目录
一、Spark 是什么
1.1 统一分析引擎?
二、Spark 风雨十年
三、Spark VS Hadoop(MapReduce)
3.1 面试题:Hadoop 的基于进程的计算和 Spark 基于线程方式优缺点?
四、Spark 四大特点
4.1 速度快
4.2 易于使用
4.3 通用性强
4.4 运行方式
五、Spark 框架模块
5.1 介绍
5.2 Spark 的运行模式
5.3 Spark 的架构角色
5.3.1 YARN 角色回顾
5.3.2 Spark 运行角色
一、Spark 是什么
Apache Spark 是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。

Spark 最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念。
 翻译过来就是:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着 RDD 进行。
翻译过来就是:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着 RDD 进行。
 简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的 API 提高了开发速度。
简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的 API 提高了开发速度。
1.1 统一分析引擎?
Spark 是一款分布式内存计算的统一分析引擎。其特点就是对任意类型的数据进行自定义计算。Spark 可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用 Python、Java、Scala、R 以及 SQL 语言去开发应用程序计算数据。
Spark 的适用面非常广泛,所以,被称之为统一的(适用面广)的分析引擎(数据处理) 。
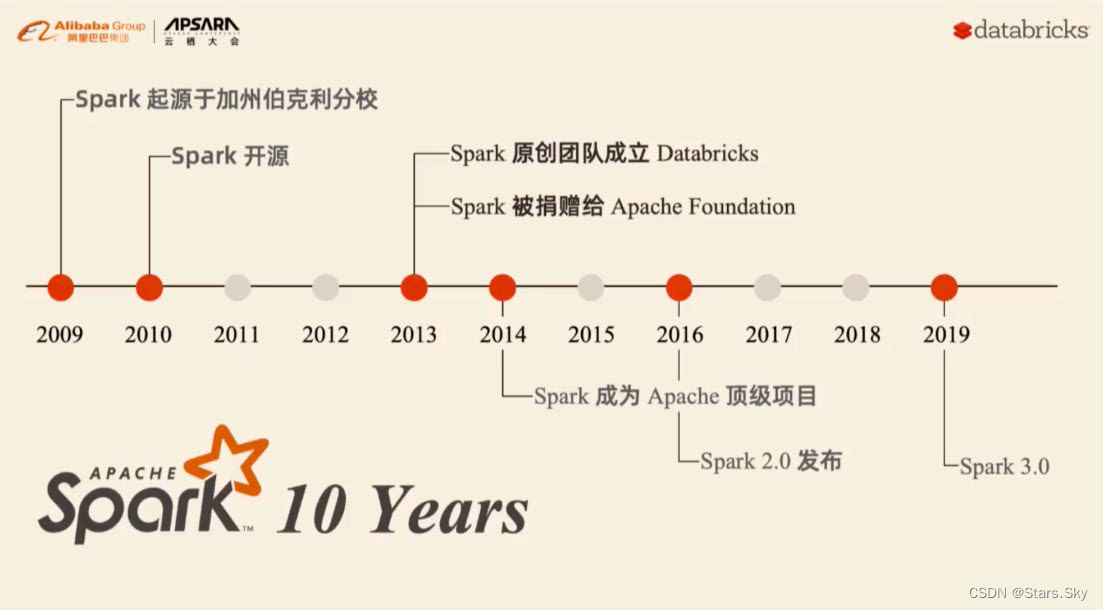
二、Spark 风雨十年
