目录
1、问题描述
2、格式化函数内部解析待格式化参数的完整机制说明
2.1、传递给被调用函数的参数是通过栈传递的
2.2、格式化函数是如何从栈上找到待格式化的参数值,并完成格式化的?
2.3、字符串格式化符%s对应的异常问题场景说明
2.4、为了方便理解上述机制,附上VC6.0中的CString类的Format函数的实现源码
2.5、如果要格式化某个C++类对象的数据,且对象中包含多个数据成员,要明确指定要格式化的那个数据成员
3、本案例中的问题分析与排查
3.1、问题代码
3.2、初步分析
3.3、为什么UINT64型数据使用%d格式化符会有问题?
3.4、解决办法
4、最后
VC++常用功能开发汇总(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)
https://blog.csdn.net/chenlycly/article/details/124272585C++软件异常排查从入门到精通系列教程(专栏文章列表,欢迎订阅,持续更新...)![]() https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)
https://blog.csdn.net/chenlycly/article/details/125529931C++软件分析工具从入门到精通案例集锦(专栏文章正在更新中...)![]() https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)
https://blog.csdn.net/chenlycly/article/details/131405795C/C++基础与进阶(专栏文章,持续更新中...)![]() https://blog.csdn.net/chenlycly/category_11931267.html 同事在分析软件的运行日志排查业务问题时,发现某个关键数据的值没有打印出来,于是查看打印日志的代码,但并没有找到问题。同事找到我,希望我去帮忙分析一下,看看是什么原因导致的。经深入分析发现,这个问题和格式化函数内部从栈内存上解析传进来的参数数据时出现了异常,代码中对待格式化的UINT64整型数据错误地使用了%d格式化符引发的。今天我们就来详细讲述一下这个问题的排查过程。
https://blog.csdn.net/chenlycly/category_11931267.html 同事在分析软件的运行日志排查业务问题时,发现某个关键数据的值没有打印出来,于是查看打印日志的代码,但并没有找到问题。同事找到我,希望我去帮忙分析一下,看看是什么原因导致的。经深入分析发现,这个问题和格式化函数内部从栈内存上解析传进来的参数数据时出现了异常,代码中对待格式化的UINT64整型数据错误地使用了%d格式化符引发的。今天我们就来详细讲述一下这个问题的排查过程。
1、问题描述
在源码中找到对应的那句打印日志的代码,如下所示:

现将要打印的信息格式化到一个字符串中,然后将字符串打印出来。上述代码中打印了5个参数(strId.c_str()),这些参数格式化到目标字符串中,查看日志发现第5个参数并没有打印出来。其中,第1个参数(strId.c_str())是字符串首地址,第2个参数(tRtcPlayItem.play_idx()函数的返回值)是UINT64整数值,第3个参数和第4个参数都是bool型,第5个参数(strId.c_str())也是字符串的首地址。第5个参数是字符串的首地址,其指向的内存中是有有效的字符串的。
一般这类数据格式化问题,一般都是待格式化数据和对应的格式化符不匹配导致的,一般会导致两类问题。一是打印出来的数据有异常或者数据打印不出来,二是格式化函数内部从栈上获取参数数据时访问了不该访问的内存,触发内存访问违例,引发崩溃。
大家基本都知道格式化符与待格式化参数类型不匹配时,可能会出问题或者引发软件异常崩溃,但为啥会出问题以及出问题的根本原因,估计没多少人知道!本文就带着大家去详细探究深层次的根本原因,掌握本文的内容,下次大家再遇到格式化问题时,就能自行去分析排查了!
