📝个人主页:夏目浅石.
📌博客专栏:C++的故事
🏠学习社区:夏目友人帐.
文章目录
- 前言
- Ⅰ. 函数重载
- 0x00 重载规则
- 0x01 函数重载的原理名字修饰
- Ⅱ. 引用
- 0x00 引用的概念
- 0x01 引用和指针区分
- 0x03 引用的本质
- 0x04 引用的特性
- 0x05 引用的使用场景
- 0x06 常引用
- 0x07 指针和引用区别
- Ⅲ. 结语
前言
亲爱的夏目友人帐的小伙伴们,今天我们继续讲解 C++ 入门的知识 函数重载 和 引用 这里的知识虽然入门,但是却是你后面更加深入学习 C++ 知识的钥匙,所以请跟着夏目学长一起进入 C++ 的世界吧!
Ⅰ. 函数重载
函数重载的定义:
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型不同的问题。
我们都知道 C++ 是对 C语言的 “升级版” 所以不难想到:函数重载就是对 C语言 的扩展知识,C语言当中是不允许函数名字是相同的,如果出现则 就会报错,而在 C++ 却是可以的。
0x00 重载规则
如果一个函数想要满足函数重载,则需要满足重载规则(其中一个):
- 参数类型不同
- 参数个数不同
- 参数类型顺序不同
而对于 C++ 函数重载 即 函数名字 相同 是可以存在的。
下面根据上面的三个规则给出具体的例子。
// 参数类型不同
int add(int left , int right)
{return left + right;
}int add(double left , double right)
{return left + right;
}// 参数个数不同
int add(double left , double right , int mid)
{return left + right;
}// 参数类型顺序不同
int add(int left , int right)
{return left + right;
}char add(char right , char left)
{return left + right;
}值得注意的是 :函数重载需要在同一块命名空间
因为函数重载是根据类型识别的,所以对于相同类型的数据,顺序不同,不构成函数重载,而且编译器无法识别:
// 错误样例 不构成重载
int add(int left , int right)
{return left + right;
}int add(int right , int left)
{return left + right;
}
0x01 函数重载的原理名字修饰
为什么C++支持函数重载,而C语言不支持函数重载呢?
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。
从汇编角度来讲:调用函数处会变成 call + add(地址) 的形式,然后通过汇编指令完成调用。
