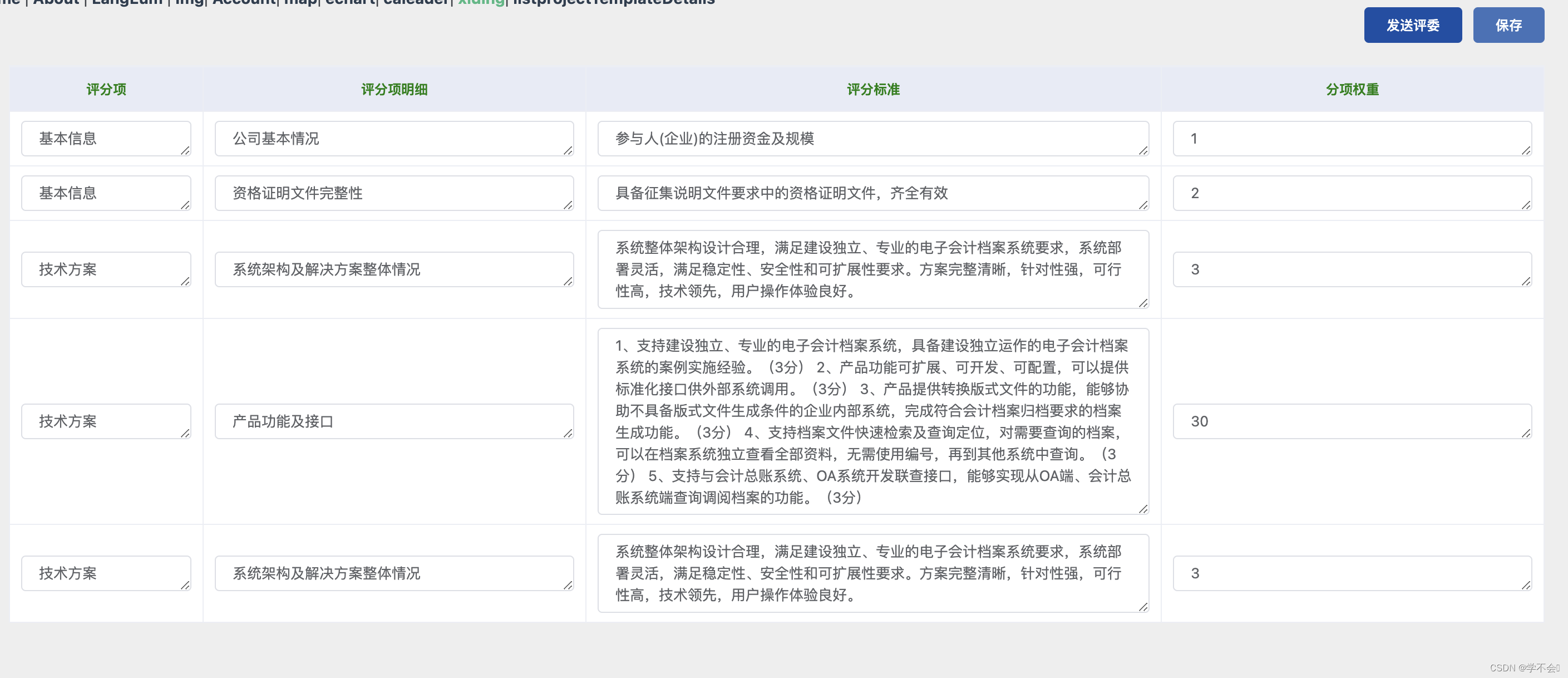
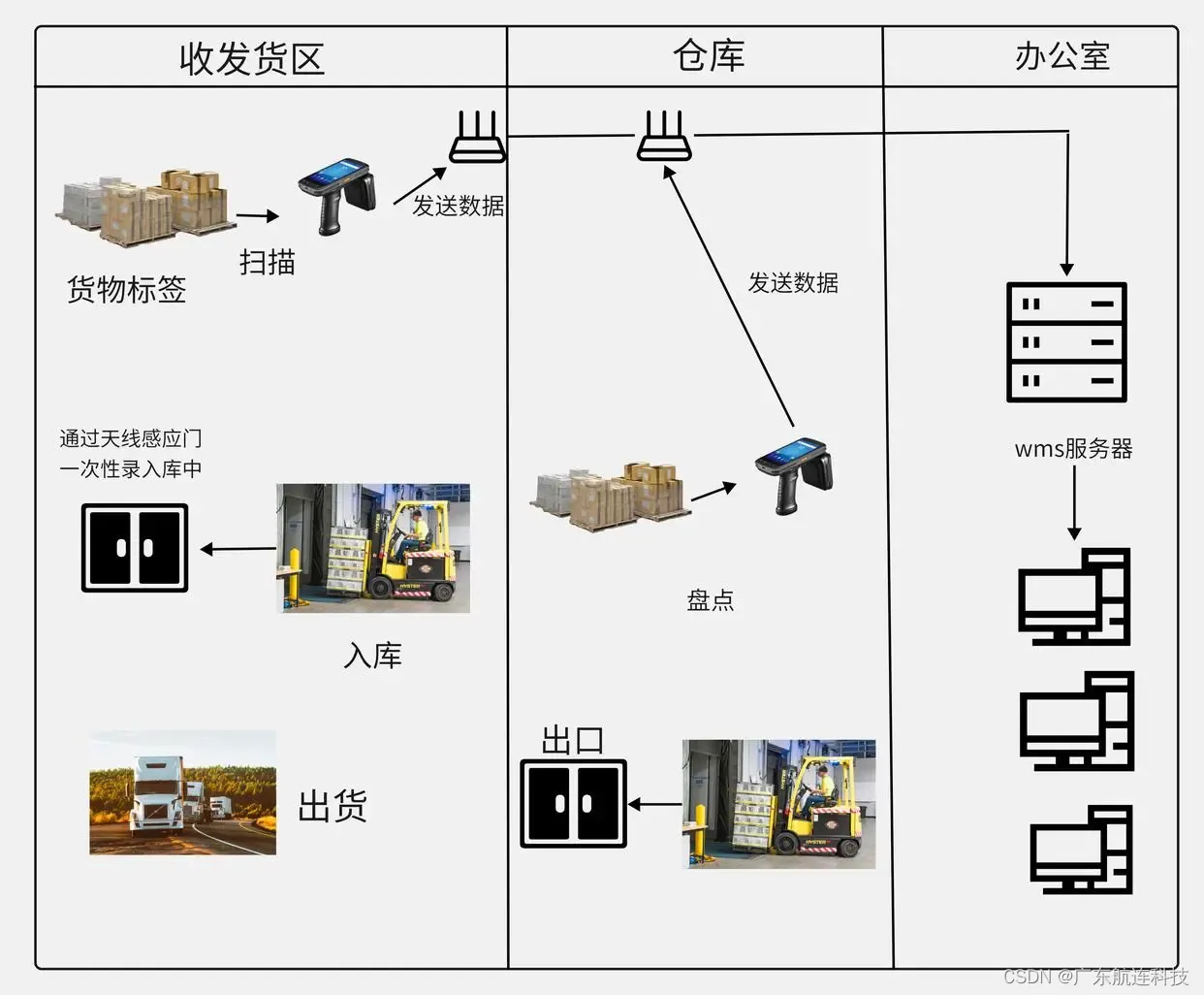
参考:
https://zh-v2.d2l.ai/chapter_recurrent-neural-networks/rnn-concise.html
https://pytorch.org/docs/stable/generated/torch.nn.RNN.html?highlight=rnn#torch.nn.RNN
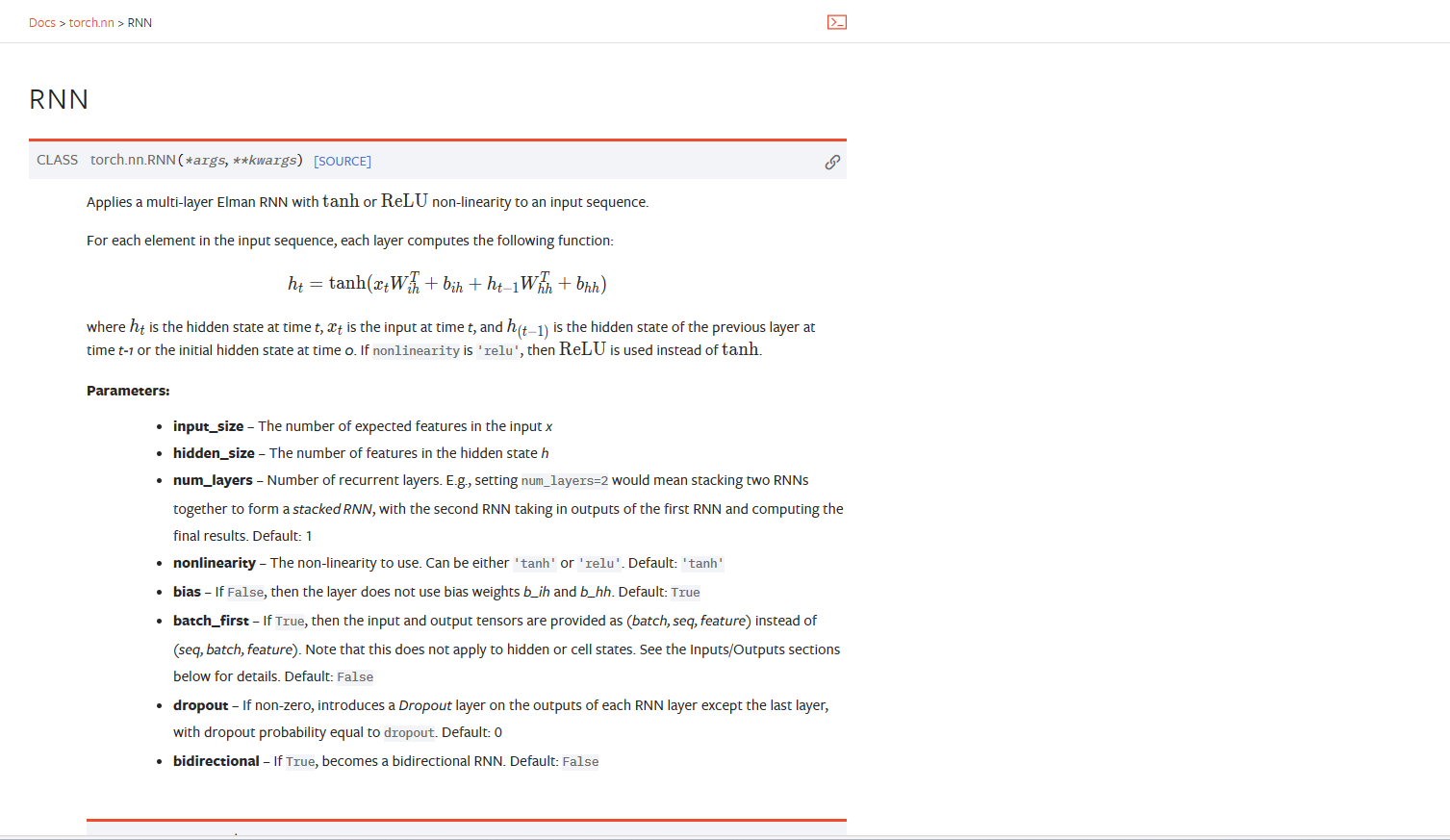
RNN


import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2lbatch_size, num_steps = 32, 35 # num_steps: sequence length
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps) # vocab:Vocab 26# 1 定义模型
# 构造一个具有256个隐藏层的循环神经网络 rnn_layer
# 此处先仅设计一层循环神经网络,以后讨论多层神经网络
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab),num_hiddens) # RNN(28,256)
"""input_size – The number of expected features in the input x
hidden_size – The number of features in the hidden state h
num_layers – Number of recurrent layers. E.g., setting num_layers=2 would mean stacking two RNNs together to form a stacked RNN, with the second RNN taking in outputs of the first RNN and computing the final results. Default: 1
nonlinearity – The non-linearity to use. Can be either 'tanh' or 'relu'. Default: 'tanh'
