目录
- 1 扩散模型与AI绘画
- 2 中文语料的挑战
- 3 昆仑天工:AIGC新思路
- 3.1 主要特色
- 3.2 模型蒸馏
- 3.3 编解码与GPT
- 3.4 stable-diffusion
- 3.5 性能指标
- 4 体验中文AI绘画模型
- 5 展望
1 扩散模型与AI绘画
AI绘画发展历史始于20世纪60年代,当时人工智能研究者们尝试使用电脑程序来模拟人类的绘画能力。在随后的几十年里,AI绘画技术不断发展,并逐渐开始应用于艺术创作和商业领域。在20世纪80年代,AI绘画技术发展到了一个新高度,电脑程序能够根据人类绘画的风格进行自动创作。这个时期的AI绘画主要应用于绘画动画和游戏领域,例如电脑游戏《模拟城市》中的画面就是由AI绘画技术完成的。20世纪90年代以来,随着人工智能技术的进一步发展,AI绘画技术也不断创新。人工智能算法开始使用深度学习来完成更复杂的绘画任务,例如根据图片内容进行自动绘画。此外,人工智能绘画技术也开始应用于商业用途,例如根据用户需求生成定制化的插画或品牌图标。
目前,AI绘画技术已经发展到了一个新的阶段,算法可以使用大量数据进行训练,完成更复杂的绘画任务。在AI绘画突然爆火?快速体验二次元画师NovelAI(diffusion)中,我们介绍了扩散算法diffusion,这个算法的基本原理是先将一幅画面逐步加入噪点,一直到整个画面都变成白噪声。记录这个过程,然后逆转过来给AI学习。AI看到的是什么?一个全是噪点的画面如何一点点变清晰直到变成一幅画,AI通过学习这个逐步去噪点的过程来学会作画。
然而,爆火的NovelAI提供的绘画软件也有缺陷——只能使用英文关键词生成图像,而且必须本地的显卡支持。
2 中文语料的挑战
比起NovelAI的英文文本生成图像模型,中文语料带来的挑战可太大了!
- 中英文分词方式不同
这点很好理解,英文词句间存在天然的分隔空格,例如英文句子:There is an apple on the wooden table;但是同样这句话的中文是木桌上有一个苹果,这要如何区分?木桌、木和桌是三个词,可单独划分理解,而苹和果却只能组合成词,所以如何正确的根据语义完成中文切分是一个挑战性的任务,一旦切词发生失误,会导致后续的文本处理产生连锁问题,给正确理解语义带来障碍 - 词性标注差异
英文中有大量中文所没有的词性——例如冠词、助动词等,这些词性的存在就好比关键词,给语义理解带来了很好的指引作用。而中文词性缺乏类似英文这样的明确规范,例如他热爱编程,这里的编程是名词,但在别的语境下却是动词 - 歧义性词语切分
例如兵乓球拍卖完了就有2种分词方式表达了2种不同的含义:乒乓球 \ 拍卖 \ 完了与乒乓 \ 球拍 \ 卖 \ 完了 - …
最近ChatGPT不是很火嘛?AI写代码、修Bug,甚至还想统治人类?快速体验ChatGPT,国内同样也有一家企业正在向AI生成文本(AIGC)领域发力,解决中文NLP领域的诸多问题
国内领先的互联网企业昆仑万维逐渐在全球范围内形成了海外信息分发及元宇宙平台Opera、海外社交娱乐平台StarX、全球移动游戏平台Ark Games、休闲娱乐平台闲徕互娱、投资板块等五大业务,昆仑天工则是由昆仑万维集团与合作伙伴奇点智源推出的全系列AIGC模型与算法,AI生成能力覆盖图像、音乐、编程、文本等全模态领域。

