一.系统IO
系统 I/O(Input/Output)是计算机操作系统提供给应用程序的一种输入和输出方式。它通过系统调用(系统内核提供的函数)来实现数据的读取和写入。系统 I/O 可以用于与文件、设备(例如磁盘驱动器、网络接口、串口等)以及其他进程之间进行数据交换。
在系统 I/O 中,输入和输出操作是通过系统调用来完成的。系统调用是一种特殊的函数调用,用于向操作系统请求特定的操作。对于输入操作,应用程序发起一个系统调用来从文件或设备中读取数据;而对于输出操作,应用程序发起一个系统调用来将数据写入文件或设备。
系统 I/O 的一般工作流程如下:
- 打开文件或设备:应用程序首先使用系统调用打开需要读取或写入的文件或设备,并获取一个文件描述符,该描述符用于后续的读写操作。
- 读取数据:应用程序使用系统调用读取文件或设备中的数据,并将数据读取到应用程序的内存空间中。
- 写入数据:应用程序使用系统调用将数据写入文件或设备中,数据可以来自应用程序的内存空间。
- 关闭文件或设备:应用程序在完成读写操作后,使用系统调用关闭文件或设备。
系统 I/O 相对于其他的 I/O 方式(如标准 I/O、网络 I/O)来说,是较为底层的接口,通常用于需要直接与设备进行交互的场景,如驱动程序开发、底层网络编程等。它提供了对文件和设备的低级别访问,能够直接控制数据的读取和写入,但使用起来相对较复杂。
需要注意的是,系统 I/O 的使用需要谨慎,特别是在多线程或多进程环境下,需要正确处理并发访问和数据一致性的问题,以避免出现竞态条件和数据损坏等情况。因此,在开发应用程序时,可以借助更高级别的 I/O 接口(如标准 I/O、网络库)来简化和提高效率。
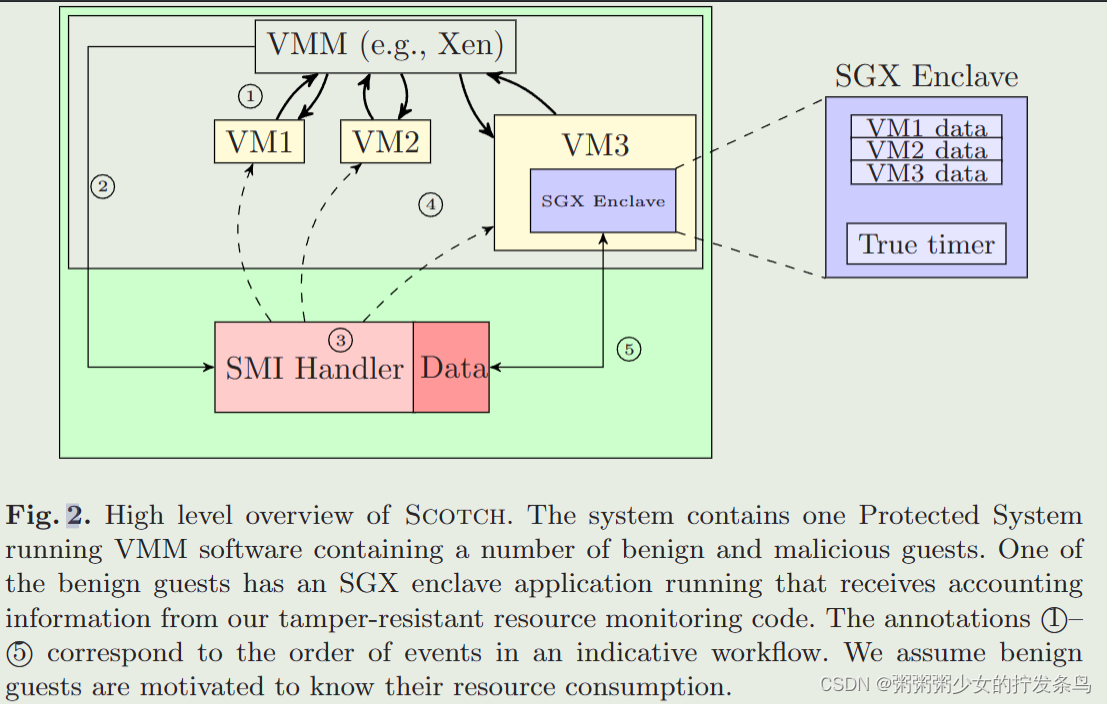
系统IO的分页缓存区
系统 I/O 中的分页缓冲区是一种用于管理磁盘存储的缓冲区。它是操作系统中的一部分,用于在内存和磁盘之间进行数据传输。
在操作系统中,有一个专门的内存区域被称为分页缓冲区(Page Buffer Cache),也有时被称为磁盘缓存(Disk Cache)或页缓存(Page Cache)。它用于存放最近被读取或写入的文件的数据页。分页缓冲区的目的是提高文件访问的性能,减少磁盘 I/O 操作的频率。
当应用程序读取文件时,操作系统将读取的数据页存储在分页缓冲区中。如果后续的读取请求需要相同的数据页,操作系统可以直接从缓冲区中读取,而不需要再次访问磁盘。同样地,当应用程序写入文件时,数据可以先写入分页缓冲区,然后由操作系统决定在合适的时机将数据页写回磁盘。这种延迟写入的机制可以提高写入的效率。
分页缓冲区通常由操作系统内核管理,使用一种类似于虚拟内存管理的机制。它维护了一个缓冲区池,用于存放数据页。缓冲区使用一种替换算法(如LRU,最近最少使用)来决定哪些数据页需要被写回磁盘,以及哪些数据页可以被替换出缓冲区。
需要注意的是,分页缓冲区是操作系统的一部分,与应用程序的系统 I/O 直接交互。应用程序无需直接操作或控制分页缓冲区。它主要是为了提供更高效的磁盘 I/O 操作,并在后台自动管理缓冲区的使用。
二.标准IO
