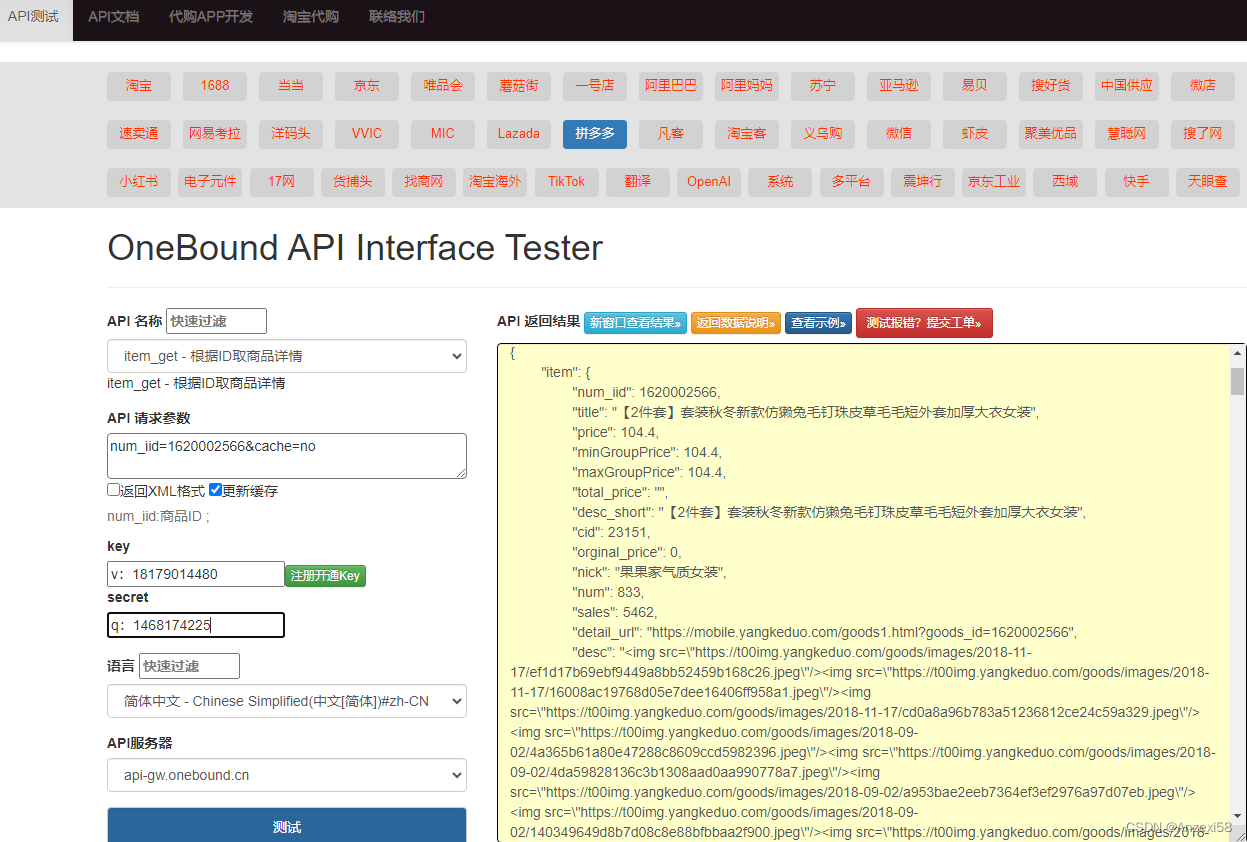
一、相关知识

首先我们需要了解传统隐写和生成式隐写的基本过程和区别。传统隐写需要选定一幅封面图像,然后使用某种隐写算法比如LSB、PVD、DCT等对像素进行修改将秘密嵌入到封面图像中得到含密图像,通过信道传输后再利用算法的逆过程提出秘密信息。而生成式隐写无需选择封面图像,主要使用GAN网络及GAN网络的变体,直接将秘密信息输入到生成器中生成含密图像,通过信道传输再使用提取器提取秘密信息。
可以很明显知道,传统隐写需要封面图像进行修改,很容易被隐写分析器检测到,而生成式隐写无需封面图像,在秘密信息的驱动下生成新的图像,具有较好的抗隐写能力。因此,生成式隐写已成为近年来信息隐藏领域最热门的研究课题之一。

