi-facebook"></i></a><a href="#" style="color: #25D366; font-size: 24px;"><i class="bi bi-wechat"></i></a><a href="#" style="color: #DB4437; font-size: 24px;"><i class="bi bi-google"></i></a></div></div></div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">登录弹窗示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-dialog__wrapper" id="loginDialog"><div class="my-dialog__mask"></div><div class="my-dialog my-dialog--small"><div class="my-dialog__header"><span class="my-dialog__title">用户登录</span><button class="my-dialog__close"><i class="bi bi-x"></i></button></div><div class="my-dialog__body"><div style="text-align: center; margin-bottom: 20px;"><i class="bi bi-person-circle" style="font-size: 48px; color: var(--primary-color);"></i></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">用户名</label><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入用户名"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">密码</label><div class="my-input"><input type="password" class="my-input__inner" placeholder="请输入密码"></div></div><div style="display: flex; justify-content: space-between; margin-bottom: 20px;"><label style="display: flex; align-items: center; cursor: pointer;"><input type="checkbox" style="margin-right: 8px;">记住我</label><a href="#" style="color: var(--primary-color); text-decoration: none;">忘记密码?</a></div><button class="my-button my-button--primary" style="width: 100%; margin-bottom: 15px;">登录</button><div style="text-align: center;"><span style="color: #909399;">还没有账号?</span><a href="#" style="color: var(--primary-color); text-decoration: none;">立即注册</a></div><div style="margin-top: 20px; text-align: center;"><div style="color: #909399; margin-bottom: 10px;">其他登录方式</div><div style="display: flex; justify-content: center; gap: 20px;"><a href="#" style="color: #1DA1F2; font-size: 24px;"><i class="bi bi-twitter"></i></a><a href="#" style="color: #4267B2; font-size: 24px;"><i class="bi bi-facebook"></i></a><a href="#" style="color: #25D366; font-size: 24px;"><i class="bi bi-wechat"></i></a><a href="#" style="color: #DB4437; font-size: 24px;"><i class="bi bi-google"></i></a></div></div></div></div>
</div></code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 注册弹窗示例 --><div class="my-card" style="margin-top: 20px;"><div class="my-card__header"><div class="my-card__title">注册弹窗</div></div><div class="my-card__body"><button class="my-button my-button--primary" onclick="document.getElementById('registerDialog').style.display='flex'">打开注册弹窗</button><!-- 注册弹窗 --><div class="my-dialog__wrapper" id="registerDialog" style="display: none;"><div class="my-dialog__mask" onclick="document.getElementById('registerDialog').style.display='none'"></div><div class="my-dialog"><div class="my-dialog__header"><span class="my-dialog__title">用户注册</span><button class="my-dialog__close" onclick="document.getElementById('registerDialog').style.display='none'"><i class="bi bi-x"></i></button></div><div class="my-dialog__body"><div style="display: grid; grid-template-columns: 1fr 1fr; gap: 20px;"><div><label style="display: block; margin-bottom: 8px;">姓氏</label><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入姓氏"></div></div><div><label style="display: block; margin-bottom: 8px;">名字</label><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入名字"></div></div></div><div style="margin: 20px 0;"><label style="display: block; margin-bottom: 8px;">电子邮箱</label><div class="my-input"><input type="email" class="my-input__inner" placeholder="请输入电子邮箱"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">手机号码</label><div class="my-input"><input type="tel" class="my-input__inner" placeholder="请输入手机号码"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">设置密码</label><div class="my-input"><input type="password" class="my-input__inner" placeholder="请设置密码"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">确认密码</label><div class="my-input"><input type="password" class="my-input__inner" placeholder="请确认密码"></div></div><div style="margin-bottom: 20px;"><label style="display: flex; align-items: center; cursor: pointer;"><input type="checkbox" style="margin-right: 8px;">我已阅读并同意<a href="#" style="color: var(--primary-color); text-decoration: none; margin: 0 4px;">服务条款</a>和<a href="#" style="color: var(--primary-color); text-decoration: none; margin: 0 4px;">隐私政策</a></label></div><button class="my-button my-button--primary" style="width: 100%;">注册</button><div style="text-align: center; margin-top: 15px;"><span style="color: #909399;">已有账号?</span><a href="#" style="color: var(--primary-color); text-decoration: none;">立即登录</a></div></div></div></div><!