所以对于C语言来说,就是依靠函数名去找函数的,如果函数名相同,则会冲突,因为不知道找哪个函数.
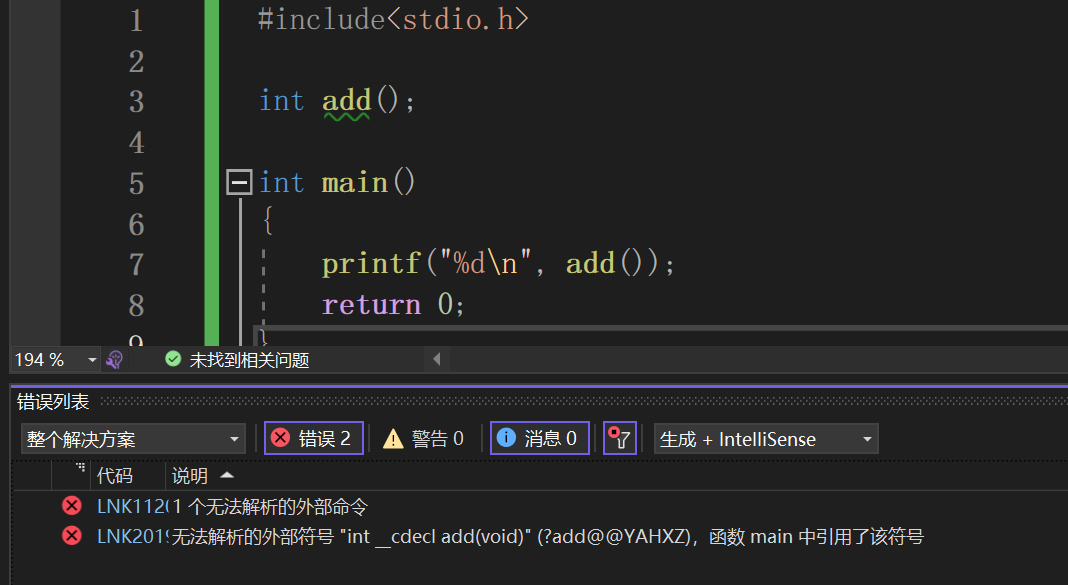
对于C++来说,不同平台就有不同的修饰规则,对于 vs 上比较复杂 所以退而求其次,这里我们讲 Linux 上的:
int add(int left, int right)
{return left + right;
}
对于这个函数,就会被修饰为 _Z3addii
我想这里你肯定看不懂,所以我先给你讲解一下Linux系统下修饰的规则:
Linux 下修饰规则—格式 : _ Z + 函数名称长度 + 函数名 + 类型首字母
下面是验证的例子:
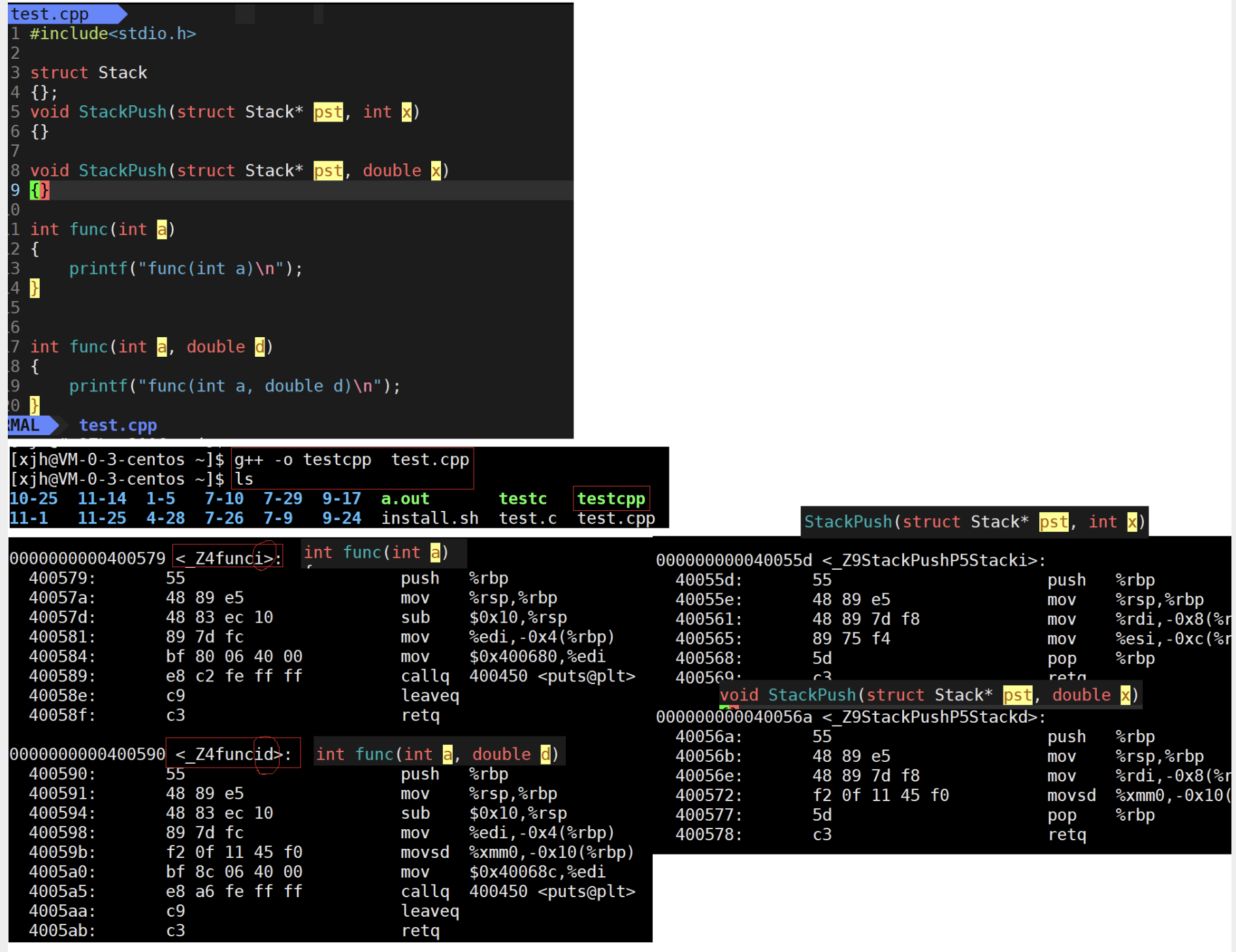
对于相同名字的函数,函数重载就根据参数的类型,顺序,个数,以这些为基准,来区别不同的函数。
而根据上面的验证,我们也知道为什么 返回值不同 和 参数类型相同但顺序不同 为什么不能构成函数重载的原因:
因为对于 参数类型相同但顺序不同,形成的后缀还是一样的 ,并不能区分该调用哪个函数;而对于返回值不同的其他都相同的函数来说,则是因为分不清调用哪个函数,不仅仅是因为函数返回值不在修饰规则内。
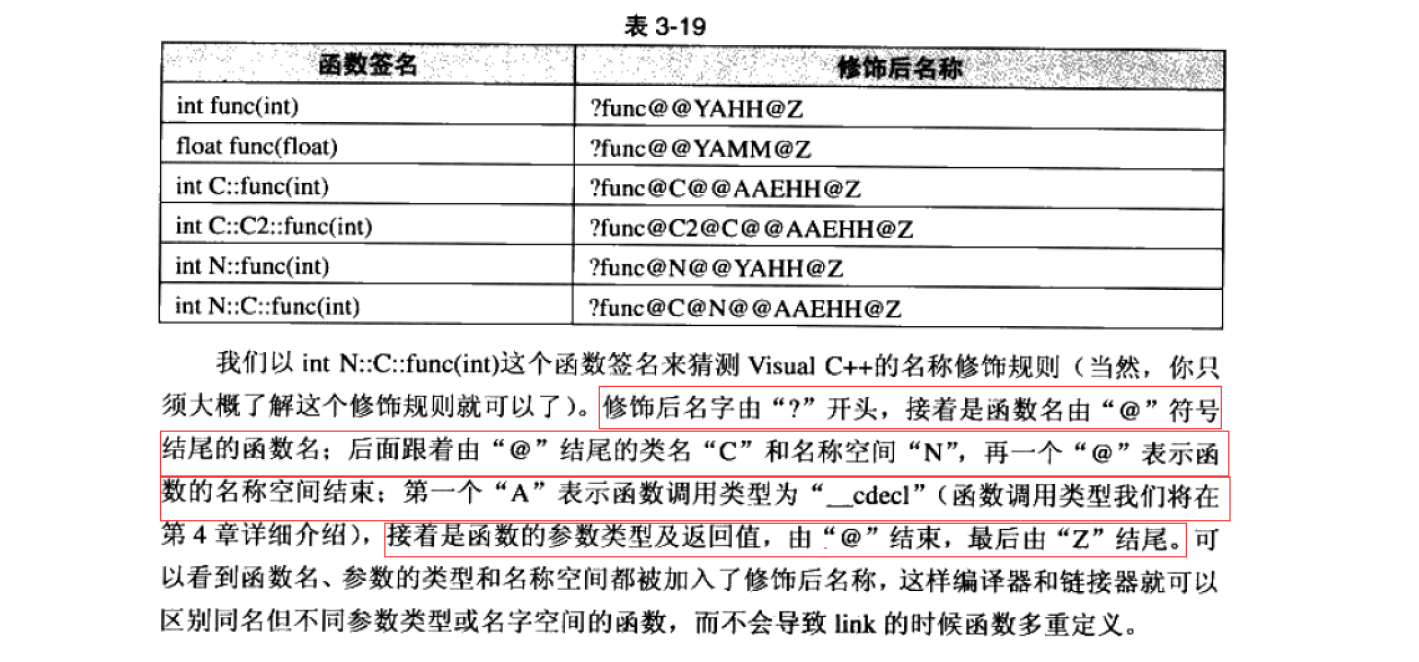
Windows 下修饰规则(简单了解):
Ⅱ. 引用
0x00 引用的概念
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
通俗来讲:别名,又可以说是外号,代称,比如水浒传里几乎是别名最多的地方。李逵,在家称为"铁牛",江湖上人称"黑旋风"。铁牛和黑旋风就是李逵的别名。
#include<iostream>using namespace std;int main()
{int a = 10;int& b = a;// b是a的引用cout << a << endl;cout << b << endl;return 0;
}
0x01 引用和指针区分
我们在学习 C语言 的时候知道 & 是 取地址的意思,所以在这里要给大家讲讲 & 的含义。
& 就是引用,但是& 这个操作符和取地址 & 操作符是重叠的。
所以它们需要不同的场景规范:
当 &b 单独存在时,这时就代表取地址,为取出变量的地址。
但是如果这样:
#include<iostream>using namespace std;int main()
{int a = 10;int& b = a; //引用int* ptr = &a; // 取地址return 0;
}
0x03 引用的本质
我们可以打开调试窗口进行查看a和b的地址和值:
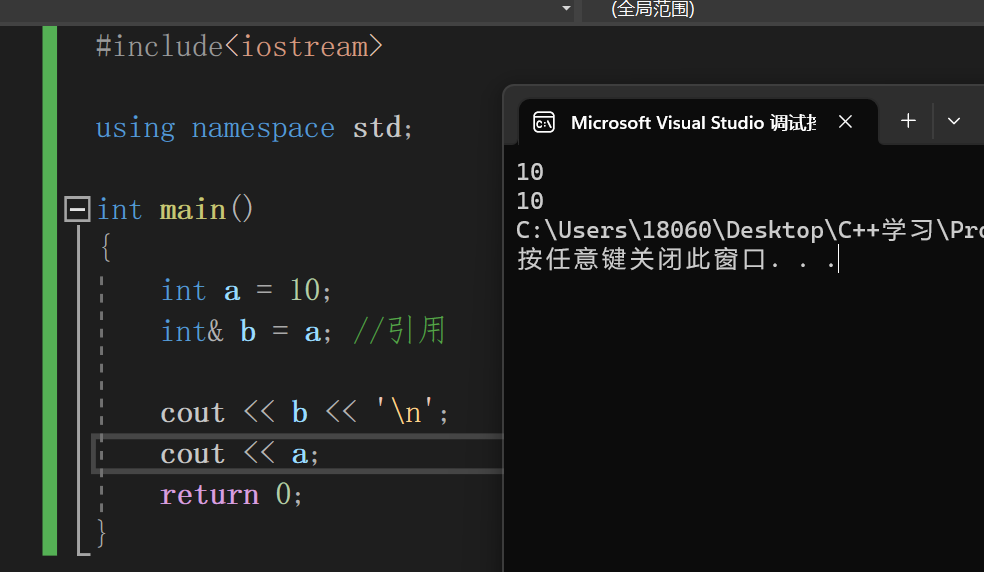
我们发现a和b不仅值相等,连地址也是相同的。而这就说明,b 就是 a ,在语法层面上,这里 b 并不是开辟的新空间,而是对原来的 a 取了一个新名称,叫做 b 。
