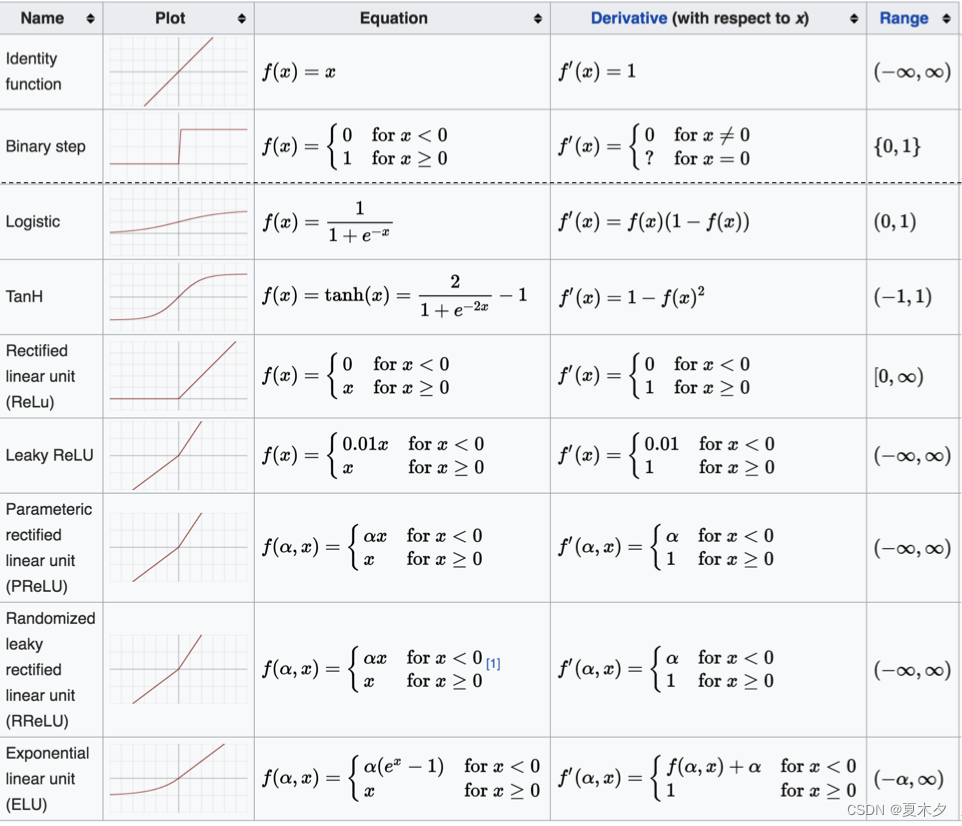
AI视野·今日CS.NLP 自然语言处理论文速览
Mon, 18 Sep 2023
Totally 51 papers
👉上期速览✈更多精彩请移步主页

Daily Computation and Language Papers
| "Merge Conflicts!" Exploring the Impacts of External Distractors to Parametric Knowledge Graphs Authors Cheng Qian, Xinran Zhao, Sherry Tongshuang Wu 大型语言模型法学硕士在预训练期间获得广泛的知识,称为参数知识。然而,为了保持最新状态并与人类指令保持一致,法学硕士在与用户交互时不可避免地需要外部知识。这就提出了一个关键问题:当外部知识干扰他们的参数知识时,法学硕士将如何应对。为了研究这个问题,我们提出了一个系统地引出法学硕士参数知识并引入外部知识的框架。具体来说,我们通过构建参数化知识图来揭示LLM的不同知识结构,并通过不同程度、方法、位置和格式的干扰因素引入外部知识,从而揭示影响。我们对黑盒和开源模型的实验表明,法学硕士往往会产生偏离其参数知识的响应,特别是当他们在详细上下文中遇到直接冲突或混淆信息变化时。我们还发现,虽然法学硕士对外部知识的准确性很敏感,但他们仍然可能会被不相关的信息分散注意力。这些发现强调了在与当前法学硕士的互动过程中,即使是间接整合外部知识时,也存在产生幻觉的风险。 |
| Are Multilingual LLMs Culturally-Diverse Reasoners? An Investigation into Multicultural Proverbs and Sayings Authors Chen Cecilia Liu, Fajri Koto, Timothy Baldwin, Iryna Gurevych 大型语言模型法学硕士非常擅长回答问题和推理任务,但在情境上下文中进行推理时,人类的期望会根据相关的文化共同点而有所不同。由于人类语言与多元文化相关,法学硕士也应该是文化多元的推理者。在本文中,我们研究了各种最先进的多语言法学硕士 mLLM 在对话环境中用谚语和俗语进行推理的能力。我们的实验表明,1 mLLM 知道的谚语有限,记住谚语并不意味着在对话环境中理解它们;2 mLLM 很难用比喻谚语和俗语进行推理,当被要求选择错误答案而不是要求其选择正确答案时, 3 mLLM 在推理从其他语言翻译的谚语和俗语时存在文化差距。 |
| Neural Machine Translation Models Can Learn to be Few-shot Learners Authors Raphael Reinauer, Patrick Simianer, Kaden Uhlig, Johannes E. M. Mosig, Joern Wuebker 大型语言模型使用少量示例来学习执行新领域和任务的新兴能力,也称为上下文学习 ICL。在这项工作中,我们展示了通过针对专门的训练目标进行微调,可以训练更小的模型来执行 ICL,例如神经机器翻译的域适应任务。凭借 ICL 的这种能力,模型可以利用相关的少数镜头示例来调整其输出以适应域。我们将这种领域适应的质量与传统监督技术和具有 40B 参数大型语言模型的 ICL 进行比较。 |
| ICLEF: In-Context Learning with Expert Feedback for Explainable Style Transfer Authors Arkadiy Saakyan, Smaranda Muresan 虽然最先进的语言模型在风格迁移任务上表现出色,但当前的工作并未解决风格迁移系统的可解释性问题。可以使用 GPT 3.5 和 GPT 4 等大型语言模型来生成解释,但当存在更小、分布广泛且透明的替代方案时,使用此类复杂系统的效率很低。我们提出了一个框架来增强和改进形式风格传输数据集,并通过 ChatGPT 的模型蒸馏进行解释。为了进一步完善生成的解释,我们提出了一种新颖的方法,通过提示 ChatGPT 充当其自身输出的批评者,将稀缺的专家人类反馈纳入上下文学习 ICLEF In Context Learning from Expert Feedback 中。我们使用由 9,960 个可解释的形式风格传输实例组成的数据集 e GYAFC 来展示当前的开放分布式指令调整模型,并且在某些设置中,ChatGPT 在任务上表现不佳,而对我们的高质量数据集的微调会带来显着的改进,如通过自动评估显示。在人类评估中,我们表明,比 ChatGPT 小得多的模型在我们的数据上进行了微调,更好地符合专家的偏好。 |
| Casteist but Not Racist? Quantifying Disparities in Large Language Model Bias between India and the West Authors Khyati Khandelwal, Manuel Tonneau, Andrew M. Bean, Hannah Rose Kirk, Scott A. Hale 现在每天有数百万用户使用的大型语言模型法学硕士可以编码社会偏见,使其用户面临代表性伤害。存在大量关于法学硕士偏见的学术研究,但它们主要采用以西方为中心的框架,而相对较少地关注南半球的偏见水平和潜在危害。在本文中,我们根据以印度为中心的框架量化了流行法学硕士中的刻板偏见,并比较了印度和西方背景之间的偏见水平。为此,我们开发了一个新颖的数据集,称为 Indian BhED 印度偏见评估数据集,其中包含种姓和宗教背景的刻板印象和反刻板印象示例。我们发现,大多数接受测试的法学硕士都强烈偏向于印度背景下的刻板印象,特别是与西方背景相比。最后,我们将指令提示作为一种减轻这种偏见的简单干预措施进行了研究,发现它在 GPT 3.5 的大多数情况下显着减少了刻板印象和反刻板印象偏见。 |
