TiDB Hackathon 2023 刚刚结束,我仔细地审阅了所有的项目。 在并未强调项目必须使用人工智能(AI)相关技术的情况下,引人注目的项目几乎一致地都使用了 AI 来构建自己的应用。 大规模语言模型(LLM)的问世使得个人开发者能够在短短 5 分钟内为程序赋予推理能力,而这在以往,几乎只有超大型团队才能胜任。 从应用开发者的角度来看,AI 时代也已经到来了。
在这些 AI 应用中,向量数据库的身影是无处不在的。尽管这些项目大多仍在使用关系型数据库,但它们似乎不再发挥一个显而易见的作用。关系型数据库究竟还值不值得获得应用开发者们的关注呢?
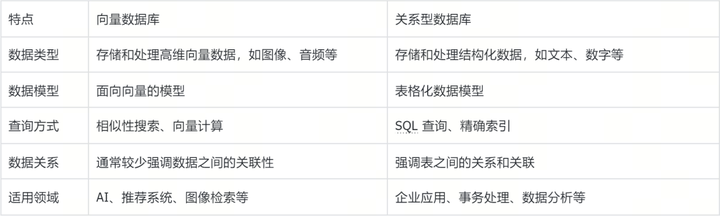
为了解答清楚这个问题,我们需要了解一下向量数据库到底跟传统的关系型数据库有什么不同。
什么是向量数据库?
为了搞清楚这个问题,我花了一些时间研究了一下向量数据库。接下来我讲用最简单的语言来解释什么是向量数据库。
这个世界上的大多数事情都是多特征的,比如你描述一个人可以用身高、体重、性格、性别、穿衣风格、兴趣爱好等等多种不同类型的维度。通常如果你愿意的话,你可以无限扩展这个维度或者特征去描述一个物体,维度或者特征越多,对于一个物体或者事件的描述就是越准确的。
现在,假如开始用一个维度来表达 Emoji 表情的话,0 代表快乐,1 代表悲伤。从 0 - 1 的数字大小就可以表达对应表情的悲欢程度,如下 x 轴所示:

但是你会发现,如果只有一个维度来描述情绪 Emoji 的话,这是笼统的,也是不够准确的。例如开心,会有很多种类型的 Emoji 可以表达。那么这个时候我们通常是加入新的维度来更好地描述它。例如我们在这里加入 Y 轴,通过 0 表示黄色,1 表示白色。加入之后表达每个表情在坐标轴上的点变成了 (x, y) 的元组形式。
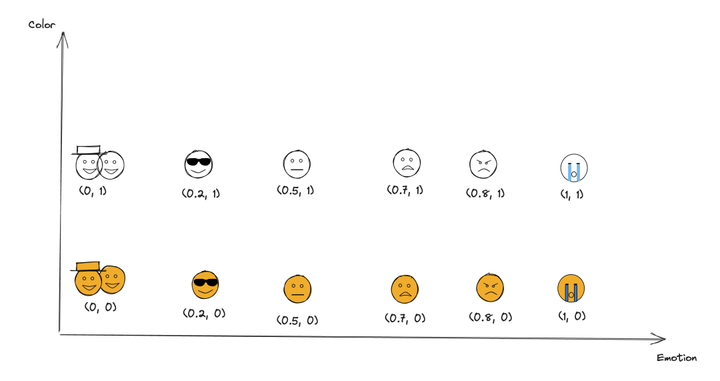
聪明的你一定发现了,即使我们加入 Y 轴这个新的描述维度,依然还有 Emoji 我们是没办法区分开的。比如
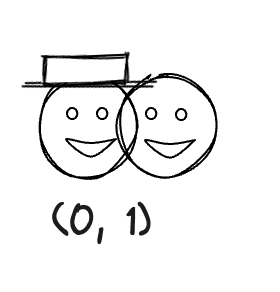
那么怎么办呢?解决这个办法依然很简单,再加一个维度。在坐标系中就是加入 z 轴。我们把新的维度简单设置为是否戴帽子(注意这里每个维度的取值尽可能地简单是为了阐述,不代表真实世界也如此简单)。用 0 表示没戴,1 表示戴了。所以我们现在就得到了一个 (x, y, z) 的三维坐标点来描述一个 Emoji 了。