2、格式化函数内部解析待格式化参数的完整机制说明
2.1、传递给被调用函数的参数是通过栈传递的
一般在调用函数时,传递给被调用函数的参数,是压到栈上传递给被调用函数的,即传入参数通过栈传递给被调用函数的。这点查看汇编代码,看的最清楚,比如如下的代码:(调用实现将两个int型数据相加的AddNum函,在函数调用处打断点,命中断点后点击右键,跳转到反汇编,查看汇编代码)
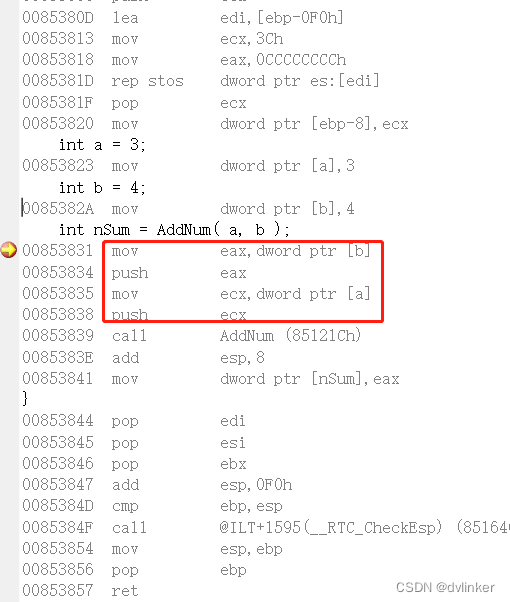
如上所示,在调用AddNum之前,将要传入的参数a和b分别压到栈上,然后再调用AddNum函数。对于被调用函数AddNum,则到栈上去获取传入的参数值。
当然,参数通过栈传递不是绝对的,比如对于64位程序,可用的寄存器比较多,要格式化的参数不多时,可能直接使用寄存器传递,这样效率比较高,比压入栈内存及读取栈内存,要快很多。下面一段话摘自微软官方说明:
在 ARM 和 x64 处理器上,接受 __cdecl、__stdcall等调用约定,但编译器一般会忽略它。 按照 ARM 和 x64 上的约定,自变量将尽可能传入寄存器,后续自变量传递到堆栈中。
关于x64环境下函数调用调用时的参数传递的详细说明,感兴趣的,可以查看微软官方链接:https://learn.microsoft.com/zh-cn/cpp/cpp/argument-passing-and-naming-conventions?view=msvc-170
就上面说的那样, 不管是x86还是x64下,直接在Visual Studio中查看反汇编代码,就知道参数是怎么传递过去的了!
为什么要讲参数是如何传递给被调用函数的呢?这个和格式化函数如何从栈上获取传入的参数内容有直接的关系。要理解格式化函数内部是如何从栈上读取传入的参数,必须了解函数调用时的栈分布(在调用函数前要把参数值压到栈上,通过栈传递给被调用函数)。
2.2、格式化函数是如何从栈上找到待格式化的参数值,并完成格式化的?
对于支持可变参的格式化函数,他没法确定主调函数实际传入了多少个参数,只能依次根据设置的格式化符依次到栈上读取对应的数据。要搞清楚格式化时为什么会出问题(甚至是崩溃),必须要搞清楚格式化函数如何根据格式化符从栈上依次解析出待格式化的参数值的。搞清楚这个问题,还需要了解上面讲到的函数调用时参数是怎么压到栈上的,多个参数时的压栈顺序则是和函数的调用约定有关系的。
以格式化函数sprintf为例,将两个int型变量的值格式化到字符串中:
int i = 2, j= 3;
char szBuffer[128] = { 0 };
sprintf( szBuffer, "i = %d, j =%d", i, j );其中,格式化函数sprintf的声明为:
int __cdecl sprintf( char *buffer, const char *format, ... );该函数是C运行时库中提供的系统函数,支持可变参的,可以对多个参数进行格式化。
对于可变参的函数,其调用约定一般都为__cdecl(C调用),不能声明为__stdcall,因为对于可变参函数,函数主调方才知道传入了多少个参数,只有函数主调方去才知道释放该释放多少参数占用的栈内存,所以要声明为__cdecl调用,而对于__stdcall调用,是被调函数去释放传入参数占用的栈内存的。通过这个支持可变参的函数,就能辅助记忆__cdecl调用和__stdcall调用的区别,这是个小技巧。
此外,对于__cdecl调用,参数是从右向左依次压栈的,即先将参数j的值压栈,然后再将参数i的值压栈。对于常用的__stdcall标准调用,参数也是从右到左依次入栈的。
之前我们看过VC6.0自带的CString类的支持可变参数格式化的Format函数的内部代码实现,从这些代码中就能看出格式化函数内部是如何根据格式化符依次到栈上找到对应的带格式化数据的。
格式化函数不管你传入了多少个参数,它是根据设置的格式化符(主要关注格式化符类型与个数),从左到右依次解析出设置的格式化符,然后根据格式化符到栈上去找待格式化的数据的。格式化函数能获取到传入的参数占用的栈内存的首地址,所有要传入的参数是依次压到栈上,所以这些参数占用的栈内存是连续的、挨在一起的。
还是以上面的例子为例,讲解格式化函数内部大概是如何根据格式化符去获取要格式化的数据!首先,绘制出了函数调用之前压栈的栈分布图,如下所示:

当解析到第1个格式化符%d,就到栈内存上取4个字节的内存,然后将内存中的值读出来,作为要格式化的内容。解析完第1个%d,将保存参数占用的栈内存首地址的指针p向后偏移%d对应的数据占用的4字节,为解析下一个待格式化的参数做准备。
当解析到第2个%d时,再到指针p中保存的内存起始地址处取出4个字节内存,将这4个字节内存中的内容作为要格式化的数据写到目标串中。同样地,将保存参数占用的栈内存首地址的指针p向后偏移%d对应的数据占用的4字节,为解析下一个待格式化的参数做准备。
2.3、字符串格式化符%s对应的异常问题场景说明
如果格式化符是%s,对应的是字符串,则调用函数前对应的参数压到栈上的内容是字符串的首地址,这样在处理到%s时从栈上将调用函数前压入的字符串首地址读出来,然后到这个首地址对应的内存中将字符串读出来。
