最近在看Deeplab系列的论文,文中提到了语义分割领域的一个难题是:将图片输入网络之前需要resize成统一大小,但是resize的话会造成细节信息的损失,所以想要网络处理任意大小的图片输入。我之前训练的U-net网络都是resize成224*224大小,于是我想实验一下不resize,直接将数据经过Totensor(),归一化之后直接丢进网络,但是确报错了
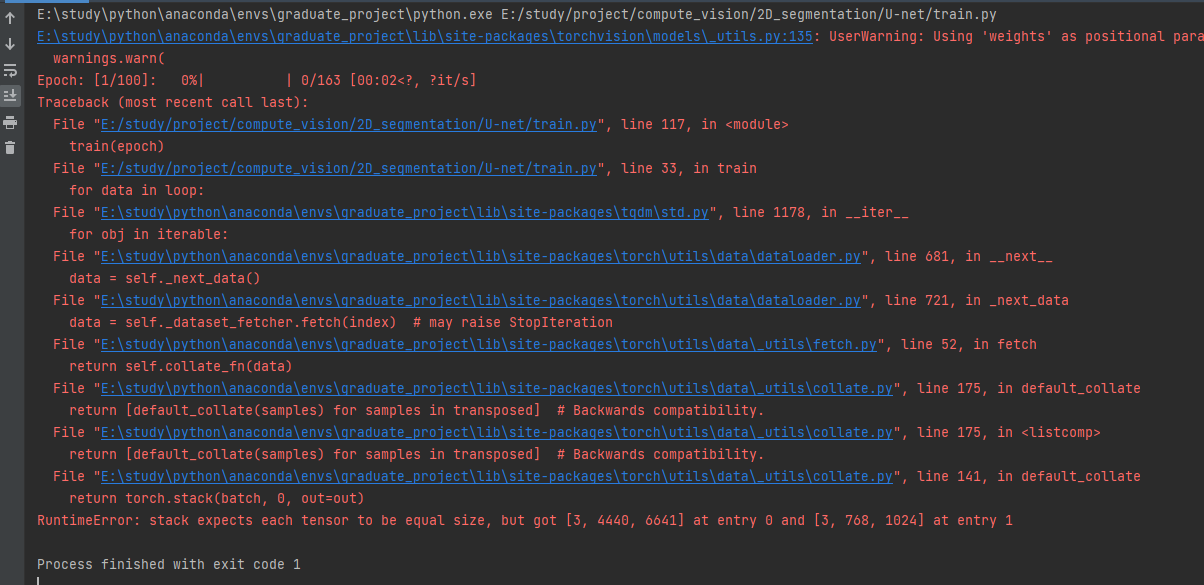
查了一下发现,在Pytorch中
1.DataLoader中的默认collate_fn假设每个样本形状相同,直接堆叠(stack)
2.模型的输入层也通常会假设输入是一个固定形状的tensor
3.很多图像操作函数(如torchvision.transforms)也要求图像形状相同
所以这让我很疑惑,这种处理任意大小的图片在训练过程中该如何实现呢?还是说中只是在test的时候能够处理任意大小的图片就行,因为不需要Dataloader了。
记录一次错误---想让U-net网络输入大小不一致的图片
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.rhkb.cn/news/138766.html
如若内容造成侵权/违法违规/事实不符,请联系长河编程网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
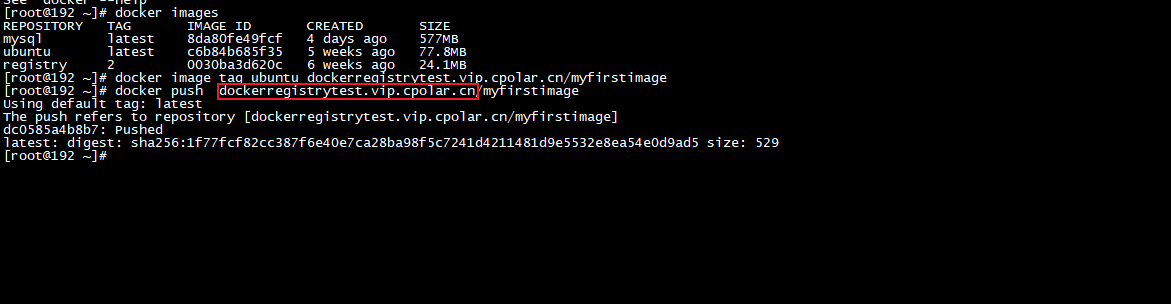
Linux 本地 Docker Registry本地镜像仓库远程连接【内网穿透】
Linux 本地 Docker Registry本地镜像仓库远程连接 文章目录 Linux 本地 Docker Registry本地镜像仓库远程连接1. 部署Docker Registry2. 本地测试推送镜像3. Linux 安装cpolar4. 配置Docker Registry公网访问地址5. 公网远程推送Docker Registry6. 固定Docker Registry公网地址…

