背景
很多公司还是用excel去管理测试用例的,所以为了减少重复繁琐的导出导出工作,学会如何用代码操作excel表格很实用~
1、读取excel文件基本步骤
1、操作excel的一些库
1、xlrd:读取库,xlwt:写入,现在基本不用,因为只能处理.xls这种格式的数据
2、使用openpyxl库:不支持的 .xls格式,支持的格式:.xlsx、.xlsm、.xltx、.xltm,可以将.xls 转化为 xlsx格式
- 安装openpyxl,使用 pip install openpyxl
- 导入:import | from openpyxl import xxx
2、读取的步骤
1、读取单元格数据
- 获取表格的工作簿对象(用到 openpyxl中的load_workbook模块)
- 得到表单,通过sheet名称 — sheet
- 获取单元格 — cell
- 获取单元格数据 — cell.value
实战演练:
excel表格如下:
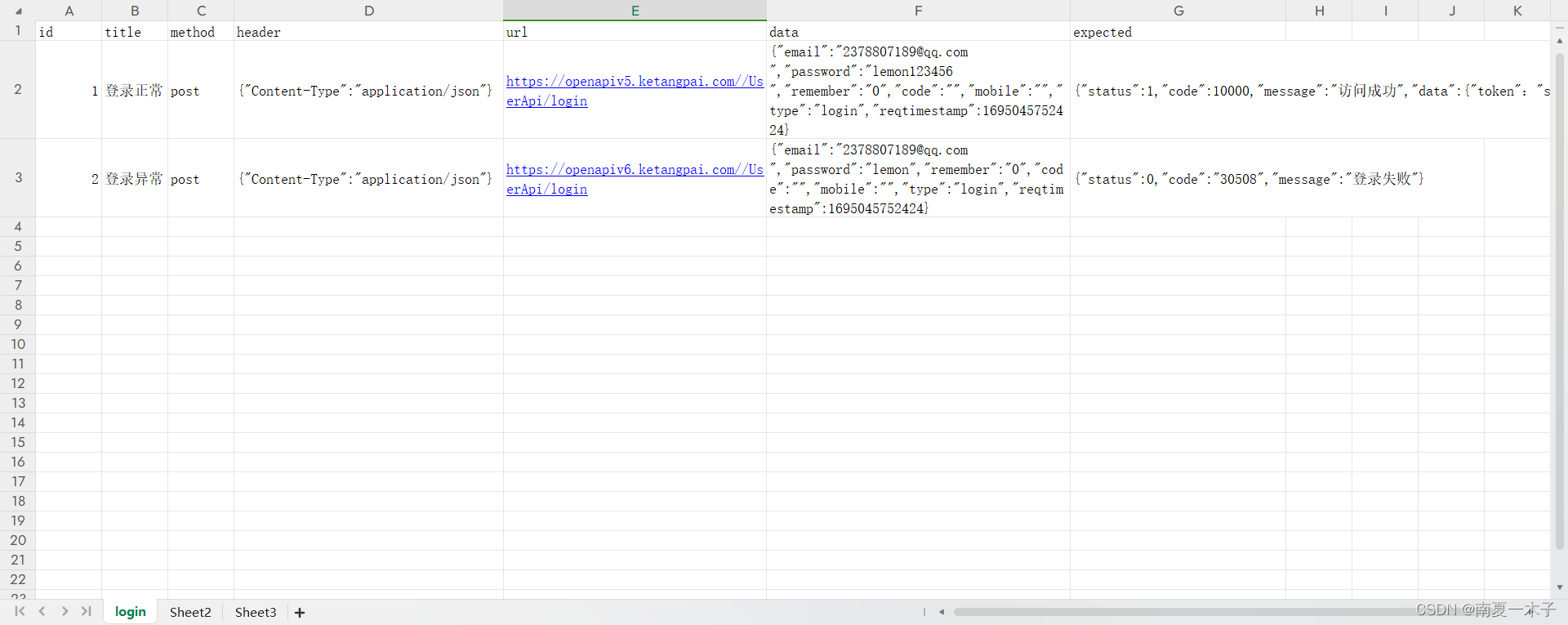
代码实战:
from openpyxl import load_workbook
import pathlib# 获取excel的相对路径
cur_path = pathlib.Path(__file__).absolute()
excel_path = cur_path.parent/"testcase64.xlsx"# 第一步,获取表格的工作簿对象
wb = load_workbook(excel_path)
print(wb) # <openpyxl.workbook.workbook.Workbook object at 0x03EFCD60># 第二步,得到表单——sheet
sheet = wb["login"]
print(sheet)# 第三步,获取单元格数据
cell = sheet.cell(row=1,column=3)
print(cell)# 第四步,获取单元格数据 -- value
cell_value = sheet.cell(row=2,column=2).value
print(cell_value) # 输出:登录正常# 获取表单中所有的数据 -- 转化为列表
# 因为 sheet.values的输出是“<generator object Worksheet.values at 0x03817840” > 就是一个生成器,可以转化为列表的形式
datas = list(sheet.values)