| How Transferable are Attribute Controllers on Pretrained Multilingual Translation Models? Authors Danni Liu, Jan Niehues 定制机器翻译模型以符合形式等细粒度属性最近取得了巨大进展。然而,当前的方法主要依赖于至少一些带有属性注释的监督数据。因此,数据稀缺仍然是使这种定制可能性民主化到更广泛的语言(尤其是资源较低的语言)的瓶颈。鉴于预训练的大规模多语言翻译模型的最新进展,我们使用它们作为基础,将属性控制能力转移到没有监督数据的语言。在这项工作中,我们基于预训练的 NLLB 200 模型对传输属性控制器进行了全面分析。我们研究了各种数据场景下的训练和推理时间控制技术,并揭示了它们在零样本性能和领域鲁棒性方面的相对优势和劣势。我们证明这两种范式是互补的,如 5 个零射击方向的一致改进所示。此外,对真正的低资源语言孟加拉语的人工评估证实了我们关于零镜头迁移到新目标语言的发现。 |
| Augmenting conformers with structured state space models for online speech recognition Authors Haozhe Shan, Albert Gu, Zhong Meng, Weiran Wang, Krzysztof Choromanski, Tara Sainath 在线语音识别(模型仅访问左侧的上下文)是 ASR 系统的一个重要且具有挑战性的用例。在这项工作中,我们通过合并结构化状态空间序列模型 S4 来研究用于在线 ASR 的增强神经编码器,S4 是一系列模型,提供了访问任意长左上下文的参数有效方式。我们进行系统的消融研究来比较 S4 模型的变体,并提出两种将它们与卷积相结合的新颖方法。我们发现最有效的设计是将使用实值循环权重的小型 S4 与局部卷积堆叠起来,使它们能够互补地工作。 |
| Connecting Large Language Models with Evolutionary Algorithms Yields Powerful Prompt Optimizers Authors Qingyan Guo, Rui Wang, Junliang Guo, Bei Li, Kaitao Song, Xu Tan, Guoqing Liu, Jiang Bian, Yujiu Yang 大型语言模型法学硕士在各种任务中表现出色,但他们依赖于精心设计的提示,而这些提示通常需要大量的人力。为了自动化这个过程,在本文中,我们提出了一种新颖的离散提示优化框架,称为 EvoPrompt,它借鉴了进化算法 EA 的思想,因为它们表现出良好的性能和快速收敛。为了使 EA 能够处理离散提示(这些提示是需要连贯且人类可读的自然语言表达),我们将 LLM 与 EA 连接起来。这种方法使我们能够同时利用 LLM 强大的语言处理能力和 EA 的高效优化性能。具体来说,EvoPrompt 放弃任何梯度或参数,从提示群体开始,并根据进化算子使用 LLM 迭代生成新的提示,并根据开发集改进群体。我们在涵盖语言理解和生成任务的 9 个数据集上优化了封闭式和开源 LLM 的提示,包括 GPT 3.5 和 Alpaca。 EvoPrompt 的性能明显优于人工设计的提示和现有的自动提示生成方法,分别高达 25 和 14。 |
| HealthFC: A Dataset of Health Claims for Evidence-Based Medical Fact-Checking Authors Juraj Vladika, Phillip Schneider, Florian Matthes 在互联网上寻求健康相关建议已成为数字时代的常见做法。确定在线发现的医疗声明的可信度并为这些信息找到适当的证据越来越具有挑战性。事实核查已成为一种利用来自可靠知识来源的证据来评估事实主张的真实性的方法。为了帮助推进这项任务的自动化,在本文中,我们引入了一个包含 750 个健康相关声明的新数据集,由医学专家标记其准确性,并以适当的临床研究的证据为支持。我们对数据集进行分析,强调其特征和挑战。该数据集可用于与自动事实检查相关的机器学习任务,例如证据检索、准确性预测和解释生成。 |
| Using Large Language Models for Knowledge Engineering (LLMKE): A Case Study on Wikidata Authors Bohui Zhang, Ioannis Reklos, Nitisha Jain, Albert Mero o Pe uela, Elena Simperl 在这项工作中,我们探索了在 ISWC 2023 LM KBC 挑战背景下使用大型语言模型 LLM 执行知识工程任务。对于此任务,给定来自维基数据的主题和关系对,我们利用预先训练的 LLM 生成字符串格式的相关对象,并将它们链接到各自的维基数据 QID。我们使用LLM知识工程LLMKE开发了一个管道,结合了知识探测和维基数据实体映射。该方法在所有属性上实现了 0.701 的宏观平均 F1 得分,得分范围为 1.00 到 0.328。这些结果表明,法学硕士的知识根据领域的不同而有很大差异,并且需要进一步的实验来确定法学硕士可以用于自动知识库的情况,例如维基数据的补全和更正。对结果的调查还表明法学硕士在协作知识工程方面的有前景的贡献。 LLMKE 赢得了挑战赛的第二场比赛。 |
| SilverRetriever: Advancing Neural Passage Retrieval for Polish Question Answering Authors Piotr Rybak, Maciej Ogrodniczuk 现代开放域问答系统通常依赖于准确且高效的检索组件来查找包含回答问题所需事实的段落。最近,神经检索器由于其卓越的性能而比词汇检索器更受欢迎。然而,大部分工作涉及英语或汉语等流行语言。对于其他国家,例如波兰语,可用的模型很少。在这项工作中,我们提出了 SilverRetriever,这是一种波兰语神经检索器,在各种手动或弱标记数据集上进行训练。 SilverRetriever 比其他波兰模型取得了更好的结果,并且与更大的多语言模型具有竞争力。 |
| Advancing the Evaluation of Traditional Chinese Language Models: Towards a Comprehensive Benchmark Suite Authors Chan Jan Hsu, Chang Le Liu, Feng Ting Liao, Po Chun Hsu, Yi Chang Chen, Da shan Shiu 大型语言模型的评估是语言理解和生成领域的一项重要任务。随着语言模型的不断进步,有效的基准来评估其性能变得势在必行。在繁体中文背景下,尽管存在DRCD、TTQA、CMDQA和FGC数据集等某些基准,但缺乏全面且多样化的基准来评估语言模型的能力。为了解决这一差距,我们提出了一套新颖的基准,利用现有的英语数据集,并专门用于评估繁体中文的语言模型。这些基准涵盖广泛的任务,包括上下文问答、总结、分类和表格理解。拟议的基准提供了一个全面的评估框架,可以评估跨不同任务的语言模型能力。在本文中,我们根据这些基准评估了 GPT 3.5、台湾 LLaMa v1.0 和我们的专有模型 Model 7 C 的性能。评估结果表明,我们的模型 Model 7 C 在部分评估功能方面实现了与 GPT 3.5 相当的性能。 |