接下来,我们看看国内昆仑万维提出的AI绘画模型,如何克服NovelAI的窘境
3 昆仑天工:AIGC新思路
3.1 主要特色
昆仑万维提供的模型的一大特色是支持中文文本生成,其次是不依赖于显卡,可以在小程序上体验
- 在增加中文提示词输入能力的同时兼容原版stable_diffusion的英文提示词模型,之前用户积累的英文提示词手册依然可以使用
- 使用1.5亿级别的平行语料优化提示词模型实现中英文对照,不仅涉及翻译任务语料,还包括了用户使用频率高的提示词中英语料,古诗词中英语料,字幕语料,百科语料,图片文字描述语料等多场景多任务的海量语料集合,生成效果最好的开源GPT中文预训练大模型
- 训练时采用模型蒸馏方案和双语对齐方案,使用教师模型对学生模型蒸馏的同时辅以解码器语言对齐任务辅助模型训练
- 针对中文领域构建了千亿级别的高质量数据集,通过高性能a10-gpu集群,训练得到百亿参数量的GPT-3生成模型
- 模型拥有多样的下游能力,包括续写,对话,中英翻译,内容风格生成,推理,诗词对联等。并在各项专业性领域的任务中(例如分类,匹配,填空,识别,识别)表现突出,与现有大模型的比试中排列前茅
3.2 模型蒸馏
这里面有一个很重要的概念——模型蒸馏。为什么需要蒸馏?
在神经网络的轻量化技术中,蒸馏作为模型压缩类别内的一种举足轻重的技术流派,它的核心思想是让一个性能强大但网络复杂体积庞大不便于移动部署的模型作为教师模型,去引导一个性能较弱但网络简单体积较小易于在移动设备上部署的学生模型,知识从教师模型提取后直接迁移到学生模型中,此期间不经过另外的模型对知识重新提取优化。直接知识蒸馏一般模型数量相对较少,计算要求简单,在实际的任务场景中有广泛的应用。
昆仑天工的模型是千亿参数级别的,这是一个什么概念?千亿参数级别的深度学习模型通常由大量计算资源支撑,包括大量的GPU计算机和大规模的数据集。这些模型可以应用于各种领域,例如计算机视觉、自然语言处理、图像分类等。千亿参数级别的深度学习模型也常常被称为“超级模型”,因为它们的规模和复杂度远超过一般的深度学习模型。它们可以通过更多的数据进行训练,从而实现更高精度的预测和分类。

由于知识的转移不受模型结构的限制,该方法具有很强的灵活性,因此,自
2015年,Hinton等人系统总结了知识蒸馏的概念后,知识蒸馏受到了国内外研究者的广泛关注并不断被后续的研究者所改进。目前,对知识蒸馏技术的分类方法中,按照迁移的“知识”的定义不同,可以细分为将尾层输出当作知识的蒸馏方法,将中间隐藏层特征当作知识的蒸馏方法以及把关系当作知识的蒸馏方法,其中关系又可继续细分为样本间的关系、网络层间关系等。
像这种大规模深度学习产品,预训练模型通常需要占用很大的空间,并且训练和推断时间也很慢;直接在实际产品或应用中使用预训练模型难以满足时间和空间需求;昆仑天工正是应用知识蒸馏技术在不损失或少量损失性能的基础上,提升推断速度。
3.3 编解码与GPT
编解码的概念广泛应用于各个领域,在 NLP 领域,人们使用语言一般包括三个步骤:
接受听到或读到的语言 -> 大脑理解 -> 输出要说的语言。
语言是一个显式存在的东西,但大脑是如何将语言进行理解、转化、存储的,则是一个目前仍未探明的东西。因此,大脑理解语言这个过程,就是大脑将语言编码成一种可理解、可存储形式的过程,这个过程就叫做语言的编码。相应的,把大脑中想要表达的内容,使用语言表达出来,就叫做语言的解码。在语言模型中,编码器和解码器都是由一个个的 Transformer 组件拼接在一起形成的
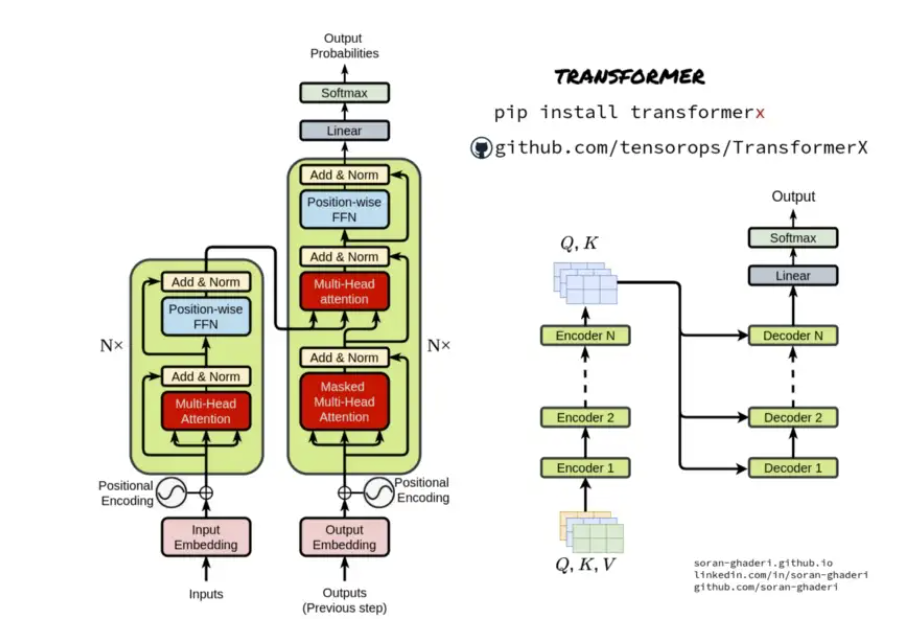
在介绍GPT模型之前,先介绍Bert。
来做一道完形填空题
_____和阿里、腾讯一起并成为中国互联网 BAT 三巨头。
请问上述空格应该填什么?有的人回答“百度”,有的人可能觉得,“字节”也没错。但总不再可能是别的字了。不论填什么,这里都表明,空格处填什么字,是受到上下文决定和影响的。
2018年谷歌出品的Bert所作的事就是从大规模的上亿的文本预料中,随机地扣掉一部分字,形成上面例子的完形填空题型,不断地学习空格处到底该填写什么。所谓语言模型的训练和学习,就是从大量的数据中学习复杂的上下文联系。
最初的时候,预训练任务仅仅是一个完形填空任务就可以让语言模型有了极大进步,那么,很多人就想,其它的语言题型应该也会对模型训练有极大的帮助。想要出语言题型不是很简单么,什么句子打乱顺序再排序、选择题、判断题、改错题、把预测单字改成预测实体词汇等等,纷纷都可以制定数据集添加在模型的预训练里。很多模型也都是这么干的。既然出题也可以,把各种NLP任务的数据集添加到预训练阶段当然也可以。那就把机器翻译、文本摘要、领域问答统统往预训练里加。这就诞生了GPT模型
昆仑天工正是使用了GPT模型,和传统Bert的区别是:Bert仅仅使用了encoder也就是编码器部分进行模型训练,GPT仅仅使用了 decoder 部分。而经验表明,GPT 的decoder模型更加适应于文本生成领域。

