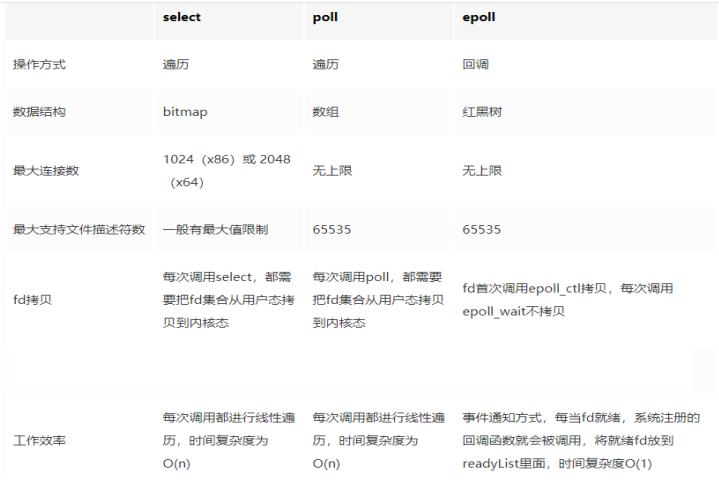
当谈到关系型数据库管理系统(RDBMS)时,MySQL无疑是最常见和广泛使用的一个。它是一个强大的工具,用于存储、管理和检索数据。在这篇博客中,我们将介绍MySQL的基本知识,包括数据库的操作、数据表的操作以及数据的增删改查~~
目录
1. 数据库的操作
1.1 创建数据库
1.2 删除数据库
1.3 选择数据库
2. 数据表的操作
2.1 创建数据表
2.2 修改数据表
2.3 删除数据表
3. 数据的增删改查
3.1 插入数据
3.2 更新数据
3.3 删除数据
3.4 查询数据
4.查询数据的具体知识点
1. 聚合函数
1.1 COUNT()
1.2 SUM()
1.3 AVG()
1.4 MAX()和MIN()
2. 连接
2.1 内连接(INNER JOIN)
2.2 左连接(LEFT JOIN)
3. 子查询
3.1 子查询作为过滤条件
3.2 子查询用于计算
4. 模糊查询
4.1 使用LIKE进行模糊查询
5. 排序数据
6. 过滤数据
6.1 使用BETWEEN过滤数据
6.2 使用IN过滤数据
6.3 使用LIMIT过滤数据
1. 数据库的操作
1.1 创建数据库
在MySQL中,创建一个新数据库非常简单。可以使用以下SQL语句:
CREATE DATABASE mydatabase charset utf8;

平时常用的字符集:
1.gbk windows简体中文版,默认字符集,2个字节表示一个汉字
2.utf8 更通用的字符集,不仅仅能表示中文,通常是3个字节表示一个汉字
3.unicode 其实严格来说,这个算编码方式,不能算一个完全的字符集
1.2 删除数据库
如果需要删除一个数据库,可以使用以下SQL语句:
DROP DATABASE mydatabase;
请注意,这将永久删除数据库及其所有数据,因此要谨慎使用。
1.3 选择数据库
使用以下命令来选择要在其上执行操作的数据库:
USE mydatabase;
2. 数据表的操作
2.1 创建数据表
创建数据表时,您需要定义表的结构,包括列的名称、数据类型和其他约束。以下是一个简单的示例:
CREATE TABLE users (id INT AUTO_INCREMENT,username VARCHAR(50),email VARCHAR(100),age INT
);

float和double都是用于定义表格列(字段)数据类型的关键词 ,但是二者表示的精度都不够,为什么呢~~
其实是跟内存存储结构有关,这两个表示方式的好处是存储空间小,计算速度快,但是可能存在误差~
使用decimal,是使用了类似字符串的方式来保存,更精确储存,但是存储空间更大,计算速度更慢了~

