ConfigurationClassPostProcessor源码 解析
书接上回,在第一次调用invokeBeanDefinitionRegistryPostProcessors方法的时候参数currentRegistryProcessors为ConfigurationClassPostProcessor,本章主要深入这个类的postProcessBeanDefinitionRegistry方法。
postProcessBeanDefinitionRegistry
首先看到的这句注释就能完整的概括这章源码的全部内容:从注册表中的配置类派生更多的bean definitions。刚看这句话可能理解不出来里面的意思,那就各位看官里面请。
/*** Derive further bean definitions from the configuration classes in the registry.*/@Overridepublic void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) {int registryId = System.identityHashCode(registry);if (this.registriesPostProcessed.contains(registryId)) {throw new IllegalStateException("postProcessBeanDefinitionRegistry already called on this post-processor against " + registry);}if (this.factoriesPostProcessed.contains(registryId)) {throw new IllegalStateException("postProcessBeanFactory already called on this post-processor against " + registry);}this.registriesPostProcessed.add(registryId);processConfigBeanDefinitions(registry);}
首先为BeanDefinitionRegistry生成了一个registryId,这个就是为了检验重复加载的问题,所以前面的都只是校验,如果只看主流程这些你都可以不看,直接关注最后一行代码,processConfigBeanDefinitions(registry)。
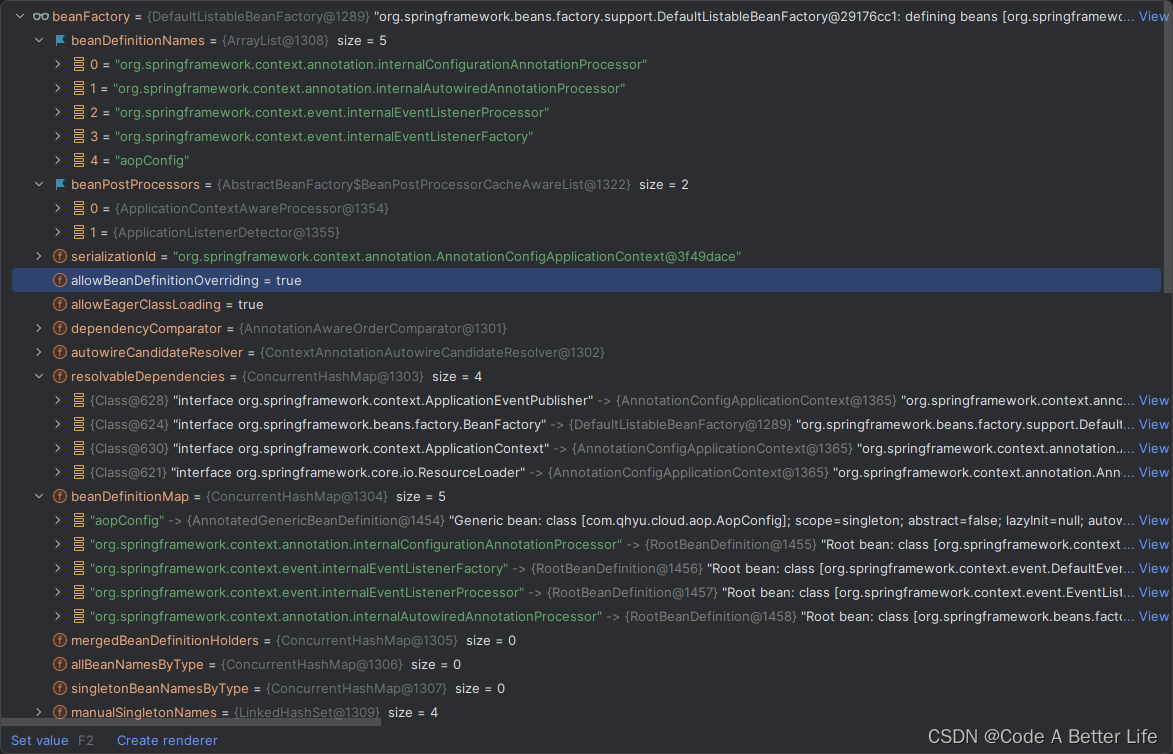
上面这张图可以知道registry中的具体属性内容,需要我们关注的是BeanDefinitionNames和beanPostProcessors这两个。aopConfig是我启动的时候的配置类,也就是我手动注册的类(register(componentClasses)),其他的都是spring自带的,本章的ConfigurationClassPostProcessor就是。
processConfigBeanDefinitions
开始进入正题,接下来就慢慢的拆解processConfigBeanDefinitions方法。
List<BeanDefinitionHolder> configCandidates = new ArrayList<>();// 当前BeanFacoty中存在的BeanDefinitonNamesString[] candidateNames = registry.getBeanDefinitionNames();for (String beanName : candidateNames) {// 根据名称获取BeanDefinitionBeanDefinition beanDef = registry.getBeanDefinition(beanName);if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {if (logger.isDebugEnabled()) {logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);}}// 检测配置候选人的条件,此处为true才会加入配置候选人// private static final Set<String> candidateIndicators = new HashSet<>(8);//// static {// candidateIndicators.add(Component.class.getName());// candidateIndicators.add(ComponentScan.class.getName());// candidateIndicators.add(Import.class.getName());// candidateIndicators.add(ImportResource.class.getName());// }// 也就是说只要包含这些也都是配置候选人else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));}}// Return immediately if no @Configuration classes were foundif (configCandidates.isEmpty()) {return;}
首先定义了一个configCandidates的集合,我们把他叫做后续按配置类集合,存放的是BeanDefinitionHolder,BeanDefinitionHolder和BeanDefinition是Spring框架中两个相关的概念,它们之间存在一种包含关系。