Spark 是加州大学伯克利分校 AMP 实验室(Algorithms Machines and People Lab)开发的通用大数据处理框架。
Spark 的发展历史,经历过几大重要阶段,如下图所示:
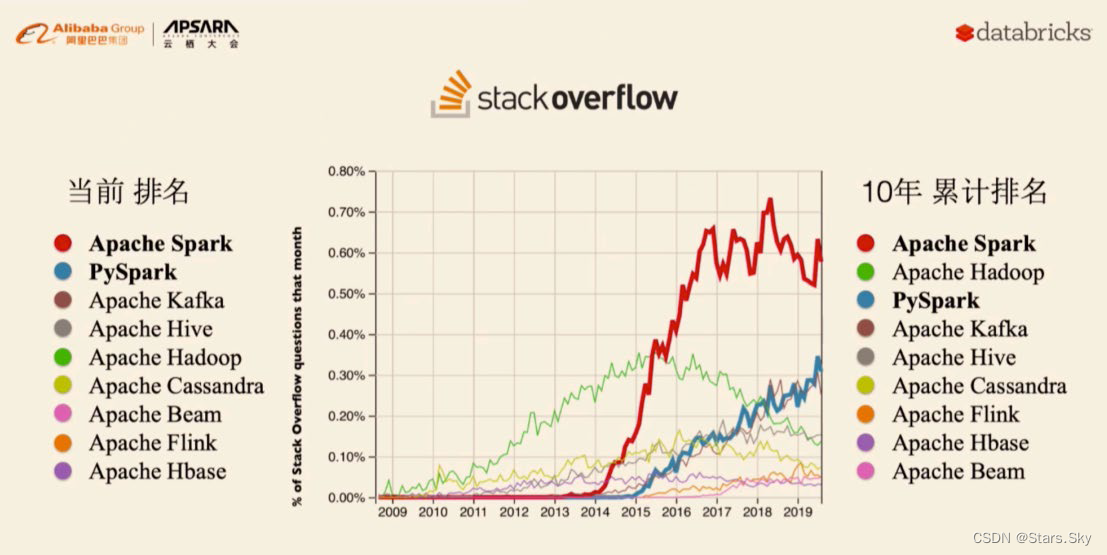
 从下面的 Stack Overflow 的数据可以看出,2015 年开始 Spark 每月的问题提交数量已经超越 Hadoop,而 2018 年 Spark Python 版本的 API PySpark 每月的问题提交数量也已超过 Hadoop。2019 年排名 Spark 第一,PySpark 第二;而十年的累计排名是 Spark 第一,PySpark 第三。按照这个趋势发展下去,Spark 和 PySpark 在未来很长一段时间内应该还会处于垄断地位。
从下面的 Stack Overflow 的数据可以看出,2015 年开始 Spark 每月的问题提交数量已经超越 Hadoop,而 2018 年 Spark Python 版本的 API PySpark 每月的问题提交数量也已超过 Hadoop。2019 年排名 Spark 第一,PySpark 第二;而十年的累计排名是 Spark 第一,PySpark 第三。按照这个趋势发展下去,Spark 和 PySpark 在未来很长一段时间内应该还会处于垄断地位。
 三、Spark VS Hadoop(MapReduce)
三、Spark VS Hadoop(MapReduce)
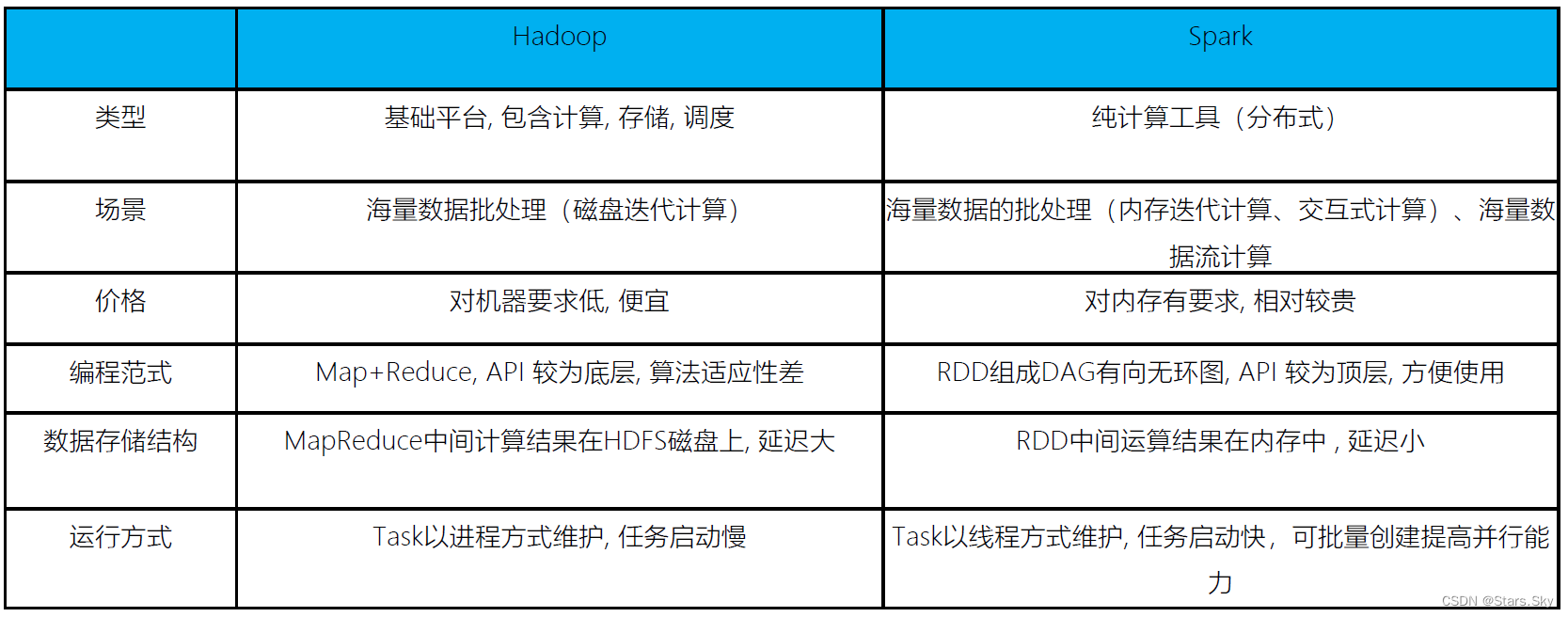 尽管 Spark 相对于 Hadoop 而言具有较大优势,但 Spark 并不能完全替代 Hadoop:
尽管 Spark 相对于 Hadoop 而言具有较大优势,但 Spark 并不能完全替代 Hadoop:
- 在计算层面,Spark 相比较 MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于 MR 构架,比如非常成熟的 Hive;