| Unleashing Potential of Evidence in Knowledge-Intensive Dialogue Generation Authors Xianjie Wu, Jian Yang, Tongliang Li, Di Liang, Shiwei Zhang, Yiyang Du, Zhoujun Li 将外部知识纳入对话生成 KIDG 对于提高响应的正确性至关重要,其中证据片段作为支持事实对话回复的知识片段。然而,引入不相关的内容往往会对回复质量产生不利影响,并且容易导致出现幻觉回复。对话系统中证据检索和集成的先前工作未能充分利用现有证据,因为该模型无法准确定位有用的片段,并且忽略了 KIDG 数据集中隐藏的证据标签。为了充分释放证据的潜力,我们提出了一个框架,将证据有效地纳入知识密集型对话生成 u EIDG 中。具体来说,我们引入了一个自动证据生成框架,该框架利用大型语言模型法学硕士的力量从未标记的数据中挖掘可靠的证据准确性标签。通过利用这些证据标签,我们训练了可靠的证据指示器,以有效地从检索到的段落中识别相关证据。此外,我们提出了一种具有证据集中注意力机制的证据增强生成器,该机制允许模型专注于证据片段。 MultiDoc2Dial 上的实验结果证明了证据标签增强和细化注意力机制在提高模型性能方面的功效。 |
| Headless Language Models: Learning without Predicting with Contrastive Weight Tying Authors Nathan Godey, ric de la Clergerie, Beno t Sagot 语言模型的自监督预训练通常包括预测广泛标记词汇表上的概率分布。在这项研究中,我们提出了一种创新方法,该方法摆脱了概率预测,而是专注于通过对比权重绑定 CWT 以对比方式重建输入嵌入。我们应用这种方法在单语言和多语言环境中预训练无头语言模型。我们的方法具有实际优势,可将训练计算要求大幅降低多达 20 倍,同时提高下游性能和数据效率。 |
| Reward Engineering for Generating Semi-structured Explanation Authors Jiuzhou Han, Wray Buntine, Ehsan Shareghi 半结构化解释用显式表示描述了推理器的隐式过程。此解释强调了如何用推理器从其内部权重生成的信息来补充特定查询中的可用信息以生成答案。尽管语言模型的生成能力最近有所改进,但生成结构化解释来验证模型的真实推理能力仍然是一个挑战。这个问题对于不太大的 LM 来说尤其明显,因为推理器需要将顺序答案与结构化解释结合起来,其中体现了正确的表示和正确的推理过程。在这项工作中,我们首先强调了监督微调 SFT 在应对这一挑战方面的局限性,然后在强化学习 RL 中引入了精心设计的奖励工程方法,以更好地解决这一问题。我们研究了多种奖励聚合方法,并提供了详细的讨论,揭示了强化学习在未来研究中的巨大潜力。 |
| Data Distribution Bottlenecks in Grounding Language Models to Knowledge Bases Authors Yiheng Shu, Zhiwei Yu 语言模型 LM 已经在理解和生成自然语言和形式语言方面表现出了卓越的能力。尽管取得了这些进步,但它们与大规模知识库 KB 等现实世界环境的集成仍然是一个不发达的领域,影响了语义解析等应用程序和沉迷于幻觉信息。本文是一项实验研究,旨在揭示 LM 在执行知识库问答 KBQA 任务时遇到的鲁棒性挑战。该调查涵盖了训练和推理之间数据分布不一致的场景,例如对未见过的领域的泛化、对各种语言变化的适应以及跨不同数据集的可转移性。我们的综合实验表明,即使采用我们提出的数据增强技术,先进的小型和大型语言模型在各个维度上也表现出较差的性能。虽然LM是一项很有前景的技术,但由于数据分布问题,当前形式在处理复杂环境时的鲁棒性很脆弱,实用性有限。 |
| Distributional Inclusion Hypothesis and Quantifications: Probing Hypernymy in Functional Distributional Semantics Authors Chun Hei Lo, Guy Emerson 功能分布语义 FDS 通过真值条件函数对单词的含义进行建模。这为上位词提供了自然的表示,但不能保证在语料库上训练 FDS 模型时能够学习到它。我们证明,当语料库严格遵循分布包含假设时,FDS 模型可以学习上位词。我们进一步引入了一个训练目标,允许 FDS 处理简单的通用量化,从而在 DIH 的相反情况下实现上位学习。 |
| Bridging Topic, Domain, and Language Shifts: An Evaluation of Comprehensive Out-of-Distribution Scenarios Authors Andreas Waldis, Iryna Gurevych 语言模型 LM 在训练和测试数据独立且同分布的分布 ID 场景中表现出色。然而,它们的性能在现实世界的应用程序(例如参数挖掘)中通常会下降。当新主题出现或其他文本域和语言变得相关时,就会发生这种退化。 |
| Self-Consistent Narrative Prompts on Abductive Natural Language Inference Authors Chunkit Chan, Xin Liu, Tsz Ho Chan, Jiayang Cheng, Yangqiu Song, Ginny Wong, Simon See 长期以来,溯因一直被认为对于日常情境的叙事理解和推理至关重要。溯因自然语言推理 alpha NLI 任务已经被提出,这种基于叙事文本的任务旨在从给定两个观察的候选者中推断出最合理的假设。然而,在之前的这项任务的工作中,句子间的连贯性和模型的一致性并没有得到很好的利用。在这项工作中,我们提出了一种即时调整模型 alpha PACE,该模型考虑了自我一致性和句子间连贯性。此外,我们提出了一个通用的自洽框架,考虑各种叙事序列,例如线性叙事和逆向时间顺序,以指导预先训练的语言模型理解输入的叙事上下文。我们进行了广泛的实验和彻底的消融研究,以说明 alpha PACE 的必要性和有效性。 |
