1.Numpy
1.1 介绍
NumPy是Python中非常流行且重要的科学计算库,提供了一个强大的多维数组对象(ndarray)和许多数学操作,包括矩阵运算、线性代数、微积分等等。
numpy是Python中一个非常有用的工具,特别是在需要进行数值计算、线性代数计算、数据分析和机器学习等领域。
其他资料:
-
GitHub截止当前: 24.4k https://github.com/numpy/numpy
-
中文文档: https://www.numpy.org.cn/
1.2 主要功能
以下是NumPy的主要功能:
-
多维数组 ( ndarray):NumPy的核心功能是多维数组对象ndarray,它是一个固定大小的数组,在内存中连续存储数据。ndarray可以保存任何类型的数据, 但通常用于存储数值类型的数据。ndarray的维度可以从一维到多维,可以进行基本的数值操作 (加法、减法、乘法、除法等) 以及矩阵运算 (矩阵乘法、矩阵转置等)。 -
数组操作: NumPy提供了一系列用于数组操作的函数和方法。可以对数组进行形状调整 (reshape) 、切片(slicing) 、索引 (indexing) 和切割 (splitting) 等操作。 这些操作高效地对数组进行重排、选取和修改。 -
数学函数: NumPy提供了大量的数学函数,如三角函数、指数函数、对数函数等。这些函数可以直接应用于数组,并进行元素级的操作。此外,NumPy还提供了统计学函数 (均值、方差、相关性等)、线性代数函数 (矩阵求逆、特征值分解等) 等。 -
文件I/0: NumPy提供了用于读写数组数据的函数。可以将数组数据保存至文件 (如CSV、HDF5等格式) 或从文件中加载数据。这对于在机器学习中保存和加载数据集非常有用。 -
广播 ( Broadcasting) : 广播是NumPy中的强大功能之一。它允许在不同形状的数组间进行数值运算,而无需进行显式的形状匹配或复制数据。通过广播, 可以对形状不同的数组进行运算,使得代码更加简洁和高效。 -
并行计算: NumPy支持并行计算和向量化操作。通过使用NumPy的通用函数 (ufunc) ,可以在数组上进行并行计算,提高计算效率。此外,NumPy还与其他库 (如SciPy) 和工具(如Numba) 集成,可进一步提升计算性能。
1.3 安装
通过
Anaconda安装的Python环境,默认会安装Numpy
# 查看当前环境是否安装
(py3.11) ➜ python-learn pip list | grep num
numexpr 2.8.4
numpy 1.25.2
# 不存在则通过下面命令安装
(py3.11) ➜ pip install numpy
2. 创建数组
2.1 序列转数组
numpy.array函数可以将Python列表或元组转换为NumPy数组。例如:
import numpy as np
if __name__ == '__main__':
# 使用numpy.array创建多维数组
print("------------创建一维数组--------------------")
list_one = np.array([1, 2, 3])
tuple_one = np.array((1, 2, 3))
print("列表转一维:{} \n元组转一维:{}".format(list_one, tuple_one))
print("------------创建二维数组--------------------")
list_two = np.array([
[1, 2, 3],
[4, 5, 6],
[7, 8, 9],
])
tuple_two = np.array((
(1, 2, 3),
(4, 5, 6),
(7, 8, 9),
))
print("列表转二维:\n {} \n元组转二维:{}".format(list_two, tuple_two))
print("------------创建三维数组--------------------")
list_three = np.array([
[
[1, 2, 3],
],
[
[4, 5, 6],
],
[
[7, 8, 9]
]
])
print("列表转三维:{} ".format(list_three))
# ********************** 输出 **********************
------------创建一维数组--------------------
列表转一维:[1 2 3]
元组转一维:[1 2 3]
------------创建二维数组--------------------
列表转二维:
[[1 2 3]
[4 5 6]
[7 8 9]]
元组转二维:[[1 2 3]
[4 5 6]
[7 8 9]]
------------创建三维数组--------------------
列表转三维:[[[1 2 3]]
[[4 5 6]]
[[7 8 9]]]
2.2 一维数组
在numpy库中,我们可以通过numpy.arange和numpy.linspace来创建一维数组,它们的主要区别在于参数的定义方式和生成数组的规则。
1. numpy.arange
numpy.arange([start, ]stop, [step, ]dtype=None)
-
start:起始值(包含在数组中)。 -
stop:终止值(不包含在数组中)。 -
step:步长,可选参数,默认为1。 -