- Spark 仅做计算,而 Hadoop 生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS 和 YARN 仍是许多大数据体系的核心架构。
3.1 面试题:Hadoop 的基于进程的计算和 Spark 基于线程方式优缺点?
答案:Hadoop 中的 MR 中每个 map/reduce task 都是一个 java 进程方式运行,好处在于进程之间是互相独立的,每个 task 独享进程资源,没有互相干扰,监控方便,但是问题在于 task 之间不方便共享数据,执行效率比较低。比如多个 map task 读取不同数据源文件需要将数据源加载到每个 map task 中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark 采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
【扩展阅读】:线程基本概念
- 线程是 CPU 的基本调度单位;
- 一个进程一般包含多个线程, 一个进程下的多个线程共享进程的资源;
- 不同进程之间的线程相互不可见;
- 线程不能独立执行;
- 一个线程可以创建和撤销另外一个线程 。
四、Spark 四大特点
 4.1 速度快
4.1 速度快
由于 Apache Spark 支持内存计算,并且通过 DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比 Hadoop 的 MapReduce 快 100 倍,在硬盘中要快 10 倍。
Spark 处理数据与 MapReduce 处理数据相比,有如下两个不同点:
- Spark 处理数据时,可以将中间处理结果数据存储到内存中;
- Spark 提供了非常丰富的算子(API),可以做到复杂任务在一个 Spark 程序中完成。
4.2 易于使用
Spark 的版本已经更新到 Spark 3.2.0(截止日期 2021.10.13),支持了包括 Java、Scala、Python 、R 和 SQL 语言在内的多种语言。为了兼容 Spark2.x 企业级应用场景,Spark 仍然持续更新 Spark2 版本。