如果格式化符与带格式化参数类型不匹配,根据%s到栈上取出的字符串首地址是0x00000001这样的很小的地址,然后去访问这个很小地址,就会触发内存访问违例。我们多次讲过,在Windows系统中,地址值小于64KB的内存区域是NULL地址内存区,是禁止访问的,一旦访问就会触发内存访问违例,系统会强行将进程终止掉。这个问题场景,我们以前就遇到过。
2.4、为了方便理解上述机制,附上VC6.0中的CString类的Format函数的实现源码
支持可变参数格式化的函数有很多,比如printf和sprintf等,但这些C运行时函数无法直接在Visual Studio中看到其内部源码实现。
其实,对于printf和sprintf内部实现源码,是能找到的,他们内部调用的都是_output_l,虽然单步调试时这个函数进不去,但_output_l可以在output.c文件中找到,所以还是能找到printf和sprintf底层实现的!
对于output.c文件,直接用Everything搜索,在我安装Visual Studio 2010的机器上能搜到:
以前我们从VC6.0 MFC库中抠出CString类的完整实现源码,为了方便大家理解上面讲解的格式化函数内部解析机制,这个地方我们给出CString::Format相关代码:
// formatting (using wsprintf style formatting)
void CString::Format(LPCTSTR lpszFormat, ...)
{assert(IsValidString(lpszFormat));va_list argList;va_start(argList, lpszFormat);FormatV(lpszFormat, argList);va_end(argList);
}#define _INTSIZEOF(n) ((sizeof(n) + sizeof(int) - 1) & ~(sizeof(int) - 1))#define __crt_va_start_a(ap, v) ((void)(ap = (va_list)_ADDRESSOF(v) + _INTSIZEOF(v)))
#define __crt_va_arg(ap, t) (*(t*)((ap += _INTSIZEOF(t)) - _INTSIZEOF(t)))
#define __crt_va_end(ap) ((void)(ap = (va_list)0))#define va_start __crt_va_start
#define va_arg __crt_va_arg
#define va_end __crt_va_end
#define va_copy(destination, source) ((destination) = (source))void CUIString::FormatV(LPCTSTR lpszFormat, va_list argList)
{assert(IsValidString(lpszFormat));va_list argListSave = argList;// make a guess at the maximum length of the resulting stringint nMaxLen = 0;for (LPCTSTR lpsz = lpszFormat; *lpsz != '\0'; lpsz = _tcsinc(lpsz)){// handle '%' character, but watch out for '%%'if (*lpsz != '%' || *(lpsz = _tcsinc(lpsz)) == '%'){nMaxLen += _tclen(lpsz);continue;}int nItemLen = 0;// handle '%' character with formatint nWidth = 0;for (; *lpsz != '\0'; lpsz = _tcsinc(lpsz)){// check for valid flagsif (*lpsz == '#')nMaxLen += 2; // for '0x'else if (*lpsz == '*')nWidth = va_arg(argList, int);else if (*lpsz == '-' || *lpsz == '+' || *lpsz == '0' ||*lpsz == ' ');else // hit non-flag characterbreak;}// get width and skip itif (nWidth == 0){// width indicated bynWidth = _ttoi(lpsz);for (; *lpsz != '\0' && _istdigit(*lpsz); lpsz = _tcsinc(lpsz));}assert(nWidth >= 0);int nPrecision = 0;if (*lpsz == '.'){// skip past '.' separator (width.precision)lpsz = _tcsinc(lpsz);// get precision and skip itif (*lpsz == '*'){nPrecision = va_arg(argList, int);lpsz = _tcsinc(lpsz);}else{nPrecision = _ttoi(lpsz);for (; *lpsz != '\0' && _istdigit(*lpsz); lpsz = _tcsinc(lpsz));}assert(nPrecision >= 0);}// should be on type modifier or specifierint nModifier = 0;if (_tcsncmp(lpsz, _T("I64"), 3) == 0){lpsz += 3;nModifier = FORCE_INT64;
#if !defined(_X86_) && !defined(_ALPHA_)// __int64 is only available on X86 and ALPHA platformsassert(FALSE);
#endif}else{switch (*lpsz){// modifiers that affect sizecase 'h':nModifier = FORCE_ANSI;lpsz = _tcsinc(lpsz);break;case 'l':nModifier = FORCE_UNICODE;lpsz = _tcsinc(lpsz);break;// modifiers that do not affect sizecase 'F':case 'N':case 'L':lpsz = _tcsinc(lpsz);break;}}// now should be on specifierswitch (*lpsz | nModifier){// single characterscase 'c':case 'C':nItemLen = 2;va_arg(argList, TCHAR_ARG);break;case 'c'|FORCE_ANSI:case 'C'|FORCE_ANSI:nItemLen = 2;va_arg(argList, CHAR_ARG);break;case 'c'|FORCE_UNICODE:case 'C'|FORCE_UNICODE:nItemLen = 2;va_arg(argList, WCHAR_ARG);break;// stringscase 's':{LPCTSTR pstrNextArg = va_arg(argList, LPCTSTR);if (pstrNextArg == NULL)nItemLen = 6; // "(null)"else{nItemLen = lstrlen(pstrNextArg);nItemLen = max(1, nItemLen);}}break;case 'S':{
#ifndef _UNICODELPWSTR pstrNextArg = va_arg(argList, LPWSTR);if (pstrNextArg == NULL)nItemLen = 6; // "(null)"else{nItemLen = wcslen(pstrNextArg);nItemLen = max(1, nItemLen);}
#elseLPCSTR pstrNextArg = va_arg(argList, LPCSTR);if (pstrNextArg == NULL)nItemLen = 6; // "(null)"else{nItemLen = lstrlenA(pstrNextArg);nItemLen = max(1, nItemLen);}
#endif}break;case 's'|FORCE_ANSI:case 'S'|FORCE_ANSI:{LPCSTR pstrNextArg = va_arg(argList, LPCSTR);if (pstrNextArg == NULL)nItemLen = 6; // "(null)"else{nItemLen = lstrlenA(pstrNextArg);nItemLen = max(1, nItemLen);}}break;case 's'|FORCE_UNICODE:case 'S'|FORCE_UNICODE:{LPWSTR pstrNextArg = va_arg(argList, LPWSTR);if (pstrNextArg == NULL)nItemLen = 6; // "(null)"else{nItemLen = wcslen(pstrNextArg);nItemLen = max(1, nItemLen);}}break;}// adjust nItemLen for stringsif (nItemLen != 0){if (nPrecision != 0)nItemLen = min(nItemLen, nPrecision);nItemLen = max(nItemLen, nWidth);}else{switch (*lpsz){// integerscase 'd':case 'i':case 'u':case 'x':case 'X':case 'o':if (nModifier & FORCE_INT64)va_arg(argList, __int64);elseva_arg(argList, int);nItemLen = 32;nItemLen = max(nItemLen, nWidth+nPrecision);break;case 'e':case 'g':case 'G':va_arg(argList, DOUBLE_ARG);nItemLen = 128;nItemLen = max(nItemLen, nWidth+nPrecision);break;case 'f':{double f;LPTSTR pszTemp;// 312 == strlen("-1+(309 zeroes).")// 309 zeroes == max precision of a double// 6 == adjustment in case precision is not specified,// which means that the precision defaults to 6pszTemp = (LPTSTR)_alloca(max(nWidth, 312+nPrecision+6));f = va_arg(argList, double);_stprintf( pszTemp, _T( "%*.*f" ), nWidth, nPrecision+6, f );nItemLen = _tcslen(pszTemp);}break;case 'p':va_arg(argList, void*);nItemLen = 32;nItemLen = max(nItemLen, nWidth+nPrecision);break;// no outputcase 'n':va_arg(argList, int*);break;default:assert(FALSE); // unknown formatting option}}// adjust nMaxLen for output nItemLennMaxLen += nItemLen;}GetBuffer(nMaxLen);//VERIFY(_vstprintf(m_pchData, lpszFormat, argListSave) <= GetAllocLength());// 将上一句的VERIFY代码注释掉,重新写// 此处去掉了VERIFYint nWriteCount = GetAllocLength() + 1;int nLen = _vstprintf(m_pchData, nWriteCount, lpszFormat, argListSave);assert( nLen <= GetAllocLength() );ReleaseBuffer();va_end(argListSave);
}上述代码中涉及到两个宏:__crt_va_arg和_INTSIZEOF,这两个宏很有特点,实现的很巧妙,要搞懂代码,需要先看懂这两个宏的含义。_INTSIZEOF宏实现4字节对齐。__crt_va_arg宏则实现栈内存地址指针ap向后累加偏移,同时返回当前待格式化参数的栈内存地址。
有人可能会说,为什么要看古老的VC6.0中的CString中的代码,为啥不看新版本Visual Studio中的CString类的实现源码呢?新版本的Visual Studio中的CString类都是用模版实现的,看着很费劲,VC6.0中的代码看着比较直观易懂,主要为了搞清楚格式化函数内部的解析机制,只要能搞懂这个机制和解析过程即可分析问题了。
2.5、如果要格式化某个C++类对象的数据,且对象中包含多个数据成员,要明确指定要格式化的那个数据成员
以duilib开源库中的CStdString字符串类为例,类中包含了两个数据成员,如下:
class DIRECTUI_API CStdString
{
public:enum { MAX_LOCAL_STRING_LEN = 16 };CStdString(); CStdString(const TCHAR ch);LPCTSTR GetData(){ return m_pstr;}// ...... // 其他成员函数省略protected:LPTSTR m_pstr; // 字符指针TCHAR m_szBuffer[MAX_LOCAL_STRING_LEN]; // 字符缓冲区
};在格式化时必须明确格式化的是哪个数据成员,不能直接把C++类对象作为参数传到函数中。因为如果传入的参数是个类对象,会把整个类的数据成员值都压到栈上去的,但实际上我们只是想格式化类中的某个数据成员,多压入的数据就会导致后续的格式化符处理出问题。比如有问题的代码如下:
CStdString strId;