-- 代码展示 --><div class="code-block"><div class="code-block__header"><div class="code-block__title">注册弹窗示例</div><div class="code-block__actions"><div class="code-block__switch-group"><button class="code-block__switch is-active" data-type="preview">预览</button><button class="code-block__switch" data-type="source">源代码</button></div><button class="code-block__button" onclick="copyCode(this)"><i class="bi bi-clipboard"></i>复制代码</button></div></div><div class="code-block__wrapper"><div class="code-block__preview is-visible"><div class="code-block__content"><pre><code><div class="my-dialog__wrapper" id="registerDialog"><div class="my-dialog__mask"></div><div class="my-dialog"><div class="my-dialog__header"><span class="my-dialog__title">用户注册</span><button class="my-dialog__close"><i class="bi bi-x"></i></button></div><div class="my-dialog__body"><div style="display: grid; grid-template-columns: 1fr 1fr; gap: 20px;"><div><label style="display: block; margin-bottom: 8px;">姓氏</label><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入姓氏"></div></div><div><label style="display: block; margin-bottom: 8px;">名字</label><div class="my-input"><input type="text" class="my-input__inner" placeholder="请输入名字"></div></div></div><div style="margin: 20px 0;"><label style="display: block; margin-bottom: 8px;">电子邮箱</label><div class="my-input"><input type="email" class="my-input__inner" placeholder="请输入电子邮箱"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">手机号码</label><div class="my-input"><input type="tel" class="my-input__inner" placeholder="请输入手机号码"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">设置密码</label><div class="my-input"><input type="password" class="my-input__inner" placeholder="请设置密码"></div></div><div style="margin-bottom: 20px;"><label style="display: block; margin-bottom: 8px;">确认密码</label><div class="my-input"><input type="password" class="my-input__inner" placeholder="请确认密码"></div></div><div style="margin-bottom: 20px;"><label style="display: flex; align-items: center; cursor: pointer;"><input type="checkbox" style="margin-right: 8px;">我已阅读并同意<a href="#" style="color: var(--primary-color); text-decoration: none; margin: 0 4px;">服务条款</a>和<a href="#" style="color: var(--primary-color); text-decoration: none; margin: 0 4px;">隐私政策</a></label></div><button class="my-button my-button--primary" style="width: 100%;">注册</button><div style="text-align: center; margin-top: 15px;"><span style="color: #909399;">已有账号?</span><a href="#" style="color: var(--primary-color); text-decoration: none;">立即登录</a></div></div></div>
</div></code></pre></div></div></div><div class="code-block__tooltip">复制成功!</div></div></div></div><!-- 添加底部 --><footer class="my-footer" id="footer"><div class="my-footer__container"><div class="my-footer__section"><h3 class="my-footer__title">关于我们</h3><ul class="my-footer__list"><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-building my-footer__icon"></i>公司简介</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-people my-footer__icon"></i>团队介绍</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-briefcase my-footer__icon"></i>工作机会</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-newspaper my-footer__icon"></i>新闻动态</a></li></ul></div><div class="my-footer__section"><h3 class="my-footer__title">帮助中心</h3><ul class="my-footer__list"><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-book my-footer__icon"></i>使用文档</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-question-circle my-footer__icon"></i>常见问题</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-chat-dots my-footer__icon"></i>技术支持</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-shield-check my-footer__icon"></i>安全中心</a></li></ul></div><div class="my-footer__section"><h3 class="my-footer__title">开发者</h3><ul class="my-footer__list"><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-code-square my-footer__icon"></i>API文档</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-download my-footer__icon"></i>下载中心</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-github my-footer__icon"></i>GitHub</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-bug my-footer__icon"></i>问题反馈</a></li></ul></div><div class="my-footer__section"><h3 class="my-footer__title">联系我们</h3><ul class="my-footer__list"><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-envelope my-footer__icon"></i>contact@myui.com</a></li><li class="my-footer__item"><a href="#" class="my-footer__link"><i class="bi bi-telephone my-footer__icon"></i>400-123-4567</a></li></ul><div class="my-footer__social" style="margin-top: 20px;"><a href="#" class="my-footer__social-link"><i class="bi bi-twitter"></i></a><a href="#" class="my-footer__social-link"><i class="bi bi-facebook"></i></a><a href="#" class="my-footer__social-link"><i class="bi bi-linkedin"></i></a><a href="#" class="my-footer__social-link"><i class="bi bi-instagram"></i></a></div></div></div><div class="my-footer__bottom"><p>© 2024 My UI Library. All rights reserved.