就好比李逵被叫做黑旋风一样,李逵还是李逵,黑旋风也是它;而 a 就是 a ,但是 b 也是 a 。
而如果这时候对 a 或 b 任意一个修改,那么 a 和 b 都会发生修改。
#include<iostream>using namespace std;int main()
{int a = 10;int& b = a; //引用b = 20;cout << b << endl;cout << a << endl;return 0;
}

0x04 引用的特性
1. 引用在定义时必须初始化
// 错误样例
int main()
{int a = 10;int& b;return 0;
}

引用是取别名,所以在定义的时候必须明确是谁的别名。
2. 一个变量可以有多个引用
一个变量也可以有多个别名。
int main()
{int a = 10;int& b = a;int& c = a;int& d = a;return 0;
}
而对于一个起过别名的变量,对它的别名取别名也是可以的。
就好比说有人可能知道李逵也叫铁牛,并不知道他真实姓名,但是他觉得李逵很黑,于是叫他黑旋风,这也没问题,因为这里描述的都是一个人,同理,描述的也是同一个变量。
int main()
{int a = 10;int& b = a;int& c = b;int& d = c;return 0;
}
3. 引用一旦引用一个实体,就不能引用其他实体
int main()
{int a = 10;int& b = a; // 引用int c = 20;b = c;// 赋值操作return 0;
}
引用一旦引用一个实体,就不能引用其他实体,引用是不会发生改变的。
但是对于指针,则是截然不同的:
int main()
{int a = 10;int c = 20;int* p = &a;p = &c;return 0;
}
对于指针来说,指针可以时刻修改:
p原本指向 a , 现在指向 c
但是引用也有局限性,因为引用之后的变量是不可修改引用的,比如链表,节点是要不断更替迭代的,所以还需要指针配合,C++才可以写出一个链表。
0x05 引用的使用场景
1. 做参数
我们知道实参的改变不影响实参,所以这种写法并不能改变值,因为此刻是 传值调用 :
#include<iostream>using namespace std;void Swap(int x,int y)
{int tmp = x;x = y;y = tmp;
}int main()
{int a = 10;int b = 20;cout << "a = " << a << " " << "b = " << b << endl;Swap(a,b);cout << "a = " << a << " " << "b = " << b << endl;return 0;
}
使用引用修改后:
#include<iostream>using namespace std;void Swap(int& x,int& y)