| Structural Self-Supervised Objectives for Transformers Authors Luca Di Liello |
| Investigating Answerability of LLMs for Long-Form Question Answering Authors Meghana Moorthy Bhat, Rui Meng, Ye Liu, Yingbo Zhou, Semih Yavuz 随着我们进入法学硕士的新时代,了解他们的能力、局限性和差异变得越来越重要。为了在这个方向上取得进一步进展,我们努力更深入地了解大型法学硕士(例如 ChatGPT)与规模较小但有效的开源法学硕士及其精炼同行之间的差距。为此,我们特别关注长篇问答 LFQA,因为它有几个实用且有影响力的应用,例如故障排除、客户服务等,但对于法学硕士来说仍然没有得到充分研究和挑战。我们提出了一种从抽象摘要生成问题的方法,并表明从长文档摘要生成后续问题可以为法学硕士从长上下文中进行推理和推断创造一个具有挑战性的环境。我们的实验结果证实 1 我们提出的从抽象摘要生成问题的方法对 LLM 提出了一个具有挑战性的设置,并显示了 ChatGPT 等 LLM 与开源 LLM 之间的性能差距 Alpaca、Llama 2 开源 LLM 表现出对上下文生成问题的依赖程度降低 |
| Encoded Summarization: Summarizing Documents into Continuous Vector Space for Legal Case Retrieval Authors Vu Tran, Minh Le Nguyen, Satoshi Tojo, Ken Satoh 我们通过引入我们的编码文档的方法,通过利用深度神经网络的短语评分框架将文档汇总到连续向量空间中,来介绍我们处理法律案件检索任务的方法。另一方面,我们探索了将词汇特征和神经网络生成的潜在特征相结合的好处。我们的实验表明,神经网络生成的词汇特征和潜在特征相互补充,可以提高检索系统的性能。此外,我们的实验结果表明使用提供的摘要和执行编码摘要在不同方面进行案例摘要的重要性。 |
| Multilingual Sentence-Level Semantic Search using Meta-Distillation Learning Authors Meryem M hamdi, Jonathan May, Franck Dernoncourt, Trung Bui, Seunghyun Yoon 多语言语义搜索是检索以不同语言组合表达的查询的相关内容的任务。这需要更好地理解用户的意图及其上下文含义。由于缺乏用于这项任务的多语言并行资源以及需要规避语言偏见,多语言语义搜索比单语言或双语同行进行的探索较少且更具挑战性。在这项工作中,我们提出了一种对齐方法 MAML Align,专门针对低资源场景。我们的方法利用基于 MAML 的元蒸馏学习,MAML 是一种基于优化的模型不可知元学习器。 MAML Align 将知识从教师元转移模型 T MAML(专门从事从单语语义搜索转移到双语语义搜索)和学生模型 S MAML(从双语语义搜索转移到多语言语义搜索)中提取知识。据我们所知,我们是第一个将元蒸馏扩展到多语言搜索应用程序的人。我们的实证结果表明,除了基于句子转换器的强大基线之外,我们的元蒸馏方法还提高了 MAML 提供的增益,并且显着优于朴素的微调方法。 |
| Using Large Language Model to Solve and Explain Physics Word Problems Approaching Human Level Authors Jingzhe Ding, Yan Cen, Xinyuan Wei 我们的工作表明,在文本上预训练的大型语言模型LLM不仅可以解决纯数学应用题,还可以解决基于一些先验物理知识通过计算和推理来解决的物理应用题。我们收集并注释了第一个物理应用题数据集 PhysQA,其中包含 1000 多个初中物理应用题,涉及运动学、质量密度、力学、热、电。然后我们使用 OpenAI 的 GPT3.5 生成这些问题的答案,发现 GPT3.5 可以自动解决 49.3 个零样本学习问题和 73.2 个少样本学习问题。这一结果表明,通过使用类似的问题及其答案作为提示,LLM可以解决接近人类水平的基础物理应用题。除了自动求解问题外,GPT3.5还可以总结问题所考察的知识或主题,生成相关解释,并根据输入问题合成新的物理应用题。我们的工作是第一个自动求解、解释和生成物理问题的研究 |
| Large Language Models for Failure Mode Classification: An Investigation Authors Michael Stewart, Melinda Hodkiewicz, Sirui Li 在本文中,我们首次对大型语言模型法学硕士在故障模式分类 FMC 中的有效性进行了调查。 FMC 是用相应的故障模式代码自动标记观察结果的任务,是维护领域的一项关键任务,因为它减少了可靠性工程师花时间手动分析工单的需要。我们详细介绍了提示工程的方法,使法学硕士能够使用受限代码列表预测给定观察的故障模式。我们证明,在带注释的数据上进行微调的 GPT 3.5 模型 F1 0.80 的性能比在相同带注释的数据集上训练的当前可用的文本分类模型 F1 0.60 有了显着的改进。经过微调的模型还优于开箱即用的 GPT 3.5 F1 0.46 。 |
| FedJudge: Federated Legal Large Language Model Authors Linan Yue, Qi Liu, Yichao Du, Weibo Gao, Ye Liu, Fangzhou Yao 大语言模型法学硕士在法律情报领域取得了显着的地位,为协助法律专业人士和外行提供了潜在的应用。然而,这些法律法学硕士的集中培训引发了数据隐私问题,因为法律数据分布在包含敏感个人信息的各个机构之间。本文通过探索法律法学硕士与联邦学习 FL 方法的整合来应对这一挑战。通过使用 FL,法律法学硕士可以在设备或客户端上进行本地微调,并且其参数在中央服务器上聚合和分布,从而在不直接共享原始数据的情况下确保数据隐私。然而,计算和通信开销阻碍了 FL 设置下 LLM 的全面微调。此外,法律数据的分布变化降低了FL方法的有效性。为此,在本文中,我们提出了第一个联邦法律大语言模型 FedJudge 框架,该框架可以高效且有效地对法律 LLM 进行微调。具体来说,FedJudge 利用参数高效的微调方法在 FL 训练期间仅更新一些附加参数。此外,我们探索了持续学习方法,以在训练本地客户以减轻数据转移问题时保留全局模型的重要参数。对三个现实世界数据集的广泛实验结果清楚地验证了 FedJudge 的有效性。 |