2.2 修改数据表
您可以使用ALTER TABLE命令来修改数据表的结构。例如,添加新列:
ALTER TABLE users
ADD phone VARCHAR(20);
2.3 删除数据表
要删除一个数据表,可以使用以下SQL语句:
DROP TABLE users;
3. 数据的增删改查
3.1 插入数据
要向数据表中插入新的数据行,使用INSERT INTO语句:
INSERT INTO users (username, email, age)
VALUES ('john_doe', 'john@example.com', 30);
3.2 更新数据
使用UPDATE语句来修改现有的数据行:
UPDATE users
SET age = 31
WHERE username = 'john_doe';
3.3 删除数据
使用DELETE语句来删除数据行:
DELETE FROM users
WHERE username = 'john_doe';
3.4 查询数据
要从数据表中检索数据,使用SELECT语句:
SELECT * FROM users;
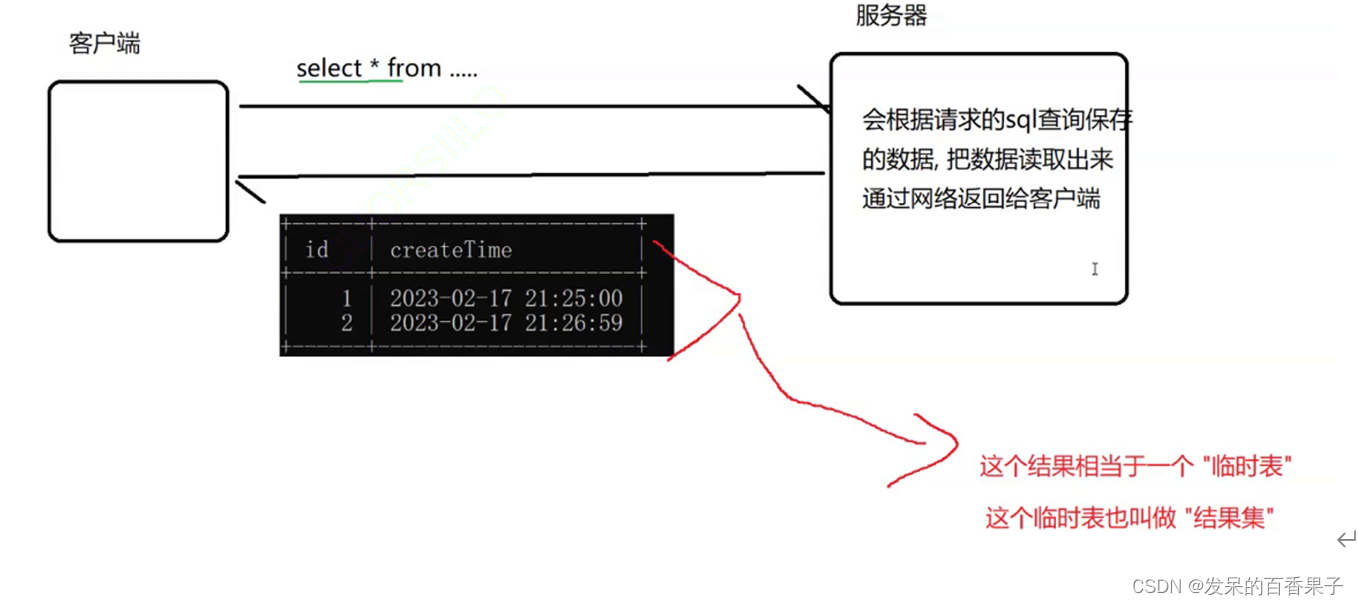

临时表显示一下就销毁了,和服务器那边的硬盘上的表没啥关系~~

您还可以添加条件来过滤数据:
SELECT * FROM users
WHERE age > 25;