BeanDefinition是一个接口,用于描述一个bean的定义信息,包括bean的类名、作用域、依赖关系、属性值等信息。它是Spring框架中定义bean的元数据的核心表示形式。
BeanDefinitionHolder是一个包装类,用于持有BeanDefinition对象以及与之关联的bean名称。它包含两个主要成员变量:bean名称和BeanDefinition对象。
在Spring框架的内部,BeanDefinitionHolder常用于在注册表中存储和管理bean的定义。它提供了一个包装机制,使得可以将bean名称与其对应的BeanDefinition关联起来,并一起存储在注册表中。
通过BeanDefinitionHolder,可以轻松地访问和操作与特定bean相关联的BeanDefinition。它提供了一种方便的方式来获取bean的名称、获取和设置BeanDefinition的属性值等操作。
candidateNames是一个string数组,从上面的截图可以看出,当前会有5个BeanDefinitionNames,然后进入for循环,for循环要做的事情就是把这些BeanDefinition拿出来判断是否是候选配置类。
else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));}
ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)方法就是用来判断是否是候选类,可以看出configCandidates.add方法就只在这里用到了。
public static boolean checkConfigurationClassCandidate(BeanDefinition beanDef, MetadataReaderFactory metadataReaderFactory) {String className = beanDef.getBeanClassName();if (className == null || beanDef.getFactoryMethodName() != null) {return false;}AnnotationMetadata metadata;if (beanDef instanceof AnnotatedBeanDefinition &&className.equals(((AnnotatedBeanDefinition) beanDef).getMetadata().getClassName())) {// Can reuse the pre-parsed metadata from the given BeanDefinition...metadata = ((AnnotatedBeanDefinition) beanDef).getMetadata();}else if (beanDef instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) beanDef).hasBeanClass()) {// Check already loaded Class if present...// since we possibly can't even load the class file for this Class.Class<?> beanClass = ((AbstractBeanDefinition) beanDef).getBeanClass();if (BeanFactoryPostProcessor.class.isAssignableFrom(beanClass) ||BeanPostProcessor.class.isAssignableFrom(beanClass) ||AopInfrastructureBean.class.isAssignableFrom(beanClass) ||EventListenerFactory.class.isAssignableFrom(beanClass)) {return false;}metadata = AnnotationMetadata.introspect(beanClass);}else {try {MetadataReader metadataReader = metadataReaderFactory.getMetadataReader(className);metadata = metadataReader.getAnnotationMetadata();}catch (IOException ex) {if (logger.isDebugEnabled()) {logger.debug("Could not find class file for introspecting configuration annotations: " +className, ex);}return false;}}Map<String, Object> config = metadata.getAnnotationAttributes(Configuration.class.getName());if (config != null && !Boolean.FALSE.equals(config.get("proxyBeanMethods"))) {beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL);}else if (config != null || isConfigurationCandidate(metadata)) {beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);}else {return false;}// It's a full or lite configuration candidate... Let's determine the order value, if any.Integer order = getOrder(metadata);if (order != null) {beanDef.setAttribute(ORDER_ATTRIBUTE, order);}return true;}
