文章目录
- 1. 前言
- 2. 实现思路
- 3. 运行结果
1. 前言
首先,说明一下,本篇博客内容可能涉及到版权问题,为此,小编只说明一下实现思路,至于全部参考代码,小编不粘贴出来。不过,小编会说明详细一些,真心能够帮助到一些读者。仅供参考,请莫用于商业活动!

2. 实现思路
在必应上搜索图片,通过向下滚动滚动条,从而刷新出新的图片出来。
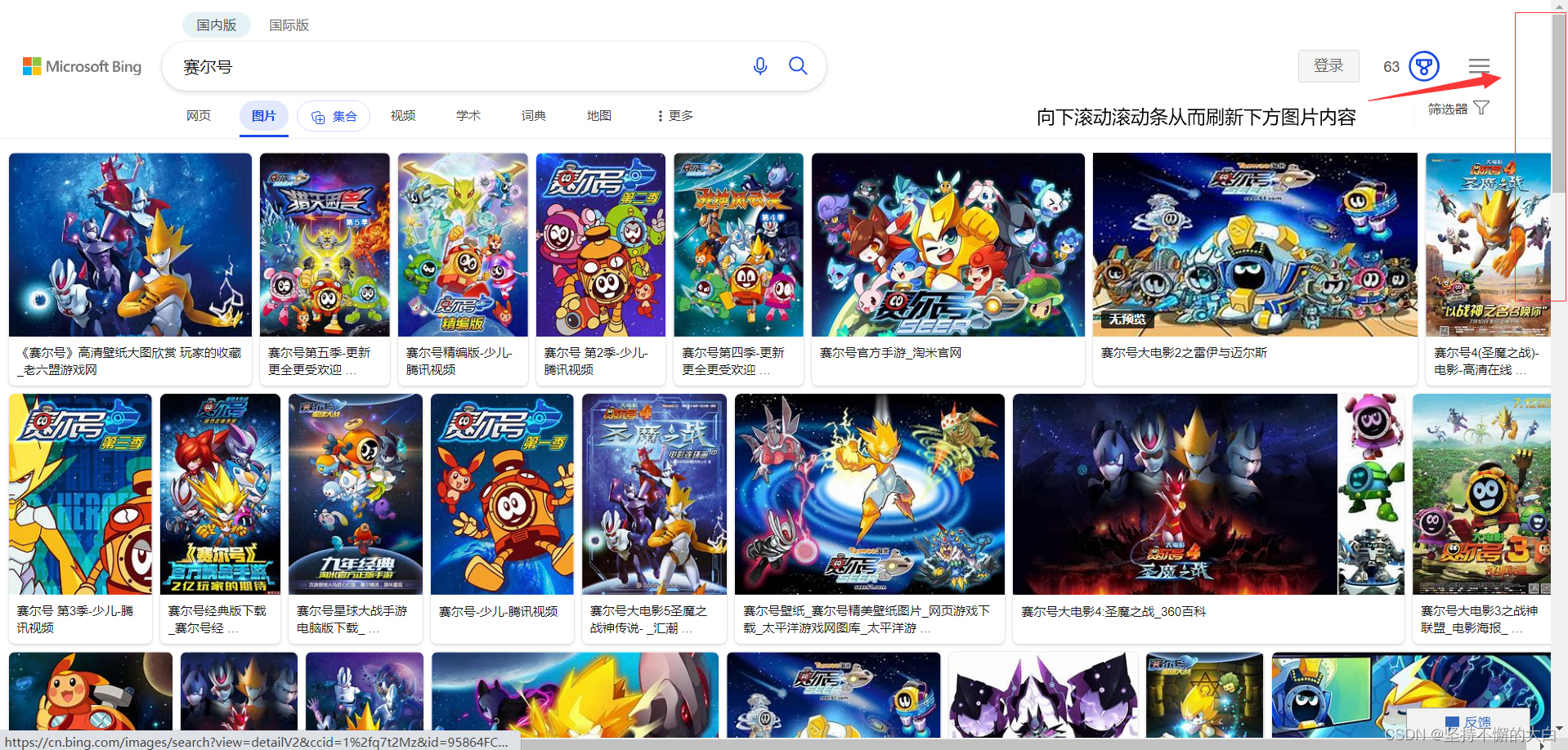
