文章目录
- 前言
- 一、模板参数的改造
- 二、模板的特例化操作
- 三、仿函数的妙用
- 四、unordered迭代器基本操作
- 1.const迭代器注意:
- 2.HashTable与HTIterator的冲突
- 五、迭代器的构造问题
- 六、完整代码
- 1.hash_bucket.h
- 2.unordered_set.h
- 3.unordered_map.h
前言
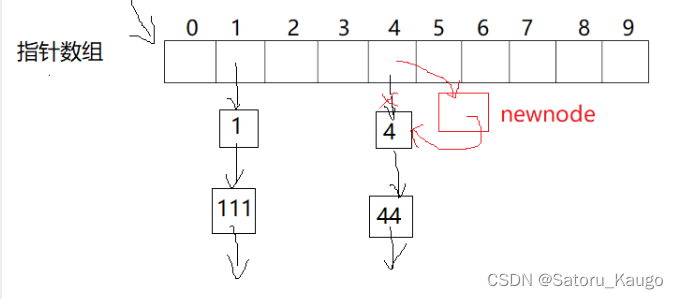
我们开辟一个指针数组,指针数组中存放我们结点的类型,我们算出元素的下标hashi后,头插在数组的对应位置,数组的位置可以链接一串链表,所以也避免了哈希冲突
一、模板参数的改造
我们这里把pair<K,V>看成一个整体,我们设计模板的时候就不需要考虑是不是键值对类型,需不需要多传一个模板参数的问题,达到了普适性。
template<class T>
struct HashNode {T _data;HashNode<T>* _next;HashNode(const T& data):_data(data),_next(nullptr){}
};
在map中,T传pair<K,V>类型
在set中,T传K类型
二、模板的特例化操作
我们要想插入一个结点,肯定要知道这个结点插入的位置,所以我们要自己写一个哈希函数的模板来进行下标的计算,但我们int类型之间计算下标很容易,那我们字符串该怎么办?
这个时候就需要模板的特例化了,根据传入的参数不同,具体类型具体分析
template<class K>
struct DefaultHashFunc {size_t operator()(const K& key) {return (size_t)key;}
};template<>
struct DefaultHashFunc<string> {//对字符串特殊处理size_t operator()(const string& str) {size_t hash = 0;for (auto e : str) {hash *= 131;hash += e;}//字符串的总和再与131相乘,//减少字符串和雷同的情况return hash;}
};之后再对算出的hash进行取模的操作
三、仿函数的妙用
我们value_type类型用模板参数T代替之后,这个时候就会衍生一个问题,我T可能为键值对类型,我键值对之间怎么比较呢?
例如:T t1与T t2两个变量,我们肯定不能直接比较,肯定要依据他们的键值大小进行比较,所以我们需要自己写一个用于比较的函数,这个时候仿函数刚好能发挥这个用处,可以作为模板参数传入自己写的比较函数
取出他们的键,让他们进行比较,这里set也这样写是为了配合map,因为两者都用的一个哈希桶模板
struct SetKeyOfT {const K& operator()(const K&key) {return key;}};struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};四、unordered迭代器基本操作
1.const迭代器注意:
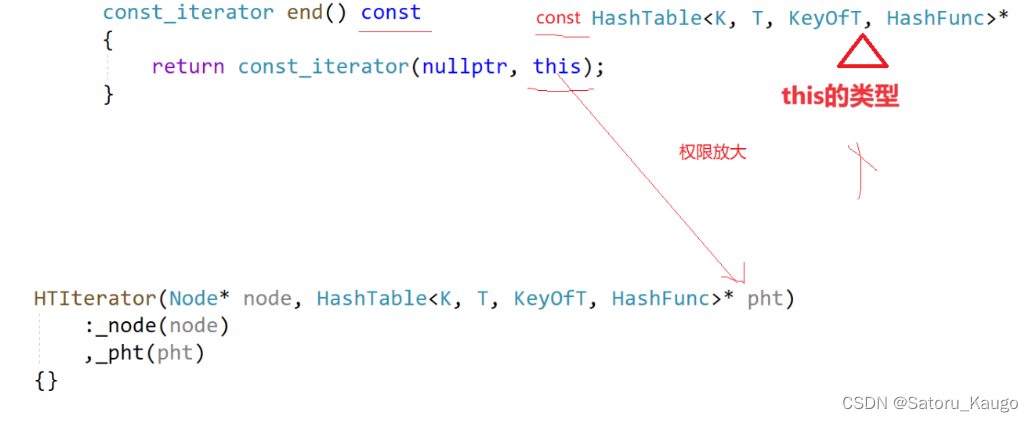
这里如果使用const迭代器会报错,因为发生了权限的放大
修改方法:在参数的位置以及定义的时候给HashTable加上const
这样当我们传const类型的时候发生权限的平移,传普通类型的时候发生权限缩小const HashTable<K, T, KeyOfT, HashFunc>* _pht;Node* _node;HTIterator(Node*node, const HashTable<K, T, KeyOfT, HashFunc>* pht):_node(node),_pht(pht){}
2.HashTable与HTIterator的冲突
HashTable中用到了HTIterator,因为要创建出迭代器,而我们HTIterator内部使用到了HashTable中的私有。这就造成了先有鸡还是先有蛋的问题。
解决方法:
在HTIterator的类前面进行前置声明。告诉编译器这个HashTable是存在的
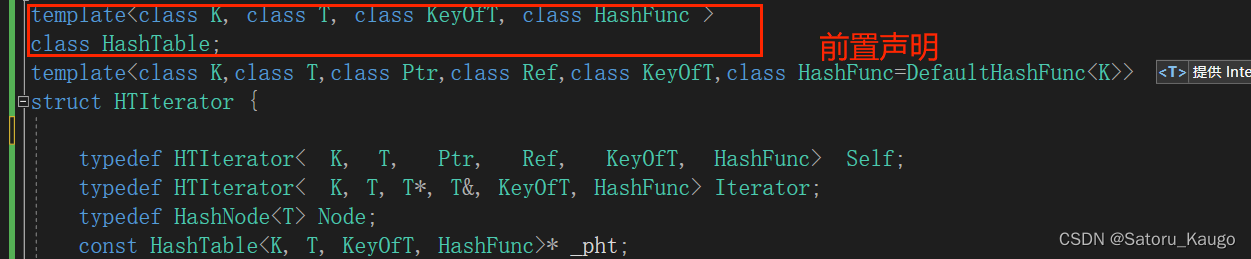
在HashTable中声明友元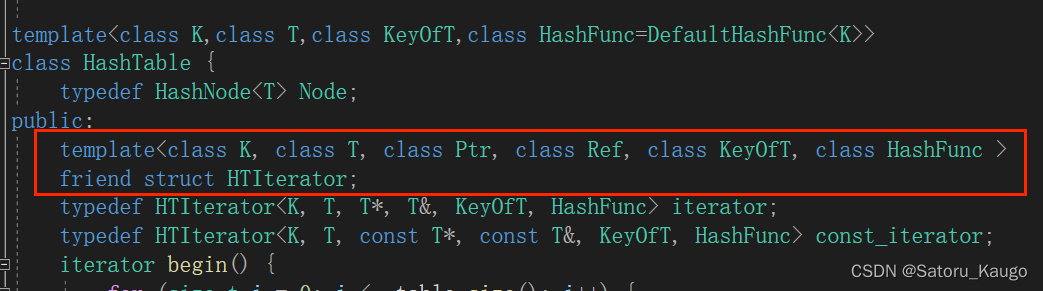
五、迭代器的构造问题