dtype:可选参数,指定数组的数据类型。
使用示例:
import numpy as np
if __name__ == '__main__':
print("np.arange(10):", np.arange(10))
print("np.arange(5, 10):", np.arange(5, 10))
print("np.arange(0, 10, 3):", np.arange(0, 10, 3))
# -------------------------- 输出 --------------------------
np.arange(10): [0 1 2 3 4 5 6 7 8 9]
np.arange(5, 10): [5 6 7 8 9]
np.arange(0, 10, 3): [0 3 6 9]
2. numpy.linspace
linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
-
start:起始值(包含)。 -
stop:终止值(默认包含,可根据参数endpoint调整)。 -
num:可选参数,默认为50,指定数组的长度(元素个数)。 -
endpoint:可选参数,默认为True,如果为True,终止值(stop)将包含在数组中;如果为False,终止值不包含在数组中。 -
retstep:可选参数,默认为False,如果为True,将会返回数组的取值间隔。 -
dtype:可选参数,指定数组的数据类型。
使用示例:
import numpy as np
if __name__ == '__main__':
print("在 [0,10]之间取5个元素:", np.linspace(0, 10, 5))
print("在 [0,10]之间取5个元素,并返回取值间隔:", np.linspace(0, 10, 5, retstep=True))
print("在 [0,10)之间取5个元素,不包含10:", np.linspace(0, 10, 5, endpoint=False))
# --------------------- 输出 ---------------------
在 [0,10]之间取5个元素: [ 0. 2.5 5. 7.5 10. ]
在 [0,10]之间取5个元素,不包含10: [0. 2. 4. 6. 8.]
在 [0,10]之间取5个元素,并返回取值间隔: (array([ 0. , 2.5, 5. , 7.5, 10. ]), 2.5)
@使用说明: 至于到底选择使用哪个函数,取决于您希望如何生成一维数组。
依据 步长生成,用 numpy.arange;依据 元素个数生成,用 numpy.linspace。
2.3 特别数组
-
numpy.zeros: 该函数可以创建指定形状的数组,并将所有元素初始化为0。 -
numpy.ones: 该函数可以创建指定形状的数组,并将所有元素初始化为1。
import numpy as np
if __name__ == '__main__':
print("---------------------------- 全是0 ------------------------------------")
print("一维数组-> np.zeros(6):", np.zeros(6))
print("二维数组(2,3)-> np.zeros((2,3)):", np.zeros((2, 3)))
print("三维数组(2,3,3)-> np.zeros((2,2,3)):", np.zeros((2, 2, 3)))
print("---------------------------- 全是1 ------------------------------------")
print("一维数组-> np.ones(6):", np.ones(6))
print("二维数组(2,3)-> np.ones((2,3)):", np.ones((2, 3)))
print("三维数组(2,3,3)-> np.ones((2,2,3)):", np.ones((2, 2, 3)))
# ********************************* 输出 *********************************
---------------------------- 全是0 ------------------------------------
一维数组-> np.zeros(6): [0. 0. 0. 0. 0. 0.]
二维数组(2,3)-> np.zeros((2,3)): [[0. 0. 0.]
[0. 0. 0.]]
三维数组(2,3,3)-> np.zeros((2,2,3)): [[[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]]]
---------------------------- 全是1 ------------------------------------
一维数组-> np.ones(6): [1. 1. 1. 1. 1. 1.]
二维数组(2,3)-> np.ones((2,3)): [[1. 1. 1.]
[1. 1. 1.]]
三维数组(2,3,3)-> np.ones((2,2,3)): [[[1. 1. 1.]
[1. 1. 1.]]
[[1. 1. 1.]
[1. 1. 1.]]]