【CSS】画个三角形或圆形或环
首先通过调整边框,我们可以发现一些端倪
<!DOCTYPE html>
<html><head><meta charset"utf-8"><title></title></head><style>.box{width: 150px;height:150px;border: 50px solid black;}</style&g…
【docker安装Mysql并配置主从复制】
Mysql主从复制
目的:
是为了后面naocs集群的服务配置做准备工作
准备工作
准备至少两台虚拟机或服务器,安装好了docker,找到他们的ip地址
后面操作都用xshell操作来代替 拉取并启动mysql镜像和容器
主机的命令为mysql01,对…

机器学习笔记:seq2seq attentioned seq2seq
1 Seq2Seq
1.1 介绍
对于序列对<X,Y>,我们的目标是给定输入序列X,期待通过Encoder-Decoder框架来生成目标序列Y Encoder对输入的序列X进行编码,将输入序列通过非线性变换转化为中间语义表示C: Decoder根据序列X的中间语义…
百度知道本地搭建环境无限制采集聚合【最新版】
本工具是本地php环境搭建,根据关键词进行采集聚合某度知道,不限制ip,最新版新添加了违规词过滤,样式处理,自动匹配优质标题等功能,只需要导入关键词可以无限采集,是养站的好帮手! 功…
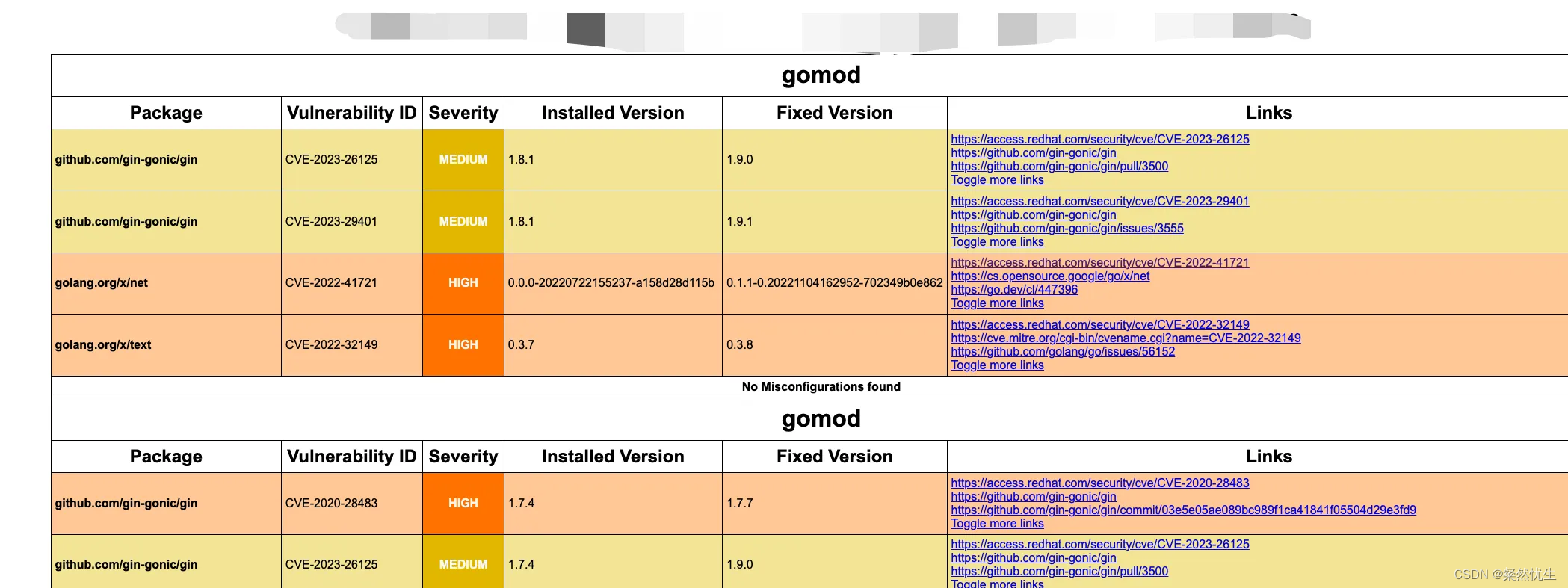
Golang代码漏洞扫描工具介绍——trivy
Golang代码漏洞扫描工具介绍——trivy Golang作为一款近年来最火热的服务端语言之一,深受广大程序员的喜爱,笔者最近也在用,特别是高并发的场景下,golang易用性的优势十分明显,但笔者这次想要介绍的并不是golang本身&a…