print(datas) # 是一个列表,每一个数据都是元组
'''
[
('id', 'title', 'method', 'header', 'url', 'data', 'expected'),
(1, '登录正常', 'post', '{"Content-Type":"application/json"}', 'https://openapiv5.ketangpai.com//UserApi/login', '{"email":"2378807189@qq.com ","password":"lemon123456 ","remember":"0","code":"","mobile":"","type":"login","reqtimestamp":1695045752424}', '{"status":1,"code":10000,"message":"访问成功","data":{"token":"skjdaskjhd"}'),
(2, '登录异常', 'post', '{"Content-Type":"application/json"}', 'https://openapiv6.ketangpai.com//UserApi/login', '{"email":"2378807189@qq.com ","password":"lemon","remember":"0","code":"","mobile":"","type":"login","reqtimestamp":1695045752424}', '{"status":0,"code":"30508","message":"登录失败"}')
]
''''''
全部读取的数据转化为项目里需要的格式数据
'''
# 第一步,取出标题
title = datas[0]# 第二步,再一次获取后续的每一行数据,跟title压缩成字典
case_list = []
for case in datas[1:]:case_dict = dict(zip(title,case))case_list.append(case_dict)
print(case_list)# 通过列表推导式来遍历
case_list1 = []
case_list1 = [case_list1.append(dict(zip(title,case))) for case in datas]
print(case_list)2、读取excel文件的优化
优化思路,代码分层思想:按照不同的功能代码进行不同包的管理(自动化框架的结构):