2.4 空数组
NumPy中的empty函数是用于创建一个指定形状和数据类型的空数组。它会分配内存空间来存储数组元素,但不会对这些元素进行初始化。因此,创建的数组将包含未初始化的随机值或者之前内存中遗留的值。
numpy.empty(shape, dtype=float, order='C')
1.参数说明:
-
shape:表示所需的数组形状,可以是一个整数或者一个整数元组。 -
dtype(可选):表示所需的数组元素的数据类型,默认为float。 -
order(可选):表示数组在内存中的存储顺序,可以是'C'(按行存储)或'F'(按列存储),默认为'C'。
2.使用示例:
import numpy as np
if __name__ == '__main__':
print("二维数组:\n", np.empty((2, 3)))
print("三维数组:\n", np.empty((2, 2, 2)))
# --------------------- 输出 ---------------------
/Users/liuqh/opt/anaconda3/envs/py3.11/bin/python /Users/liuqh/ProjectItem/PythonItem/python-learn/main.py
二维数组:
[[0. 0.15 0.25]
[0.5 0.75 1. ]]
三维数组:
[[[0. 0.03 ]
[0.215 0.4 ]]
[[0.586 0.77 ]
[0.954 1. ]]]
2.5 随机数组
NumPy有一个random子模块,可以用来创建随机数组,该模块下有三个常用的函数:
-
np.random.random:用于生成[0,1)区间内的随机浮点型数组;def random(size=None):
# size: 用于指定数组元素个数 -
np.random.randint:用于生成[low, high)区间内的随机整型数组。def randint(low, high=None, size=None, dtype=None)
# low: 区间最小值(包含)
# high: 区间最大值(不包含)
# size:是一个元组,用于指定数组形状
# dtype: 用于指定数组类型 -
np.random.random:用于生成以loc为均值、以scale为标准差的正态分布数组;def normal(loc=0.0, scale=1.0, size=None)
# loc:均值
# size:是一个元组,用于指定数组形状
代码示例:
import numpy as np
if __name__ == '__main__':
print("------------- np.random.random 演示 -------------")
random_var = np.random.random(4)
print("random_var:", random_var)
print("random_var.shape:", random_var.shape)
print("------------- np.random.randint 演示 -------------")
rand_int = np.random.randint(1, 10, size=(2, 3))
print("rand_int:", rand_int)
print("rand_int.shape:", rand_int.shape)
print("------------- np.random.randint 演示 -------------")
rand_normal = np.random.normal(size=(3, 3))
print("rand_normal:", rand_normal)
print("rand_normal.shape:", rand_normal.shape)
# ******************** 输出 *******************
------------- np.random.random 演示 -------------
random_var: [0.61308029 0.45486095 0.69006646 0.38384838]
random_var.shape: (4,)
------------- np.random.randint 演示 -------------
rand_int: [[9 4 9]
[7 4 3]]
rand_int.shape: (2, 3)
------------- np.random.randint 演示 -------------
rand_normal: [[ 1.93567259 1.21137246 0.128895 ]
[-2.28372489 0.63390644 0.48948102]
[ 0.34386644 0.3941035 0.60806804]]
rand_normal.shape: (3, 3)
3. 数组属性
3.1 常用属性
| 属性 | 说明 |
|---|---|
shape | 数组的形状 |
ndim | 数组的维度 |
dtype | 数组元素的数据类型 |
size | 数组元素的总数 |
3.2 元素类型
if __name__ == '__main__':
# 所有数据类型
print("所有数据类型:", np.sctypeDict.values())
# 定义数组,dtype=np.int32
arr = np.arange(0, 8, dtype=np.int32)
print("打印数组:", arr)
print("数组类型.dtype:", arr.dtype)
# 类型转换
new_arr = arr.astype(np.int64)
print("类型转换后.dtype:", new_arr.dtype)
# ----------------------输出---------------------
所有数据类型: dict_values([...]) # 类型太多,此处省略
打印数组: [0 1 2 3 4 5 6 7]
数组类型.dtype: int32
类型转换后.dtype: int64
@注意:
NumPy的数值对象的运算速度比Python的内置类型的运算速度慢很多,如果程序中需要大量地对单个数值运算,应尽量使用Python的内置类型
3.3 使用示例
import numpy as np
if __name__ == '__main__':
print("----------------------------------------------------------")
# 定义一维数组
one_arr = np.arange(4, dtype=np.int32)
print("一维数组:\n", one_arr)
# 定义二维数组
two_arr = np.arange(6, dtype=float).reshape(2, 3)
print("二维数组:\n", two_arr)
# 定义多维数组
three_arr = np.arange(0, 12, dtype=int).reshape((2, 2, 3))
print("三维数组:\n", three_arr)
print("---------------------- 数组的维度 --------------------------")
print("one_arr.ndim:", one_arr.ndim)
print("two_arr.ndim:", two_arr.ndim)
print("three_arr.ndim:", three_arr.ndim)
print("---------------------- 数组的形状 --------------------------")
print("one_arr.shape:", one_arr.shape)
print("two_arr.shape:", two_arr.shape)
print("three_arr.shape:", three_arr.shape)
print("---------------------- 数组元素的总数 -----------------------")
print("one_arr.size:", one_arr.size)
print("two_arr.size:", two_arr.size)
print("three_arr.size:", three_arr.size)
print("---------------------- 数组元素类型 -------------------------")
print("one_arr.dtype:", one_arr.dtype)
print("two_arr.dtype:", two_arr.dtype)
print("three_arr.dtype:", three_arr.dtype)
# **************************** 输出 *****************************
----------------------------------------------------------
一维数组:
[0 1 2 3]
二维数组:
[[0. 1. 2.]