在本文中,将生成式隐写分成两类:一类是单阶段方法,直接隐藏图像生成过程中的秘密信息,目前的单阶段方法主要是构造纹理、指纹等含密图像,比如第一个是2009年的《移动数据通信中的纹理合成》,第二个是构造大理石纹理含密图像,第三个是构造指纹含密图像。其主要缺点是:合成的含密图像内容不自然,视觉效果不够好,且隐藏容量低。
另外一类是两阶段方法,通常首先将给定的秘密信息编码为特征表示比如GAN的标签、潜变量等,然后通过GAN及GAN的变体将特征表示转换为相应的隐写图像。这幅框架图是我们阅读过的2022年的《基于生成对抗网络和梯度下降逼近的鲁棒无覆盖隐写术》,该文中将秘密信息映射成噪声向量,再通过WGAN-GP生成含密图像。目前的生成式隐写存在的问题主要有:信息提取准确率不高,特征域安全性低,性能差,隐藏容量低。本文主要针对前两个问题进行解决。

同时,本文通过了两个定义引出了刚才提出的目前生成式隐写存在的问题。
定义1主要是说明解耦特征和交织特征的定义,将一个数据空间映射到另一个特征空间中,如果变量xi满足这个公式为解耦特征,即该空间中的特征独立于其他空间中的特征变化,否则为交织特征,即指特征不易分离和解耦。该公式简单理解为在变量xj的条件下对变量xi本身概率无影响。
因为目前的大部分生成式隐写都将秘密信息映射成交织特征,在提取秘密信息时,特征不易分离,使秘密信息准确性受到影响。
定义2主要是通过相对熵的概念来判断一个隐写系统是否为保持分布系统。当载体空间和隐写空间的相对熵为0时,表示该隐写系统为保持分布系统。显然,封面图像和隐写图像的分布完全相同,无法被隐写分析器检测,具有较好的安全性。
因为目前的大部分生成式隐写都是以非保持分布的形式将秘密信息映射成交织特征,且交织特征存在较低的安全性。当对隐写图像进行特征域分析,安全性较低。
二、提出方法

本文提出的框架图如图所示,主要包括信息隐藏和信息提取两个阶段。其中信息隐藏阶段是通过CtrGAN将秘密信息编码成轮廓图像,然后通过BicycleGAN进行轮廓-图像变换生成含密图像;信息提取阶段是通过BicycleGAN的逆向过程进行图像-轮廓变换得到轮廓图像,再根据CtrGAN的逆向过程提取秘密信息。

本文提出了一种新的GAN模型,称为轮廓生成对抗网络即CtrGAN,所提出的CtrGAN由轮廓生成器和轮廓判别器组成。因为物体轮廓可以看作是由一系列连续的点组成的曲线,物体轮廓生成过程相当于在二维平面上选取一系列轮廓点。又因为LSTM长短期记忆网络可以根据前t−1时刻的数据计算t时刻数据的概率分布,具有强大的序列数据生成能力,所以CtrGAN的生成器采用的是LSTM。判别器使用简单的基于CNN的二分类网络,其中真实轮廓图像是通过HED算法进行提取,使用判别器对真实轮廓图像和生成轮廓图像进行判断。

算法1是对本文提出的CtrGAN的训练过程,其中对于生成器Gθ的训练主要使用强化学习。在公式3中,MC是一个搜索函数,由蒙特卡洛算法实现。将C1:t−1视为当前轮廓点,在剩下的T-t+1个点中进行N次搜索,并使用公式4计算这N个轮廓点的平均回报值,选择平均回报值最大的轮廓点序列作为生成轮廓点。
对于判别器Dφ的训练是使用Gθ生成的物体轮廓和D中的真实物体轮廓进行对抗性训练,公式7是Dφ的损失函数,使用梯度上升策略进行更新。