4.3 通用性强
在 Spark 的基础上,Spark 还提供了包括 Spark SQL、Spark Streaming、MLib 及GraphX 在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。
 4.4 运行方式
4.4 运行方式
Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone 的独立运行模式,同时也可以运行在云 Kubernetes(Spark 2.3 开始支持)上。
 对于数据源而言,Spark 支持从 HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
对于数据源而言,Spark 支持从 HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
五、Spark 框架模块
5.1 介绍
整个 Spark 框架模块包含:Spark Core、Spark SQL、Spark Streaming、Spark GraphX、Spark MLlib,而后四项的能力都是建立在核心引擎之上。

- Spark Core:Spark 的核心,Spark 核心功能均由 Spark Core 模块提供,是 Spark 运行的基础。Spark Core 以 RDD 为数据抽象,提供 Python、Java、Scala、R 语言的 API,可以编程进行海量离线数据批处理计算。
- SparkSQL:基于 SparkCore 之上,提供结构化数据的处理模块。SparkSQL 支持以 SQL 语言对数据进行处理,SparkSQL 本身针对离线计算场景。同时基于 SparkSQL,Spark 提供了 StructuredStreaming 模块,可以以 SparkSQL 为基础,进行数据的流式计算。
- SparkStreaming:以 SparkCore 为基础,提供数据的流式计算功能。
