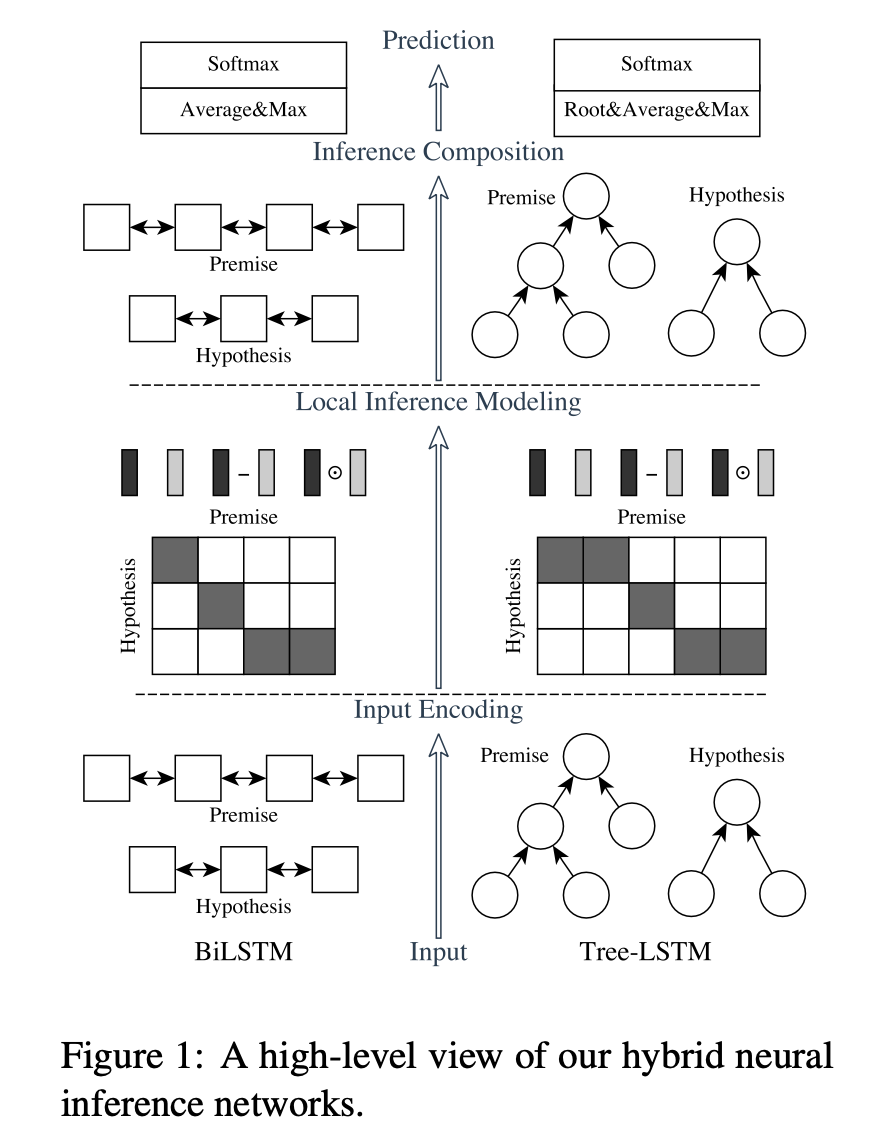
filter算子
接受一个函数,可用lambda快速编写;函数对RDD 数据逐个处理,得到True的保留到返回值的RDD中
"""
filter成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 对RDD的数据进行过滤
rdd2 = rdd.filter(lambda num: num % 2 == 0)
print(rdd2.collect())
distinct算子
对RDD数据去重,返回新的RDD
"""
distinct成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 1, 3, 3, 5, 5, 7, 8, 8, 9, 10])
# 对RDD的数据进行去重
rdd2 = rdd.distinct()
print(rdd2.collect())
sortBy算子
基于制定的排序规则,对RDD数据进行排序
"""
演示RDD的sortBy成员方法的使用
"""
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# 1. 读取数据文件
rdd = sc.textFile("D:/hello.txt")
# 2. 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
# 3. 将所有单词都转换成二元元组,单词为Key,value设置为1
word_with_one_rdd = word_rdd.map(lambda word: (word, 1))
# 4. 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 5. 对结果进行排序
final_rdd = result_rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=1)
print(final_rdd.collect())
案例综合
完成练习案例:JSON商品统计
需求:
1. 各个城市销售额排名,从大到小
2. 全部城市,有哪些商品类别在售卖
3. 北京市有哪些商品类别在售卖
文件内容
{"id":1,"timestamp":"2019-05-08T01:03.00Z","category":"平板电脑","areaName":"北京","money":"1450"}|{"id":2,"timestamp":"2019-05-08T01:01.00Z","category":"手机","areaName":"北京","money":"1450"}|{"id":3,"timestamp":"2019-05-08T01:03.00Z","category":"手机","areaName":"北京","money":"8412"}
{"id":4,"timestamp":"2019-05-08T05:01.00Z","category":"电脑","areaName":"上海","money":"1513"}|{"id":5,"timestamp":"2019-05-08T01:03.00Z","category":"家电","areaName":"北京","money":"1550"}|{"id":6,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"杭州","money":"1550"}
{"id":7,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"北京","money":"5611"}|{"id":8,"timestamp":"2019-05-08T03:01.00Z","category":"家电","areaName":"北京","money":"4410"}|{"id":9,"timestamp":"2019-05-08T01:03.00Z","category":"家具","areaName":"郑州","money":"1120"}
{"id":10,"timestamp":"2019-05-08T01:01.00Z","category":"家具","areaName":"北京","money":"6661"}|{"id":11,"timestamp":"2019-05-08T05:03.00Z","category":"家具","areaName":"杭州","money":"1230"}|{"id":12,"timestamp":"2019-05-08T01:01.00Z","category":"书籍","areaName":"北京","money":"5550"}
{"id":13,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"5550"}|{"id":14,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"1261"}|{"id":15,"timestamp":"2019-05-08T03:03.00Z","category":"电脑","areaName":"杭州","money":"6660"}