bias – If False, then the layer does not use bias weights b_ih and b_hh. Default: True
batch_first – If True, then the input and output tensors are provided as (batch, seq, feature) instead of (seq, batch, feature). Note that this does not apply to hidden or cell states. See the Inputs/Outputs sections below for details. Default: False
dropout – If non-zero, introduces a Dropout layer on the outputs of each RNN layer except the last layer, with dropout probability equal to dropout. Default: 0
bidirectional – If True, becomes a bidirectional RNN. Default: False
"""
# 2.我们使用张量来初始化隐状态,它的形状是(隐藏层数,批量大小,隐藏单元数)
state = torch.zeros((1,batch_size,num_hiddens))
print(state.shape) #(torch.size([1,32,256]))#3. 通过一个隐状态和一个输入,我们就可以用更新后的隐状态计算输出。
# 需要强调的是,rnn_layer的“输出”(Y)不涉及输出层的计算: 它是指每个时间步的隐状态,这些隐状态可以用作后续输出层的输入。
X=torch.rand(size=(num_steps,batch_size,len(vocab))) #torch.Size([35, 32, 28]) # (L,N,H(in)) L:sequence length N batch size Hin: input_size
Y,state_new = rnn_layer(X,state)
print(Y.shape,state_new.shape) #torch.Size([35, 32, 256]) torch.Size([1, 32, 256])class RNNModel(nn.Module):"""循环神经网络"""def __init__(self,rnn_layer,vocab_size,**kwargs):super(RNNModel,self).