| LASER: LLM Agent with State-Space Exploration for Web Navigation Authors Kaixin Ma, Hongming Zhang, Hongwei Wang, Xiaoman Pan, Dong Yu 大型语言模型法学硕士已成功适应网络导航等交互式决策任务。在实现良好性能的同时,以前的方法隐式地假设模型仅前向执行模式,其中它们仅提供上下文示例中的预言轨迹,以教导模型如何在交互式环境中进行推理。因此,该模型无法处理上下文示例中未涵盖的更具挑战性的场景,例如错误,从而导致性能不佳。为了解决这个问题,我们建议将交互式任务建模为状态空间探索,其中 LLM 代理通过执行操作来完成任务,在一组预定义的状态之间进行转换。这种公式可以实现灵活的回溯,使模型能够轻松地从错误中恢复。我们在 WebShop 任务上使用 State Space ExploRation LASER 评估我们提出的 LLM Agent。 |
| Draft & Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding Authors Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, Sharad Mehrotra 我们提出了一种新颖的推理方案,即自推测解码,用于加速大型语言模型 LLM,而无需辅助模型。该方法的特点是起草和验证过程分为两个阶段。起草阶段以稍低的质量但更快地生成草稿令牌,这是通过在起草期间有选择地跳过某些中间层来实现的。随后,验证阶段采用原始 LLM 在一次前向传递中验证这些草稿输出令牌。此过程可确保最终输出与未更改的法学硕士产生的输出相同,从而保持输出质量。所提出的方法不需要额外的神经网络训练,也不需要额外的内存占用,使其成为一种即插即用且经济高效的推理加速解决方案。 |
| Investigating the Applicability of Self-Assessment Tests for Personality Measurement of Large Language Models Authors Akshat Gupta, Xiaoyang Song, Gopala Anumanchipalli 随着大型语言模型法学硕士的能力不断发展,最近的各种研究试图使用为研究人类行为而创建的心理工具来量化其行为。其中一个例子是使用性格自我评估测试来衡量法学硕士的性格。在本文中,我们对法学硕士的人格测量进行了三项此类研究,这些研究使用为研究人类行为而创建的人格自我评估测试。我们使用这三篇不同论文中使用的提示来衡量同一位法学硕士的个性。我们发现所有三个提示都会导致截然不同的性格得分。这个简单的测试揭示了法学硕士的人格自我评估分数取决于提示者的主观选择。由于我们不知道法学硕士人格分数的真实值,因为此类问题没有正确答案,因此无法断言一个提示是否比另一个提示更正确或更不正确。然后我们介绍了法学硕士人格测量的期权顺序对称性。由于大多数自我评估测试都以多项选择题 MCQ 问题的形式存在,因此我们认为分数不仅对于提示模板而且对于选项呈现的顺序也应该是稳健的。该测试毫不奇怪地表明,自我评估测试的答案对于选项的顺序并不稳健。 |
| RADE: Reference-Assisted Dialogue Evaluation for Open-Domain Dialogue Authors Zhengliang Shi, Weiwei Sun, Shuo Zhang, Zhen Zhang, Pengjie Ren, Zhaochun Ren 由于一对多问题等原因,评估开放域对话系统具有挑战性,即除了黄金响应之外还有许多适当的响应。到目前为止,自动评估方法需要与人类更好的一致性,而可靠的人类评估可能会耗费时间和成本。为此,我们提出了多任务学习框架下的参考辅助对话评估RADE方法,该方法利用预先创建的话语作为参考而不是黄金响应来缓解一对多问题。具体来说,RADE 明确比较参考和候选人的反应以预测他们的总体分数。此外,辅助响应生成任务通过共享编码器增强预测。为了支持 RADE,我们扩展了三个数据集,添加了额外的评级响应,而不仅仅是人工注释的黄金响应。 |
| Unimodal Aggregation for CTC-based Speech Recognition Authors Ying Fang, Xiaofei Li 本文致力于非自回归自动语音识别。提出了一种单峰聚合UMA来分割和整合属于同一文本标记的特征帧,从而学习更好的文本标记特征表示。逐帧特征和权重均来自编码器。然后,具有单峰权重的特征帧被集成并由解码器进一步处理。应用连接主义时间分类 CTC 损失进行训练。与常规CTC相比,该方法学习了更好的特征表示并缩短了序列长度,从而降低了识别误差和计算复杂度。对三个普通话数据集的实验表明,UMA 表现出比其他先进的非自回归方法(例如自条件 CTC)优越或相当的性能。 |
| Research on Joint Representation Learning Methods for Entity Neighborhood Information and Description Information Authors Le Xiao, Xin Shan, Yuhua Wang, Miaolei Deng 针对编程设计课程知识图谱嵌入性能较差的问题,提出一种结合实体邻域信息和描述信息的联合表示学习模型。首先,采用图注意网络来获取实体相邻节点的特征,结合关系特征来丰富结构信息。接下来,结合注意力机制利用BERT WWM模型来获取实体描述信息的表示。最后,结合实体邻域信息和描述信息的向量表示,得到最终的实体向量表示。 |