2023 Sui Builder House全球之旅圆满收官
2023年的最后一场Builder House于上周在新加坡举行,包括主题演讲、小组讨论和研讨会等聚焦Sui的现在和未来的活动。其中,zkLogin是本次活动的最大亮点。作为一种新的Sui原语,zkLogin允许用户使用Web2身份验证创建帐户,有望推动大规…

产品解读 | 分布式多模数据库:KaiwuDB
1.KaiwuDB 是什么?
KaiwuDB 是由浪潮创新研发的一款分布式、多模融合,支持原生 AI 的数据库产品,拥有“就地计算”等核心技术,具备高速写入、极速查询、SQL 支持、随需压缩、智能预计算、订阅发布、集群部署等特性,具…

Arduino驱动 LCD1602/2004液晶屏转接板模块
目录 一、简介二、内部逻辑图三、引脚说明四、原理图五、器件地址六、使用方法 一、简介 点击图片购买 LCD1602/2004液晶屏转接板模块采用MCP2308芯片,通过IIC接口扩展8路通用双向IO口。可以为较少IO口的单片机扩展IO口,还可以作为LCD1602、LCD2004液晶屏…

北京智和信通亮相2023IT运维大会,共话数智浪潮下自动化运维新生态
2023年9月21日,由IT运维网、《网络安全和信息化》杂志社联合主办的“2023(第十四届)IT运维大会”在北京成功举办。大会以“以数为基 智引未来”为主题,北京智和信通技术有限公司(下文简称:北京智和信通&…
成集云 | 金蝶云星空集成聚水潭ERP(金蝶云星空主管供应链)| 解决方案
源系统成集云目标系统 方案介绍
金蝶云星空是金蝶软件(中国)有限公司研发的新一代战略性企业管理软件,致力于为企业提供端到端的供应链整体解决方案,它可以帮助企业构建敏捷供应链体系,降低供应链成本,提…
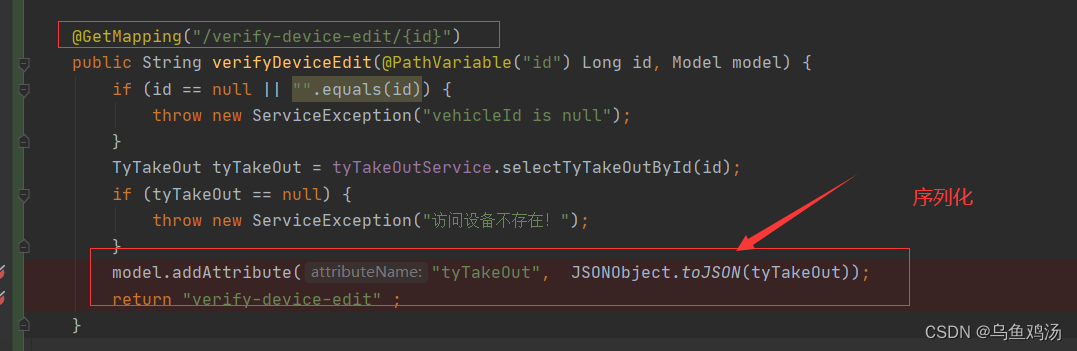
spring boot 时间格式化输出
目录标题 一、spring boot 序列化二、 JsonFormat(pattern "yyyy-MM-dd HH:mm:ss")和JSONField(format "yyyy-MM-dd HH:mm:ss")区别三、在实体类中序列化时间(格式化输出)(一)使用JsonFormat(二…


