🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。
🏆数年电商行业从业经验,AWS/阿里云资深使用用户,历任核心研发工程师,项目技术负责人。
🎉欢迎 👍点赞✍评论⭐收藏
文章目录
- 🚀一、前言-关于Flask框架
- 🚀二、功能描述
- 🚀三、功能开发实现
- 🔎3.1 搭建后端服务
- 🍁3.1.1 安装Flask
- 🍁3.1.2 创建后端服务代码
- 🍁3.1.3 测试5000端口访问
- 🍁3.1.4 规范化启动服务(restart.sh)
- 🍁3.1.5 Nginx代理5000端口
- 🍁3.1.6 修改本机host访问Api
- 🔎3.2 编写前端页面
- 🍁3.2.1 创建HTML文件
- 🍁3.2.2 部署前端页面
- 🚀四、测试功能
- 4.1 测试标题抓取
- 4.2 测试图片抓取
- 🚀五、结语
随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。
前面通过 华为云云耀云服务器L实例评测|从服务器购买到一站式搭建Presta Shop跨境商城完整教学 这一篇,已经完整实现了服务器的购买到初步的使用。这边文章由我带大家再进一步的进行实战内容扩充,本篇主要讲述用Python的Flask框架加Nginx实现一个通用的爬虫项目实践。在评测服务器使用的同时,供大家学习使用参考。
如果想了解华为云云耀云服务器L实例评测,可以点击这里直接进入。
🚀一、前言-关于Flask框架
Flask是一个基于Python的微框架,用于构建Web应用程序。它是一个轻量的并且被广泛应用的框架,具有简单易懂的设计和灵活的扩展能力。

以下是关于Flask的一些重要特点和概念:
路由:Flask使用装饰器来定义URL路由,将不同的URL路径映射到相应的函数上。例如,可以使用@app.route('/hello')装饰器将函数hello()与路径/hello绑定。
视图函数(View function):视图函数是Flask应用程序处理URL请求的函数。每当用户访问指定路径时,与该路径绑定的视图函数将被调用,并返回相应的内容。