虽然上述的代码看起来很长,而且杂七杂八的逻辑判断让我们不知道如何下手,这个时候可以打端点调试一下。
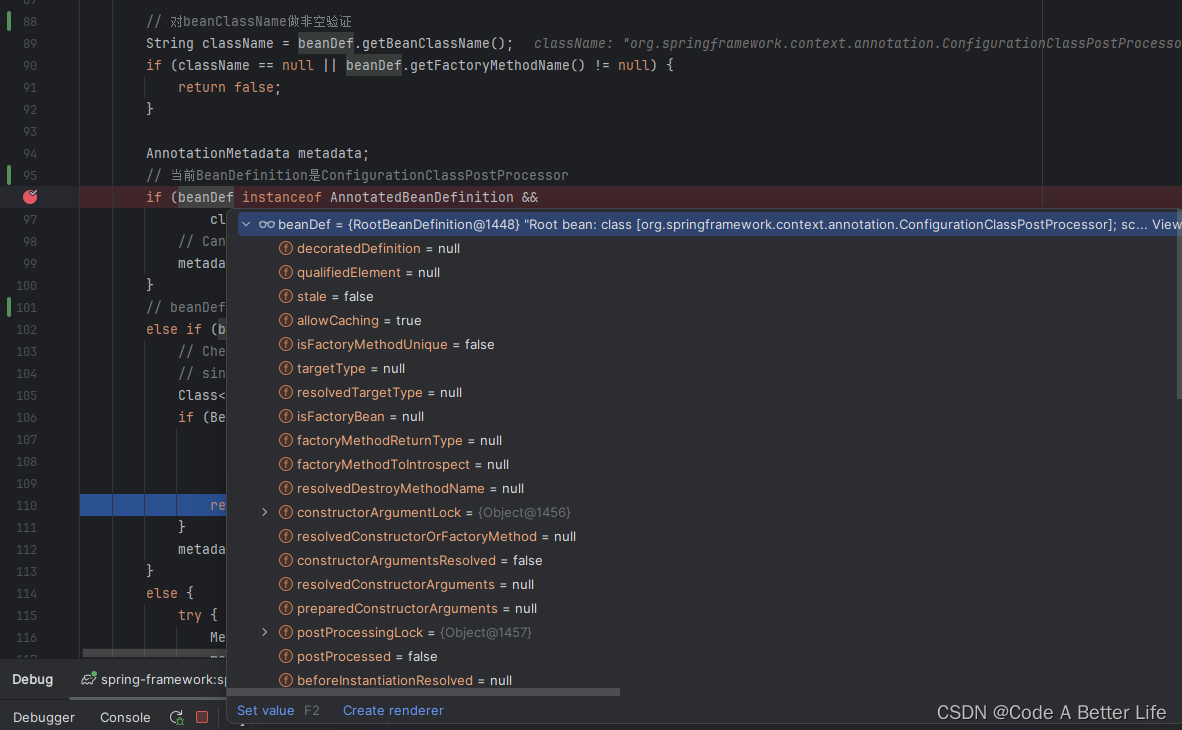
唉哟,beanDef是RootBeanDefinition类型,所以会进入else if的逻辑里面,也就到了我们这段代码的第一个核心逻辑。因为这里有个return,所以在看的时候需要关注一下。
Class<?> beanClass = ((AbstractBeanDefinition) beanDef).getBeanClass();if (BeanFactoryPostProcessor.class.isAssignableFrom(beanClass) ||BeanPostProcessor.class.isAssignableFrom(beanClass) ||AopInfrastructureBean.class.isAssignableFrom(beanClass) ||EventListenerFactory.class.isAssignableFrom(beanClass)) {return false;}
这段代码用于过滤掉特定类型的bean,不对它们应用后续的处理。
具体来说,改代码中的条件判断用于检查给定的beanClass是否属于以下四个类型之一:
1、BeanFactoryPostProcessor:实现了BeanFactoryPostProcessor接口的类,用于在容器实例化任何其他bean之前对bean工厂进行自定义修改。
2、BeanPostProcessor:实现了BeanPostProcessor接口的类,用于在容器实例化bean时对bean进行自定义处理,例如初始化前后的操作。
3、AopInfrastructureBean:实现了AopInfrastructureBean接口的类,用于定义AOP基础设施bean,如AOP代理工厂等。
4、EventListenerFactory:实现了EventListenerFactory接口的类,用于创建事件监听的工厂。
如果给定的beanClass是上述四个类型之一,那么该代码会返回false,表示不对该类型的bean应用后续的处理。
打端点之后其实可以知道Spring自己注入的那些都会被跳过,唯独就是我们手动registry(AopConfig.class)

else {try {MetadataReader metadataReader = metadataReaderFactory.getMetadataReader(className);metadata = metadataReader.getAnnotationMetadata();}catch (IOException ex) {if (logger.isDebugEnabled()) {logger.debug("Could not find class file for introspecting configuration annotations: " +className, ex);}return false;}}Map<String, Object> config = metadata.getAnnotationAttributes(Configuration.class.getName());if (config != null && !Boolean.FALSE.equals(config.get("proxyBeanMethods"))) {beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_FULL);}else if (config != null || isConfigurationCandidate(metadata)) {beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);}else {return false;}// It's a full or lite configuration candidate... Let's determine the order value, if any.Integer order = getOrder(metadata);if (order != null) {beanDef.setAttribute(ORDER_ATTRIBUTE, order);}
然后我们可以知道metadataReader就是元数据的读取,然后看是否含有@Configuration注解,我们的AopConfig其实是没有@Configutation注解的。
// 容器启动
AnnotationConfigApplicationContext annotationConfigApplicationContext =new AnnotationConfigApplicationContext(AopConfig.class);// AopCofig类,类似于SpringBoot的Application启动类
@ComponentScan(value = {"com.qhyu.cloud.**"})
public class AopConfig {// 啥也没有
}
所以第二个核心逻辑就是isConfigurationCandidate(matedata),ConfigurationClassUtils类中。