基于TensorFlow+CNN+协同过滤算法的智能电影推荐系统——深度学习算法应用(含微信小程序、ipynb工程源码)+MovieLens数据集(七)
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 模型训练1)数据集分析2)数据预处理3)模型创建4)模型训练5)获取特征矩阵 2. 后端Django3. 前端微信小程序1)小程序全局配置文件2)…

动力节点老杜JavaWeb笔记(全)
Servlet
关于系统架构 系统架构包括什么形式? C/S架构B/S架构C/S架构? Client / Server(客户端 / 服务器)C/S架构的软件或者说系统有哪些呢? QQ(先去腾讯官网下载一个QQ软件,几十MB,然后把这个客户端软件安装上去,然后输入QQ号以及密码,登录之后,就可以和你的朋友聊…
Vim编辑器使用入门
目录
一、Vim 编辑器基础操作
二、Vim 编辑器进阶操作
三、Vim 编辑器高级操作
四、Vim 编辑器文件操作
五、Vim 编辑器文件管理
六、Vim 编辑器进阶技巧
七、Vim 编辑器增强功能 Vim的三种工作模式 一、Vim 编辑器基础操作
1.移动光标 - 光标的移动控制
移动光标有两…
【云服务器开放端口详细教程~来了】
你不知道我真的会哭 云服务器开放端口详细教程来了 前言 一、常见云服务器端口的认识 ● 云服务器端口一般是指 TCP/IP 协议中的端口,端口号的范围从 0 到 65535,比如用于浏览网页服务的 80 端口,用于 FTP 服务的 21 端口等等。 ● 当一…
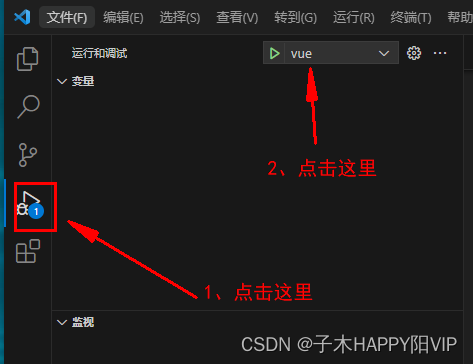
VScode断点调试vue
VScode断点调试vue
1、修改launch.js文件(没有这个文件就新建)。
{// Use IntelliSense to learn about possible attributes.// Hover to view descriptions of existing attributes.// For more information, visit: https://go.microsoft.com/fwlin…
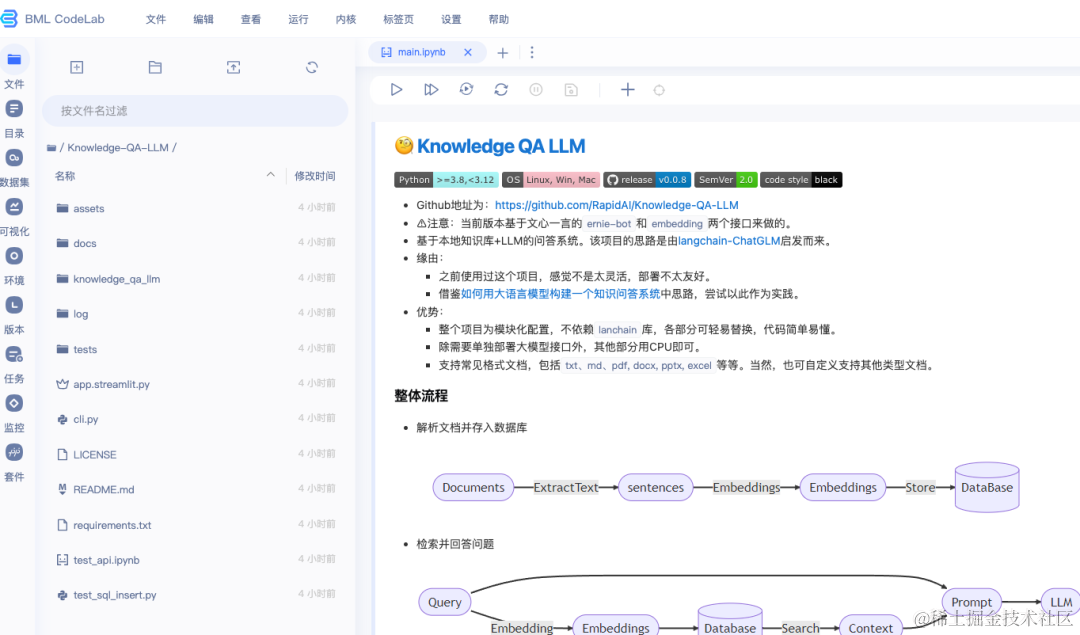
AI Studio星河社区生产力实践:基于文心一言快速搭建知识库问答
还在寻找基于文心一言搭建本地知识库问答的方案吗?AI Studio星河社区带你实战演练(支持私有化部署)!
相信对于大语言模型(LLM)有所涉猎的朋友,对于“老网红”知识库问答不会陌生。自从大模型爆…