标准 I/O(Standard Input/Output)是一种在 C/C++ 程序中用于进行输入和输出操作的接口,它是通过 C 标准库提供的一组函数来实现的。标准 I/O 提供了一种高层次的抽象,使得程序员可以方便地进行文件、终端、管道等的输入输出操作,同时具有缓冲、格式化等功能。
标准 I/O 提供了以下几个重要的概念和函数:
-
标准输入(stdin)、标准输出(stdout)和标准错误输出(stderr):这是三个与程序相关联的特殊文件流。标准输入通常关联于键盘输入,标准输出关联于屏幕输出,标准错误输出用于打印错误信息。它们都是文件流的一种,可以使用标准 I/O 函数进行读写操作。
-
文件流:文件流是标准 I/O 的一个重要概念,它代表文件或设备的输入输出流。文件流可以通过
FILE类型的指针来表示,由标准 I/O 函数打开或创建,并通过文件描述符与实际文件或设备进行关联。 -
标准 I/O 函数族:标准 I/O 提供了一组函数用于进行输入和输出操作,常用的函数有:
fopen:用于打开文件,并返回一个FILE指针。fclose:用于关闭文件。fgetc、fgets:用于从文件中读取一个字符或一行文本。fputc、fputs:用于向文件中写入一个字符或一行文本。fprintf、fscanf:用于格式化输入输出,类似于printf和scanf。fread、fwrite:用于二进制数据的读写操作。feof、ferror:用于判断文件流的结束和错误状态。
-
标准 I/O 的缓冲机制:标准 I/O 使用内存缓冲区来提高文件读写效率。它将数据先写入缓冲区,然后才将缓冲区的数据写入文件;或者从缓冲区读取数据,而不是直接从文件读取。缓冲区可以是全缓冲(默认),这意味着当缓冲区满时才进行写入或读取;也可以是行缓冲,这意味着在读取或写入换行符或缓冲区满时才进行操作;或者是无缓冲,即立即读写数据。
标准 I/O 在 C/C++ 程序中广泛应用,它提供了一种交互方式,使得程序可以方便地处理输入和输出。同时,标准 I/O 可以通过重定向、管道等技术与其他程序进行数据交换,提供了更多实用的功能。然而,需要注意的是,在多线程环境下,标准 I/O 可能存在线程安全性问题,需要额外的同步机制来保护共享的文件流。
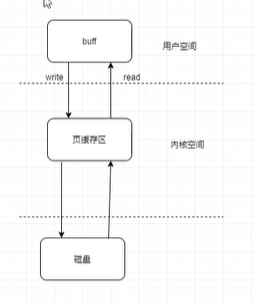
标准IO缓冲区
标准 I/O 缓冲区是标准 I/O 抽象层中用于提高输入输出性能的一种机制。它是由 C 标准库提供的,可以应用于文件、终端和其他设备的输入输出。
标准 I/O 提供了三种类型的缓冲区,它们分别是全缓冲、行缓冲和无缓冲。
-
全缓冲(Fully Buffered):在全缓冲模式下,数据会存储在内存缓冲区中,直到缓冲区填满后才进行实际的 I/O 操作。或者,当使用
fflush函数时,也会强制将缓冲区中的数据写入实际的文件或设备。全缓冲模式常用于文件的读写操作,适用于较大量的数据传输,可以减少实际的 I/O 操作次数,提高性能。 -
行缓冲(Line Buffered):在行缓冲模式下,数据会存储在内存缓冲区中,直到遇到换行符
\n或者缓冲区满时才进行实际的 I/O 操作。行缓冲模式常用于终端设备的输入和输出,默认情况下,当输出到终端时采用行缓冲模式。 -