3.4 stable-diffusion
Stable diffusion是一个基于潜在扩散模型(Latent Diffusion Models,LDMs)的文图生成模型。具体来说,得益于Stability AI的计算资源支持和LAION的数据资源支持,Stable Diffusion在LAION-5B的一个子集上训练了一个Latent Diffusion Models,该模型专门用于文图生成。
Latent Diffusion Models通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。

Latent Diffusion Models整体框架如图,首先需要训练好一个自编码模型(AutoEncoder,包括一个编码器和一个解码器)。这样一来,我们就可以利用编码器对图片进行压缩,然后在潜在表示空间上做diffusion操作,最后我们再用解码器恢复到原始像素空间即可,称为感知压缩。
之前的很多扩散模型没有使用感知压缩也可以进行,但原有的非感知压缩的扩散模型有一个很大的问题在于,由于在像素空间上训练模型,如果我们希望生成一张分辨率很高的图片,这就意味着我们训练的空间也是一个很高维的空间。引入感知压缩就是说通过VAE这类自编码模型对原图片进行处理,忽略掉图片中的高频信息,只保留重要、基础的一些特征。这种方法带来的的好处就像引文部分说的一样,能够大幅降低训练和采样阶段的计算复杂度,让文图生成等任务能够在消费级GPU上,在10秒级别时间生成图片,大大降低了落地门槛。
感知压缩主要利用一个预训练的自编码模型,该模型能够学习到一个在感知上等同于图像空间的潜在表示空间。这种方法的一个优势是只需要训练一个通用的自编码模型,就可以用于不同的扩散模型的训练,在不同的任务上使用。这样一来,感知压缩的方法除了应用在标准的无条件图片生成外,也可以十分方便的拓展到各种图像到图像(inpainting,super-resolution)和文本到图像(text-to-image)任务上。
3.5 性能指标
进行图像生成任务中,我们的目的就是为了得到高质量的生成图像,那么总得需要个度量指标来衡量生成的图像是否是“高质量”的吧?不能完全靠人眼主观判断。这里提到生成图像的“高质量”,主要从两方面考虑:第一个是图像本身的质量。如:是否清晰,内容是否完整,是否逼真等;第二个是多样性。最终的生成器所生成的图像需要多种多样的,不能只生成一种或几种类型的图像。
R-Precision是一个很重要的模型指标,即召回率-准确率。对于判断正确/错误,有
- 准确率Accuracy
- 精确度Precision
- 召回率Recall
三个概念,在实际检测任务中,判断结果会存在 4 种情况:即第一种样本是正的,预测结果也是正的,即将正样本检测出来了,正确的正样本,用 True Positive(TP)表示;第二种样本是正的,预测结果是负的,即将正样本当作了负的,错误的负样本,用 False Negative(FN)表示;第三种样本是负的,预测结果也是负的,即将负样本检测出来了,正确的负样本,用 True Negative(TN)表示;第四种样本是负的,预测结果是正的,即将负样本当作了正的,错误的正样本,用 False Positive(FP)表示
以一个判断图片是否为狗的任务为例,TP 表示能够检测出狗,FN 表示图片是狗但没检测出来,TN 表示图片不是狗检测结果也不是狗,FP 则表示图片不是狗但检测结果是狗。因此可以用预测正确的样本数占整个样本数的比例来评价检测器性能。
接下来,我们再看看昆仑天工提供的AIGC指标。