{int tmp = x;x = y;y = tmp;
}int main()
{int a = 10;int b = 20;cout << "a = " << a << " " << "b = " << b << endl;Swap(a,b);cout << "a = " << a << " " << "b = " << b << endl;return 0;
}
x 和 y 分别是 a 和 b 的引用,对 x 和 y 进行修改,就是对 a 和 b 进行修改,所以值也被修改成功了。
它们的地址是完全相同的。而这里这里既不是传值调用,也不是传址调用,而是 传引用调用 。
思考:上面三个函数是否构成函数重载? 构成,但无法调用。
根据函数名修饰规则,传值和传引用的是不一样的,比如会加上 R 做区分。
但是不能同时调用传值和传引用,因为有歧义,因为 调用不明确 ,编译器并不知道调用哪个:
#include<iostream>using namespace std;void Swap(int& x,int& y)
{int tmp = x;x = y;y = tmp;
}void Swap(int x,int y)
{int tmp = x;x = y;y = tmp;
}int main()
{int a = 10;int b = 20;cout << "a = " << a << " " << "b = " << b << endl;Swap(a,b);cout << "a = " << a << " " << "b = " << b << endl;return 0;
}
2. 引用解决二级指针生涩难懂的问题
讲单链表时,我们写的由于是没有头结点的链表,所以修改时,需要二级指针,对于指针概念不清晰的小伙伴们可能比较难理解。
但是学了引用,就可以解决这个问题:
结构定义:
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode;原代码:
void SListPushFront(SLTNode** pphead, SLTDateType x)
{SLTNode* newnode = BuyListNode(x);newnode->next = *pphead; *pphead = newnode;
}// 调用
SLTNode* pilst = NULL;
SListPushFront(&plist);
修改后:
void SListPushFront(SLTNode*& pphead, SLTDateType x) // 改
{SLTNode* newnode = BuyListNode(x);newnode->next = *pphead; *pphead = newnode;
}// 调用
SLTNode* pilst = NULL;
