一 zset的作用以及结构
1.1 zset作用
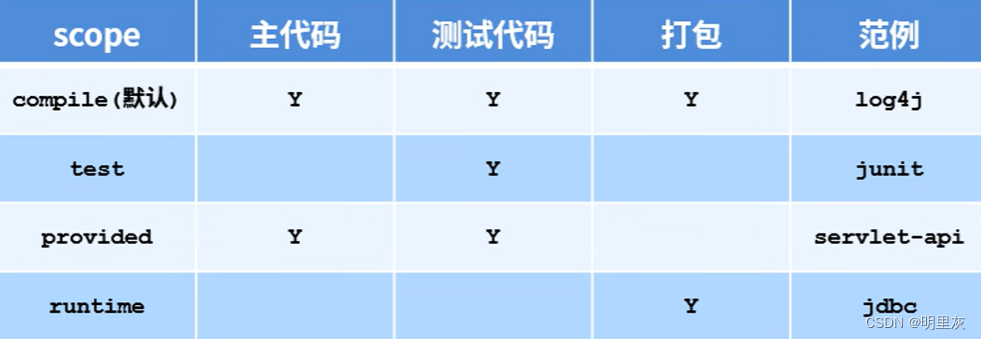
redis的zset是一个有序的集合,和普通集合set非常相似,是一个没有重复元素的字符串集合。常用作排行榜等功能,以用户 id 为 value,关注时间或者分数作为 score 进行排序。
1.2 zset的底层结构
1.zset是一个特别的数据结构,一方面它等价于 Java 的数据结构 Map<String, Double>,可以给每一个元素 value 赋予一个权重 score,另一方面它又类似于 TreeSet,内部的元素会按照权重 score 进行排序,可以得到每个元素的名次,还可以通过 score 的范围来获取元素的列表。
2.zset 底层使用了两个数据结构:
hash,hash 的作用就是关联元素 value 和权重 score,保障元素 value 的唯一性,可以通过元素 value 找到相应的 score 值。
跳跃表,跳跃表的目的在于给元素 value 排序,根据 score 的范围获取元素列表。
https://blog.51cto.com/u_14191/6345603
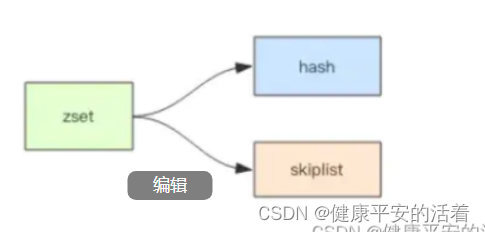
ZSet 有两种不同的实现,分别是 ziplist 和 skiplist。具体使用哪种结构进行存储,规则如下:
1.ziplist:满足以下两个条件:
[value,score]键值对数量少于128个;每个元素的长度小于64字节。

2.skiplist:不满足以上两个条件时使用skiplist跳表,组合了hash和skiplist
hash用来存储value到score的映射,在时间复杂度o(1)时间内知道对应value的分数。
skiplist按照从小到大的顺序存储分数;每个元素存储的都是<value,score>对。
1.3 zset的api接口
zrevrange key start stop [WITHSCORES]----------------返回按score从大到小排序后且索引在[start,stop]区间的元素,从0开始
zrevrangebyscore key max min[WITHSCORES]------------------返回按score从大到小排序后且分数在[min,max]区间的元素
zrangebylex key min max[LIMIT offset count]--------------通过字典区间返回有序集合的成员
zrank key member-------------返回元素member的索引,不存在nil
zrevrank key member--------------返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序
zscore key member---------------返回有序集合中,元素member分数
zscan key cursor [MATCH pattern] [COUNT count]-------------迭代有序集合中的元素(包括元素的分值)
zunionstore destination numkeys key [key …]-------------计算给定的一个或多个有序集的并集,并存储在新的 key 中
zinterstore destination numkeys key [key …]--------------计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中
zincrby key increment member-----------有序集合中对指定元素的分数加上增量 increment
zrem key member[member…]-----------移除有序集合中的一个或多个元素
zremrangebylex key min max-----------移除有序集合中给定的字典区间的所有成员
zremrangebyrank key start stop---------移除有序集合中给定的排名区间的所有成员
zremrangebyscore key min max-------移除有序集合中给定的分数区间的所有成员
https://blog.51cto.com/u_14191/6345603
二 跳跃表
2.1 跳跃表
跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其它节点的指针,从而达到快速访问节点的目的。链表加多级索引的的结构,就是跳跃表。
数组支持随机访问的线性结构,底层使用二分查找。链表不支持随机访问的线性结构。跳跃表中查询任意数据的时间复杂度就是 O(logn)
2.2 跳跃表分析
1.对于一个单链表来讲,即便链表中存储的数据是有序的,如果我们要想在其中查找某个数据,也只能从头到尾遍历链表。这样查找效率就会很低,时间复杂度会很高,是 O(n)。

2.在该链表中,每隔一个节点就有一个附加的指向它在表中前两个位置上的节点的链,正因为如此,在最坏的情形下,最多考察 n/2 + 1 个节点。比如我们要查 90 这个节点,按照之前单链表的查找的话要 8 个节点,现在只需 5 个节点。

3.这里每隔 4 个节点就有一个链接到该节点前方的下一个第 4 节点的链,只有 n/4 + 1 个节点被考察。
我们利用数学的思想,针对通用性做扩展。每隔第 2^i 个节点就有一个链接到这个节点前方下一个第 2^i 个节点链。链的总个数仅仅是加倍,但现在在一次查找中最多只考察 logn 个节点。不难看到一次查找的总时间消耗为 O(logn),这是因为查找由向前到一个新的节点或者在同一节点下降到低一级的链组成。在一次查找期间每一步总的时间消耗最多为 O(logn)。注意,在这种数据结构中的查找基本上是折半查找(Binary Search)。
2.3 跳跃表底层结构
Redis 的跳跃表是由 redis.h/zskiplistNode 和 redis.h/zskiplist 两个结构定义,其中 zskiplistNode 用于表示跳跃节点,而 zskiplist 结构则用于保存跳跃表节点的相关信息,比如节点的数量以及指向表头节点和表尾节点的指针等等。

上图最左边的是 zskiplist 结构,该结构包含以下属性:
-
header:指向跳跃表的表头节点
-
tail:指向跳跃表的表尾节点
-
level:记录目前跳跃表内,层数最大的那个节点层数(表头节点的层数不计算在内)
-
length:记录跳跃表的长度,也就是跳跃表目前包含节点的数量(表头节点不计算在内)
位于 zskiplist 结构右侧是四个 zskiplistNode 结构,该结构包含以下属性:
-
层(level):节点中用 L1、L2、L3 等字样标记节点的各个层,L1 代表第一层,L2 代表第二层,以此类推。每个层都带有两个属性:前进指针和跨度。前进指针用于访问位于表尾方向的其它节点,而跨度则记录了前进指针所指向节点和当前节点的距离。
-
后退(backward)指针:节点中用 BW 字样标识节点的后退指针,它指向位于当前节点的前一个节点。后退指针在程序从表尾向表头遍历时使用。
-
分值(score):各个节点中的 1.0、2.0 和 3.0 是节点所保存的分值。在跳跃表中,节点按各自所保存的分值从小到大排列。
-
成员对象(obj):各个节点中的 o1、o2 和 o3 是节点所保存的成员对象。
2.4 平衡树,跳跃表,hash之间的比较

Redis中ZSet的底层数据结构跳跃表skiplist,你真的了解吗?