| Connecting the Dots in News Analysis: A Cross-Disciplinary Survey of Media Bias and Framing Authors Gisela Vallejo, Timothy Baldwin, Lea Frermann 新闻报道中偏见的表现和影响几十年来一直是社会科学的中心话题,最近在 NLP 界受到越来越多的关注。虽然 NLP 可以帮助扩大分析范围或提供自动程序来调查有偏见的新闻对社会的影响,但我们认为,目前占主导地位的方法论不足以解决理论媒体研究中解决的复杂问题和影响。在这篇调查论文中,我们回顾了社会科学方法,并与 NLP 媒体偏见分析中使用的典型任务表述、方法和评估指标进行了比较。我们讨论悬而未决的问题,并提出可能的方向,以缩小理论和预测模型及其评估之间已确定的差距。 |
| Investigating Gender Bias in News Summarization Authors Julius Steen, Katja Markert 摘要是大型语言模型法学硕士的一个重要应用。之前大多数对摘要模型的评估都集中在其在内容选择、语法性和连贯性方面的表现。然而,众所周知,法学硕士会繁殖并强化有害的社会偏见。 |
| An Empirical Evaluation of Prompting Strategies for Large Language Models in Zero-Shot Clinical Natural Language Processing Authors Sonish Sivarajkumar, Mark Kelley, Alyssa Samolyk Mazzanti, Shyam Visweswaran, Yanshan Wang 大型语言模型法学硕士在自然语言处理 NLP 方面表现出了卓越的能力,特别是在标记数据稀缺或昂贵的领域,例如临床领域。然而,为了解锁这些法学硕士隐藏的临床知识,我们需要设计有效的提示,引导他们在没有任何任务特定训练数据的情况下执行特定的临床 NLP 任务。这被称为情境学习,这是一门艺术和科学,需要了解不同法学硕士的优点和缺点以及及时的工程方法。在本文中,我们对五种临床 NLP 任务(临床意义消歧、生物医学证据提取、共指消解、用药状态提取和用药属性提取)的提示工程进行了全面、系统的实验研究。我们评估了最近文献中提出的提示,包括简单前缀、简单完形填空、思维链和预期提示,并引入了两种新的提示类型,即启发式提示和整体提示。我们在三个最先进的法学硕士 GPT 3.5、BARD 和 LLAMA2 上评估了这些提示的性能。我们还将零次提示与少量提示进行了对比,并为临床 NLP 中法学硕士的提示工程提供了新颖的见解和指南。 |
| Exploring the Impact of Human Evaluator Group on Chat-Oriented Dialogue Evaluation Authors Sarah E. Finch, James D. Finch, Jinho D. Choi 人类评估已被广泛接受为评估面向聊天的对话系统的标准。然而,之前的工作在招募谁作为评估员方面存在显着差异。领域专家、大学生和专业注释者等评估者群体已被用来评估和比较对话系统,尽管目前尚不清楚评估者群体的选择会在多大程度上影响结果。本文通过使用 4 个不同的评估者群体测试 4 个最先进的对话系统,分析了评估者群体对对话系统评估的影响。我们的分析揭示了 Likert 评估对评估者群体的稳健性,而 Pairwise 则没有这种稳健性,在改变评估者群体时仅观察到微小差异。 |
| Leveraging Contextual Information for Effective Entity Salience Detection Authors Rajarshi Bhowmik, Marco Ponza, Atharva Tendle, Anant Gupta, Rebecca Jiang, Xingyu Lu, Qian Zhao, Daniel Preotiuc Pietro 在新闻文章等文本文档中,内容和关键事件通常围绕文档中提到的所有实体的子集。这些实体通常被视为显着实体,为读者提供有关文档内容的有用线索。人们发现,识别实体的显着性对于一些下游应用程序(例如搜索、排名和以实体为中心的摘要等)很有帮助。先前有关显着实体检测的工作主要集中在需要大量特征工程的机器学习模型上。我们表明,与特征工程方法相比,使用跨编码器风格架构微调中型语言模型可带来显着的性能提升。为此,我们使用代表中型预训练语言模型系列的模型对四个公开可用的数据集进行了全面的基准测试。 |
| Sparse Autoencoders Find Highly Interpretable Features in Language Models Authors Hoagy Cunningham, Aidan Ewart, Logan Riggs, Robert Huben, Lee Sharkey 更好地理解神经网络内部结构的障碍之一是文本多语义性,其中神经元似乎在多个语义不同的上下文中激活。多语义性使我们无法对神经网络内部的行为进行简洁的、人类可理解的解释。多语义性的一个假设原因是文本叠加,其中神经网络通过将特征分配给激活空间中一组超完整的方向而不是单个神经元来表示比其神经元更多的特征。在这里,我们尝试使用稀疏自动编码器来识别这些方向,以重建语言模型的内部激活。这些自动编码器学习一组稀疏激活的特征,这些特征比其他方法识别的方向更可解释和单一语义,其中可解释性是通过自动化方法测量的。消除这些功能可以实现精确的模型编辑,例如,通过删除代词预测等功能,同时比现有技术更少地破坏模型行为。这项工作表明可以使用可扩展的无监督方法来解决语言模型中的叠加。 |
| Chain-of-Thought Reasoning is a Policy Improvement Operator Authors Hugh Zhang, David C. Parkes 大型语言模型以其令人着迷的新功能震惊了世界。然而,他们目前缺乏自学新技能的能力,而是依赖大量人类生成的数据进行训练。我们通过思想链推理引入了 SECToR Self Education,这是一个概念证明,表明语言模型可以使用思想链推理成功地自学新技能。受到先前强化学习(Silver 等人,2017 年)和人类认知 Kahneman(2011 年)工作的启发,SECToR 首先使用思维链推理来慢慢思考解决问题的方法。然后,SECToR 微调模型以生成相同的答案,这一次不使用思维链推理。通过 SECToR 训练的语言模型可以自主学习将最多 29 位数字相加,除了仅包含 6 位或更少数字的初始监督微调阶段之外,无需访问任何真实示例。我们的中心假设是,思想推理链可以充当策略改进算子,类似于 AlphaZero 中使用蒙特卡罗树搜索的方式。 |