- MLlib:以 SparkCore 为基础,进行机器学习计算,内置了大量的机器学习库和 API 算法等。方便用户以分布式计算的模式进行机器学习计算。
- GraphX:以 SparkCore 为基础,进行图计算,提供了大量的图计算 API,方便用于以分布式计算模式进行图计算。
5.2 Spark 的运行模式
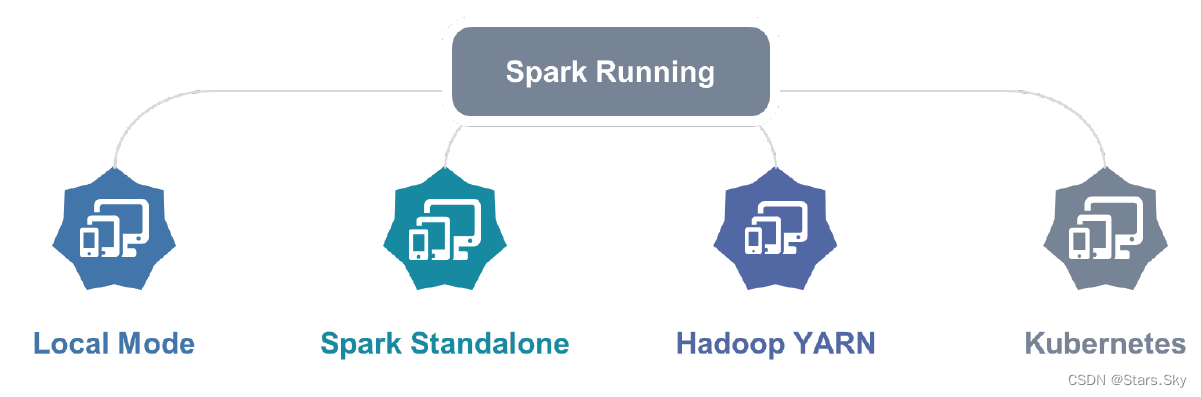
Spark提供多种运行模式,包括:
- 本地模式(单机)
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个 Spark 运行时环境。
- Standalone 模式(集群)
Spark 中的各个角色以独立进程的形式存在,并组成 Spark 集群环境。
- Hadoop YARN 模式(集群)
Spark 中的各个角色运行在 YARN 的容器内部,并组成 Spark 集群环境。
- -Kubernetes 模式(容器集群)
Spark 中的各个角色运行在 Kubernetes 的容器内部,并组成 Spark 集群环境。
5.3 Spark 的架构角色
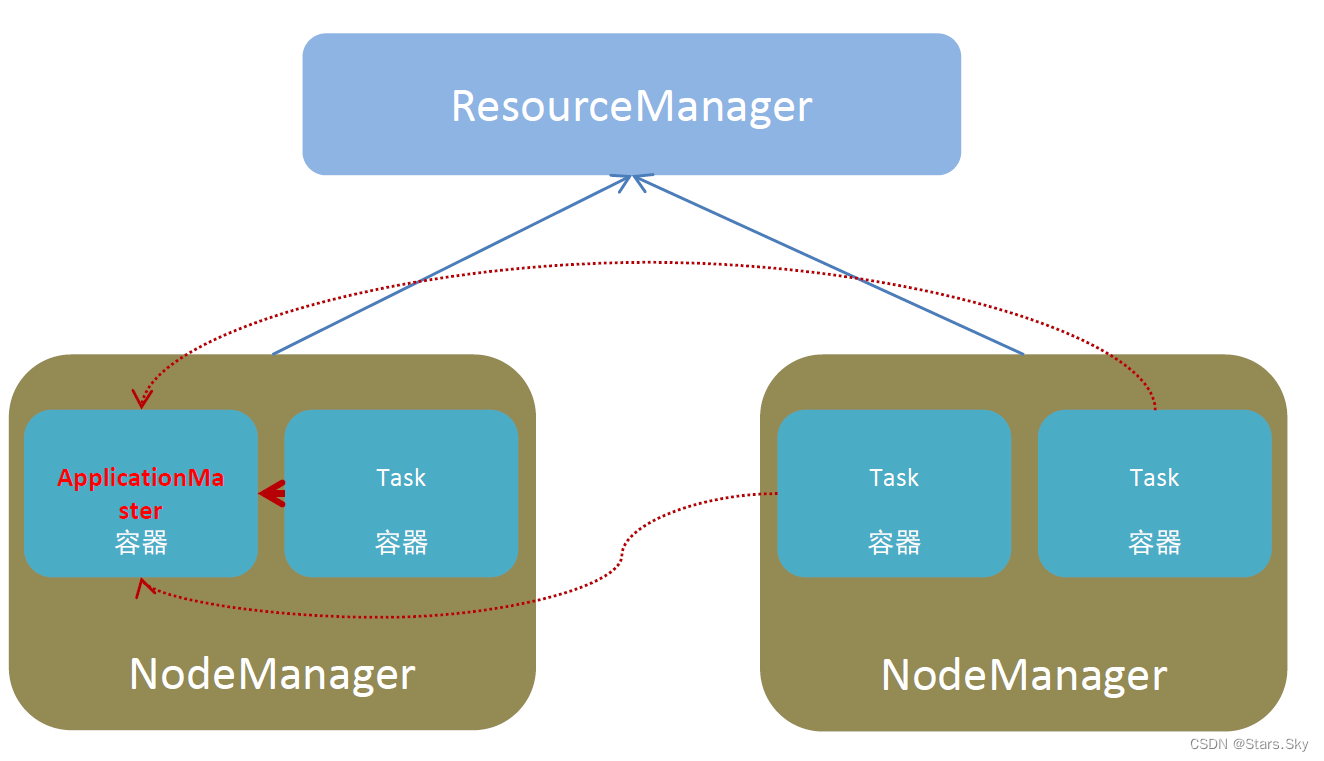
5.3.1 YARN 角色回顾
YARN 主要有 4 类角色,从 2 个层面去看:
资源管理层面
- 集群资源管理者(Master):ResourceManager
- 单机资源管理者(Worker):NodeManager
任务计算层面
- 单任务管理者(Master):ApplicationMaster
- 单任务执行者(Worker):Task(容器内计算框架的工作角色)
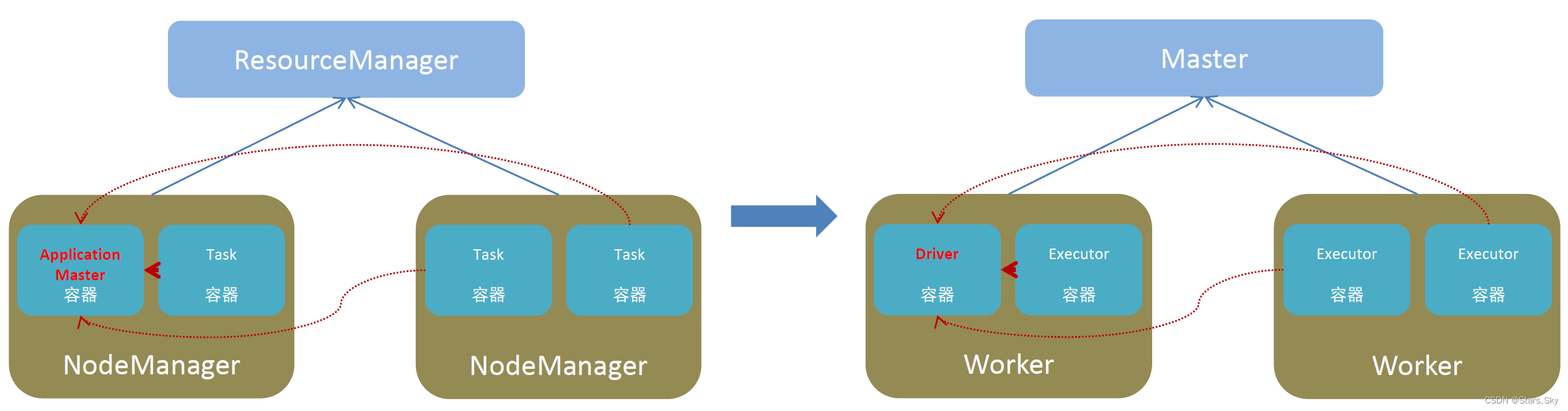
 5.3.2 Spark 运行角色
5.3.2 Spark 运行角色

注:正常情况下 Executor 是干活的角色,不过在特殊场景下(Local 模式)Driver 可以即管理又干活。
上一篇文章:HDFS 架构剖析_Stars.Sky的博客-CSDN博客
下一篇文章:Spark-3.2.4 高可用集群安装部署详细图文教程_Stars.Sky的博客-CSDN博客