基于movie lens-100k数据集的协同过滤算法实现
数据集处理
基于用户的协同过滤算法的实现
基于物品的协同过滤算法的实现
数据集处理
import pandas as pdu_data = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.data')
u_genre = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.genre')
u_info = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.info')
# u_item = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.item')
u_occupation = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.occupation')
# u_user = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.user')
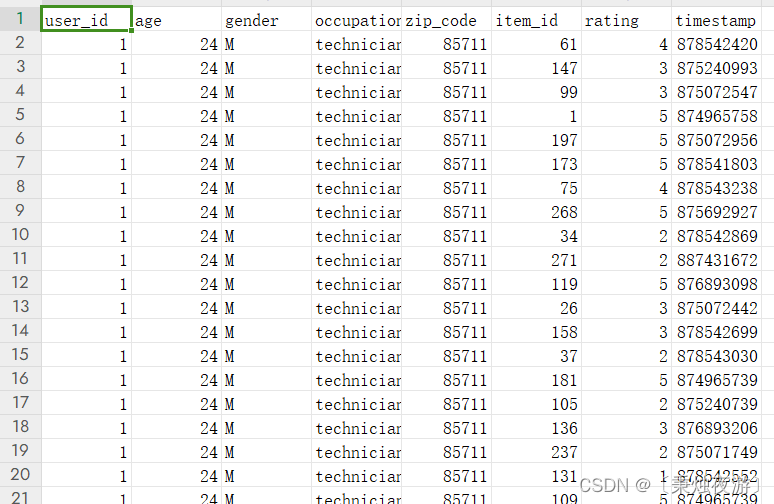
u_user = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.user', encoding='GBK', sep='|', names=['user_id', 'age', 'gender', 'occupation', 'zip_code'])# 加载评分数据集
u_ratings = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u.data', sep='\t', names=['user_id', 'item_id', 'rating', 'timestamp'])# 合并用户信息(u_user)和评分信息(u_ratings)
u_result = pd.merge(u_user, u_ratings, on='user_id')# 保存结果到u_result.csv文件
u_result.to_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u_result_text1.csv', index=False)u_result_sorted = u_result.sort_values(by='user_id')# 保存结果到 u_result_sorted.csv 文件
u_result_sorted.to_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u_result_sorted.csv', index=False)文件结构
基于用户的协同过滤算法的实现
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 加载处理好的文件
u_result = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u_result_text1.csv')# 构件用户-物品评分矩阵
ratings_matrix = u_result.pivot_table(index='user_id', columns='item_id', values='rating').fillna(0)
print("评分矩阵:", ratings_matrix)# 计算用户之间的相似度
user_similarity = cosine_similarity(ratings_matrix)
print("用户之间的相似度矩阵:", user_similarity)
rows = user_similarity.shape[0]
columns = user_similarity.shape[1]
print("矩阵的行数为:", rows)
print("矩阵的列数为:", columns)
def generate_recommendations(ratings_matrix, user_similarity, user_id, k, min_rating_threshold):# 找到目标用户已经评分的物品rated_items = ratings_matrix.loc[user_id]# 找到与目标用户相似度最高的k个邻居用户similarities = list(enumerate(user_similarity[user_id]))similarities.sort(key=lambda x: x[1], reverse=True)neighbors = [x[0] for x in similarities[1:k + 1]]print("邻居用户:", neighbors)# 汇总邻居用户的评分记录neighbor_ratings = ratings_matrix.loc[neighbors]# 根据邻居用户的评分记录和预测评分公式生成推荐列表recommendations = []for item_id, rating in neighbor_ratings.items():if rated_items[item_id] == 0: # 只考虑目标用户未评分过的物品prediction = predict_rating(neighbor_ratings, user_similarity, user_id, item_id, k)if prediction > min_rating_threshold: # 添加阈值条件recommendations.append((item_id, prediction))# print("第一次打印:", recommendations)recommendations.sort(key=lambda x: x[1], reverse=True) # 按照预测评分降序排序return recommendations# 预测评分公式
def predict_rating(ratings_matrix, user_similarity, user_id, item_id, k):numerator = 0 # 分子denominator = 0 # 分母# 找到与目标用户相似度最高的k个邻居用户similarities = list(enumerate(user_similarity[user_id]))similarities.sort(key=lambda x: x[1], reverse=True)neighbors = [x[0] for x in similarities[1:k + 1]]for neighbor in neighbors:similarity = user_similarity[user_id][neighbor]rating = ratings_matrix.loc[neighbor, item_id]numerator += similarity * ratingdenominator += similarityif denominator != 0:prediction = numerator / denominatorelse:prediction = 0return predictionuser_id = 98 # 目标用户ID
k = 3 # 邻居数量
min_rating_threshold = 4.0 # 最小预测评分阈值recommendations = generate_recommendations(ratings_matrix, user_similarity, user_id, k, min_rating_threshold)
# print("预测物品列表:")
print(recommendations)
基于物品的协同过滤算法的实现
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity# 加载处理好的文件
u_result = pd.read_csv('D:/PyCharmWorkSpace/ml-100k/ml-100k/u_result_text1.csv')
# 构件物品-用户评分矩阵
ratings_matrix = u_result.pivot_table(index='item_id', columns='user_id', values='rating').fillna(0)
print("评分矩阵:", ratings_matrix)
# 计算物品之间的相似度
item_similarity = cosine_similarity(ratings_matrix)
print("物品之间的相似度矩阵:", item_similarity)def generate_recommendations(ratings_matrix, item_similarity, user_id, k, min_rating_threshold):# 找到目标用户已经评分的物品rated_items = ratings_matrix.transpose().loc[user_id]# 找到与目标物品相似度最高的k个邻居物品similarities = list(enumerate(item_similarity[user_id]))similarities.sort(key=lambda x: x[1], reverse=True)neighbors = [x[0] for x in similarities[1:k + 1]]print("邻居物品:", neighbors)# 根据邻居物品的评分记录和预测评分公式生成推荐列表recommendations = []for neighbor in neighbors:neighbor_ratings = ratings_matrix[neighbor]for user, rating in neighbor_ratings.items():if rated_items[user] == 0: # 只考虑目标用户未评分过的物品prediction = predict_rating(ratings_matrix, item_similarity, user, neighbor, k)if prediction > min_rating_threshold: # 添加阈值条件recommendations.append((user, prediction))recommendations.sort(key=lambda x: x[1], reverse=True) # 按照预测评分降序排序return recommendations# 预测评分公式
def predict_rating(ratings_matrix, item_similarity, user_id, item_id, k):numerator = 0 # 分子denominator = 0 # 分母# 找到与目标物品相似度最高的k个邻居物品similarities = list(enumerate(item_similarity[item_id]))similarities.sort(key=lambda x: x[1], reverse=True)neighbors = [x[0] for x in similarities[1:k + 1]]for neighbor in neighbors:similarity = item_similarity[item_id][neighbor]rating = ratings_matrix[neighbor][user_id]numerator += similarity * ratingdenominator += similarityif denominator != 0:prediction = numerator / denominatorelse:prediction = 0return prediction
user_id = 98 # 目标用户ID
k = 3 # 邻居数量
min_rating_threshold = 3.3 # 最小预测评分阈值
recommendations = generate_recommendations(ratings_matrix, item_similarity, user_id, k, min_rating_threshold)
print(recommendations)