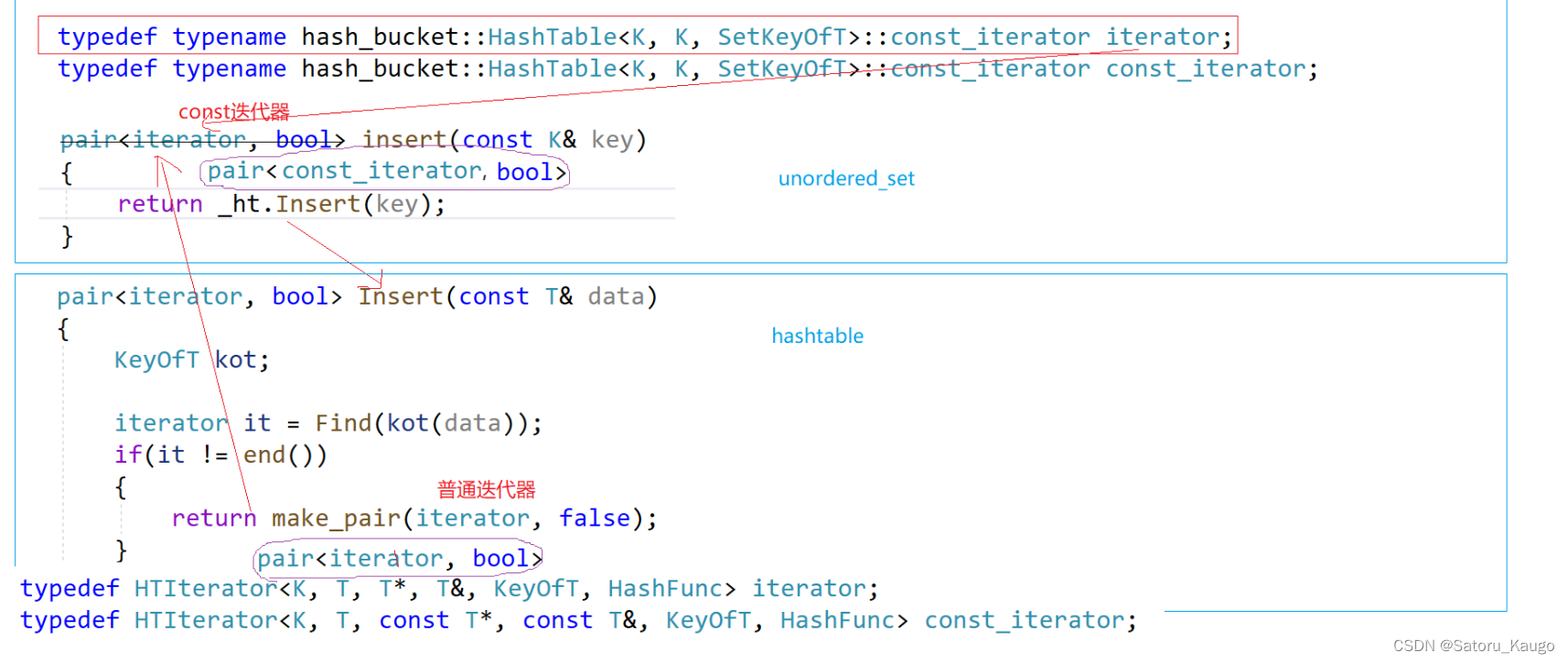
在unordered_set中我们返回的pair里面的iterator是const类型,但我们哈希桶里面写的Insert中的pair返回的是普通迭代器,因为类模板实例化不同的模板参数就是不同的类型,所以这里const_iterator与iterator我们可以看成是两个不相同的类型,如果我们直接传哈希桶里面的Insert返回值会发生报错,因为类型不匹配。
这个时候我们需要一个函数来将iterator类型转变为const_iterator类型,我们可以从迭代器的拷贝构造下手。
typedef HTIterator< K, T, Ptr, Ref, KeyOfT, HashFunc> Self;
typedef HTIterator< K, T, T*, T&, KeyOfT, HashFunc> Iterator;
typedef HashNode<T> Node;
const HashTable<K, T, KeyOfT, HashFunc>* _pht;
Node* _node;HTIterator(const Iterator& it):_node(it._node), _pht(it._pht){}
如果调用这个函数的是普通迭代器iterator,这里就是纯拷贝构造
如果调用这个函数的是const_iterator,那么这个函数就是构造,我们可以传入普通迭代器iterator来构造出const_iterator
六、完整代码
1.hash_bucket.h
#pragma once
#include<vector>
#include<string>namespace hash_bucket {template<class T>
struct HashNode {//结点的定义T _data;HashNode<T>* _next;HashNode(const T& data):_data(data),_next(nullptr){}
};template<class K>
struct DefaultHashFunc {//哈希函数进行下标的求取size_t operator()(const K& key) {return (size_t)key;}
};template<>//模板特例化
struct DefaultHashFunc<string> {//对字符串特殊处理size_t operator()(const string& str) {size_t hashi = 0;for (auto e : str) {hashi *= 131;hashi += e;}return hashi;}
};template<class K, class T, class KeyOfT, class HashFunc >
class HashTable;
//前置声明
template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc = DefaultHashFunc<K>>
struct HTIterator {typedef HTIterator< K, T, Ptr, Ref, KeyOfT, HashFunc> Self;typedef HTIterator< K, T, T*, T&, KeyOfT, HashFunc> Iterator;typedef HashNode<T> Node;const HashTable<K, T, KeyOfT, HashFunc>* _pht;//引入哈希桶,因为我们进行++操作的时候需要哈希桶数组来确定位置//这里哈希桶要为const类型Node* _node;HTIterator(Node* node, const HashTable<K, T, KeyOfT, HashFunc>* pht):_node(node),_pht(pht){}HTIterator(const Iterator& it):_node(it._node), _pht(it._pht){}Self& operator++() {if (_node->_next) {//当前链表后面还有_node = _node->_next;}else {//当前链表以及走完KeyOfT kot;HashFunc hf;size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();//kot先取出_node->_data中的K值然后hf算出哈希下标++hashi;//从下一个位置开始while (hashi < _pht->_table.size()) {if (_pht->_table[hashi]) {//找不为空的位置_node = _pht->_table[hashi];return*this;}else {hashi++;}}_node = nullptr;}return *this;}Ref operator*() {return _node->_data;}Ptr operator->() {return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}bool operator==(Self& s) {return _node == s._node;}};template<class K,class T,class KeyOfT,class HashFunc=DefaultHashFunc<K>>
//KeyOfT的作用是取出T里面的K值,因为T有可能为pair类型
class HashTable {typedef HashNode<T> Node;
public:template<class K, class T, class Ptr, class Ref, class KeyOfT, class HashFunc >friend struct HTIterator;//友元的引入typedef HTIterator<K, T, T*, T&, KeyOfT, HashFunc> iterator;typedef HTIterator<K, T, const T*, const T&, KeyOfT, HashFunc> const_iterator;iterator begin() {//找到数组的第一个不为空的位置for (size_t i = 0; i < _table.size(); i++) {if (_table[i]) {return iterator(_table[i], this);}}return iterator(nullptr, this);}iterator end() {return iterator(nullptr, this);}const_iterator begin()const {for (size_t i = 0; i < _table.size(); i++) {if (_table[i]) {return const_iterator(_table[i], this);}}return const_iterator(nullptr, this);}const_iterator end()const {return const_iterator(nullptr, this);}HashTable(){//构造函数_table.resize(10,nullptr);}~HashTable() {//析构函数for (size_t i = 0; i < _table.size(); i++) {Node* cur = _table[i];while (cur) {Node* first = cur->_next;delete cur;cur = first;}_table[i] = nullptr;}}iterator Find(const K& key){HashFunc hf;KeyOfT kot;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (kot(cur->_data) == key){return iterator(cur, this);}cur = cur->_next;}return end();}pair<iterator, bool> Insert(const T& data){KeyOfT kot;iterator it = Find(kot(data));if (it != end()){return make_pair(it, false);}HashFunc hf;// 负载因子到1就扩容if (_n == _table.size()){//size_t newSize = _table.size() * 2;size_t newSize = _table.size()*2;vector<Node*> newTable;newTable.resize(newSize, nullptr);// 