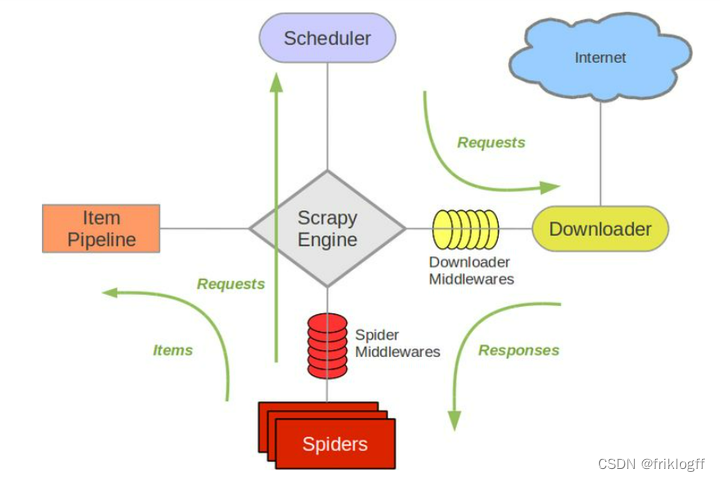
贝叶斯原理是一种基于概率的分析方法,可以用来估计一个事件发生的概率。在人类认知和机器学习领域中,都有对应的贝叶斯原理。
人类认知的贝叶斯原理:
在人类认知研究中,贝叶斯原理被认为是一种重要的思维方式。人类的认知过程通常涉及到对不确定性和信息缺失的处理,而贝叶斯原理提供了一种理论框架,可以帮助我们处理这样的问题。具体来说,人类使用已知的先验知识和新获得的证据来更新自己对事物的信念和推断。换言之,人类利用贝叶斯原理将先验知识与新证据进行结合,从而形成更加准确的观点和假设。
在某些情况下,人类智能可能存在一些违反贝叶斯原理的成分。以下是其中几个例子:
忽视先验知识:贝叶斯原理强调利用先验知识来更新信念和推断,但有时人类可能会忽视先验知识,而仅仅依赖于新获得的证据。这可能导致对信息过度依赖,忽略了已有的知识和经验。
选择性偏见:人类对信息的处理通常受到选择性偏见的影响,即更倾向于接受符合自身观点或期望的证据,而忽略或低估与之相悖的证据。这可能导致个人的推断不符合贝叶斯原理中先验和后验概率的更新关系。
概率判断错误:人类对概率的判断往往受到认知偏差的影响,如过度乐观或过度悲观,容易产生主观估计误差。这可能导致人们在推断和决策中违背贝叶斯原理中基于概率的计算方法。
虽然人类智能可能在某些情况下违反贝叶斯原理,但这并不意味着贝叶斯原理是错误的或无效的。相反,贝叶斯原理提供了一种理论框架和方法,可以帮助我们更好地理解和处理不确定性问题。通过认识到这些偏差和局限性,我们可以尝试纠正和改善我们的决策和推断过程,更好地利用贝叶斯原理的优势。
机器的贝叶斯原理:
在机器学习中,贝叶斯原理也得到广泛应用。机器学习通常需要在训练阶段根据已有数据进行参数估计,然后利用这些参数进行预测和推断。贝叶斯方法提供了一种基于概率的框架,可以在统计学习中进行参数估计和模型选择。它可以将先验知识与新数据进行结合,从而提高模型的预测能力和准确性。
概括而言,贝叶斯原理是一种基于概率的分析方法,在人类认知和机器学习领域中都有重要应用。它通过先验知识和新证据的结合来推断和预测,可以帮助我们在不确定性和信息缺失的情况下做出更加准确和可靠的推断和决策。
正则贝叶斯(Regularized Bayesian)是一种结合了贝叶斯方法和正则化技术的统计学习方法。它旨在通过引入正则化项来控制模型的复杂度,并在贝叶斯推断中进行参数估计。
传统的贝叶斯方法将先验分布与观测数据结合,通过贝叶斯公式推导出后验分布。然而,在实际应用中,当观测数据较少或噪声较大时,贝叶斯方法可能会过度拟合训练数据,导致泛化性能下降。正则贝叶斯通过引入正则化项,如L1正则化或L2正则化,来限制模型的复杂度。这些正则化项在似然函数中加入对参数的惩罚,从而在参数估计中平衡了先验知识和数据拟合程度。正则化项的选择和参数的正则化强度可以通过交叉验证等技术来确定。正则贝叶斯方法在许多机器学习任务中都有广泛的应用。例如,在分类问题中,正则贝叶斯可以通过合适的正则化项来提高模型的泛化能力,并且在特征选择中有一定作用。在回归问题中,正则贝叶斯可以通过控制模型的复杂度来避免过拟合,并提高预测的准确性。总的来说,正则贝叶斯是一种结合了贝叶斯方法和正则化技术的统计学习方法。它通过引入正则化项来限制模型的复杂度,在贝叶斯推断中进行参数估计,以提高模型的泛化能力和预测准确性。