[3. 4. 5.]]
三维数组:
[[[ 0 1 2]
[ 3 4 5]]
[[ 6 7 8]
[ 9 10 11]]]
---------------------- 数组的维度 --------------------------
one_arr.ndim: 1
two_arr.ndim: 2
three_arr.ndim: 3
---------------------- 数组的形状 --------------------------
one_arr.shape: (4,)
two_arr.shape: (2, 3)
three_arr.shape: (2, 2, 3)
---------------------- 数组元素的总数 -----------------------
one_arr.size: 4
two_arr.size: 6
three_arr.size: 12
---------------------- 数组元素类型 --------------------------
one_arr.dtype: int32
two_arr.dtype: float64
three_arr.dtype: int64
4. 数组访问
4.1 维度理解
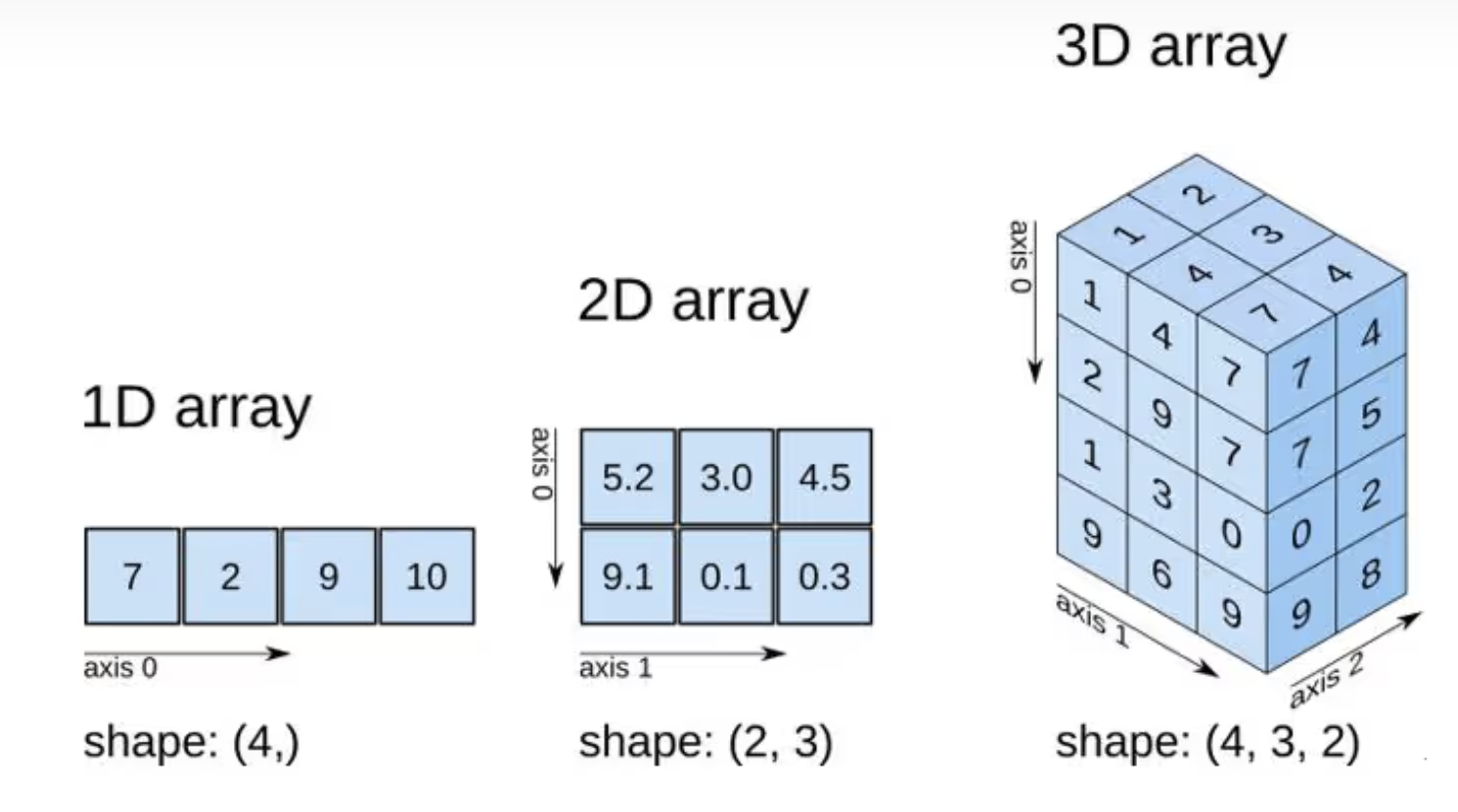
当维度大于1时,axis=x含义如下:
-
axis=0: 代表对横轴操作,即第几行 -
axis=1: 代表对纵轴操作,即第几列 -
axis=2: 代表对层级操作,即第几层
@注:上述说明也许过于浅显,要是更好的多维理解文章,求推荐。
4.2 访问语法
一维数组的访问方式和列表一样,这里不在叙述;这里主要学习二维和三维数组的访问方式,访问语法如下:
# 当访问二维数组时
arr[x,y] 或 arr[x][y]
# 当访问三维数组时
arr[c,x,y] 或 arr[c][x][y]
-
x: 指第几行,从0开始,如:arr[0]代表访问第一行, -
y: 指第几列,从0开始,如:arr[0,0]代表访问第一行第一列 -
c: 指第几层,从0开始,如:arr[0,0,0]代表访问第一层第一行第一列
代码示例:
import numpy as np
if __name__ == '__main__':
arr = np.arange(6).reshape((2, 3))
print("----------------------- 二维数组访问 -----------------------")
print("二维数组:\n", arr)
print("第2行第3列:", arr[1, 2])
print("@第2行第3列:", arr[1][2])
three_arr = np.arange(12).reshape((2, 3, 2))
print("----------------------- 三维数组访问 -----------------------")
print("三维数组:\n", three_arr)
print("第1层第2行第2列:", three_arr[0, 1, 1])
print("@第1层第2行第2列:", three_arr[0][1][1])
print("第2层第3行第1列:", three_arr[1, 2, 0])
print("@第2层第3行第1列:", three_arr[1][2][0])
# *********************** 输出 ***********************
----------------------- 二维数组访问 -----------------------
二维数组:
[[0 1 2]
[3 4 5]]
第2行第3列: 5
@第2行第3列: 5
----------------------- 三维数组访问 -----------------------
三维数组:
[[[ 0 1]
[ 2 3]
[ 4 5]]
[[ 6 7]
[ 8 9]
[10 11]]]
第1层第2行第2列: 3
@第1层第2行第2列: 3
第2层第3行第1列: 10
@第2层第3行第1列: 10