和百度图片效果一样,当时实现技术可能有一点不同吧!至于哪一点不同,只有读者自己实践才能知道。必应上搜索内容,至于改动这个参数即可,如下:
https://cn.bing.com/images/search?q=%E8%B5%9B%E5%B0%94%E5%8F%B7&first=1
也就是 q= 之后 &first 之前这部分字符串(进行了相关编码的结果)。直接在输入框中输入搜索内容,搜索栏里的链接会很长一段,但是只要上述那一段字符串链接就可以返回所搜索的结果了。
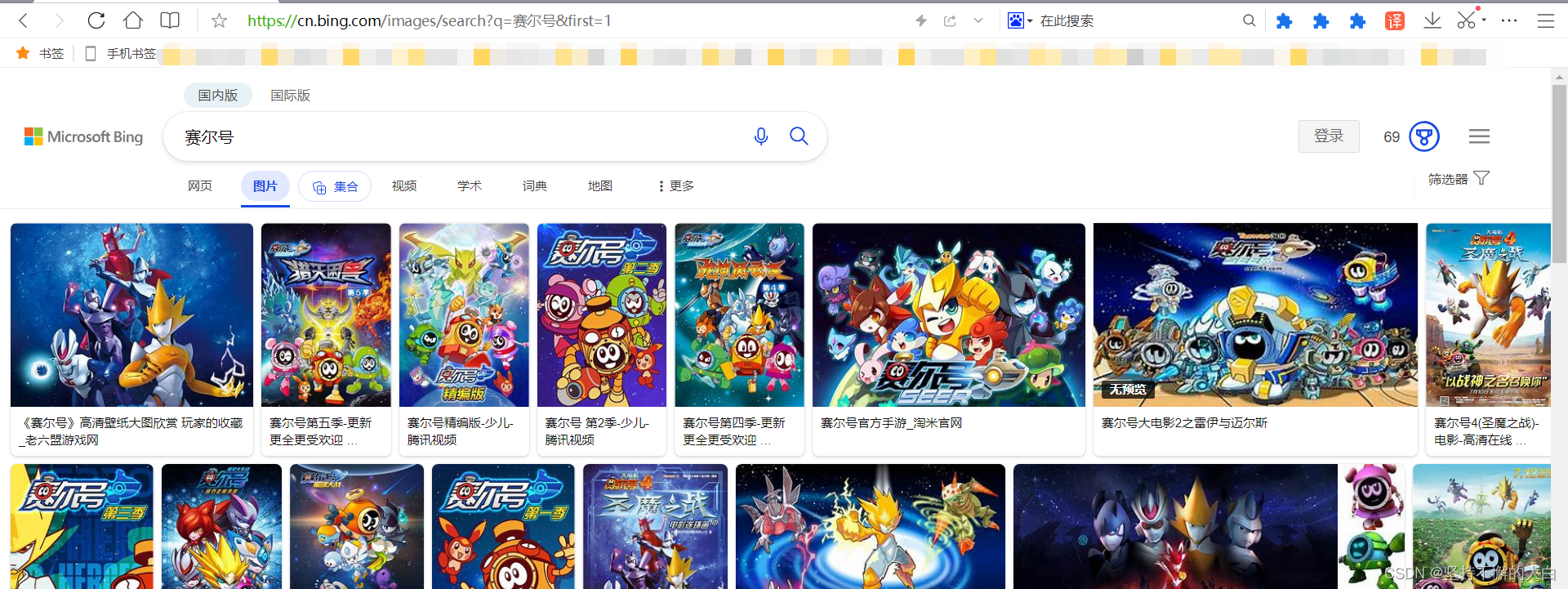
直接用requests模块访问这个链接,用lxml解析即可得到相关图片的下载链接,但是如果想下载多页数据,怎样得到下一页的数据呢?通过分析,可以发现在初始链接的html源码中,能够找到第二页链接接口,而访问第二页的链接接口,又可以找到第三页的链接接口,。。。
至于一共有多少页的数据,网站中好像没有提供总页数的数据。不过,像这种动态加载数据的,如果让我来实现相关的前端代码,根本没有必要把总页数据提供出来。