一、简介
LINE (Large-scale Information Network Embedding,2015) 是一种设计用于处理大规模信息网络的算法。它主要的目标是在给定的大规模信息网络中学习高质量的节点嵌入,并尽量保留网络中信息的丰富性。其具体的表现为在一个低 维空间里以向量形式表示网络中的节点,以便后续的机器学习任务可以更好地理解。
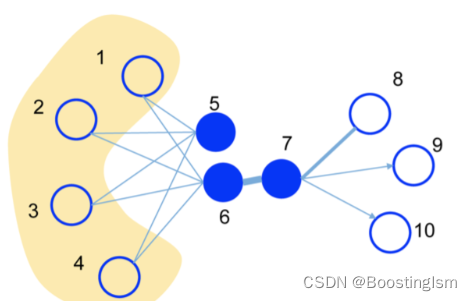
LINE算法根据两种相互关联的线性化策略去处理信息图,分别考虑了图节点的一阶邻居和二阶邻居。通过这种方式,LINE既能反映出网络的全局属性又能反映出网络的局部属性。
调用算法流程如下:
-
首先,为图中的每个节点初始化一个随机向量。
-
接着,使用一阶邻居的优化原型函数进行训练。在一阶近邻策略中,若两个节点存在直接连接,则他们的向量应该尽可能相近。
-
然后,使用二阶邻居的优化原型函数进行训练。在二阶近邻策略中,考虑两节点间的间接联系。例如,若两节点存在共享的邻居,即使他们之间没有直接的联系,他们的向量也应该相近。
-
对每个节点,计算其在一阶和二阶优化下的损失函数值,并对其进行优化。
-
优化完成后,此时每个节点上的向量就是最终的嵌入表示。
-
基于得到的嵌入表示进行后续的分析或机器学习任务。
接下来就是快乐的代码时间嘿嘿嘿
二、代码
import os
import pandas as pd
import numpy as np
import networkx as nx
import time
import scipy.sparse as sp
from torch_geometric.data import Data
from torch_geometric.transforms import ToSparseTensor
import torch_geometric.utils
from sklearn.preprocessing import LabelEncoderimport torch
import torch.nn as nn#配置项
class configs():def __init__(self):# Dataself.data_path = r'./data'self.save_model_dir = r'./'self.num_nodes = 2708self.embedding_dim = 128self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")self.learning_rate = 0.01self.epoch = 30self.criterion = nn.BCEWithLogitsLoss()self.istrain = Trueself.istest = Truecfg = configs()def load_cora_data(data_path = './data/cora'):content_df = pd.read_csv(os.path.join(data_path,"cora.content"), delimiter="\t", header=None)content_df.set_index(0, inplace=True)index = content_df.index.tolist()features = sp.csr_matrix(content_df.values[:,:-1], dtype=np.float32)# 处理标签labels = content_df.values[:,-1]class_encoder = LabelEncoder()labels = class_encoder.fit_transform(labels)# 读取引用关系cites_df = pd.read_csv(os.path.join(data_path,"cora.cites"), delimiter="\t", header=None)cites_df[0] = cites_df[0].astype(str)cites_df[1] = cites_df[1].astype(str)cites = [tuple(x) for x in cites_df.values]edges = [(index.index(int(cite[0])), index.index(int(cite[1]))) for cite in cites]edges = np.array(edges).T# 构造Data对象data = Data(x=torch.from_numpy(np.array(features.todense())),edge_index=torch.LongTensor(edges),y=torch.from_numpy(labels))idx_train = range(140)idx_val = range(200, 500)idx_test = range(500, 1500)# 读取Cora数据集 return geometric Data格式def index_to_mask(index, size):mask = np.zeros(size, dtype=bool)mask[index] = Truereturn maskdata.train_mask = index_to_mask(idx_train, size=labels.shape[0])data.val_mask = index_to_mask(idx_val, size=labels.shape[0])data.test_mask = index_to_mask(idx_test, size=labels.shape[0])def to_networkx(data):edge_index = data.edge_index.to(torch.device('cpu')).numpy()G = nx.DiGraph()for src, tar in edge_index.T:G.add_edge(src, tar)return Gnetworkx_data = to_networkx(data)return data,networkx_data
#获取数据:pyg_data:torch_geometric格式;networkx_data:networkx格式def generate_pairs(adj_matrix):# 根据邻接矩阵生成正例和负例pos_pairs = torch.nonzero(adj_matrix, as_tuple=True)pos_u = pos_pairs[0]pos_v = pos_pairs[1]mask = torch.ones_like(adj_matrix)for i in range(len(pos_u)):mask[pos_u[i]][pos_v[i]] = 0mask[pos_v[i]][pos_u[i]] = 0tmp = torch.nonzero(mask, as_tuple=True)#TODO 随机选取负例idx = torch.randperm(tmp[0].size(0))neg_u = tmp[0][idx][:pos_u.size(0)]neg_v = tmp[1][idx][:pos_v.size(0)]return pos_u, pos_v, neg_u, neg_v# 构建LINE网络