public static boolean isConfigurationCandidate(AnnotationMetadata metadata) {// Do not consider an interface or an annotation...if (metadata.isInterface()) {return false;}// Any of the typical annotations found?for (String indicator : candidateIndicators) {if (metadata.isAnnotated(indicator)) {return true;}}// Finally, let's look for @Bean methods...return hasBeanMethods(metadata);}
如果是个接口直接返回false,说明得是类才可以。candidateIndicators是一个静态的全局变量,内容是static静态代码块里加载的。
private static final Set<String> candidateIndicators = new HashSet<>(8);static {candidateIndicators.add(Component.class.getName());candidateIndicators.add(ComponentScan.class.getName());candidateIndicators.add(Import.class.getName());candidateIndicators.add(ImportResource.class.getName());}
很明朗了对吧。就是包含这些注解的,都会被加入到configCandidates配置后端名单中。
跳出方法查看beanDef.setAttribute(CONFIGURATION_CLASS_ATTRIBUTE, CONFIGURATION_CLASS_LITE);这行代码将一个名为 CONFIGURATION_CLASS_ATTRIBUTE 的属性设置为值 CONFIGURATION_CLASS_LITE。
在Spring中,CONFIGURATION_CLASS_ATTRIBUTE是一个常量,用于指示配置类的类型。它通常用于标识配置类是以何种方式加载和处理的。
CONFIGURATION_CLASS_LITE 和 CONFIGURATION_CLASS_FULL 是两种可能的取值,表示不同类型的配置类:
1、CONFIGURATION_CLASS_LITE:表示轻量级配置类。这种类型的配置类通常是通过@Configuration注解进行标记的,但不包含任何特殊的逻辑处理。它们可能指示简单地定义一些bean的声明,而没有涉及复杂的依赖注入、条件化配置或其他高级功能。轻量级配置类在处理过程中会更加简单和高效。
2、CONFIGURATION_CLASS_FULL:表示完全配置类。这种类型的配置类包含了更多的复杂逻辑和功能,如条件配置、依赖注入、AOP、事件处理等。完全配置类可能使用了更多的Spring功能和特性,需要进行更全面的解析和处理。
重回processConfigBeanDefinitions
去过了最远的地方,还得回到最原来的地方。
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {//registry 也就是BeanFactory(ConfigurableListableBeanFactory)// configCandidates Candidates候选人List<BeanDefinitionHolder> configCandidates = new ArrayList<>();// 当前BeanFacoty中存在的BeanDefinitonNamesString[] candidateNames = registry.getBeanDefinitionNames();for (String beanName : candidateNames) {// 根据名称获取BeanDefinitionBeanDefinition beanDef = registry.getBeanDefinition(beanName);if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) {if (logger.isDebugEnabled()) {logger.debug("Bean definition has already been processed as a configuration class: " + beanDef);}}// 检测配置候选人的条件,此处为true才会加入配置候选人// private static final Set<String> candidateIndicators = new HashSet<>(8);//// static {// candidateIndicators.add(Component.class.getName());// candidateIndicators.add(ComponentScan.class.getName());// candidateIndicators.add(Import.class.getName());// candidateIndicators.add(ImportResource.class.getName());// }// 也就是说只要包含这些也都是配置候选人else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) {configCandidates.add(new BeanDefinitionHolder(beanDef, beanName));}}// Return immediately if no @Configuration classes were foundif (configCandidates.isEmpty()) {return;}