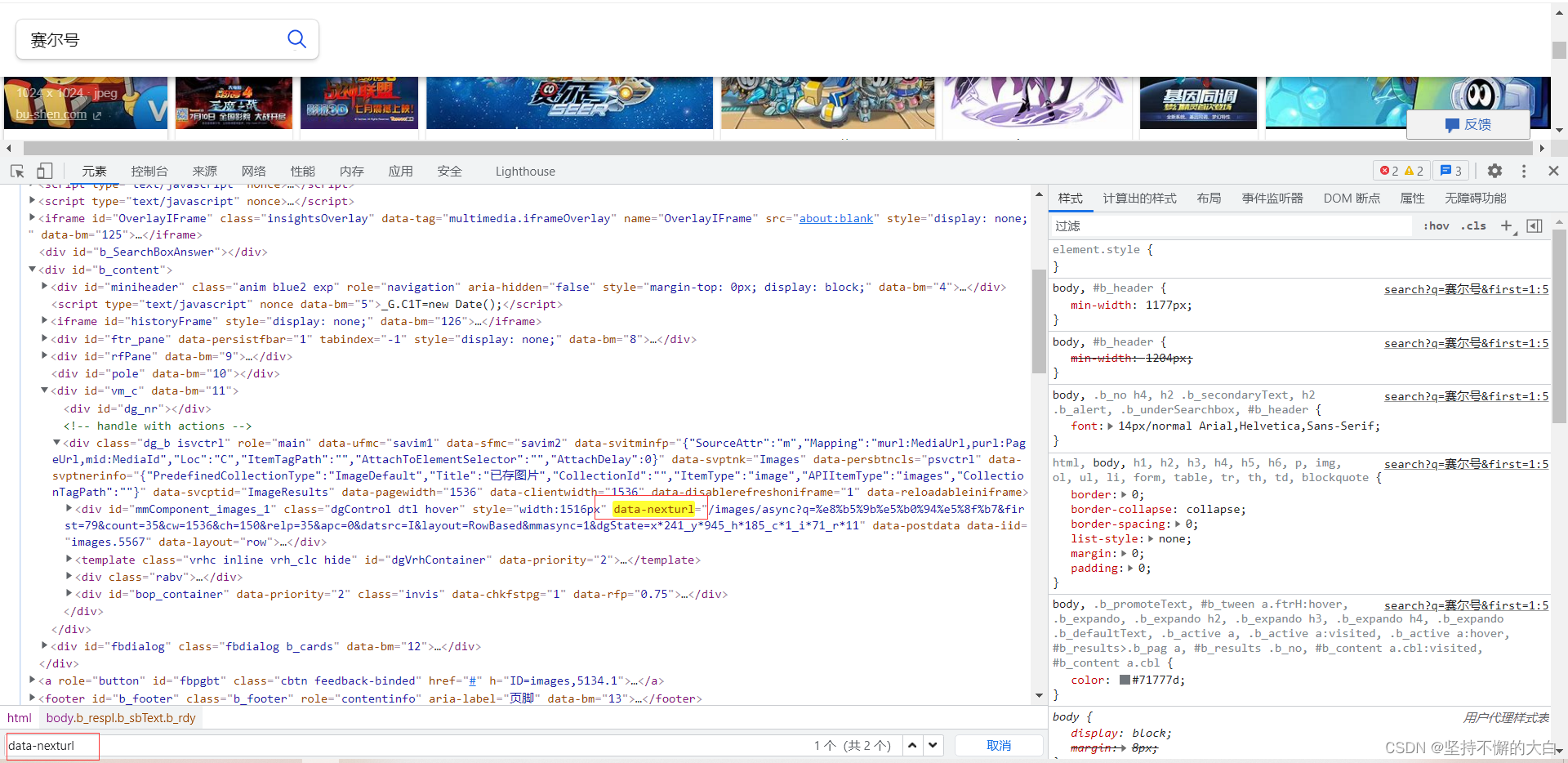
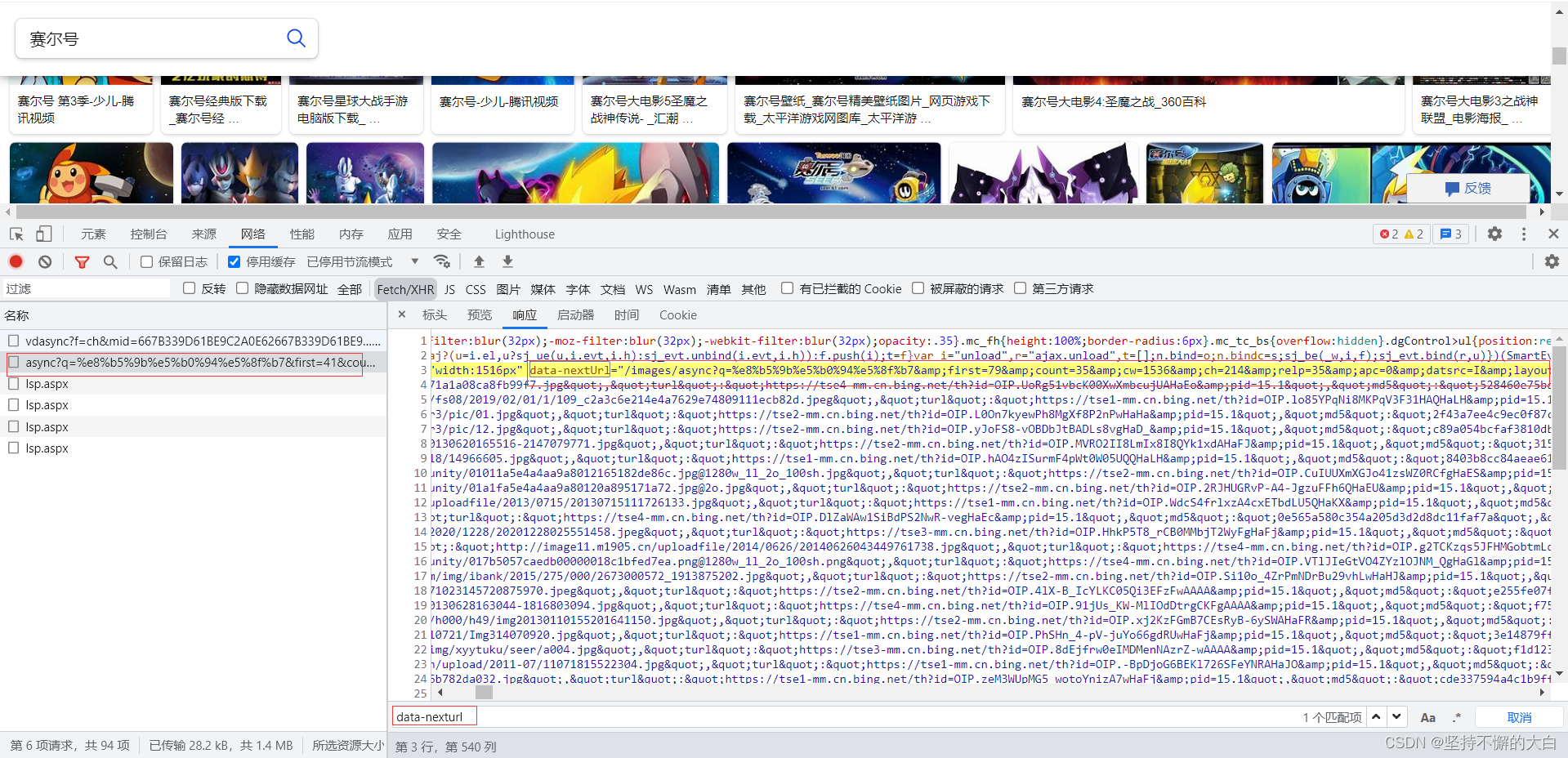
不过,在实际实现过程中,却发现了一个问题,那就是下一页的接口链接找不到的情况,开始以为是应为网站用了反爬才导致的。最后发现用requests模块访问链接返回数据时,结果中有两种情况。一类情况就是能找到下一页接口链接的那种;还有一类情况就是出现了分页的情况,就是可以找到当前