@注: A[x,y]和A[x][y]两者是有区别的。A[x,y]只进行一次计算,直接获取数组中行为x、列为y的元素;而A[x][y]进行了两次计算:首先获取A[x]对应的数据集合(是第x行的数据集合),然后在获取的新数据集合中获取第y个元素。建议使用A[x,y]这种方式获取数组元素
4.3 切片索引
访问数组时,切片索引下标说明:
arr[x:y:z]
-
x: 指从哪儿开始,包括当前元素,默认0; -
y: 指到哪儿结束, 不包括当前元素,默认到最后; -
z: 指间隔多少取一次元素,默认1;
使用切片索引时,一定要注意索引中的逗号(
,)
这里以**三维数组:arr[层,行,列]**为例,列举几个访问方式:
-
arr[0]: 访问三维数组中的第一层; -
arr[0,:,0]: 这里 行被写成**:**,指访问第1层所有行中的第1列; -
arr[0,0,:]: 这里 列被写成**:**,指访问第1层第1行中的所有列; -
arr[0,0,0]: 指访问第1层第1行第1列对应的元素; -
arr[1,0,0:2]: 指访问第2层第1行,第1、2列的元素,0:2中的0可以省略即:arr[1,0,:2] -
arr[1, 0, ::2]: 指在第2层第1行所有元素中,每间隔2个元素取一次
import numpy as np
if __name__ == '__main__':
arr = np.arange(18).reshape((2, 3, 3))
print("三维数组:\n", arr)
print("第1层:\n", arr[0])
print("第1层所有行中的第1列:", arr[0, :, 0])
print("第1层第1行中的所有列:", arr[0, 0, :])
print("第1层第1行第1列元素:", arr[0, 0, 0])
print("第2层第1行第1、2列元素:", arr[1, 0, :2])
print("在第2层第1行所有元素中,每间隔2个元素取一次:", arr[1, 0, ::2])
# *************** 输出 ****************
三维数组:
[[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]]
[[ 9 10 11]
[12 13 14]
[15 16 17]]]
第1层:
[[0 1 2]
[3 4 5]
[6 7 8]]
第1层所有行中的第1列: [0 3 6]
第1层第1行中的所有列: [0 1 2]
第1层第1行第1列元素: 0
第2层第1行第1、2列元素: [ 9 10]
在第2层第1行所有元素中,每间隔2个元素取一次: [ 9 11]
@注意:使用切片得到的数组,底层依旧指向原来的数组,修改切片元素,也会影响到原始数组(引用变量), 如下示例:
import numpy as np
if __name__ == '__main__':
arr = np.arange(5)
print("arr:", arr)
# 通过切片得到新数组
slice_arr = arr[2:4]
print("slice_arr:", slice_arr)
# 修改切片数组
slice_arr[0] = 100
print("修改切片数组后 slice_arr:", slice_arr)
print("修改切片数组后 arr:", arr)
# ---------------------- 输出 ----------------------
arr: [0 1 2 3 4]
slice_arr: [2 3]
修改切片数组后 slice_arr: [100 3]
修改切片数组后 arr: [ 0 1 100 3 4]
4.4 布尔索引
在NumPy中,布尔索引是一种非常强大和灵活的索引方式,它允许我们根据指定的条件来获取数组中满足该条件的元素,并且返回一个与原始数组形状相同的布尔数组,其中对应位置上的元素是True或False。
1.常用表达式:
| 表达式 | 说明 |
|---|---|
== | 相等;如:arr == 3 |
!= | 不等;如:arr != 3 |
>和< | 大于和小于; 如: arr > 3 |
& | 并且(and),都为真则为True |
| ` | ` |
~ | 逻辑非,即相反的条件 |