class LINE(nn.Module):def __init__(self, num_nodes, embed_dim):super(LINE, self).__init__()#num_nodes为Node个数 , embed_dim为描述Node的Embedding维度self.embed_dim = embed_dimself.num_nodes = num_nodesself.embeddings = nn.Embedding(self.num_nodes, self.embed_dim)self.reset_parameters()def reset_parameters(self):self.embeddings.weight.data.normal_(std=1 / self.embed_dim)def forward(self, pos_u, pos_v, neg_v):emb_pos_u = self.embeddings(pos_u)emb_pos_v = self.embeddings(pos_v)emb_neg_v = self.embeddings(neg_v)pos_scores = torch.sum(torch.mul(emb_pos_u, emb_pos_v), dim=1)neg_scores = torch.sum(torch.mul(emb_pos_u, emb_neg_v), dim=1)return pos_scores, neg_scoresclass LINE_run():def train(self):t = time.time()# 创建一个模型_, networkx_data = load_cora_data()adj_matrix = torch.tensor(nx.adjacency_matrix(networkx_data).toarray(), dtype=torch.float32)model = LINE(num_nodes=cfg.num_nodes, embed_dim=cfg.embedding_dim).to(cfg.device)optimizer = torch.optim.Adam(model.parameters(), lr=cfg.learning_rate)#Trainmodel.train()for epoch in range(cfg.epoch):optimizer.zero_grad()pos_u, pos_v, neg_u, neg_v = generate_pairs(adj_matrix)pos_u = pos_u.to(cfg.device)pos_v = pos_v.to(cfg.device)neg_v = neg_v.to(cfg.device)pos_scores, neg_scores = model(pos_u, pos_v, neg_v)pos_losses = cfg.criterion(pos_scores, torch.ones(len(pos_scores)).to(cfg.device))neg_losses = cfg.criterion(neg_scores, torch.zeros(len(neg_scores)).to(cfg.device))loss = pos_losses + neg_lossesloss.backward()optimizer.step()print('Epoch: {:04d}'.format(epoch + 1),'loss_train: {:.4f}'.format(loss.item()),'time: {:.4f}s'.format(time.time() - t))torch.save(model, os.path.join(cfg.save_model_dir, 'latest.pth')) # 模型保存print('Embedding dim : ({},{})'.format(model.embeddings.weight.shape[0],model.embeddings.weight.shape[1]))def infer(self):# Create Test Processing_, networkx_data = load_cora_data()adj_matrix = torch.tensor(nx.adjacency_matrix(networkx_data).toarray(), dtype=torch.float32)model_path = os.path.join(cfg.save_model_dir, 'latest.pth')model = torch.load(model_path, map_location=torch.device(cfg.device))model.eval()_, networkx_data = load_cora_data()pos_u, pos_v, neg_u, neg_v = generate_pairs(adj_matrix)pos_u = pos_u.to(cfg.device)pos_v = pos_v.to(cfg.device)neg_v = neg_v.to(cfg.device)pos_scores, neg_scores = model(pos_u, pos_v, neg_v)pos_losses = cfg.criterion(pos_scores, torch.ones(len(pos_scores)).to(cfg.device))neg_losses = cfg.criterion(neg_scores, torch.zeros(len(neg_scores)).to(cfg.device))loss = pos_losses + neg_lossesprint("Test set results:","loss= {:.4f}".format(loss.item()),'Embedding dim : ({},{})'.format(model.embeddings.weight.shape[0], model.embeddings.weight.shape[1]))if __name__ == '__main__':mygraph = LINE_run()if cfg.istrain == True:mygraph.train()if cfg.istest == True:mygraph.infer()三、输出结果
跑的是Cora数据,共2708个Node,设置的Embedding维度是128维。上面代码运行完就是长下面这个样子。
Epoch: 0001 loss_train: 1.3863 time: 3.0867s
Epoch: 0002 loss_train: 1.3832 time: 3.7739s
Epoch: 0003 loss_train: 1.3768 time: 4.4471s
...
Epoch: 0028 loss_train: 0.7739 time: 21.3568s
Epoch: 0029 loss_train: 0.7694 time: 22.0310s
Epoch: 0030 loss_train: 0.7663 time: 22.7042s
Embedding dim : (2708,128)
Test set results: loss= 0.7609 Embedding dim : (2708,128)
效果未知,没有用下游聚类测一下,反正看起来BCE loss是降了哈哈,这期就到这里。