| When do Generative Query and Document Expansions Fail? A Comprehensive Study Across Methods, Retrievers, and Datasets Authors Orion Weller, Kyle Lo, David Wadden, Dawn Lawrie, Benjamin Van Durme, Arman Cohan, Luca Soldaini 使用大型语言模型 LM 进行查询或文档扩展可以提高信息检索的泛化能力。然而,尚不清楚这些技术是普遍有益还是仅在特定设置中有效,例如对于特定检索模型、数据集域或查询类型。为了回答这个问题,我们对基于 LM 的扩展进行了首次全面分析。我们发现,检索器性能和扩展收益之间存在很强的负相关性,扩展可以提高较弱模型的分数,但通常会损害较强的模型。我们证明了这一趋势在 11 种扩展技术、12 个具有不同分布变化的数据集以及 24 个检索模型中都成立。通过定性错误分析,我们假设虽然扩展提供了可能提高召回率的额外信息,但它们增加了额外的噪音,使得难以辨别最相关的文档,从而引入误报。 |
| Towards Practical and Efficient Image-to-Speech Captioning with Vision-Language Pre-training and Multi-modal Tokens Authors Minsu Kim, Jeongsoo Choi, Soumi Maiti, Jeong Hun Yeo, Shinji Watanabe, Yong Man Ro 在本文中,我们提出了构建强大且高效的图像到语音字幕 Im2Sp 模型的方法。为此,我们首先将大规模预训练视觉语言模型中与图像理解和语言建模相关的丰富知识导入到 Im2Sp 中。我们将所提出的 Im2Sp 的输出设置为离散语音单元,即自监督语音模型的量化语音特征。语音单元主要包含语言信息,同时抑制语音的其他特征。这使得我们能够将预训练的视觉语言模型的语言建模能力合并到 Im2Sp 的口语建模中。通过视觉语言预训练策略,我们在两个广泛使用的基准数据库 COCO 和 Flickr8k 上设置了最先进的 Im2Sp 性能。然后,我们进一步提高了 Im2Sp 模型的效率。与语音单元的情况类似,我们将原始图像转换为图像单元,这些图像单元是通过原始图像的矢量量化得出的。通过这些图像单元,与原始图像数据相比,我们可以将保存图像数据所需的数据存储量大幅减少至 0.8 位。 |
| Mixture Encoder Supporting Continuous Speech Separation for Meeting Recognition Authors Peter Vieting, Simon Berger, Thilo von Neumann, Christoph Boeddeker, Ralf Schl ter, Reinhold Haeb Umbach 自动语音识别 ASR 的许多实际应用都需要处理重叠语音。常见方法包括首先将语音分离为无重叠的流,然后对结果信号执行 ASR。最近,有人提出在 ASR 模型中加入混合编码器。该混合编码器利用原始重叠语音来减轻语音分离引入的伪影的影响。然而,此前该方法仅解决了两种说话人场景。在这项工作中,我们将这种方法扩展到更自然的会议环境,具有任意数量的发言者和动态重叠。我们使用不同的语音分离器评估性能,包括强大的 TF GridNet 模型。我们的实验展示了 LibriCSS 数据集上最先进的性能,并突出了混合编码器的优势。 |
| PatFig: Generating Short and Long Captions for Patent Figures Authors Dana Aubakirova, Kim Gerdes, Lufei Liu 本文介绍了 Qatent PatFig,这是一个新颖的大规模专利数据集,包含来自 11,000 多个欧洲专利申请的 30,000 个专利数据。对于每个图,该数据集提供了短标题和长标题、参考数字、它们对应的术语以及描述图像组件之间相互作用的最小权利要求集。 |
| DiaCorrect: Error Correction Back-end For Speaker Diarization Authors Jiangyu Han, Federico Landini, Johan Rohdin, Mireia Diez, Lukas Burget, Yuhang Cao, Heng Lu, Jan Cernocky 在这项工作中,我们提出了一个名为 DiaCorrect 的纠错框架,以简单而有效的方式细化二值化系统的输出。该方法的灵感来自于自动语音识别中的纠错技术。我们的模型由两个并行卷积编码器和一个基于变换的解码器组成。通过利用输入录音和初始系统输出之间的交互,DiaCorrect 可以自动纠正初始说话者活动,以最大限度地减少二值化错误。对 2 个说话者电话数据的实验表明,所提出的 DiaCorrect 可以有效改善初始模型的结果。 |
| Cross-lingual Knowledge Distillation via Flow-based Voice Conversion for Robust Polyglot Text-To-Speech Authors Dariusz Piotrowski, Renard Korzeniowski, Alessio Falai, Sebastian Cygert, Kamil Pokora, Georgi Tinchev, Ziyao Zhang, Kayoko Yanagisawa 在这项工作中,我们介绍了一个跨语言语音合成的框架,其中涉及上游语音转换 VC 模型和下游文本到语音 TTS 模型。拟议的框架由 4 个阶段组成。在前两个阶段,我们使用 VC 模型将目标语言环境中的话语转换为目标说话者的声音。在第三阶段,转换后的数据与目标语言录音的语言特征和持续时间相结合,然后用于训练单说话者声学模型。最后,最后一个阶段需要训练独立于语言环境的声码器。我们的评估表明,所提出的范例优于基于训练大型多语言 TTS 模型的最先进方法。此外,我们的实验证明了我们的方法对于不同模型架构、语言、说话者和数据量的稳健性。 |