当ConfigurationClassUtils类的isConfigurationCandidate返回true之后就说明ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)返回true。所以会把当前beanDefinitionHolder加入到配置候选集合中。当然如果配置候选集合为空就直接return了。
接下来这个就是单纯的排序,这边直接跳过,不耽误时间,有兴趣自己深入,或者后续单独讲一期排序。
// Sort by previously determined @Order value, if applicableconfigCandidates.sort((bd1, bd2) -> {int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition());int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition());return Integer.compare(i1, i2);});SingletonBeanRegistry sbr = null;if (registry instanceof SingletonBeanRegistry) {sbr = (SingletonBeanRegistry) registry;if (!this.localBeanNameGeneratorSet) {BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton(AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR);if (generator != null) {this.componentScanBeanNameGenerator = generator;this.importBeanNameGenerator = generator;}}}if (this.environment == null) {this.environment = new StandardEnvironment();}
排序下面这段代码用于获取并设置组件扫描时使用的Bean名称生成器。
首先定义了一个SingletonBeanRegistry类型的变量sbr并初始化为null。然后,通过检查registry对象是否是SingletonBeanRegistry的实例来确定是否可以进行后续的操作。
如果registry是SingletonBeanRegistry的实例,说明它是一个单例Bean注册表,可以用于获取和设置单例Bean。接下来,讲registry对象强制转换为SingletonBeanRegistry类型,并将其赋值给sbr变量。
代码尝试从sbr中获取名为AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR的单例Bean。这个常量是用于指定配置类的Bean名称生成器的键。如果能够获取到该单例Bean,说明已经为配置类设置了特定的Bean名称生成器。如果generator不为null,代码将获取到的generator赋值给两个成员变量:componentScanBeanNameGenerator和importBeanNameGenerator。这两个成员变量分别用于组件扫描和导入Bean时使用的Bean名称生成器。
通过这段代码,可以实现以下功能:
- 检查是否有合适的单例Bean注册表可用。
- 获取配置类的Bean名称生成器。
- 设置组件扫描和导入Bean时使用的Bean名称生成器。
这样做的目的是为了在Spring的组件扫描和Bean加载过程中使用适当的Bean名称生成器,以确保生成的Bean名称符合预期并与其他组件协调一致。
// Parse each @Configuration classConfigurationClassParser parser = new ConfigurationClassParser(this.metadataReaderFactory, this.problemReporter, this.environment,this.resourceLoader, this.componentScanBeanNameGenerator, registry);// 这是候选人Set,去重Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates);// 以及解析了的配置类Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size());do {StartupStep processConfig = this.applicationStartup.start("spring.context.config-classes.parse");// 解析我们的配置类,我们使用AnnotationConfigApplicationContent启动的时候,使用的构造函数进行创建// 也就是加入了@ComponentScan注解,需要根据里面的路径扫描包路径,从而找到所有需要被Spring管理的Bean的beanDefiniton信息// ConfigurationClassParser去解析我们的AopConfig类.