__init__(**kwargs)self.rnn = rnn_layerself.vocab_size = vocab_sizeself.num_hiddens = self.rnn.hidden_size# 如果RNN是双向的,num_directions 应该是2,否则应该是1if not self.rnn.bidirectional:self.num_directions = 1self.linear = nn.Linear(self.num_hiddens,self.vocab_size)else:self.num_directions = 2self.linear = nn.Linear(self.num_hiddens*2,self.vocab_size)def forward(self,inputs,state):X = F.one_hot(inputs.T.long(),self.vocab_size)X = X.to(torch.float32)Y,state = self.rnn(X,state)# 全连接首层将Y的形状改为(时间步数*批量大小,隐藏单元数)output = self.linear(Y.reshape((-1,Y.shape[-1])))return output,statedef begin_state(self, device, batch_size=1):if not isinstance(self.rnn, nn.LSTM):# nn.GRU以张量作为隐状态return torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens),device=device)else:# nn.LSTM以元组作为隐状态return (torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device),torch.zeros((self.num_directions * self.rnn.num_layers,batch_size, self.num_hiddens), device=device))# 训练
device = d2l.try_gpu()
net = RNNModel(rnn_layer,vocab_size=len(vocab))
net = net.to(device)
num_epochs ,lr = 500,1
d2l.train_ch8(net,train_iter,vocab,lr,num_epochs,device)