无缓冲(Unbuffered):在无缓冲模式下,数据会直接进行实时的 I/O 操作,不会进行任何缓冲。无缓冲模式适用于某些要求实时性的场景,比如输入密码等敏感信息。
缓冲区的模式可以通过setvbuf函数来设置,该函数可以将一个已经打开的文件与指定的缓冲区类型关联起来。
标准 I/O 缓冲区的目的是提高输入输出的性能,减少频繁的调用低层的系统 I/O 接口带来的开销。缓冲区的大小可以通过调用setvbuf函数在打开文件之后进行设置。另外,可以使用fflush函数来强制将输出缓冲区中的数据写入输出设备,或者清空输入缓冲区。
需要注意的是,在标准 I/O 中对文件的读写操作并不保证是实时的,也就是说数据可能会先存储在缓冲区中,而不是直接读取或写入实际的文件。如果需要实现实时的读写,可以使用类似fseek、fread、fwrite等函数来直接操作文件的内容,而不使用标准 I/O 缓冲区的功能。
三.IO模式
非常抱歉,我之前的回答已经包含了错误信息。下面是文件 I/O 中常见的五种模式,包括阻塞 I/O、非阻塞 I/O、I/O 复用、信号驱动 I/O和异步 I/O:
-
阻塞 I/O: 同步 I/O 是一种阻塞模式的 I/O,程序会被阻塞直到 I/O 操作完成。在进行同步 I/O 操作时,程序会等待文件系统或设备准备好并返回所需数据后继续执行。
-
非阻塞 I/O:非阻塞 I/O 是一种非阻塞模式的 I/O,它允许程序发起 I/O 操作后立即返回,而不会等待操作的完成。如果数据不可用或 I/O 操作没有立即完成,非阻塞 I/O 将返回一个错误码或特定的状态,程序可以继续执行其他任务。
-
I/O 复用:I/O 复用是一种同时监听多个文件描述符的机制,使得程序可以同时等待多个文件描述符上的 I/O 操作。常见的 I/O 复用模型有
select、poll和epoll。通过 I/O 复用模型,程序可以同时处理多个连接或 I/O 操作,而不需要为每个连接或 I/O 操作创建一个独立的线程或进程。 -
信号驱动 I/O:信号驱动 I/O 是一种异步模式的 I/O,它使用信号来通知程序 I/O 操作已经就绪。程序在发起 I/O 操作后可以继续执行其他任务,当 I/O 操作就绪时,操作系统会发送一个信号给程序,程序可以捕获该信号并处理相应的 I/O 操作。
-
异步 I/O:异步 I/O 是一种完全异步的 I/O 模式,它允许程序发起 I/O 操作后继续执行其他任务,同时在后台完全异步地等待 I/O 操作的完成。当 I/O 操作完成后,程序会得到通知,并可以处理完成的数据。
信号驱动 I/O 和异步 I/O 是两种不同的异步模式,它们在处理 I/O 操作的方式和机制上有所不同。它们的选择通常基于应用程序的需求和底层操作系统的支持。对于信号驱动 I/O,操作系统会发送信号来通知 I/O 就绪,而异步 I/O 则使用回调函数或轮询等方式来处理完成的 I/O 操作。
![[BJDCTF2020]Mark loves cat foreach导致变量覆盖](https://img-blog.csdnimg.cn/1c0898034b6c4126a69982b70fd296b0.png)