需要指出的是,这里的评估baseline采用CNhneeCcLP(CNCLP),先根据模望的encoder得到text和image的embedding,再经过统一的KNN检索,从而计算出检索任务的Recall@1/5/10和平均Recall。评估数据集则采用Flickr30K-CN的测试数据集,采用同级别image encoder模型ViT-L/14。可以看出昆仑天工模型的性能和主流模型相比还是具有一定优势的。
4 体验中文AI绘画模型
最近卡塔尔世界杯正在进行,我们来试试用AI绘画生成风格迥异的足球
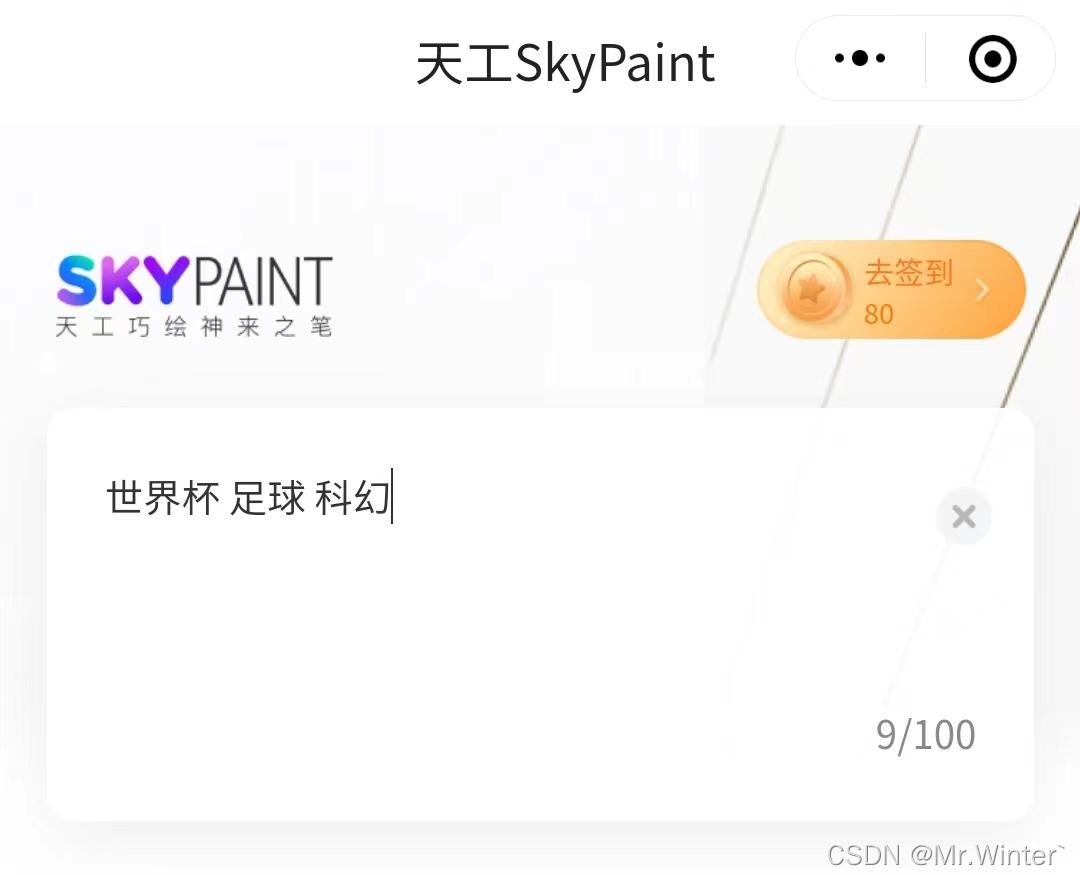
打开SkyPaint小程序,输入世界杯 足球 <风格>
科幻

热火

自然

徽章

- …
大家可以自行尝试体验
5 展望
面向未来,昆仑万维对 AI 文本生成图像也提出了展望,将来会引入更多语言的提示词输入支持、更强大的语言生成模型指导图像生成,会增加更多艺术风格的支持,并支持用户对生成的图像进行二次提示词编辑图像功能。
除AI作画外,昆仑万维提供的AI模型还涵盖AI文本、AI作曲、AI生成代码等功能,对其有需求、感兴趣的伙伴们,可以考虑尝试体验了。
🔥 更多精彩专栏:
- 《ROS从入门到精通》
- 《机器人原理与技术》
- 《机器学习强基计划》
- 《计算机视觉教程》
- …
![[每天进步一点点~] uni-app 聊天对话](https://img-blog.csdnimg.cn/img_convert/45880e7fc9d2e20516b58b50334dcd70.png)