</p></div></footer><script>// 处理导航栏响应式切换document.querySelector('.my-navbar__toggle').addEventListener('click', function() {document.querySelector('.my-navbar').classList.toggle('is-active');});// 处理移动端下拉菜单document.querySelectorAll('.my-navbar__dropdown').forEach(dropdown => {dropdown.addEventListener('click', function(e) {if (window.innerWidth <= 768) {e.preventDefault();this.classList.toggle('is-active');}});});// 点击导航项时关闭移动端菜单document.querySelectorAll('.my-navbar__item').forEach(item => {item.addEventListener('click', function(e) {if (window.innerWidth <= 768 && !this.classList.contains('my-navbar__dropdown')) {document.querySelector('.my-navbar').classList.remove('is-active');}});});// 点击下拉菜单项时关闭移动端菜单document.querySelectorAll('.my-navbar__dropdown-item').forEach(item => {item.addEventListener('click', function(e) {if (window.innerWidth <= 768) {document.querySelector('.my-navbar').classList.remove('is-active');}});});// 点击页面其他区域时关闭移动端菜单document.addEventListener('click', function(e) {if (window.innerWidth <= 768) {const navbar = document.querySelector('.my-navbar');const toggle = document.querySelector('.my-navbar__toggle');if (!navbar.contains(e.target) && navbar.classList.contains('is-active')) {navbar.classList.remove('is-active');}}});// 监听窗口大小变化,在切换到桌面版时重置状态window.addEventListener('resize', function() {if (window.innerWidth > 768) {document.querySelector('.my-navbar').classList.remove('is-active');document.querySelectorAll('.my-navbar__dropdown').forEach(dropdown => {dropdown.classList.remove('is-active');});}});// 代码块相关功能document.querySelectorAll('.code-block__switch').forEach(button => {button.addEventListener('click', function() {const type = this.dataset.type;const codeBlock = this.closest('.code-block');// 切换按钮状态codeBlock.querySelectorAll('.code-block__switch').forEach(btn => {btn.classList.remove('is-active');});this.classList.add('is-active');// 切换内容显示codeBlock.querySelectorAll('.code-block__preview, .code-block__source').forEach(content => {content.classList.remove('is-visible');});codeBlock.querySelector(`.code-block__${type}`).classList.add('is-visible');});});// 复制代码功能function copyCode(button) {const codeBlock = button.closest('.code-block');const code = codeBlock.querySelector('.code-block__content:not([style*="display: none"]) code').textContent;// 创建临时文本区域const textarea = document.createElement('textarea');textarea.value = code;document.body.appendChild(textarea);textarea.select();document.execCommand('copy');document.body.removeChild(textarea);// 显示提示const tooltip = codeBlock.querySelector('.code-block__tooltip');tooltip.classList.add('is-visible');setTimeout(() => {tooltip.classList.remove('is-visible');}, 2000);}// 初始化代码块展开/收起状态document.querySelectorAll('.code-block__wrapper').forEach(wrapper => {wrapper.classList.add('is-expanded');});</script>
</body>
</html>
main.css
/* -----------base---------------------------------- */
:root {/* 主题色 */--primary-color: #409eff;--success-color: #67c23a;--warning-color: #e6a23c;--danger-color: #f56c6c;--info-color: #909399;/* 文字颜色 */--text-primary: #303133;--text-regular: #606266;--text-secondary: #909399;--text-placeholder: #c0c4cc;/* 边框颜色 */--border-color: #dcdfe6;--border-color-light: #e4e7ed;--border-color-lighter: #ebeef5;/* 背景颜色 */--background-color: #ffffff;--background-color-light: #f5f7fa;}/* 基础样式重置 */* {margin: 0;padding: 0;box-sizing: border-box;}a {text-decoration: none;color: inherit;}body {font-family: "Helvetica Neue", Helvetica, "PingFang SC", "Hiragino Sans GB", "Microsoft YaHei", "微软雅黑", Arial, sans-serif;font-size: 14px;color: var(--text-primary);-webkit-font-smoothing: antialiased;}
/* ---------------------my-button------------------------ */
.my-button {display: inline-flex;justify-content: center;align-items: center;line-height: 1;height: 32px;white-space: nowrap;cursor: pointer;color: var(--text-regular);text-align: center;box-sizing: border-box;outline: none;transition: .1s;font-weight: 500;padding: 8px 15px;font-size: 14px;border-radius: 4px;border: 1px solid var(--border-color);background-color: var(--background-color);}.my-button:hover {color: var(--primary-color);border-color: var(--primary-color);background-color: var(--background-color-light);}/* 主要按钮 */.my-button--primary {color: #fff;background-color: var(--primary-color);border-color: var(--primary-color);}.my-button--primary:hover {background: var(--primary-color);border-color: var(--primary-color);color: #fff;opacity: 0.8;}/* 成功按钮 */.my-button--success {color: #fff;background-color: var(--success-color);border-color: var(--success-color);}.my-button--success:hover {background: var(--success-color);border-color: var(--success-color);color: #fff;opacity: 0.8;}/* 警告按钮 */.my-button--warning {color: #fff;background-color: var(--warning-color);border-color: var(--warning-color);}.my-button--warning:hover {background: var(--warning-color);border-color: var(--warning-color);color: #fff;opacity: 0.8;}/* 危险按钮 */.my-button--danger {color: #fff;background-color: var(--danger-color);border-color: var(--danger-color);}.my-button--danger:hover {background: var(--danger-color);border-color: var(--danger-color);color: #fff;opacity: 0.8;}/* 禁用状态 */.my-button.is-disabled {cursor: not-allowed;opacity: 0.5;}/* 按钮尺寸 */.my-button--large {height: 40px;padding: 12px 19px;font-size: 14px;}.my-button--small {height: 24px;padding: 5px 11px;font-size: 12px;}/* 圆角按钮 */.my-button--round {border-radius: 20px;}/* 按钮组样式 */.my-button-group {display: inline-flex;vertical-align: middle;}/* 按钮组中的按钮样式 */.my-button-group .my-button {position: relative;margin: 0;border-radius: 0;}/* 移除相邻按钮之间的边框重叠 */.my-button-group .my-button:not(:first-child) {margin-left: -1px;}/* 第一个按钮的圆角 */.my-button-group .my-button:first-child {border-top-left-radius: 4px;border-bottom-left-radius: 4px;}/* 最后一个按钮的圆角 */.my-button-group .my-button:last-child {border-top-right-radius: 4px;border-bottom-right-radius: 4px;}/* 悬浮时提升层级,避免边框被遮挡 */.my-button-group .my-button:hover {z-index: 1;}/* 圆角按钮组 */.my-button-group--round .my-button:first-child {border-top-left-radius: 20px;border-bottom-left-radius: 20px;}.my-button-group--round .my-button:last-child {border-top-right-radius: 20px;border-bottom-right-radius: 20px;}/* 垂直按钮组 */.my-button-group--vertical {display: inline-flex;flex-direction: column;vertical-align: middle;}.my-button-group--vertical .my-button {margin: 0;border-radius: 0;}.my-button-group--vertical .my-button:not(:first-child) {margin-top: -1px;margin-left: 0;}.my-button-group--vertical .my-button:first-child {border-top-left-radius: 4px;border-top-right-radius: 4px;border-bottom-left-radius: 0;border-bottom-right-radius: 0;}.my-button-group--vertical .my-button:last-child {border-top-left-radius: 0;border-top-right-radius: 0;border-bottom-left-radius: 4px;border-bottom-right-radius: 4px;}/* 按钮组中的图标样式 */.my-button-group .my-button i {font-size: 14px;vertical-align: middle;}.my-button-group .my-button i:first-child:not(:last-child) {margin-right: 5px;}.my-button-group .my-button i:last-child:not(:first-child) {margin-left: 5px;} /* ---------------------my-card------------------------ */.demo-card-container { /* 容器 */display: grid; /* 使用网格布局 */grid-template-columns: repeat(auto-fill, minmax(300px, 1fr)); /* 自动填充,最小宽度为300px,最大宽度为1fr */gap: 20px; /* 项目之间的间距 */padding: 10px; /* 容器内边距 */
}.demo-card-horizontal-container { /* 水平布局容器 */display: grid; /* 使用网格布局 */grid-template-columns: repeat(auto-fill, minmax(400px, 1fr)); /* 自动填充,最小宽度为400px,最大宽度为1fr */gap: 20px; /* 项目之间的间距 */padding: 10px; /* 容器内边距 */
}.my-card { /* 卡片 */border-radius: 4px; /* 圆角 */border: 1px solid var(--border-color-light); /* 边框 */background-color: var(--background-color); /* 背景颜色 */overflow: hidden; /* 隐藏溢出内容 */color: var(--text-regular); /* 文字颜色 */transition: .3s; /* 过渡效果 */}.my-card:hover { /* 鼠标悬停时 */box-shadow: 0 2px 12px 0 rgba(0,0,0,.1); /* 阴影 */}.my-card__header { /* 卡片头部 */padding: 18px 20px; /* 内边距 */border-bottom: 1px solid var(--border-color-light); /* 底部边框 */box-sizing: border-box; /* 包括内边距和边框 */}.my-card__title { /* 卡片标题 */font-size: 16px; /* 字体大小 */font-weight: bold; /* 字体加粗 */color: var(--text-primary); /* 字体颜色 */line-height: 1.5; /* 行高 */}.my-card__body { /* 卡片主体 */padding: 20px; /* 内边距 */}/* 无边框卡片 */.my-card--borderless { /* 无边框 */border: none; /* 去除边框 */box-shadow: 0 2px 12px 0 rgba(0,0,0,.1); /* 添加阴影 */}/* 简单卡片 */.my-card--simple { /* 简单卡片 */border: none; /* 去除边框 */}/* 悬浮效果增强 */.my-card--hover:hover { /* 鼠标悬停时 */transform: translateY(-4px); /* 向上移动 */box-shadow: 0 4px 16px rgba(0,0,0,.1); /* 添加阴影 */} /* 卡片图片样式 */.my-card__image { /* 卡片图片样式 */width: 100%; /* 宽度 */height: 200px; /* 高度 */object-fit: cover; /* 覆盖 */
}/* 卡片图片样式 */.my-card-left__image { /* 卡片图片样式 */width: 100%; /* 宽度 */height: 250px; /* 高度 */object-fit: cover; /* 覆盖 */
}
/* 卡片列表样式 */
.my-card__list { /* 卡片列表样式 */list-style: none; /* 去除列表样式 */padding: 0; /* 去除内边距 */margin: 0; /* 去除外边距 */
}
.my-card__list-item { /* 列表项样式 */padding: 12px 20px; /* 内边距 */border-bottom: 1px solid var(--border-color-light); /* 底部边框 */
}
.my-card__list-item:last-child { /* 最后一个列表项 */border-bottom: none; /* 去除底部边框 */
}
/* 卡片页脚样式 */
.my-card__footer { /* 卡片页脚样式 */padding: 12px 20px; /* 内边距 */background-color: var(--background-color-light); /* 背景颜色 */border-top: 1px solid var(--border-color-light); /* 顶部边框 */
}
/* 卡片文本样式 */
.my-card__text { /* 卡片文本样式 */margin-bottom: 15px; /* 底部外边距 */line-height: 1.5; /* 行高 */
}
.my-card__subtitle { /* 卡片副标题样式 */color: var(--text-secondary); /* 文本颜色 */font-size: 14px; /* 字体大小 */margin-top: 5px; /* 顶部外边距 */
}/* -------------------my-datepicker-------------------------- */.my-datepicker {position: relative;display: inline-block;
}.my-datepicker__input {width: 200px;height: 32px;padding: 0 30px 0 12px;border: 1px solid var(--border-color);border-radius: 4px;font-size: 14px;color: var(--text-primary);background-color: #fff;cursor: pointer;transition: all 0.3s;