当然在现实世界中,一个事物的性质不会那么少,所以我们需要通过增加很多个维度来描述它,所以就出现了类似高维数组这样的描述 (0.123, 0.295, 0.358, 0.222 ...)。到这里我们已经非常接近向量数据库中的 “向量” 了,其实向量数据库中存的就是这样的一些数组,用以表示各种各样的数据,包括图片、视频、文字等等。这些事物都是经过我们上述这种转换的方式,把它们变成了一个个高维的数组,然后保存下来。
可能说到这里你还不理解向量数据库有什么作用:为什么我们要把事物变成这样的形式?
简单来讲,这是因为变成向量以后,我们就有办法去量化世界上任意两种事物之间的关联性和相似性了。通过我们刚才的演示,各个维度上越接近的事物,就会在空间中越接近。通过计算两个点之间的距离,就可以判断两者的相似度。

那么如果我们有一个之前从未出现过的一个 Emoji,我们通过上面的方式,可以把这个 Emoji 变成向量(0.01, 1, 0)。

通过计算跟库中的已经存储的向量,就可以找出来最接近的 Emoji 是

次之距离接近的就是

作为佐证,可以看看 PineCone Query Data ( https://docs.pinecone.io/docs/query-data#sending-a-query ) 获取数据的例子(Score 可以简单被认为是相似度):
index.query(vector=[0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3],top_k=3,include_values=True
)
# Returns:
# {'matches': [{'id': 'C',
# 'score': -1.76717265e-07,
# 'values': [0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3, 0.3]},
# {'id': 'B',
# 'score': 0.080000028,
# 'values': [0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2, 0.2]},
# {'id': 'D',
# 'score': 0.0800001323,
# 'values': [0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4, 0.4]}],
# 'namespace': ''}Values 中就是找回来的向量(在我们这个例子中可以被认为是对应的 Emoji)。这意味着我们可以通过向量化所有的查询条件,找到最 “接近” 我们要求的东西。如果把 Emoji 替换成文本的话,我们就可以实现 “语义” 搜索。如果把 Emoji 替换成图片或者视频的话,就可以实现图片或者视频相似性推荐。
为什么Al应用常常需要依赖于向量数据库?
通过一句话来解释的话就是:“大模型” 能记住的事情有限。
这非常类似于我们的大脑。在交流的过程中,我们不可能把自己所有的知识都在对话中交给对方,通常我们只能通过有限的上下文来做一定的 “推理”。那么在现在的 AI 应用中,推理能力是由 LLM 提供的,而从你的大脑中把需要表达的最相关的上下文找出来。所以类比来看,向量数据库类似于 LLM 的记忆或者知识库。所以完成一个 AI 相关的功能,如果没有向量数据库的帮助,通常 AI 大模型能完成的功能以及准确度就很有限。