模板引擎:Flask使用Jinja2模板引擎来实现页面的动态生成。模板引擎允许开发人员将静态模板与动态数据结合,生成最终的HTML页面发送给客户端。
请求-响应循环:当用户发送HTTP请求时,Flask使用请求-响应循环来处理请求并返回响应。请求-响应循环由Flask框架自动处理,开发人员只需要关注如何处理请求和生成响应。
扩展性:Flask拥有丰富的第三方扩展,可以轻松地集成其他功能,如数据库访问、用户认证、表单验证等。
开发简便:Flask提供了简洁的API和清晰的文档,使开发人员能够快速构建Web应用程序。它的学习曲线相对较低,适合初学者入门。
🚀二、功能描述
今天本文主要在华为云云耀云服务器L实例上面,通过Flask框架做服务,前端开发主要通过Html+JQuery来实现。写一个爬虫功能,前端有一个Input用来输入网页地址,然后还有一个下拉框Select,里面可以选择标题,图片,视频等。还有一个提交按钮,提交给了Python后端,比如提交了https://www.baidu.com这个网页地址,然后Select选择了图片,就抓去这个地址的所有图片url返回给前端。

话不多说,下面直接进入正题。
🚀三、功能开发实现
🔎3.1 搭建后端服务
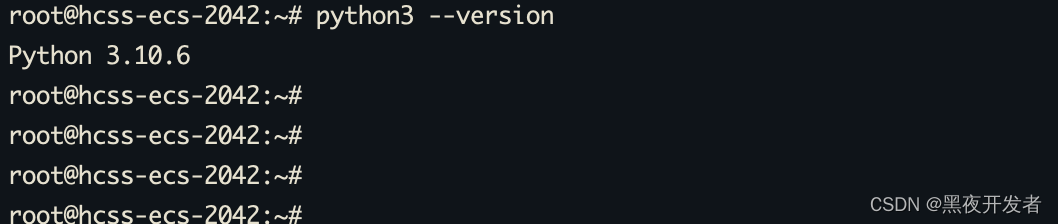
使用Flask搭建一个简单的后端服务来处理前端的请求。可以看到L实例上面已经预装Python3的环境。
🍁3.1.1 安装Flask
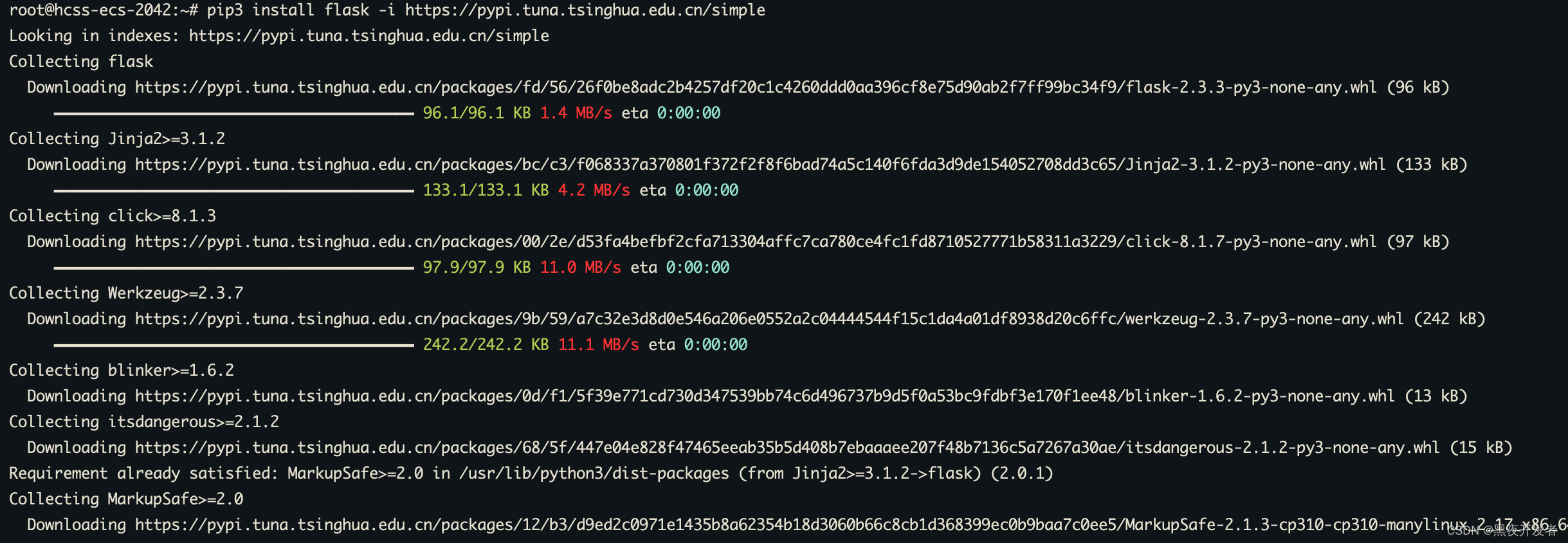
打开命令行终端,执行以下命令安装Flask,这里还是加一个源,不然默认的太慢了:
pip3 install flask -i https://pypi.tuna.tsinghua.edu.cn/simple
下面是实际执行的效果,很快就安装好了。
🍁3.1.2 创建后端服务代码
创建一个名为server.py的Python文件,添加以下内容:
from flask import Flask, request, jsonify