页的后几页的链接,不过没有尾页的链接,这种把用requests访问链接得到结果保存到一个html文件中,然后访问该html文件就可以发现,如下(搜索关键词改了的,这是有的情况下):
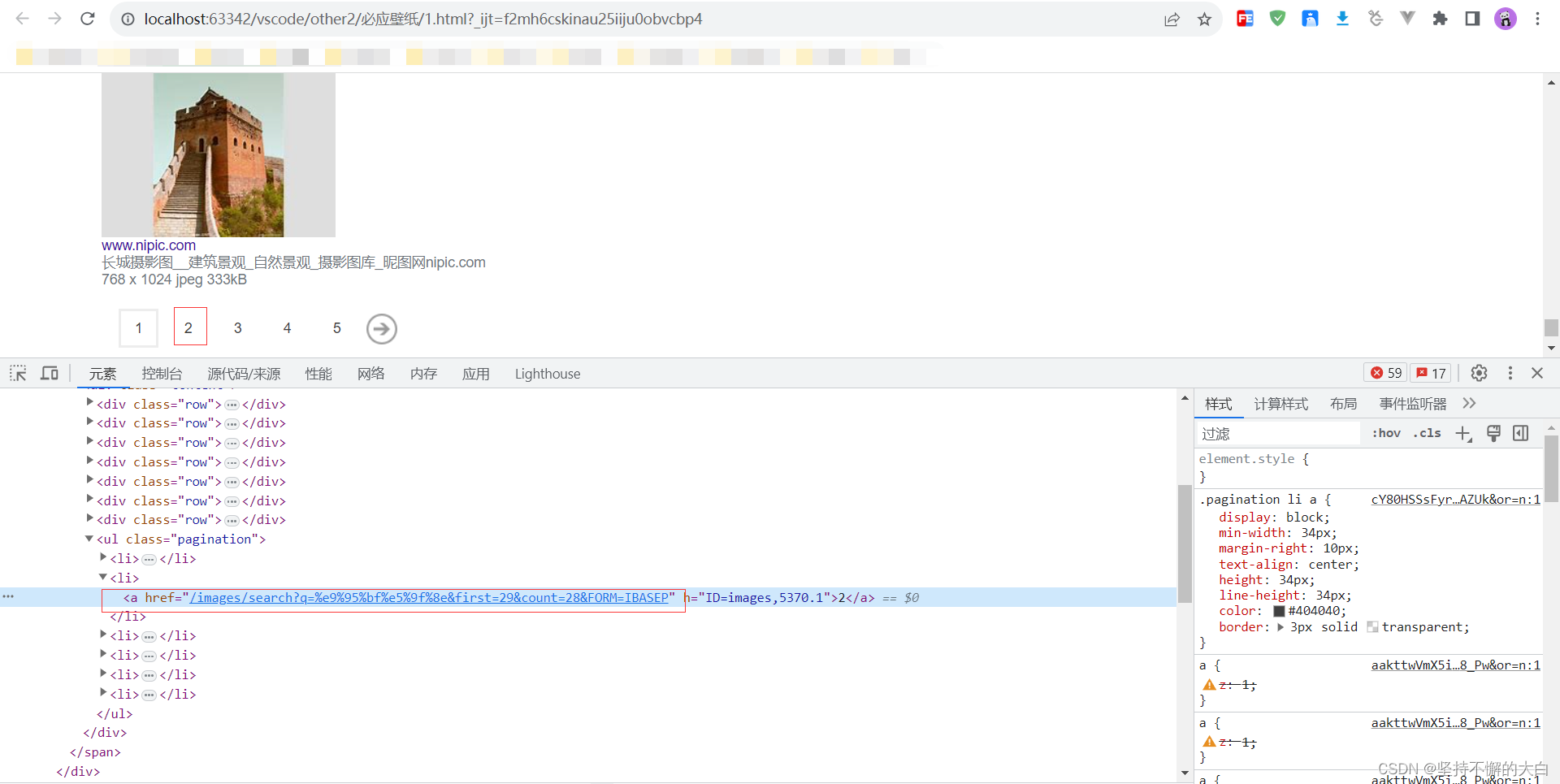
因此,小编觉得,如果要想代码在运行中不报错(能得到想要的结果数据),需要做两种情况处理,如果在当前页面html源码中能找到下一页链接数据,下一次访问这个链接即可;找不到下一页链接数据,那么就找那个多页分页的那些数据,看是否有下一页的数据。