猫头虎博主的AI魔法课:一起探索CSDN AI工具集的奥秘!
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…
最新文章
- 外贸企业网站建设方案/google官网入口下载
- 温岭做鞋子的网站/线上宣传方式有哪些
- 西宁哪家网络公司做网站/广东广州疫情最新情况
- 哪些网站做的美剧/合川网站建设
- 哪个网站做任务赚钱多/模板建站常规流程
- 小区百货店网怎么做网站/免费做网站软件
- Next.js 14 性能优化:从首屏加载到运行时优化的最佳实践
- JOGL 从入门到精通:开启 Java 3D 图形编程之旅
- Vue开发环境搭建上篇:安装NVM和NPM(cpnm、pnpm)
- x86_64 Ubuntu 编译安装英伟达GPU版本的OpenCV
- 计算机毕业设计Python+卷积神经网络租房推荐系统 租房大屏可视化 租房爬虫 hadoop spark 58同城租房爬虫 房源推荐系统
- bypy上传配置
推荐文章
- 8th参考文献:[8]许少辉.乡村振兴战略下传统村落文化旅游设计[M]北京:中国建筑出版传媒,2022.
- 干货!影视剪辑大神常用避免侵权的8个秘籍首次公开【覃小龙课堂】
- 如何高效开发一个OA办公系统?
- #JAVA-常用API-爬虫
- #中国版chatGPT来了# 2023年开年,
- (1)LT9211学习笔记
- (2022|ECCV,文本图像视频,3D 邻域注意,3D 稀疏注意)NÜWA:神经视觉世界创建的视觉合成预训练
- (24)(24.3) MSP OSD(二)
- (4)Elastix图像配准:3D图像
- (C++进阶)使用Eigen库进行多项式曲线拟合
- (c语言)经典bug
- (done) 声音信号处理基础知识(4) (Understanding Audio Signals for ML)