import requests
from bs4 import BeautifulSoupapp = Flask(__name__)@app.route('/', methods=['POST'])
def crawl():url = request.form.get('url')mode = request.form.get('mode')response = requests.get(url)soup = BeautifulSoup(response.text, 'html.parser')result = []if mode == 'title':title = soup.title.stringresult.append(title)elif mode == 'image':images = soup.find_all('img')for img in images:result.append(img['src'])elif mode == 'video':videos = soup.find_all('video')for video in videos:result.append(video['src'])return jsonify(result)if __name__ == '__main__':app.run()
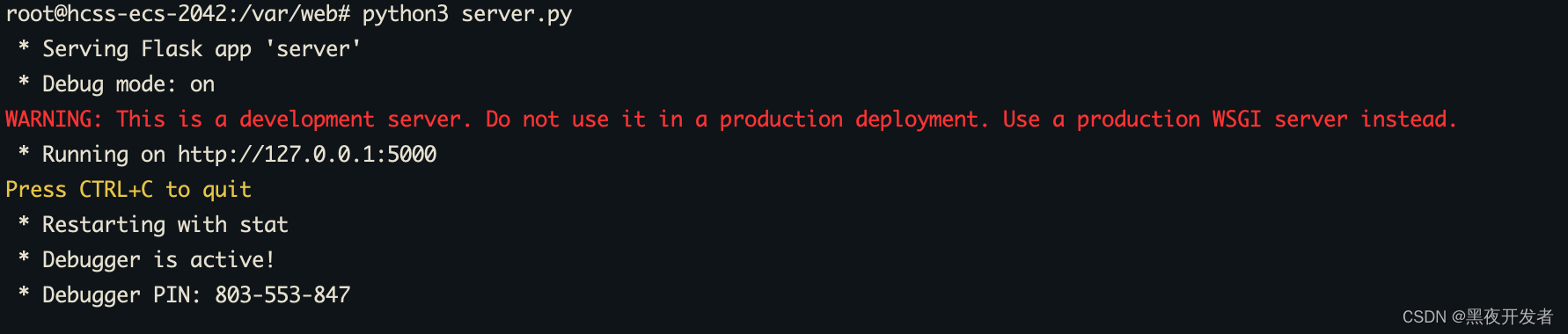
然后我把我这个文件放到了/var/web目录下面,然后我来尝试运行一下,看看效果。

报错了,我的扩展少装了,继续执行一下下面的操作
pip3 install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple
然后继续python3 server.py。发现成功了,一个简单的web服务就这么启动了,太舒服了。
🍁3.1.3 测试5000端口访问
现在服务启动起来了,我们先不要停止,现在没有开发5000安全组,来试一下浏览器能不能访问。直接输入http://124.70.177.136:5000/,这是我真实的服务器地址。浏览器转了半天事实证明没有反应,访问不可触达。