SListPushFront(plist); // 改修改之后的代码里的二级指针被替换成了引用。
而这里的意思就是给一级指针取了一个别名,传过来的是plist,而plist 是一个一级指针,所以会出现 * ,而这里就相当于 pphead 是 plist 的别名。而这里修改 pphead ,也就可以对 plist 完成修改。
但是有时候也会这么写 :
结构定义:
typedef struct SListNode
{int data;struct SListNode* next;
}SLTNode, *PSLTNode;这里的意思就是将 struct SListNode* 类型重命名为 PSLTNode 。
void SListPushFront(PSLTNode& pphead, SLTDateType x) // 改
{PSLTNode newnode = BuyListNode(x);newnode->next = pphead; pphead = newnode;
}// 调用
PSLTNode plist = NULL;
SListPushFront(plist);在 typedef 之后,PSLTNode 就是结构体指针,所以传参过去,只需要在形参那边用引用接收,随后进行操作,就可以达成目的。
而形参的改变影响实参的参数叫做输出型参数,对于输出型参数,使用引用十分方便
3.做返回值
//用引用来接收n的引用
#include<iostream>
using namespace std;
int& Count(int x)
{int n = x;n++;// ...return n;
}int main()
{int& ret = Count(10);//随机值cout << ret << endl;Count(20);cout << ret << endl;//随机值return 0;
}
这里打印ret的值是不确定的
如果Count函数结束,栈帧销毁,栈帧没有清理,那么ret的值是侥幸正确的
如果Count函数结束,栈帧销毁,栈帧被清理,那么ret的值是随机值
这里可能是编译器的问题,结果和我们预想的是一样的,但是别的编译器来运行可能就会是随机值
当第一次调用Count函数时返回n的引用。
第二次调用相同的函数,栈帧用的是同一块空间,并且 ret 是 n 的引用的别名,所以出现与传参预期的结果一样,那么当调用其他不同的函数后,那么该栈帧就会被覆盖,则第二次打印ret就会出现随机值了,所以这样使用ret是错误的。
// 正确的做法
#include<iostream>
using namespace std;
int& Count(int x)
{static int n = x;n++;// ...return n;
}int main()
{int& ret = Count(10);cout << ret << endl;Count(20);cout << ret << endl;return 0;