}.my-datepicker__input:hover {border-color: var(--primary-color);
}.my-datepicker__input:focus {outline: none;border-color: var(--primary-color);box-shadow: 0 0 0 2px rgba(24, 144, 255, 0.2);
}.my-datepicker__icon {position: absolute;right: 8px;top: 50%;transform: translateY(-50%);color: var(--text-secondary);pointer-events: none;
}.my-datepicker__panel {position: absolute;top: calc(100% + 4px);left: 0;z-index: 1000;width: 280px;background-color: #fff;border: 1px solid var(--border-color);border-radius: 4px;box-shadow: 0 2px 12px rgba(0, 0, 0, 0.1);padding: 8px;
}.my-datepicker__header {display: flex;align-items: center;justify-content: space-between;padding: 8px;border-bottom: 1px solid var(--border-color-light);
}.my-datepicker__arrow {width: 24px;height: 24px;display: flex;align-items: center;justify-content: center;cursor: pointer;border-radius: 4px;transition: all 0.3s;
}.my-datepicker__arrow:hover {background-color: var(--background-color-light);color: var(--primary-color);
}.my-datepicker__current-month {font-size: 14px;font-weight: 500;color: var(--text-primary);
}.my-datepicker__weekdays {display: grid;grid-template-columns: repeat(7, 1fr);padding: 8px 0;
}.my-datepicker__weekday {text-align: center;font-size: 12px;color: var(--text-secondary);
}.my-datepicker__days {display: grid;grid-template-columns: repeat(7, 1fr);gap: 2px;
}.my-datepicker__day {height: 32px;display: flex;align-items: center;justify-content: center;font-size: 14px;cursor: pointer;border-radius: 4px;transition: all 0.3s;
}.my-datepicker__day:hover {background-color: var(--background-color-light);
}.my-datepicker__day.is-today {color: var(--primary-color);font-weight: bold;
}.my-datepicker__day.is-selected {background-color: var(--primary-color);color: #fff;
}.my-datepicker__day.is-disabled {color: var(--text-disabled);cursor: not-allowed;background-color: transparent;
}.my-datepicker__day.is-other-month {color: var(--text-disabled);
}.my-datepicker__footer {padding: 8px;text-align: right;border-top: 1px solid var(--border-color-light);
}.my-datepicker__btn {padding: 4px 12px;font-size: 12px;border-radius: 4px;border: 1px solid var(--border-color);background-color: #fff;color: var(--text-primary);cursor: pointer;transition: all 0.3s;margin-left: 8px;
}.my-datepicker__btn:hover {color: var(--primary-color);border-color: var(--primary-color);
}.my-datepicker__btn--primary {background-color: var(--primary-color);border-color: var(--primary-color);color: #fff;
}.my-datepicker__btn--primary:hover {background-color: var(--primary-color-dark);border-color: var(--primary-color-dark);color: #fff;
} /* ----------------.my-dialog----------------------------- */
.my-dialog__wrapper {position: fixed;top: 0;right: 0;bottom: 0;left: 0;z-index: 2000;display: flex;align-items: center;justify-content: center;
}.my-dialog__mask {position: fixed;top: 0;right: 0;bottom: 0;left: 0;background-color: rgba(0, 0, 0, 0.5);z-index: 2001;
}.my-dialog {position: relative;background: #fff;border-radius: 4px;box-shadow: 0 1px 3px rgba(0, 0, 0, 0.3);margin: 0 auto;width: 50%;max-width: 600px;z-index: 2002;
}/* 不同方向的弹出框样式 */
.my-dialog--top {position: fixed;top: 0;left: 0;width: 100%;max-width: 100%;margin: 0;border-radius: 0 0 4px 4px;
}.my-dialog--bottom {position: fixed;bottom: 0;left: 0;width: 100%;max-width: 100%;margin: 0;border-radius: 4px 4px 0 0;
}.my-dialog--left {position: fixed;top: 0;left: 0;height: 100vh;margin: 0;border-radius: 0 4px 4px 0;
}.my-dialog--right {position: fixed;top: 0;right: 0;height: 100vh;margin: 0;border-radius: 4px 0 0 4px;
}.my-dialog--small {width: 30%;
}.my-dialog--large {width: 70%;
}.my-dialog__header {padding: 20px;padding-bottom: 10px;display: flex;justify-content: space-between;align-items: center;
}.my-dialog__title {line-height: 24px;font-size: 18px;color: #303133;font-weight: 500;
}.my-dialog__close {border: none;background: transparent;padding: 0;cursor: pointer;font-size: 20px;color: #909399;
}.my-dialog__close:hover {color: var(--primary-color);
}.my-dialog__body {padding: 30px 20px;color: #606266;font-size: 14px;word-break: break-all;
}.my-dialog__footer {padding: 20px;padding-top: 10px;text-align: right;
}.my-dialog__footer .my-button + .my-button {margin-left: 10px;
}/* 响应式布局 */
@media screen and (max-width: 768px) {.my-dialog,.my-dialog--small,.my-dialog--large {width: 90%;}.my-dialog--left,.my-dialog--right {width: 80%;}
}/* 动画效果 */
.my-dialog__wrapper {animation: fadeIn 0.3s ease-in-out;
}/* 中间弹出 */
.my-dialog {animation: slideIn 0.3s ease-in-out;
}/* 顶部弹出 */
.my-dialog--top {animation: slideDown 0.3s ease-in-out;
}/* 底部弹出 */
.my-dialog--bottom {animation: slideUp 0.3s ease-in-out;
}/* 左侧弹出 */
.my-dialog--left {animation: slideRight 0.3s ease-in-out;
}/* 右侧弹出 */
.my-dialog--right {animation: slideLeft 0.3s ease-in-out;
}@keyframes fadeIn {from {opacity: 0;}to {opacity: 1;}