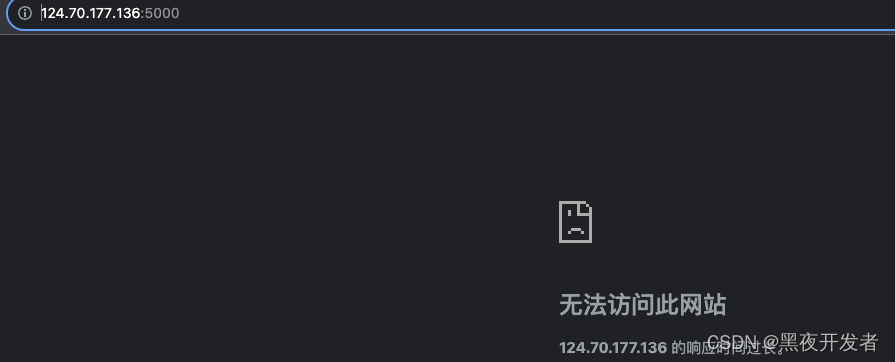
现在我们去安全组开一把5000端口试试。
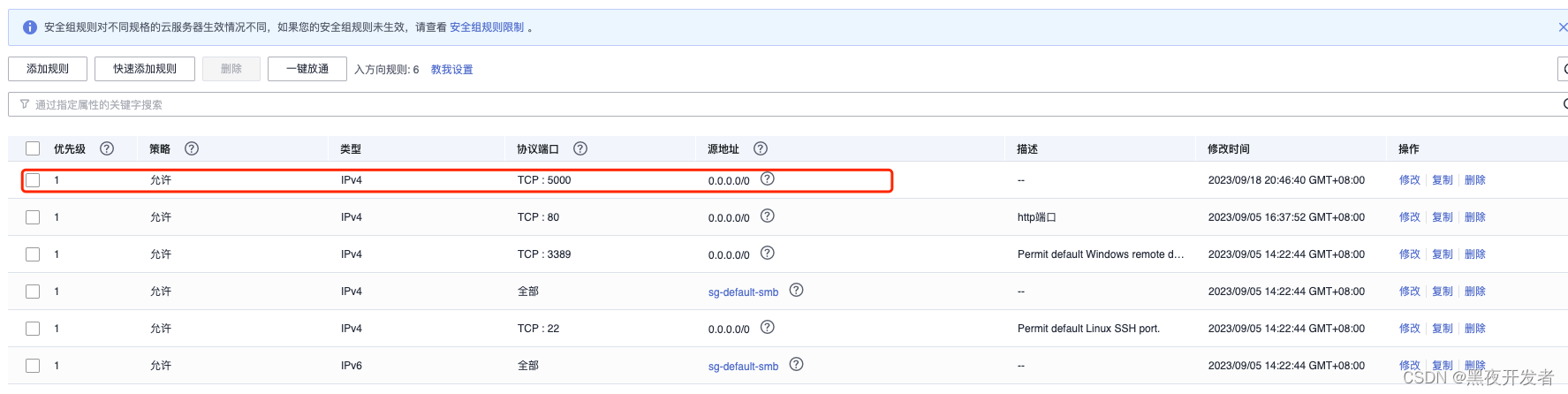
开了安全组后发现还是不行,后面经过排查,把上面代码里面的最后一句改为app.run(host='0.0.0.0')即可。下面是浏览器通畅后的效果。
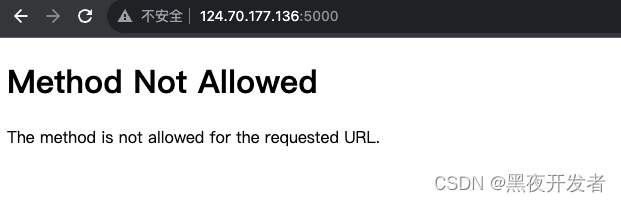
然后访问后,服务器控制台也给出了请求的反馈。
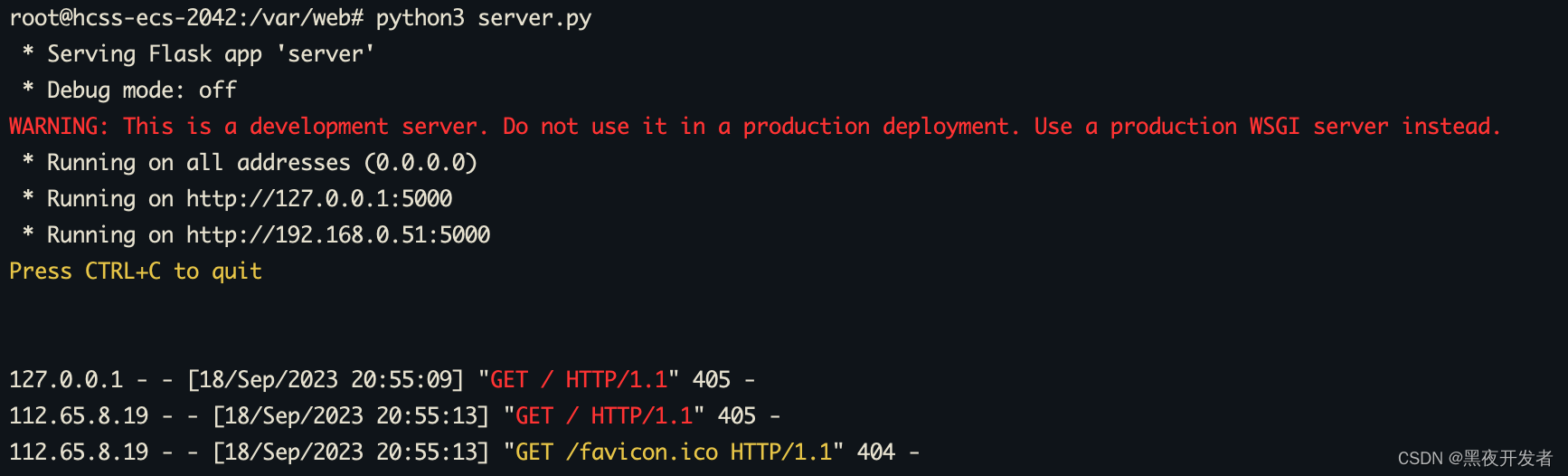
🍁3.1.4 规范化启动服务(restart.sh)
上面这种直接在控制台输出肯定不行,这样太粗糙了,一点都不优雅,终端断了还可能导致服务中断,直接上一个sh脚本控制日志输出并且让服务后台运行才是最佳实践,玩的就是一个项目实战。这方面知识欠缺的可以去看我的Linux命令大全专栏。
#!/bin/bash
echo "结束进程"
kill ` lsof -i:5000 | awk '{NR==2 ;print $2}' ` #杀死运行中的server服务进程
echo "启动进程"
nohup python3 server.py >> server.log 2>&1 & #后台启动服务将日志写入server.log文件
ps -aux | grep 5000
直接bash restart.sh就可以重启服务,服务后台运行,日志直接查看server.log,是不是舒服多了。见下图。
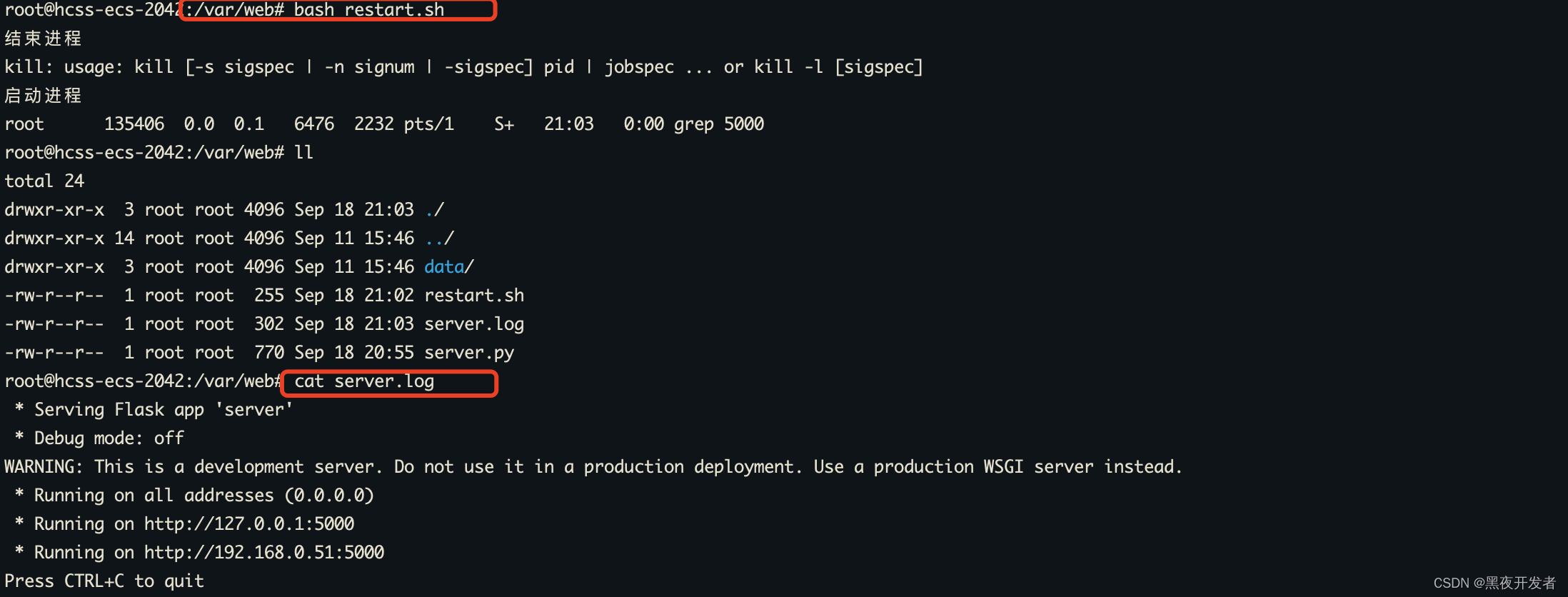
🍁3.1.5 Nginx代理5000端口
如果你以为直接访问5000端口可行,那也是粗糙*2,不够优雅,玩的就是一个细节,下面继续用Nginx来代理上5000端口。这里我们通过sites-enabled目录来新建虚拟域名代理,这样显得更加隔离一些。
cd /etc/nginx/
mkdir sites-enabled