}而这时 static 修饰的静态变量不委屈了:n不会被销毁,所以就不会产生随机值这一错误了
0x06 常引用
以前学习C语言的时候我们知道:const 修饰的是常变量,不可修改。
#include<iostream>
using namespace std;
int main()
{const int a = 10;int& b = a;return 0;
}
a 本身都不能修改,b 为 a 的引用,那么 b 也不可以修改,这样就没意义了。a 是只读,但是引用 b 具有 可读可写 的权利,该情况为 权限放大 ,所以错误了。
这时,只要加 const 修饰 b ,让 b 的权限也只有只读,使得 权限不变 ,就没问题了:
int main()
{const int a = 10;const int& b = a;return 0;
}
而如果原先变量可读可写,但是别名用 const 修饰,也是可以的,这种情况为 权限缩小 :

对于函数的返回值来说,也不能权限放大,例如:
int func()
{static int n = 0;n++;return n;
}int main()
{int& ret = func();// 错误的return 0;
}
这样也是不行的,因为返回方式为 传值返回 ,返回的是临时变量,具有 常性 ,是不可改的;而引用放大了权限,所以是错误的;这时加 const 修饰就没问题:const int& ret = func()
0x07 指针和引用区别
从语法概念上来说,引用是没有开辟空间的,而指针是开辟了空间的,但是从底层实现上来说,则又不一样:
int main()
{int a = 10;int& r = a;r = 20;int* p = &a;*p = 20;return 0;
}其实从汇编上,引用其实是开空间的,并且实现方式和指针一样,引用其实也是用指针实现的。
区别汇总:
- 引用概念上定义一个变量的 别名 ,指针存储一个变量 地址
- 引用 在定义时 必须初始化 ,指针最好初始化 ,但是不初始化也不会报错
- 引用在初始化时引用一个实体后 ,就不能再引用其他实体 ,而指针可以在任何时候指向任何一个同类型
- 没有NULL引用,但有NULL指针
- 在sizeof中含义不同:引用结果为 引用类型的大小,但指针始终是 地址空间所占字节个数 (32位平台下占4个字节)
- 引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 引用比指针使用起来相对更安全
Ⅲ. 结语

📌 [ 笔者 ] 夏目浅石.
📃 [ 更新 ] 2023.9.21
❌ [ 勘误 ] /* 暂无 */
📜 [ 声明 ] 由于作者水平有限,本文有错误和不准确之处在所难免,本人也很想知道这些错误,恳望读者批评指正!
📜 参考文献:
B. 比特科技. C/C++[EB/OL]. 2021[2021.8.31]
 如果侵权,请联系作者夏目浅石,立刻删除
如果侵权,请联系作者夏目浅石,立刻删除