CStdString strName;// 中间对strId和strName的赋值代码省略,假设这两个变量中已经存放了真实的字符串数据。
// ...CStdString strLog;
strLog.Format(_T("strId: %s, strName: %s"), strId, strName);此处的写法就是有问题的,直接把类对象strId和strName作为参数传进去了,而对应的CStdString包含了两个数据成员m_pstr和m_szBuffer,这样在调函函数之前压栈时将两个成员变量都压到栈上了。而实际上我们要格式化的是m_pstr。当然这个地方有一点比较迷惑人,CStdString就是处理字符串的字符串类,大家在格式化时理所当然直接传入对象进去。
正确的做法是,调用CStdString::GetData接口获取到成员变量m_pstr,我们只需要格式化m_pstr成员的数据,正确的代码如下:
CStdString strId;
CStdString strName;// 中间对strId和strName的赋值代码省略,假设这两个变量中已经存放了真实的字符串数据。
// ...CStdString strLog;
strLog.Format(_T("strId: %s, strName: %s"), strId.GetData(), strName.GetData() );3、本案例中的问题分析与排查
3.1、问题代码
出问题的打印日志代码如下所示:

第1个参数是字符串首地址,第2个参数是整数值,第3个参数和第4个参数都是bool型,第5个参数也是字符串的首地址。一般这类问题,都是格式化符和待格式化参数类型不匹配不一致引发的,但并没有发现明显的不匹配问题。
以前我在做C++软件调试与异常排查培训课时,讲到过格式化符与待格式化参数不匹配的问题,维护这块代码的同事怀疑是不是和压栈的参数有关系。确实,从汇编上看,在调用函数时,对于C调用约定,参数要从右到左依次压栈,被调用函数内部从栈上读取传入的参数值。
对于支持可变参的格式化函数,函数内部时根据设置的格式化符,依次到栈上取出对应的要格式化的数据。如果格式化符与待格式化的参数可不一致,则在从栈上读取数据时会出现地址偏差,读取了不该读取的内存区域,导致出异常。
3.2、初步分析
最开始怀疑第3个和第4个bool型参数,都使用了%d格式化符,是不是有问题?bool型变量好像只压栈一个字节的内存数据,但格式化函数内部遇到%d格式化符时,会从栈上取出4个字节,这个好像不一致了,于是在bool型待格式化参数前人为加上一个int型的强转,编译代码测试了一下,第5个参数还是打印不出来。
其实待格式化的bool型参数,在压栈的时候压入的四个字节,即四字节对齐。于是询问了同事,第2个参数类型是啥,这个参数是一个函数的返回值,不问还好,一问就不好了,这个参数类型是UINT64,即无符号64位整型,结果格式化符使用的是%d,问题就出在这里了,应该使用64位无符号整型对应的格式化符%llu(注意此处不要用%lld,因为UINT64是无符号的),用%d肯定是有问题的。
3.3、为什么UINT64型数据使用%d格式化符会有问题?
格式化函数内部根据当前要的格式化符,到栈内存上读取对应字节数的内存中的数据,作为当前要格式化的数据,同时将栈内存地址向后偏移当前格式化符对应的内存长度,为处理下一个格式化符数据的格式化做准备。然后取出第二个格式化符,处理第二个待格式化的参数。然后依次类推!
本问题中出问题的打印代码如下:

上述出问题的那行代码,传入了5个参数,在调用打印函数之前需要把这5个参数压到栈上,传递给被调用的日志打印函数。这几个参数压入栈后的栈分布图如下:

在本问题中,处理%d格式化符对应的UINT64数据格式化时,因为格式化符%d对应4个字节,所以只从栈内存上取出4字节内存中的数据(取得不是64为整型数据对应的8字节),同时栈内存指针向后偏移%d格式化符对应的4字节,这样导致在解析第3个%d格式化符时取的还是UINT64整型数据的一部分,即错位了,所以出问题了!所以继续往下推算,在解析第5个%s格式化符对应的内存时取的是第4个bool型的内存,把bool值作为一个字符串的首地址,然后取读取地址中的字符串,因为地址很小,应该会触发内存访问违例,产生崩溃。但实际运行时并没有崩溃,并且输出了(null)值,难道是格式化函数中特别做了一个保护,发现地址为空,直接输出了一个null串?估计是这样的。
3.4、解决办法
解决这个问题的办法很简单,只要将UINT64类型参数对应的格式化符换成%llu就可以了。用一句话概括,要使用带格式化参数类型对应长度的格式化符!
4、最后
本案例很典型,通过这个案例详细讲解了格式化函数内部机制和解析过程,对于排查数据格式化问题(比如数据没有打印出来,或者程序发生异常崩溃)有直接的指导价值,有直接的实战参考价值。参考这个实例的分析过程,大家后面遇到格式化问题时,就能自行去分析和排查了!



![ros2学习笔记:shell环境变量脚本setup.bash[-z][-n][-f]参数作用](https://img-blog.csdnimg.cn/46e09f18b29d4199a6c979eaaef6e3b3.png)