举个例子~


4.查询数据的具体知识点

所以不能写where XXX=null这样~
可以写where XXX is null~

1. 聚合函数
聚合函数允许您对数据进行汇总和计算。以下是一些常见的聚合函数:
1.1 COUNT()
COUNT()函数用于计算行数或特定列的非空值数量。
SELECT COUNT(*) FROM users; -- 计算用户总数1.2 SUM()
SUM()函数用于计算数值列的总和。
SELECT SUM(salary) FROM employees; -- 计算员工工资总和
1.3 AVG()
AVG()函数用于计算数值列的平均值。
SELECT AVG(age) FROM users; -- 计算用户年龄平均值
1.4 MAX()和MIN()
MAX()和MIN()函数分别用于找到数值列中的最大值和最小值。
SELECT MAX(score) FROM exam_results; -- 找到最高分
SELECT MIN(price) FROM products; -- 找到最低价格
2. 连接
连接操作允许您将多个表的数据合并在一起,以便一起查询。以下是一些常见的连接类型:
2.1 内连接(INNER JOIN)
内连接返回匹配的行,仅包括两个表中都存在的数据。
SELECT orders.order_id, customers.customer_name
FROM orders
INNER JOIN customers ON orders.customer_id = customers.customer_id;
2.2 左连接(LEFT JOIN)
左连接返回左表中的所有行以及右表中与左表匹配的行。如果右表中没有匹配的行,将返回NULL。
比如存在一个只有名字没有成绩的记录和一个只有成绩没有名字的记录~
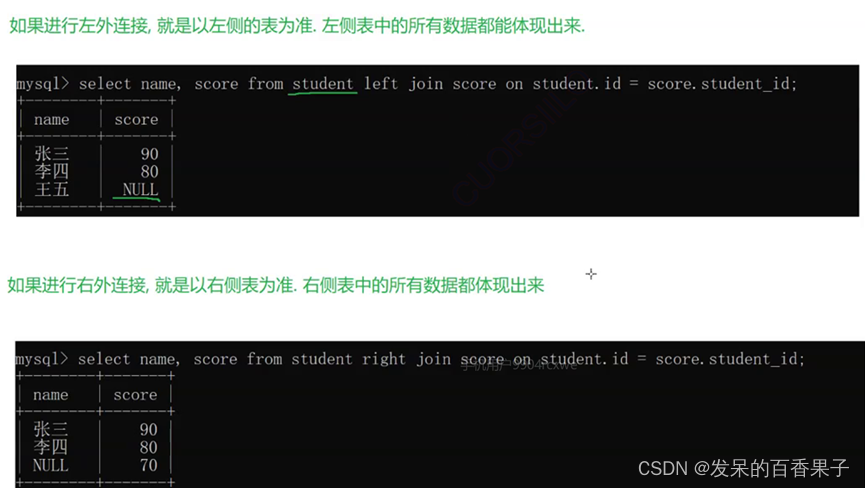
3. 子查询
子查询是在查询中嵌套的查询。它们可以用于过滤、计算和比较数据。
3.1 子查询作为过滤条件
SELECT product_name, product_price
FROM products
WHERE product_price > (SELECT AVG(product_price) FROM products);
3.2 子查询用于计算
SELECT department_name, (SELECT AVG(salary) FROM employees WHERE employees.department_id = departments.department_id) AS avg_salary
FROM departments;
4. 模糊查询
4.1 使用LIKE进行模糊查询
LIKE操作符用于在文本列中执行模糊查询。通配符 % 表示零个或多个字符,_ 表示一个字符。例如,要查找以 "李" 开头的用户名:
SELECT * FROM users
WHERE username LIKE '李%';
要查找包含 "doe" 的用户名:
SELECT * FROM users
WHERE username LIKE '%doe%';
5. 排序数据
使用ORDER BY子句对查询结果进行排序。例如,按年龄升序排序:
SELECT * FROM users
ORDER BY age ASC;
按用户名降序排序:
SELECT * FROM users
ORDER BY username DESC;
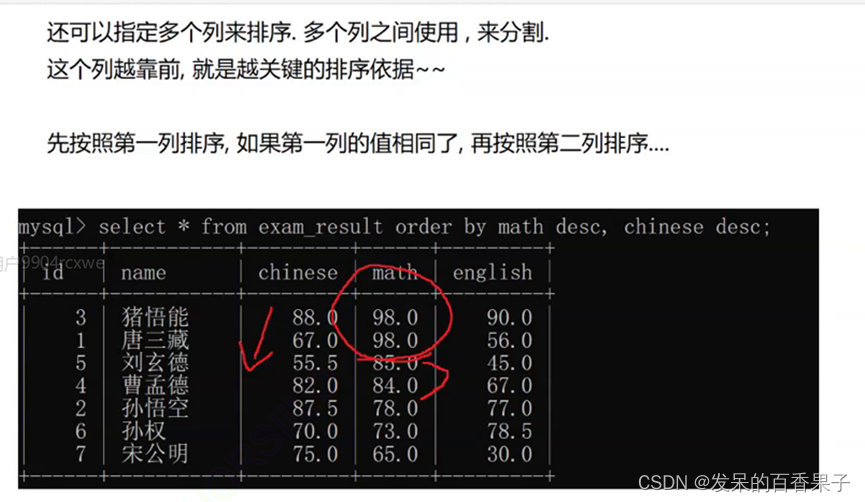
6. 过滤数据
6.1 使用BETWEEN过滤数据
BETWEEN关键字用于选择在指定范围内的数据。例如,查找年龄在25到35之间的用户:
SELECT * FROM users
WHERE age BETWEEN 25 AND 35;
6.2 使用IN过滤数据
IN关键字用于匹配多个条件中的一个。例如,查找特定用户名的用户:
SELECT * FROM users
WHERE username IN ('john_doe', 'jane_smith');
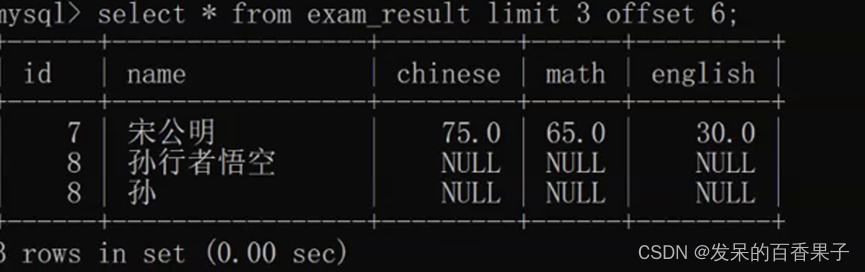
6.3 使用LIMIT过滤数据
SELECT * FROM users
WHERE username IN ('john_doe', 'jane_smith')
limit 2;

举个例子~