下面通过算法2说明秘密信息隐藏阶段中的基于CPS编码。首先通过加密安全伪随机数生成器CSPRNG生成秘密密钥序列对秘密信息M进行异或运算进行加密得到M’,再将M’等分成l位的片段,并将其转化为十进制。
对于第一个轮廓点c1,需要使用公式9进行特殊处理。我们可以通过代值观察,假设v1=6,l=3和w=h=256,则Ind1=7+8Rand(0,8191),其中Rand(x,y)表示在[x,y]范围内随机选择一个整数的函数。
当Rand(0,8191)=8191时,Ind1 = 7 + 8 * 8191 = 65535;当Rand(0,8191)=0时,Ind1=7 + 8 * 0 = 7。此处公式9主要是为了生成轮廓起始位置不过低,然后选择候选池中第Ind1个点作为c1,其中候选池pool1中由w*h个点组成。

对于其余轮廓点,将生成轮廓点c1~ci−1输入到CtrGAN的Gθ,使用公式11输出ci的条件概率分布,构建非零值的候选点池pooli。因为在生成轮廓时不能重复使用同一轮廓点。如果一个候选点已被占用,则设置该候选点的概率为0。再使用公式12将均匀分布vi映射到P(ci|ci,ci,…,ci−1)概率分布,其中RS()是拒绝采样函数,其主要功能是将一个变量从均匀概率分布映射到另一个概率分布。最后使用公式13选择pooli中的第Indi个点作为轮廓点vi。

该图是轮廓生成过程中的基于CPS编码示意图,我们通过一个例子具体理解CPS编码。
假设加密后秘密信息段110101…110…100,且分段长度l=3,则110/101/…/110/…/100,对应十进制为v1=6,v2=5,…,vi=6,…,vn=4。又假设通过公式9,计算v1的Ind1=7+597=600,即选取第600个点作为轮廓点。又假设通过公式12,计算vi的Indi=200,即选取第200个点作为轮廓点。
我们可以得出一个结论:假设总共生成含有n个轮廓点的轮廓线,分段长度为l,则在轮廓线生成过程中的隐藏总量为l*n位。另外感觉这个图有个地方画错了,对于第一个轮廓点v1并没有使用拒绝采样函数进行处理。

秘密信息隐藏的第二个阶段是轮廓-图像变换,主要是通过BicycleGAN完成,它有两部分组成:cVAE-GAN即条件变分自编码器GAN 和cLR-GAN即条件隐回归GAN。其中条件变分自编码器GAN的损失有三部分组成:LKL(E)为生成的潜在编码和高斯分布的KL散度损失、LGANVAE(G,D,E)为cVAE-GAN的对抗损失和LVAE(G,E)为生成图像与真实图像的重建损失L1;条件隐回归GAN的损失有两部分组成:Llatent(G,E)为提取的潜在编码和高斯分布的L1损失和LGAN(G,D)为cLR-GAN的对抗损失。公式14是BicycleGAN的最终损失函数,两个对抗损失无超参数,而其余三个损失对应三个超参数λ、λlatent和λKL,将在实验部分确定其具体值。
BicycleGAN在2017年的论文《走向多模态图像到图像的翻译》被提出,本文只是重新训练和使用。同时生成器和判别器分别采用原文的中设置分别为U-Net和PatchGAN。另外感觉这个图有个地方画错了,对于cVAE-GAN部分,图中只给出两个损失LKL(E)和LVAE(G,E),还应该包括一个对抗损失LGANVAE(G,D,E),在2017年原文画出,但此处并没有标注。

于秘密信息提取阶段,我们首先需要通过BicycleGAN的逆过程从隐写图像中恢复出轮廓图像,再通过算法3从恢复的轮廓图像中进行秘密解码。对于第一个轮廓点v1使用公式15计算,其余轮廓点使用公式16计算。将所有秘密段的十进制值转换为二进制位,并将所有二进制位连接起来,得到秘密比特流M’。最后,用Key对M’进行解密,恢复原来的秘密比特流M。算法3的伪码缺少十进制转二进制的操作。
三、实验结果

本文采用的数据集有三个:(1)T-Zap50K(鞋子图像);(2)从亚马逊下载的产品集(手提包图像);(3)通过谷歌搜索下载的动物集(10,000张动物图像),都是不常见的数据集,同时并将图像处理成256*256大小。
对于前文提及的参数设置分别是BicycleGAN损失函数的三个超参数和秘密段长度l,本文通过消融实验进行说明。首先看超参数λ(LVAE(G,E)为生成图像与真实图像的重建损失L1),从该图的(a)可以看出当λ=10时,信息提取准确率开始稳定不变,从该图的(b)可以看出当λ=8时,生成图像的EMD开始微小波动,为了在信息提取的准确性和生成的隐写图像质量之间取得良好的平衡,设置λ = 10。