}@keyframes slideIn {from {transform: translateY(-20px);opacity: 0;}to {transform: translateY(0);opacity: 1;}
}@keyframes slideDown {from {transform: translateY(-100%);}to {transform: translateY(0);}
}@keyframes slideUp {from {transform: translateY(100%);}to {transform: translateY(0);}
}@keyframes slideRight {from {transform: translateX(-100%);}to {transform: translateX(0);}
}@keyframes slideLeft {from {transform: translateX(100%);}to {transform: translateX(0);}
} /* -------------------my-footer-------------------------- */
.my-footer {background-color: var(--background-color);border-top: 1px solid var(--border-color);padding: 40px 0;color: var(--text-regular);}.my-footer__container {max-width: 1200px;margin: 0 auto;padding: 0 20px;display: grid;grid-template-columns: repeat(4, 1fr);gap: 40px;}.my-footer__section {display: flex;flex-direction: column;}.my-footer__title {font-size: 18px;font-weight: bold;color: var(--text-primary);margin-bottom: 20px;}.my-footer__list {list-style: none;padding: 0;margin: 0;}.my-footer__item {margin-bottom: 12px;}.my-footer__link {color: var(--text-regular);text-decoration: none;transition: .3s;display: inline-flex;align-items: center;}.my-footer__link:hover {color: var(--primary-color);}.my-footer__icon {margin-right: 8px;font-size: 16px;}.my-footer__social {display: flex;gap: 16px;}.my-footer__social-link {color: var(--text-regular);font-size: 20px;transition: .3s;}.my-footer__social-link:hover {color: var(--primary-color);}.my-footer__bottom {margin-top: 40px;padding-top: 20px;border-top: 1px solid var(--border-color);text-align: center;color: var(--text-secondary);font-size: 14px;}/* 响应式布局 */@media screen and (max-width: 992px) {.my-footer__container {grid-template-columns: repeat(2, 1fr);}}@media screen and (max-width: 576px) {.my-footer__container {grid-template-columns: 1fr;gap: 30px;}.my-footer {padding: 30px 0;}.my-footer__bottom {margin-top: 30px;}} /* ---------------my-input------------------------------ */.my-input {position: relative;font-size: 14px;display: inline-block;width: 100%;}.my-input__inner {background-color: var(--background-color);border-radius: 4px;border: 1px solid var(--border-color);box-sizing: border-box;color: var(--text-regular);display: inline-block;font-size: inherit;height: 32px;line-height: 32px;outline: none;padding: 0 15px;transition: border-color .2s;width: 100%;}.my-input__inner:hover {border-color: var(--text-secondary);}.my-input__inner:focus {border-color: var(--primary-color);outline: none;}.my-input__inner::placeholder {color: var(--text-placeholder);}/* 禁用状态 */.my-input.is-disabled .my-input__inner {background-color: var(--background-color-light);border-color: var(--border-color);color: var(--text-placeholder);cursor: not-allowed;}/* 尺寸 */.my-input--large .my-input__inner {height: 40px;line-height: 40px;font-size: 14px;}.my-input--small .my-input__inner {height: 24px;line-height: 24px;font-size: 12px;}/* 带图标的输入框 */.my-input--prefix .my-input__inner {padding-left: 30px;}.my-input--suffix .my-input__inner {padding-right: 30px;}.my-input__prefix,.my-input__suffix {position: absolute;height: 100%;top: 0;display: flex;align-items: center;color: var(--text-secondary);}.my-input__prefix {left: 5px;}.my-input__suffix {right: 5px;} /* ---------------my-navbar------------------------------ */.my-navbar {height: 60px;background-color: var(--background-color);border-bottom: 1px solid var(--border-color);display: flex;align-items: center;padding: 0 20px;position: sticky;top: 0;z-index: 100;box-shadow: 0 2px 4px rgba(0,0,0,.05);}.my-navbar__brand {font-size: 20px;font-weight: bold;color: var(--text-primary);text-decoration: none;margin-right: 40px;}.my-navbar__nav {display: flex;align-items: center;list-style: none;margin: 0;padding: 0;height: 100%;}.my-navbar__item {height: 100%;padding: 0 20px;display: flex;align-items: center;color: var(--text-regular);cursor: pointer;transition: .3s;position: relative;}.my-navbar__item:hover {color: var(--primary-color);}.my-navbar__item.is-active {color: var(--primary-color);}.my-navbar__item.is-active::after {content: '';position: absolute;bottom: 0;left: 20px;right: 20px;height: 2px;background-color: var(--primary-color);}/* 搜索框样式 */.my-navbar__search {position: relative;margin-left: 20px;margin-right: 20px;}.my-navbar__search-input {width: 200px;height: 32px;padding: 0 35px 0 15px;border-radius: 16px;border: 1px solid var(--border-color);background-color: var(--background-color-light);transition: all .3s;outline: none;font-size: 14px;color: var(--text-regular);}.my-navbar__search-input:focus {width: 250px;border-color: var(--primary-color);background-color: var(--background-color);}.my-navbar__search-input::placeholder {color: var(--text-placeholder);}.my-navbar__search-icon {position: absolute;right: 12px;top: 50%;transform: translateY(-50%);color: var(--text-secondary);font-size: 14px;}/* 右侧导航项 */.my-navbar__right {margin-left: auto;display: flex;align-items: center;}/* 下拉菜单 */.my-navbar__dropdown {position: relative;}.my-navbar__dropdown-menu {position: absolute;top: 100%;left: 0;min-width: 150px;background-color: var(--background-color);border: 1px solid var(--border-color-light);border-radius: 4px;box-shadow: 0 2px 12px 0 rgba(0,0,0,.1);padding: 10px 0;display: none;}.my-navbar__dropdown:hover .my-navbar__dropdown-menu {display: block;}.my-navbar__dropdown-item {padding: 8px 20px;color: var(--text-regular);cursor: pointer;transition: .3s;}.my-navbar__dropdown-item:hover {background-color: var(--background-color-light);color: var(--primary-color);}/* 响应式菜单按钮 */.my-navbar__toggle {display: none;font-size: 24px;color: var(--text-regular);cursor: pointer;margin-left: auto;}/* 响应式布局 */@media screen and (max-width: 768px) { /* 根据需要调整断点 */.my-navbar__toggle { /* 显示菜单按钮 */display: block; /* 显示菜单按钮 */}.my-navbar__nav,.my-navbar__right { /* 隐藏导航栏和右侧内容 */display: none;}.my-navbar.is-active .my-navbar__nav,.my-navbar.is-active .my-navbar__right { /* 显示导航栏和右侧内容 */display: flex; /* 显示导航栏和右侧内容 */flex-direction: column; /* 垂直排列 */position: absolute; /* 绝对定位 */top: 60px; /* 菜单按钮的高度 */left: 0; /* 左对齐 */right: 0; /* 右对齐 */background-color: var(--background-color); /* 背景色 */border-bottom: 1px solid var(--border-color); /* 底部边框 */padding: 10px 0; /* 内边距 */}.my-navbar__item {height: 50px;width: 100%;}.my-navbar__dropdown-menu {position: static;box-shadow: none;border: none;background-color: var(--background-color-light);}.my-navbar__search {width: 100%;margin: 10px 20px;}.my-navbar__search-input {width: 100%;}.my-navbar__search-input:focus {width: 100%;}} /* ------------------my-number-input--------------------------- */.my-number-input {position: relative;display: inline-flex;width: 180px;border: 1px solid var(--border-color);border-radius: 4px;overflow: hidden;transition: all 0.3s;
}.my-number-input:hover {border-color: var(--primary-color);
}.my-number-input:focus-within {border-color: var(--primary-color);box-shadow: 0 0 0 2px rgba(24, 144, 255, 0.2);
}.my-number-input__inner {flex: 1;width: 100%;height: 32px;padding: 0 8px;border: none;outline: none;font-size: 14px;color: var(--text-primary);text-align: center;
}.my-number-input__inner::-webkit-inner-spin-button,
.my-number-input__inner::-webkit-outer-spin-button {-webkit-appearance: none;margin: 0;
}.my-number-input__controls {display: flex;flex-direction: column;border-left: 1px solid var(--border-color);
}.my-number-input__up,
.my-number-input__down {display: flex;align-items: center;justify-content: center;width: 32px;height: 16px;cursor: pointer;background-color: var(--background-color-light);transition: all 0.3s;user-select: none;
}.my-number-input__up {border-bottom: 1px solid var(--border-color);
}.my-number-input__up:hover,
.my-number-input__down:hover {background-color: var(--border-color-light);color: var(--primary-color);
}.my-number-input__icon {font-size: 12px;color: var(--text-secondary);
}/* 禁用状态 */
.my-number-input.is-disabled {background-color: var(--background-color-light);border-color: var(--border-color);cursor: not-allowed;
}.my-number-input.is-disabled .my-number-input__inner {background-color: var(--background-color-light);color: var(--text-disabled);cursor: not-allowed;
}.my-number-input.is-disabled .my-number-input__up,
.my-number-input.is-disabled .my-number-input__down {cursor: not-allowed;background-color: var(--background-color-light);
}.my-number-input.is-disabled .my-number-input__icon {color: var(--text-disabled);
}/* 尺寸变体 */
.my-number-input--large {width: 200px;
}.my-number-input--large .my-number-input__inner {height: 40px;font-size: 16px;
}.my-number-input--large .my-number-input__up,
.my-number-input--large .my-number-input__down {width: 40px;height: 20px;
}.my-number-input--small {width: 130px;
}.my-number-input--small .my-number-input__inner {height: 24px;font-size: 12px;
}.my-number-input--small .my-number-input__up,
.my-number-input--small .my-number-input__down {width: 24px;height: 12px;
}.my-number-input--small .my-number-input__icon {font-size: 10px;
} /* -----------------my-pagination---------------------------- */
.my-pagination {display: flex;align-items: center;justify-content: center;gap: 8px;margin: 20px 0;
}.my-pagination__item {min-width: 32px;height: 32px;padding: 0 4px;display: flex;align-items: center;justify-content: center;border: 1px solid var(--border-color);border-radius: 4px;background-color: #fff;color: var(--text-primary);font-size: 14px;cursor: pointer;transition: all 0.3s;user-select: none;
}.my-pagination__item:hover {color: var(--primary-color);border-color: var(--primary-color);
}.my-pagination__item.is-active {background-color: var(--primary-color);color: #fff;border-color: var(--primary-color);