这个类只会在启动的时候呗调用一次parser.parse(candidates);// 验证parser.validate();Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());configClasses.removeAll(alreadyParsed);// Read the model and create bean definitions based on its contentif (this.reader == null) {this.reader = new ConfigurationClassBeanDefinitionReader(registry, this.sourceExtractor, this.resourceLoader, this.environment,this.importBeanNameGenerator, parser.getImportRegistry());}// ImportBeanDefinitionRegistrar扫描实现了这个接口的方法// ConfigurationClassParser解析的在这里又读出来,这里需要打断点再观察一下。this.reader.loadBeanDefinitions(configClasses);alreadyParsed.addAll(configClasses);processConfig.tag("classCount", () -> String.valueOf(configClasses.size())).end();candidates.clear();if (registry.getBeanDefinitionCount() > candidateNames.length) {String[] newCandidateNames = registry.getBeanDefinitionNames();Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames));Set<String> alreadyParsedClasses = new HashSet<>();for (ConfigurationClass configurationClass : alreadyParsed) {alreadyParsedClasses.add(configurationClass.getMetadata().getClassName());}for (String candidateName : newCandidateNames) {if (!oldCandidateNames.contains(candidateName)) {BeanDefinition bd = registry.getBeanDefinition(candidateName);if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) &&!alreadyParsedClasses.contains(bd.getBeanClassName())) {candidates.add(new BeanDefinitionHolder(bd, candidateName));}}}candidateNames = newCandidateNames;}}while (!candidates.isEmpty());
这段代码是最最最核心的内容,还会引入一个新的类来解析和处理候选配置类,本章我们主要梳理这段代码的逻辑,深入的源码将在下一章节来分析。
1、创建一个ConfigurationClassParser对象并进行初始化。该对象用于解析候选配置类,并生成相应的配置类对象(ConfigurationClass)和相关的Bean定义。
2、创建一个Set<BeanDefinitionHolder>类型的变量candidates,用于存储候选的Bean定义持有者。这些候选人是从configCandidates中获取的,它是一个包含待解析的候选配置类的集合。
3、创建一个Set<ConfigurationClass>类型的变量alreadyParsed,用于存储已经解析过的配置类。
4、进入循环,直到候选人集合为空。在每次循环迭代中,执行以下操作:
a. 启动一个性能追踪步骤,记录解析过程的性能指标。
b. 调用parser.parse(candidates)方法,解析candidates中的候选配置类。在解析过程中,将根据配置类的内容创建相应的Bean定义。
c. 调用parser.validate()方法,对解析后的配置类进行验证,确保它们符合规范。
d. 获取解析后的配置类集合,并将其与已解析的配置类集合进行比较,筛选出新增的配置类。
e. 如果this.reader为null,则创建一个ConfigurationClassBeanDefinitionReader对象,用于读取模型并基于其内容创建Bean定义。
f. 调用this.reader.loadBeanDefinitions(configClasses)方法,将配置类转换为Bean定义,并注册到Bean定义注册表中。
g. 将已解析的配置类添加到alreadyParsed集合中。
h. 根据新的Bean定义数量更新candidateNames数组,并筛选出新增的候选人Bean定义。
i. 清空candidates集合,准备下一次循环迭代。
整个过程会迭代解析和处理所有的候选配置类,将它们转换为相应的Bean定义,并注册到Bean定义注册表中。这样,这些候选配置类中声明的Bean就可以在应用程序中使用和管理了。
总结
本章就ConfigurationClassPostProcessor的processConfigBeanDefinitions方法做了深入的源码分析,描述了方法内部所完成的spring实例化的过程,具体的在项目启动过程中如何将我们自己定义的需要被spring管理的bean的定义信息放入工厂中,会在下一个章节进行详细的分析。