人类认知的正则贝叶斯方法可以通过以下实例进行说明:
假设你是一位想要购买一款新手机的消费者。在做决策之前,你收集了一些信息,如不同品牌的手机性能、价格和用户评价等。在这个过程中,你的大脑会使用正则贝叶斯方法来进行推断和决策。首先,你可能拥有一些先验知识,如某个品牌的手机在过去的经验中表现良好。这些先验知识可以看作是先验概率分布。然后,你会根据收集到的新证据(如其他消费者的评价)来更新你对各个品牌手机性能的估计,并得出后验概率分布。正则贝叶斯方法在这里的应用是通过引入正则化项来平衡先验知识和新证据的影响。例如,如果你对某个品牌的手机有较高的先验概率估计,但新证据显示该品牌的性能并不理想,正则化项可以通过惩罚该品牌的估计值,使其不过分依赖先验概率。此外,正则贝叶斯方法还可以帮助你在决策时考虑模型的复杂度。例如,如果在你的选择中有多个品牌的手机都有类似的性能表现,你可以使用正则化项来选择一个更简单的模型,从而避免过度拟合和决策的复杂化。综上所述,人类认知的正则贝叶斯方法在购买手机这样的决策过程中可以帮助我们结合先验知识和新证据,并通过引入正则化项来平衡它们的影响,从而做出更合理和有效的决策。注意,这个例子是用来说明概念,实际认知过程可能涉及更复杂的因素和推断方式。
人机混合的正则贝叶斯方法是一种结合了人类专家知识和机器学习算法的方法,以提高模型的准确性和稳定性。下面是一个简单的例子来说明这种方法的应用:
假设我们要开发一个用于垃圾邮件过滤的分类器,要求能够准确地将垃圾邮件和非垃圾邮件进行分类。
首先,我们可以使用机器学习算法(如朴素贝叶斯分类器)来构建一个基于训练数据自动学习的分类模型。这个模型可以根据特征(如邮件中的单词或短语)来判断一个邮件是否为垃圾邮件。然而,由于垃圾邮件的特点多种多样,可能存在一些特殊情况或新形式的垃圾邮件,这些邮件可能会被机器学习模型误分类。为了克服这个问题,我们可以引入人类专家知识来修正模型的预测结果。通过建立一个人机互动的界面,当模型对某些邮件的分类结果不确定或存在疑问时,系统可以将这些邮件展示给人类专家进行复核。专家可以根据自己的经验和知识,判断这些邮件是否为垃圾邮件,并将自己的判断结果反馈给系统。系统可以通过记录人类专家的判断结果,形成一个专家数据库。然后,可以将这些人类判断结果用作正则化的先验信息,并与机器学习模型结合。在今后的分类过程中,机器学习模型可以利用这个先验信息进行修正,提高预测的准确性和鲁棒性。通过不断的人机互动,机器学习模型可以逐步优化,并适应新的垃圾邮件形式。人类专家的经验和知识可以帮助模型克服数据偏差或不完备的情况,提供更可靠的分类结果。
总结起来,人机混合的正则贝叶斯方法结合了机器学习算法和人类专家知识,通过人机互动来修正和优化模型的预测结果。这种方法可以在面对复杂、多样且变化快速的问题时,提高模型的效果和稳定性。





![Hive行转列[一行拆分成多行/一列拆分成多列]](https://img-blog.csdnimg.cn/a329dd8afa55418db34b9d1b641bbd22.png)