}.my-pagination__item.is-disabled {cursor: not-allowed;color: var(--text-disabled);background-color: var(--background-color-light);border-color: var(--border-color);
}.my-pagination__item--prev,
.my-pagination__item--next {font-size: 12px;
}.my-pagination__item--more {border: none;background: none;cursor: default;
}.my-pagination__item--more:hover {color: var(--text-primary);border: none;
}/* 响应式调整 */
@media (max-width: 768px) {.my-pagination {gap: 4px;}.my-pagination__item {min-width: 28px;height: 28px;font-size: 12px;}
} /* ---------------my-table------------------------------ */.my-table {width: 100%;border-collapse: collapse;background-color: var(--background-color);font-size: 14px;margin-bottom: 20px;}.my-table th,.my-table td {padding: 12px 15px;text-align: left;border-bottom: 1px solid var(--border-color-light);}.my-table th {font-weight: bold;color: var(--text-primary);background-color: var(--background-color-light);}.my-table tbody tr {transition: .3s;}.my-table tbody tr:hover {background-color: var(--background-color-light);}/* 斑马纹表格 */.my-table--striped tbody tr:nth-child(even) {background-color: var(--background-color-light);}.my-table--striped tbody tr:hover {background-color: #f0f2f5;}/* 带边框的表格 */.my-table--bordered {border: 1px solid var(--border-color-light);}.my-table--bordered th,.my-table--bordered td {border: 1px solid var(--border-color-light);}/* 紧凑型表格 */.my-table--small th,.my-table--small td {padding: 8px 12px;}/* 状态样式 */.my-table__row--success {background-color: rgba(103, 194, 58, 0.1);}.my-table__row--warning {background-color: rgba(230, 162, 60, 0.1);}.my-table__row--danger {background-color: rgba(245, 108, 108, 0.1);}/* 固定表头 */.my-table-wrapper {max-height: 400px;overflow: auto;}.my-table--fixed-header {position: relative;}.my-table--fixed-header thead th {position: sticky;top: 0;z-index: 1;background-color: var(--background-color-light);}/* 响应式表格 */@media screen and (max-width: 768px) {.my-table-wrapper {overflow-x: auto;}.my-table {min-width: 600px;}} /* 横向卡片样式 */
/* .my-card--horizontal {margin-bottom: 1rem;
} */.my-card__row {display: flex;flex-direction: row;
}.my-card__image-col {flex: 0 0 33.333333%;max-width: 33.333333%;
}.my-card-left__image-col {flex: 0 0 35%;max-width: 100%;
}.my-card__content-col {flex: 1;padding: 0 1rem;
}.my-card-left__content-col {padding: 0;margin: 0;
}.my-card__text--muted {color: #6c757d;
}/* 响应式布局 */
@media (max-width: 768px) {.my-card__row {flex-direction: column;}.my-card__image-col {max-width: 100%;}.my-card__content-col {padding: 1rem;}
} /* -----------code-block---------------------------------- */
.code-block {position: relative;background-color: #fafafa;border-radius: 4px;margin: 16px 0;
}.code-block__header {display: flex;align-items: center;justify-content: space-between;padding: 8px 16px;background-color: #f5f7fa;border-bottom: 1px solid var(--border-color-light);border-radius: 4px 4px 0 0;
}.code-block__title {font-size: 14px;color: var(--text-secondary);
}.code-block__actions {display: flex;align-items: center;gap: 8px;
}.code-block__button {padding: 4px 8px;font-size: 12px;color: var(--text-secondary);background: transparent;border: none;cursor: pointer;display: flex;align-items: center;gap: 4px;transition: all 0.3s;
}.code-block__button:hover {color: var(--primary-color);
}.code-block__content {padding: 16px;overflow-x: auto;
}.code-block pre {margin: 0;padding: 0;background: transparent;
}.code-block code {display: block;font-family: Consolas, Monaco, 'Andale Mono', 'Ubuntu Mono', monospace;font-size: 14px;line-height: 1.5;color: var(--text-primary);
}/* 复制成功提示 */
.code-block__tooltip {position: absolute;top: 40px;right: 16px;padding: 6px 12px;background-color: var(--success-color);color: white;border-radius: 4px;font-size: 12px;opacity: 0;transform: translateY(-10px);transition: all 0.3s;
}.code-block__tooltip.is-visible {opacity: 1;transform: translateY(0);
}/* 源代码/渲染切换按钮组 */
.code-block__switch-group {display: inline-flex;border: 1px solid var(--border-color);border-radius: 4px;overflow: hidden;
}.code-block__switch {padding: 4px 12px;font-size: 12px;background: transparent;border: none;cursor: pointer;color: var(--text-regular);transition: all 0.3s;
}.code-block__switch.is-active {background-color: var(--primary-color);color: white;
}.code-block__switch:hover:not(.is-active) {background-color: var(--background-color-light);
}/* 展开/收起动画 */
.code-block__wrapper {max-height: 0;overflow: hidden;transition: max-height 0.3s ease-out;
}.code-block__wrapper.is-expanded {max-height: 1000px;
}/* 源代码/预览切换 */
.code-block__preview,
.code-block__source {display: none;
}.code-block__preview.is-visible,
.code-block__source.is-visible {display: block;
}/* 响应式调整 */
@media screen and (max-width: 768px) {.code-block__header {flex-direction: column;align-items: flex-start;gap: 8px;}.code-block__actions {width: 100%;justify-content: flex-end;}
}