然后在sites-enabled下面建一个reptile.conf放入下面的内容:
server {listen 80;server_name reptile.heiye.net;set $back_port "5000";location ~* ^/api {proxy_pass "http://127.0.0.1:$back_port";}
}
然后在主要文件里面要引入sites-enabled下面的所有文件,使得这些配置生效。vim /etc/nginx/conf.d/default.conf 头部放入如下内容。注意不同的环境配置效果可能不一样,我这里是这样去配置。
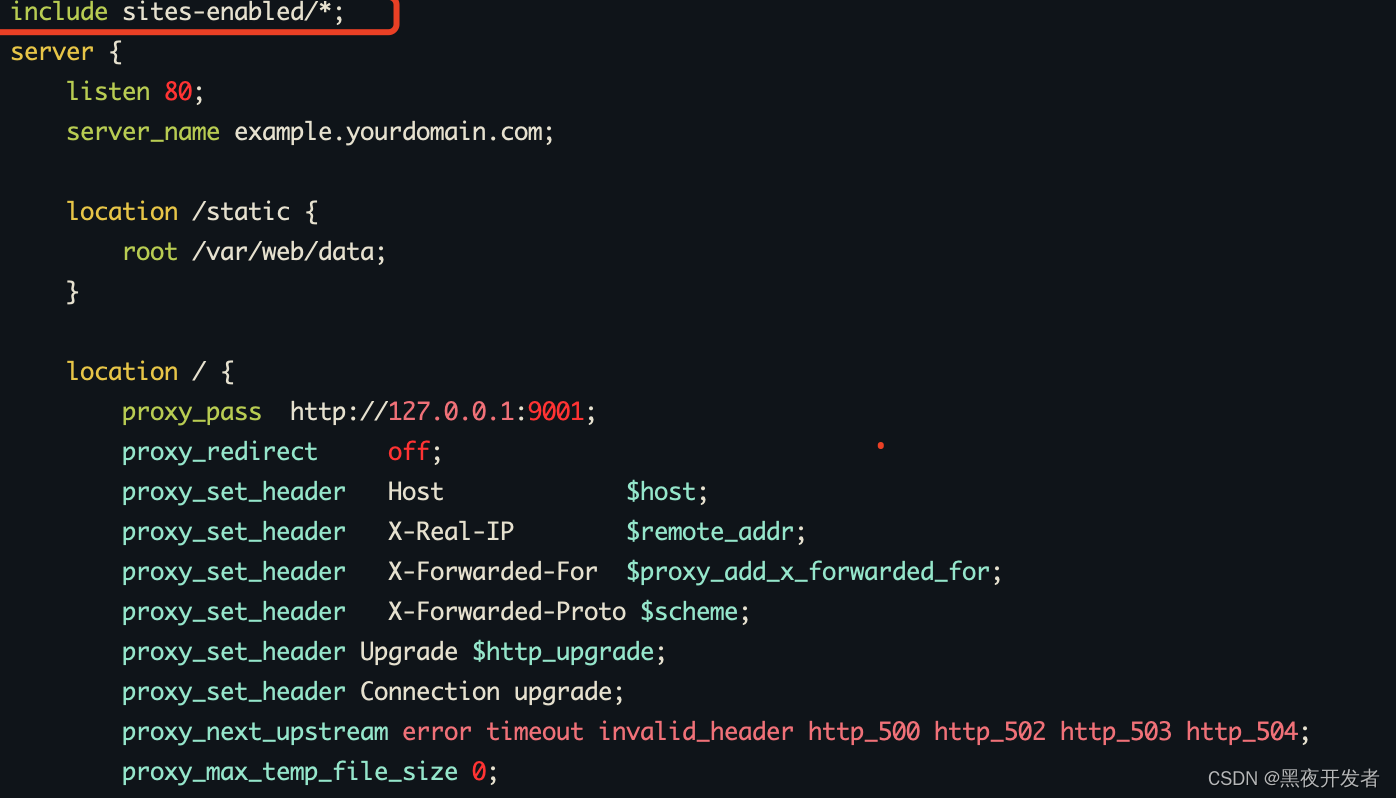
然后nginx -t通过后nginx -s reload。养成先测试的好习惯。

🍁3.1.6 修改本机host访问Api
上面Nginx配置里面提到了reptile.heiye.net这个域名,实际上这个域名不是真实存在的,要访问到需要配置一下,我是Mac,在/etc/hosts中修改,Windows在C:\Windows\System32\drivers\etc这个目录下面的host文件,放入下面这一行。
124.70.177.136 reptile.heiye.net
现在我们一起用浏览器访问一下reptile.heiye.net就能够直达上面开启的server服务了,完美,后端服务基本上就部署完成了。
🔎3.2 编写前端页面
使用HTML和jQuery编写一个简单的前端页面。
🍁3.2.1 创建HTML文件
创建一个名为index.html的HTML文件,添加以下内容:
<!DOCTYPE html>
<html>
<head><title>爬虫功能示例</title><script src="https://code.jquery.com/jquery-3.6.0.min.js"></script>
</head>