接下来,我们继续看λlatent和λKL。从(a)和(b)的纵轴观察可知,λlatent和λKL对信息提取的准确性和生成的隐写图像质量的影响比较小,小于超参数λ,因为这两个超参数都是针对衡量潜在编码和高斯分布之间的差异。同理由图可知,将超参数λlatent和λKL设置为1和0.01,所提方法达到最优。
最后观察秘密段长度l,l表示每个轮廓点选择过程中隐藏的比特数,随着l的增大,信息容量会显著增加,但信息提取的准确性和生成图像的质量会下降。所以本文测试l取2,4,6,8时的条件下各种指标的结果,均表现较好,EAR都在98%以上,EMD都在0.02左右。

我们从有效载荷的角度看一下本文所提方法的隐藏容量,分别计算l去2,4,6,8时的条件下的有效载荷,前面已经说明图像大小为256*256。由计算结果可知,当l=2时,有效载荷为0.0078125bpp;当l=4时,有效载荷为0.03125bpp。将该结果与2022年论文《基于生成对抗网络和梯度下降逼近的鲁棒无覆盖隐写术》对比可知,是比不过红色框的有效载荷结果,原因可能是他们设置的图像大小比较小,大部分为64 * 64,更有16 * 16。

该表将本文方法与传统基于嵌入隐写方法和生成式隐写方法在信息提取精度进行比较。虽然在2*256位条件下,ISN的信息提取精度略高于本文提出的方法,但总体上高于其他方法。因为在基于嵌入的隐写方法中,秘密信息以有损方式编码和嵌入;生成式隐写方法将秘密信息编码为潜在噪声向量或抽象结构向量等交织特征,提取时难以分离。这些对比的方法有很多都是我们阅读过的论文,比如Deep-Stego、HiNet、ISN、IDEAS。

该表表示不同隐藏有效载荷的不同隐写方法对SRM和XuNet隐写分析器的反隐写分析能力,所使用的指标PE,当PE = 0.5时,抗隐写能力性能最佳。本文所提出方法的PE值最接近0.5。这表明在不同的隐藏载荷下,该方法对隐写分析器具有最高的抗检测能力。
同时可以发现,基于嵌入的隐写算法的抗隐写能力低于生成隐写术算法。主要原因是基于嵌入的隐写方法不可避免地留下修改痕迹,这将导致它们很容易被隐写分析器检测到。

该表表示不同方法在特征域上的抗检测性,由表可知在高容量下,这些方法在特征域很容易被隐写分析器检测到,因为目前的生成隐写术直接以非保持分布的方式将秘密信息编码为特征,而我们的方法是以保持分布的方式实现秘密信息。
图像域和特征域抗隐写分析的区别:1)图像域直接对图像进行分析,而特征域将图像映射到另一个空间再分析该空间的特征;2)图像域中隐写算法对分析算法影响大,而特征域对所有隐写算法具有通用性。

该表表示不同隐藏载荷下不同方法生成的隐写图像的FID值。其中FID越小,生成的隐写图像质量越高,与其他生成隐写术方法相比,所提出的方法通常具有较小的FID值。
下图是生成图像的展示,很难直接区分没有信息隐藏的生成图像和有信息隐藏的生成图像,涉及到前面提到的鞋子和手提袋数据集,但没有展示动物数据集。

该表表示在不同类型的图像攻击下比如强度变化、对比度增强、椒盐噪声、高斯噪声、JPEG压缩和图像消毒,不同方法的信息提取精度。从表中可以看出,在这些图像攻击下,该方法的信息提取精度远高于SWE和ISWE。但个人存在一个问题:没有使用常见的图像攻击如右图所示,比如平移、旋转、裁剪等。
四、总结

论文地址:Generative Steganography via Auto-Generation of Semantic Object Contours
中文参考论文地址:基于轮廓自动生成的构造式图像隐写方法