沿着这个思路往下看,除了一些不那么精确的模糊匹配以外,其实在现实生活中也存在很多需要非常精确和确定性的搜索/索引。这个就类似于我们通常会把一些重要信息记录在笔记本里面,需要的时候再通过索引把它精确找回来。
所以向量数据库和关系型数据库最大的不同是对于数据的存储方式和索引查询方式。而正是由于关系型数据库当中存在的精确索引,所以它能在毫秒级别获取到对应的信息。对应于业务系统中需要高速访问的例如账号、商品和订单信息等等,目前依然是需要由它来完成。
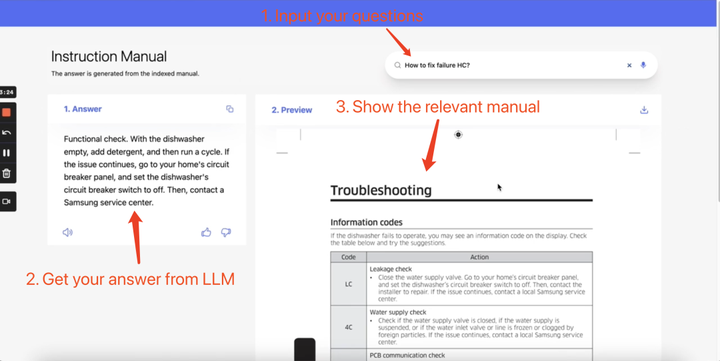
下面以这次 Hackathon 获奖的应用 Heuristic AI ( https://devpost.com/software/cx-8lh7ps ) 作为例子给大家展示一下,在一个真实的项目中,分别是怎么使用这两种类型的数据库的。
日常生活中,当我们使用的电子产品出现故障的时候,通常需要翻阅复杂的使用手册才能获取到相关的解决方案,并且需要花费大量的时间学习。这个项目完成了以下事情:
- 把所有产品手册导入到向量数据库里面
- 把遇到的问题用自然语言描述,通过语义搜索,在向量数据库中找到最相关的上下文
- 把上下文打包成 Prompt 发送给 OpenAI,生成对应的解决方案
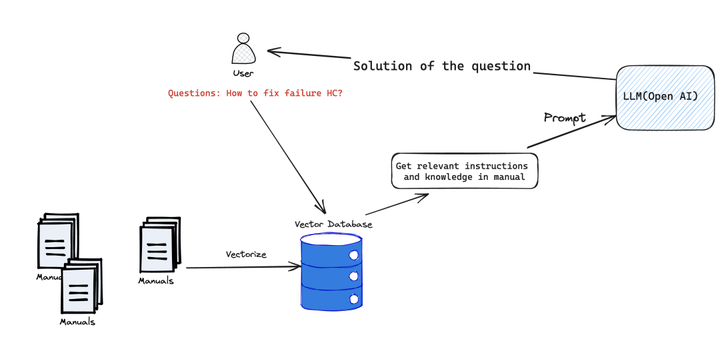
大致的技术实现如下:
如果这个软件到此为止了,那基本上也就是一个玩具。通常还需要为系统加入用户认证与管理系统,另外通常在后台还需要加上对业务数据的分析系统,比如多少在线用户使用了产品,使用频率如何等等维度。而这些功能,就需要使用传统的数据库来实现了:
当然作为一个 Hackathon 项目,这个软件其实已经相对比较完整了。但是如果它要进一步产品化,需要考虑以下的方面:
○ 用户数据量暴增,系统的可扩展性和稳定性
○ 多数据中心和灾难情况下的数据备份和恢复
这些都不酷,甚至有些痛苦,但是这依然是我们需要慎重且认真对待的领域。好在从这次 Hackathon 中,可以肉眼观察到的另一个趋势:Serverless ,在帮助开发者们不断减轻产品化一个应用的技术难度。
基础软件 Serverless 化带来的效率提升
可以观察到的:独立开发者在项目开发中发挥的作用日益突出。独立开发者在项目开发中发挥的作用日益突出。相较于过去,不再需要庞大的 3-4 人团队合作,现在的优秀项目往往由 1-2 名开发者,甚至是个别人单独完成。
这一趋势的背后,Serverless 化的浪潮充当了重要的推动力。借助 Serverless,开发者能够专注于业务逻辑,而不必纠结于底层基础设施的细节。这次没有再看到有开发者会利用本地部署实现自己的应用了,前端和业务代码部署使用 Vercel,后端组件,比如 Vector 数据库用 Qrdrant ( https://qdrant.tech/ ),或者 Pinecone ( https://www.pinecone.io/ ),关系型数据库使用 TiDB Cloud Serverless ( https://bit.ly/3PsYJle ),用上这一套,基本上一个工程师就能完成 Demo 级别的应用了。
这个时代下也并非只有 AI 领域一枝独秀,其他的传统技术,其实也在为开发者们提供越来越方便的使用体验,也在随着浪潮不断递进迭代。
只要关注回到开发者本身,大家都有光明的未来。