<body><h1>爬虫功能示例</h1><form id="crawl-form"><label for="url">网页地址:</label><input type="text" id="url" name="url" required><br><br><label for="mode">抓取内容:</label><select id="mode" name="mode" required><option value="title">标题</option><option value="image">图片</option><option value="video">视频</option></select><br><br><input type="submit" value="提交"></form><div id="result"></div><script>$(document).ready(function() {$('#crawl-form').on('submit', function(event) {event.preventDefault();var url = $('#url').val();var mode = $('#mode').val();$.ajax({url: '/',method: 'POST',data: {url: url,mode: mode},success: function(response) {var resultHtml = '';if (response.length > 0) {for (var i = 0; i < response.length; i++) {resultHtml += '<p>' + response[i] + '</p>';}} else {resultHtml = '<p>没有找到相关内容。</p>';}$('#result').html(resultHtml);},error: function() {alert('请求失败,请检查输入的网页地址。');}});});});</script>
</body>
</html>
🍁3.2.2 部署前端页面
前端页面实际上也要放到服务器下面去,具体的文件放置于/var/web/front/reptile/index.html。同样的Nginx也配置一下,对于请求到底是到页面还是到后端服务需要进行分流。在reptile.conf中添加如下代码。在location /这个位置的前面。
location ~* ^/reptile {root /var/web/front/;
}
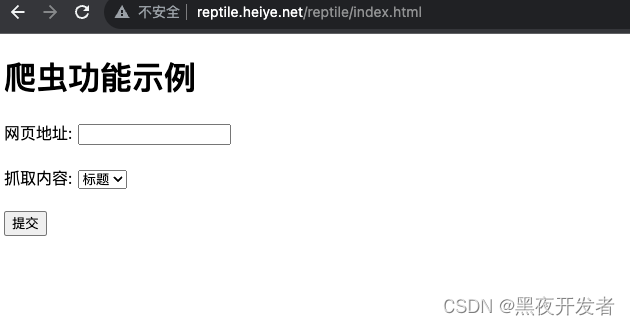
然后nginx -s reload,然后尝试访问一下页面http://reptile.heiye.net/reptile/index.html,成功出现。
🚀四、测试功能
在浏览器中访问http://reptile.heiye.net/reptile/index.html,即可看到前端页面。
4.1 测试标题抓取
这里通过https://www.runoob.com/linux/linux-command-manual.html这个网址作为我们的测试用例。抓取内容为标题,点击提交,就成功获取了。

4.2 测试图片抓取
抓取内容选择图片,可以看到页面上两张图片地址被分析出来了。

🚀五、结语
本篇文章通过华为云云耀云服务器L实例进行支持开发,实现了一个五脏俱全的前后端一起的完整爬虫小项目。所有的代码都在文章中给出了展示,您也可以根据具体的自己的使用情况进行扩展,实际项目中会遇到非常丰富以及复杂的情况,不过通过不断努力总是可以把问题解决了的。
由于是真实的流程演示,项目也实际部署到了线上,大家可以看文章绑定一下host,然后通过http://reptile.heiye.net/reptile/index.html进行访问。感谢华为云的支持。整体在L实例上面的测试流程还是比较顺畅,没有遇到多大问题,就是pip默认安装源有点慢,另外之前我安装的Presta Shop跨境商城经过一段时间的运行,还是比较稳定,没有出现过服务中断的情况,因为我这个上面部署的服务也不少了。
希望华为云越来越好,希望中国的云事业更上一层楼,我作为一个普通开发者,也将不断参与与见证这一伟大的技术探索与变革。

今天的内容就到这里,我们下期再会。