2.使用示例:
if __name__ == '__main__':
print("-------------------- 根据条件输出匹配结果 --------------------")
arr = np.array(["Python", "Go", "C", "PHP", "Java"])
# 匹配等于条件
print("等于'Go'的元素变成True:\n{}\n{}".format(arr, arr == "Go"))
# 匹配相反(~)条件
opposite_conda = ~(arr == "Go")
print("不等于'Go'的元素变成True:\n{}\n{}".format(arr, opposite_conda))
# 匹配大于条件: 大于2的元素
num_arr = np.arange(6)
print("大于2的元素变成True:\n{}\n{}".format(num_arr, num_arr > 2))
# 匹配&(and)条件: 大于2且被2整除
cond = (num_arr > 2) & (num_arr % 2 == 0)
print("大于2且被2整除的元素变成True:\n{}\n{}".format(num_arr, cond))
# 匹配|(or)条件: 大于4或被2整除
or_cond = (num_arr > 4) | (num_arr % 2 == 0)
print("大于4或被2整除的元素变成True:\n{}\n{}".format(num_arr, or_cond))
# ******************************* 输出 **************************
-------------------- 根据条件输出匹配结果 --------------------
等于'Go'的元素变成True:
['Python' 'Go' 'C' 'PHP' 'Java']
[False True False False False]
不等于'Go'的元素变成True:
['Python' 'Go' 'C' 'PHP' 'Java']
[ True False True True True]
大于2的元素变成True:
[0 1 2 3 4 5]
[False False False True True True]
大于2且被2整除的元素变成True:
[0 1 2 3 4 5]
[False False False False True False]
大于4或被2整除的元素变成True:
[0 1 2 3 4 5]
[ True False True False True True]
4.5 数组索引
在Numpy中除了使用整数索引、切片索引还可以使用数组索引,数组索引一般分为:一维数组和多维数组:
-
arr[[1,3,5]]: 当索引是一维数组时,代表访问数组arr索引( 或行)为1、3、5的元素; -
arr[ [0,1], [1,2] ]: 当索引是多维数组时,代表访问数组arr,(0,1)、(1,2)对应的元素;
import numpy as np
if __name__ == '__main__':
print("---------------- 一维索引数组演示 ----------------")
one_arr = np.arange(1, 12, 2)
print("一维数组:\n", one_arr)
# 代表访问 one_arr[1]、one_arr[3]、one_arr[5] 对应的元素
print("当索引是一维数组时(访问一维):", one_arr[[1, 3, 5]])
tmp_arr = np.arange(12).reshape(4, 3)
print("二维数组:\n", tmp_arr)
# 代表访问 tmp_arr[1]、tmp_arr[3] 对应的行
print("当索引是一维数组时(访问二维): \n", tmp_arr[[1, 3]])
print("---------------- 多维索引数组演示 ----------------")
arr = np.arange(6).reshape(2, 3)
print("二维数组:\n", arr)