同时需要注意的是解析html源码获取图片下载链接时,需要分两种情况,看看下述不同搜索词就可以找到原因了,如下:
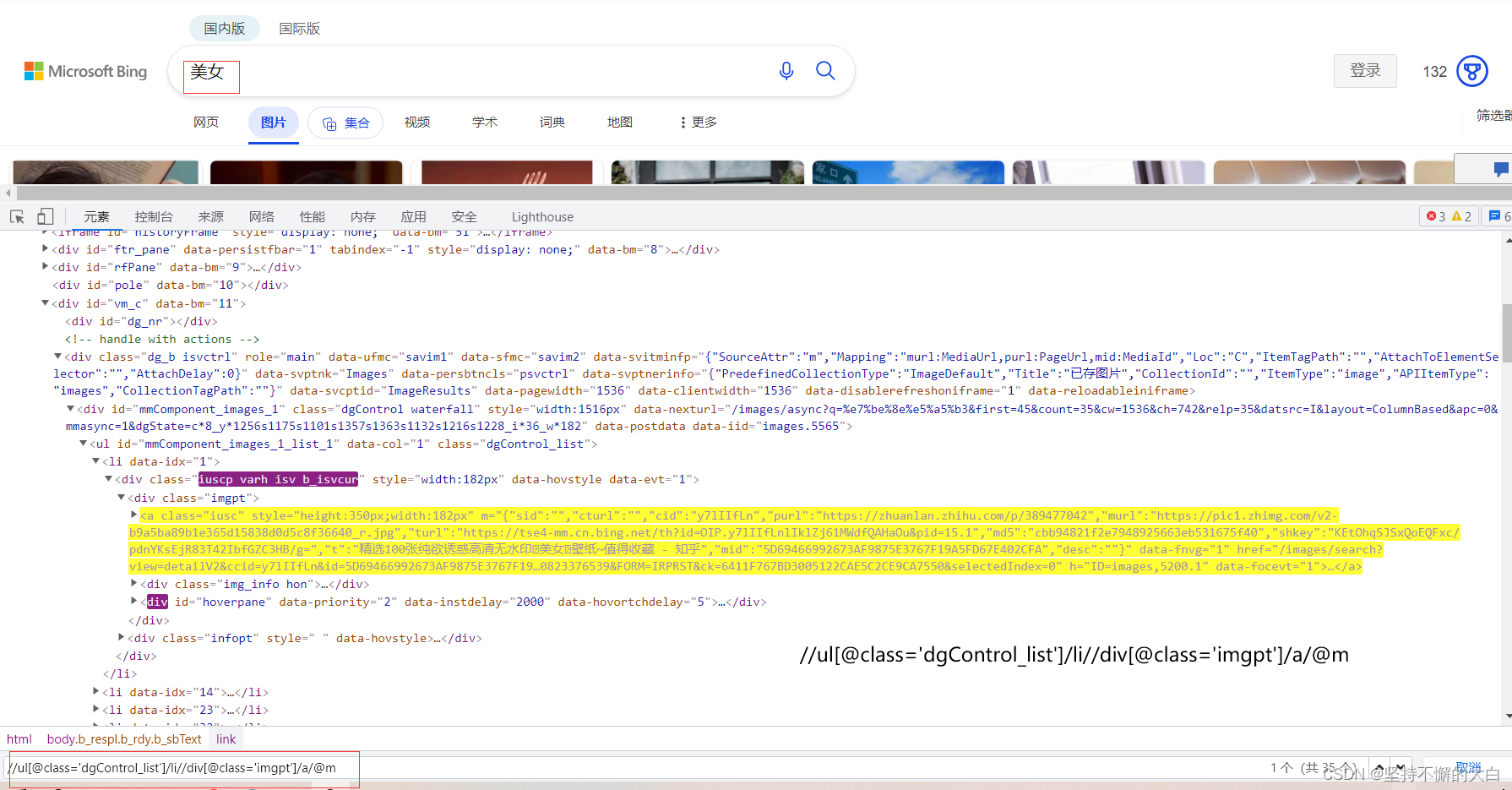
3. 运行结果
Python爬虫:获取必应图片的下载链接
【注】:请求头上加上cookie,否则有一定的问题,另外,需要注意的是获取图片的下载链接方式。(小编使用两种方式,否则不一样的搜索词获取不到对应的下载链接。)