| Audio Difference Learning for Audio Captioning Authors Tatsuya Komatsu, Yusuke Fujita, Kazuya Takeda, Tomoki Toda 这项研究引入了一种新颖的训练范式,即音频差异学习,用于改进音频字幕。所提出的学习方法的基本概念是创建一个保留音频之间关系的特征表示空间,从而能够生成详细说明复杂音频信息的字幕。该方法采用参考音频和输入音频,两者都通过共享编码器转换为特征表示。然后根据这些差异特征生成说明文字来描述它们的差异。此外,还提出了一种独特的技术,涉及将输入音频与附加音频混合,并使用附加音频作为参考。这导致混合音频和恢复为原始输入音频的参考音频之间存在差异。这允许将原始输入的标题用作其差异的标题,从而无需对差异进行附加注释。 |
| PromptTTS++: Controlling Speaker Identity in Prompt-Based Text-to-Speech Using Natural Language Descriptions Authors Reo Shimizu, Ryuichi Yamamoto, Masaya Kawamura, Yuma Shirahata, Hironori Doi, Tatsuya Komatsu, Kentaro Tachibana 我们提出 PromptTTS,这是一种基于提示的文本到语音 TTS 合成系统,允许使用自然语言描述来控制说话者身份。为了在基于提示的 TTS 框架内控制说话者身份,我们引入了说话者提示的概念,它描述了语音特征,例如性别中立、年轻、年老和低沉,设计为大致独立于说话风格。由于没有包含演讲者提示的大规模数据集,我们首先基于 LibriTTS R 语料库构建一个包含手动注释演讲者提示的数据集。然后,我们采用基于扩散的声学模型和混合密度网络来对训练数据中的不同说话者因素进行建模。与之前的研究不同的是,风格提示仅描述说话者个性的有限方面,例如音高、语速和能量,我们的方法利用额外的说话者提示来有效地学习从自然语言描述到不同说话者的声学特征的映射。我们的主观评价结果表明,与没有说话人提示的方法相比,所提出的方法可以更好地控制说话人特征。 |
| Characterizing the temporal dynamics of universal speech representations for generalizable deepfake detection Authors Yi Zhu, Saurabh Powar, Tiago H. Falk 现有的深度伪造语音检测系统缺乏对未见攻击的通用性,即由生成算法生成的样本在训练期间未见。最近的研究探索了使用通用语音表示来解决这个问题,并取得了鼓舞人心的结果。然而,这些工作集中于创新下游分类器,同时保持表示本身不变。在这项研究中,我们认为表征这些表征的长期时间动态对于普遍性至关重要,并提出了一种评估表征动态的新方法。事实上,我们表明不同的生成模型使用我们提出的方法生成相似的表示动态模式。 |
| AV2Wav: Diffusion-Based Re-synthesis from Continuous Self-supervised Features for Audio-Visual Speech Enhancement Authors Ju Chieh Chou, Chung Ming Chien, Karen Livescu 语音增强系统通常使用干净语音和噪声语音对进行训练。在视听语音增强 AVSE 中,没有那么多可用的真实干净数据,大多数视听数据集是在具有背景噪声和混响的现实环境中收集的,这阻碍了 AVSE 的发展。在这项工作中,我们介绍了 AV2Wav,一种基于重新合成的视听语音增强方法,尽管面临现实世界训练数据的挑战,它仍然可以生成干净的语音。我们使用神经质量估计器从视听语料库中获得近乎干净的语音子集,然后在该子集上训练扩散模型,以生成以来自 AV HuBERT 的连续语音表示为条件的波形,并进行噪声鲁棒训练。我们使用连续而不是离散的表示来保留韵律和说话人信息。仅通过此声编码任务,该模型就可以比基于掩蔽的基线更好地执行语音增强。我们进一步微调干净噪声话语对上的扩散模型以提高性能。我们的方法在自动指标和人类听力测试方面都优于基于掩蔽的基线,并且在质量上接近听力测试中的目标语音。 |
| DiariST: Streaming Speech Translation with Speaker Diarization Authors Mu Yang, Naoyuki Kanda, Xiaofei Wang, Junkun Chen, Peidong Wang, Jian Xue, Jinyu Li, Takuya Yoshioka 用于对话录音的端到端语音翻译 ST 涉及几个尚未探索的挑战,例如没有准确单词时间戳的说话者二值化 SD 以及以流方式处理重叠语音。在这项工作中,我们提出了 DiariST,第一个流 ST 和 SD 解决方案。它建立在基于神经换能器的流式 ST 系统之上,并集成了令牌级序列化输出训练和 t 向量,这些最初是为多说话者语音识别而开发的。由于该领域缺乏评估基准,我们通过将 AliMeeting 语料库的参考中文转录翻译成英文,开发了一个新的评估数据集 DiariST AliMeeting。我们还提出了新的指标,称为与说话人无关的 BLEU 和说话人归因的 BLEU,来衡量 ST 质量,同时考虑 SD 准确性。与基于 Whisper 的离线系统相比,我们的系统实现了强大的 ST 和 SD 能力,同时对重叠语音进行流式推理。 |
| Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults Authors Ahmed Adel Attia, Jing Liu, Wei Ai, Dorottya Demszky, Carol Espy Wilson 自动语音识别 ASR 系统的最新进展(以 Whisper 为代表)已经证明,在提供足够数据的情况下,这些系统有接近人类水平表现的潜力。然而,由于合适的儿童特定数据库的可用性有限以及儿童言语的独特特征,这一进展并不容易扩展到儿童 ASR。最近的一项研究调查了利用 My Science Tutor MyST 儿童语音语料库来增强 Whisper 在识别儿童语音方面的表现。本文以这些发现为基础,通过更高效的数据预处理来增强 MyST 数据集的实用性。我们还强调了提高儿童 ASR 表现的重要挑战。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页
pic from pexels.com