# [0,1]: 第1行第2列元素
# [1,2]: 第2行第3列元素
a = arr[[0, 1], [1, 2]]
print("当索引是二维数组时:", a)
# ******************** 输出 ********************
---------------- 一维索引数组演示 ----------------
一维数组:
[ 1 3 5 7 9 11]
当索引是一维数组时(访问一维): [ 3 7 11]
二维数组:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
当索引是一维数组时(访问二维):
[[ 3 4 5]
[ 9 10 11]]
---------------- 多维索引数组演示 ----------------
二维数组:
[[0 1 2]
[3 4 5]]
当索引是二维数组时: [1 5]
5.数组赋值
5.1 普通索引赋值
import numpy as np
if __name__ == '__main__':
arr = np.arange(6).reshape(2, 3)
print("原始数组:\n", arr)
# 使用普通索引赋值
oldVal = arr[1, 2]
newVal = oldVal * oldVal
arr[1, 2] = newVal
print("把arr[1,2]对应元素:{},改成:{}".format(oldVal, newVal))
print("修改后的数组:\n", arr)
# ******************** 输出 ********************
原始数组:
[[0 1 2]
[3 4 5]]
把arr[1,2]对应元素:5,改成:25
修改后的数组:
[[ 0 1 2]
[ 3 4 25]]
5.2 切片索引赋值
import numpy as np
if __name__ == '__main__':
arr = np.arange(12).reshape(4, 3)
print("原始数组:\n", arr)
# 修改整行中所有的元素
arr[0, :] = 99
print("修改数组第1行所有元素后:\n", arr)
# 修改所有行中第2列元素
arr[:, 1] = 88
print("修改所有行中第2列元素后:\n", arr)
# ******************** 输出 ********************
原始数组:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
修改数组第1行所有元素后:
[[99 99 99]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
修改所有行中第2列元素后:
[[99 88 99]
[ 3 88 5]
[ 6 88 8]
[ 9 88 11]]
5.3 布尔索引赋值
import numpy as np
if __name__ == '__main__':
arr = np.arange(6)
print("原始数组:", arr)
index = (arr % 2 == 0)
print("布尔索引:", index)
# 被2整除的元素,都乘以2
arr[index] *= 2
print("被2整除的元素,都乘以2:", arr)
# 大于3的元素,都设置成0
arr[arr > 3] = 0
print("大于3的元素,都设成0: ", arr)
# ******************** 输出 ********************
原始数组: [0 1 2 3 4 5]
布尔索引: [ True False True False True False]
被2整除的元素,都乘以2: [0 1 4 3 8 5]
大于3的元素,都设成0: [0 1 0 3 0 0]
本文由 mdnice 多平台发布








![[JAVAee]Spring项目的创建与基本使用](https://img-blog.csdnimg.cn/034286397b35431294a9a6943f892915.png)