{"id":16,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"天津","money":"6660"}|{"id":17,"timestamp":"2019-05-08T01:03.00Z","category":"书籍","areaName":"北京","money":"9000"}|{"id":18,"timestamp":"2019-05-08T05:01.00Z","category":"书籍","areaName":"北京","money":"1230"}
{"id":19,"timestamp":"2019-05-08T01:03.00Z","category":"电脑","areaName":"杭州","money":"5551"}|{"id":20,"timestamp":"2019-05-08T01:01.00Z","category":"电脑","areaName":"北京","money":"2450"}
{"id":21,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"5520"}|{"id":22,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"6650"}
{"id":23,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"1240"}|{"id":24,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"天津","money":"5600"}
{"id":25,"timestamp":"2019-05-08T01:03.00Z","category":"食品","areaName":"北京","money":"7801"}|{"id":26,"timestamp":"2019-05-08T01:01.00Z","category":"服饰","areaName":"北京","money":"9000"}
{"id":27,"timestamp":"2019-05-08T01:03.00Z","category":"服饰","areaName":"杭州","money":"5600"}|{"id":28,"timestamp":"2019-05-08T01:01.00Z","category":"食品","areaName":"北京","money":"8000"}|{"id":29,"timestamp":"2019-05-08T02:03.00Z","category":"服饰","areaName":"杭州","money":"7000"}
代码实现
from pyspark import SparkConf, SparkContext
import os
import json
os.environ['PYSPARK_PYTHON'] = 'D:/dev/python/python310/python.exe'
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)# TODO 需求1: 城市销售额排名
# 1.1 读取文件得到RDD
file_rdd = sc.textFile("D:/orders.txt")
# 1.2 取出一个个JSON字符串
json_str_rdd = file_rdd.flatMap(lambda x: x.split("|"))
# 1.3 将一个个JSON字符串转换为字典
dict_rdd = json_str_rdd.map(lambda x: json.loads(x))
# 1.4 取出城市和销售额数据
# (城市,销售额)
city_with_money_rdd = dict_rdd.map(lambda x: (x['areaName'], int(x['money'])))
# 1.5 按城市分组按销售额聚合
city_result_rdd = city_with_money_rdd.reduceByKey(lambda a, b: a + b)
# 1.6 按销售额聚合结果进行排序
result1_rdd = city_result_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)
print("需求1的结果:", result1_rdd.collect())
# TODO 需求2: 全部城市有哪些商品类别在售卖
# 2.1 取出全部的商品类别
category_rdd = dict_rdd.map(lambda x: x['category']).distinct()
print("需求2的结果:", category_rdd.collect())
# 2.2 对全部商品类别进行去重
# TODO 需求3: 北京市有哪些商品类别在售卖
# 3.1 过滤北京市的数据
beijing_data_rdd = dict_rdd.filter(lambda x: x['areaName'] == '北京')
# 3.2 取出全部商品类别
result3_rdd = beijing_data_rdd.map(lambda x: x['category']).distinct()
print("需求3的结果:", result3_rdd.collect())
# 3.3 进行商品类别去重