遍历旧表,顺手牵羊,把节点牵下来挂到新表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = hf(kot(cur->_data)) % newSize;cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashi = hf(kot(data)) % _table.size();// 头插Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return make_pair(iterator(newnode, this), true);}bool Erase(const K& key) {HashFunc hf;size_t hashi = hf(key) % _table.size();Node* prev = nullptr;Node* cur = _table[hashi];while (cur) {if (kot(cur->_data) == key) {if (prev == nullptr) {_table[hashi] = nullptr;}else {Node* next = cur->_next;prev->_next = next;}delete cur;return true;}prev = cur;cur = cur->_next;}--_n;return false;}private:vector<Node*> _table;//定义指针数组size_t _n;
};}
2.unordered_set.h
#pragma once
#include"hash_bucket.h"namespace bit {template<class K>class unordered_set {struct SetKeyOfT {const K& operator()(const K& key) {return key;}};public:typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator iterator;//重点typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator const_iterator;iterator begin()const {return _ht.begin();}iterator end()const {return _ht.end();}pair<iterator,bool>insert(const K& key) {pair< hash_bucket::HashTable<K, K, SetKeyOfT>::iterator,bool>ret= _ht.Insert(key);//先拿到为普通迭代器的iteratorreturn pair<iterator, bool>(ret.first, ret.second);//用普通迭代器构造const迭代器}private:hash_bucket::HashTable<K, K, SetKeyOfT> _ht;};}
3.unordered_map.h
#pragma once
#include"hash_bucket.h"namespace bit {template<class K,class V>class unordered_map {struct MapKeyOfT {const K& operator()(pair<K,V>kv) {return kv.first;}};public:typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}iterator begin() {return _ht.begin();}iterator end() {return _ht.end();}const_iterator begin()const {return _ht. begin();}const_iterator end()const {return _ht.end();}V& operator[](const K& key) {pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second;}private:hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT> _ht;};}