- 工具层:tools/common/util,封装好的公共方法,类同于Jmeter里的函数助手,比如对excel读取数据的处理过程
- 测试数据层:data/testdata,放测试数据,例如:txt文件、excel表格等
- 测试用例层:主要维护用例(pytest框架主要做的事情)
- 测试结果输出:如 测试报告、测试日志
- 入口文件:main.py、run.py一般放在最外层
优化实战:
1、按照分层思想,新建data层和tools层,并完善其中的文件,参考如下图片:
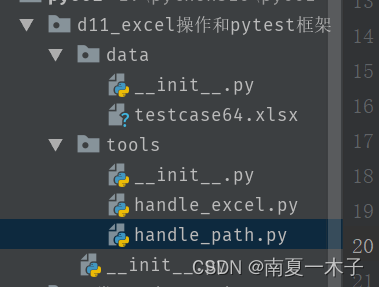
2、将获取excel_path和获取数据的方式分别写到handle_excel文件和handle_path两个文件中,如下:
'''handle_excel文件
'''
from openpyxl import load_workbook
from d11_excel操作和pytest框架.tools.handle_path import exce_pathdef read_excel(filename, sheet)wb = load_workbook(filename)sheet = wb[sheet]datas_list = list(sheet.values)title = datas_list[0]list_case = []for case in datas_list[1:]:tep_dict = dict(zip(title,case))list_case.append(tep_dict)return list_case'''
handle_path.py
'''
import pathlibcur_path = pathlib.Path(__file__).absolute()
exce_path = cur_path.parent.parent/"data"/"testcase64.xlsx"if __name__ == '__main__':print(exce_path)3、一些扩展(如何快速查看excel表格中的数据类型)
可以通过debug的方式,看到我们从excel中读取的数据的类型,举例如下:

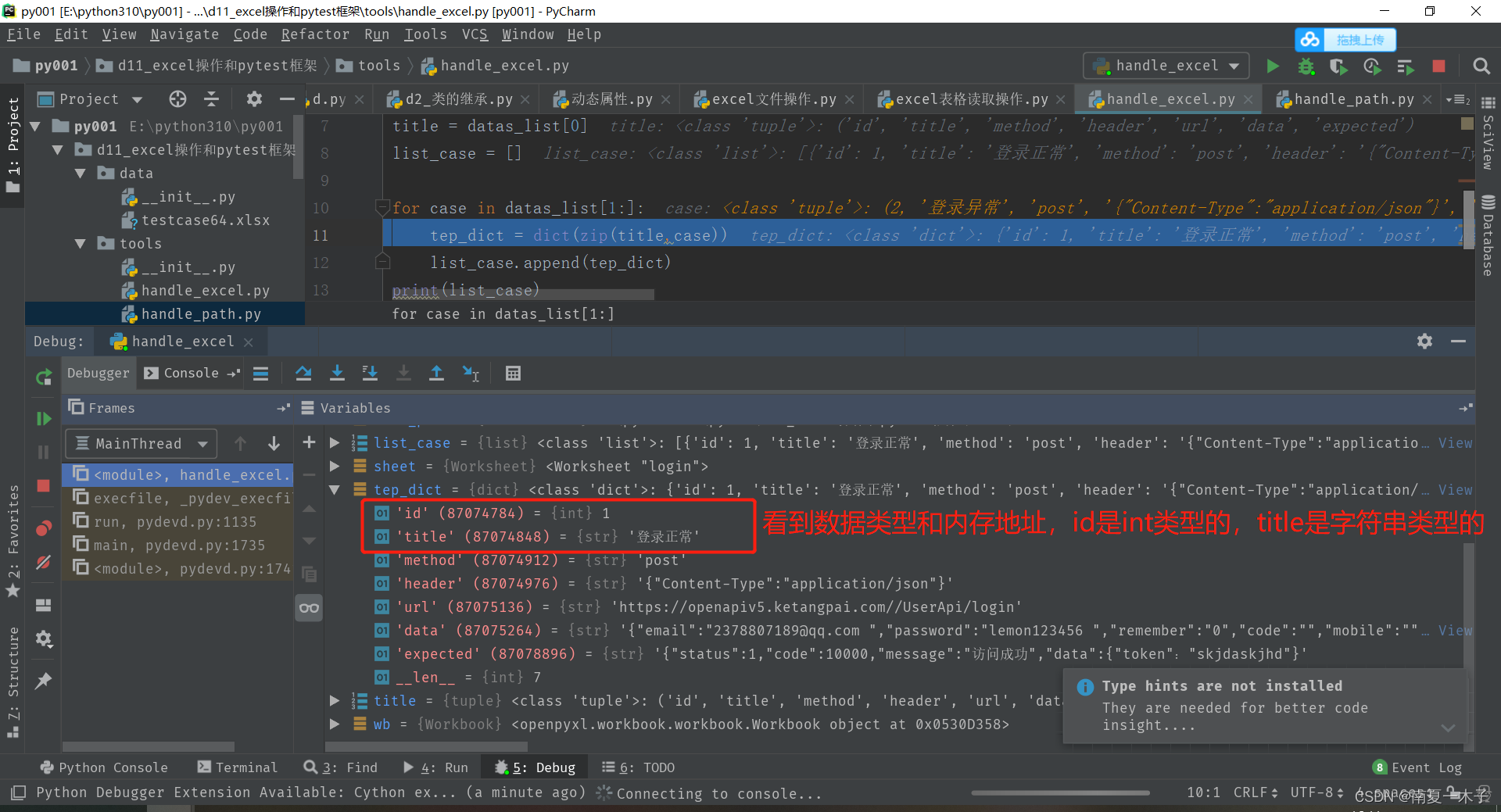










![[设计模式] 浅谈SOLID设计原则](https://img-blog.csdnimg.cn/f845bb46162944a4b7f3f8e7292cf2aa.png)